イライラするAI画像と息をのむような画像の違いは、才能や運ではありません。それは、機械が理解する視覚言語を話すことを学ぶことです。
すべてが変わった正確な瞬間を、私は今でも覚えています。火曜日の深夜2時でした。私は何時間も画面を見つめ、プロンプトを次々と実行し、ChatGPTが私が想像していたものとはまったく似ていない画像を吐き出すのを見ていました。ありえない解剖学的構造の指。意味不明な文字に溶けたテキスト。私の意図に積極的に抵抗しているかのように見えるキャラクターたち。私はAI画像生成を完全に諦める準備ができていました — それは他の人たちにしか機能しない、過大評価されたテクノロジーだと一蹴しようとしていました。
そこで私は別のことを試しました。見たいものを説明するのではなく、カメラが何を捉えるかを説明したのです。「美しい夕日」を頼む代わりに、「山頂を流れるゴールデンアワーの光、Canon 5D Mark IVで撮影、24-70mmレンズ f/2.8、自然なカラーグレーディング」と書きました。現れた画像は、単に許容範囲内というだけでなく、素晴らしいものでした。フォトリアリスティック。ついさっきまで私の想像の中にしか存在しなかったものが、まさにそこにありました。
そのたった一つの視点の転換が、すべてを解き放ちました。それからの数ヶ月間、私は深く掘り下げました。何千もの画像を生成しました。見つけられる限りのあらゆるテクニックをテストしました。OpenAIのドキュメントを端から端まで読みました。GPT Image 1.5がリリースされたその日に実験しました。そして今、私が学んだことのすべてを共有します — 他の場所で見つかるような表面的なヒントではなく、プロと趣味の人を分ける深い知識を。これは、私が始めたときに存在してほしかったガイドです。イライラする初心者から自信に満ちたクリエイターになる方法は、ここにあります。
AI画像生成への私の旅
すべてが始まった場所へお連れしましょう。これを読んでいる多くの人と同じように、私は当初、AI画像生成に懐疑的でした。「これはテクノロジーオタクのためのおもちゃに過ぎない」と私は思っていました。「本当のクリエイティブな仕事には、まだ本当のスキルが必要だ。」これほど間違っていたことはありませんでした。
AI画像に対する私の最初の本当のニーズは、実用的な問題から生じました。私はあるプロジェクトのコンテンツを作成していて、カバー画像が必要でした — それも大量に。私はストックフォトにお金を払い、他のすべてのクリエイターも使っている一般的なショットにお金を費やしていました。画像は問題ありませんでしたが、魂が欠けていました。それらは借り物のように感じられ、自分のものとは思えませんでした。
友人が、ChatGPTが画像を生成できるようになったと言いました。「欲しいものを説明するだけだよ」と彼女は言いました。「魔法みたいだよ。」そこで私は試してみました。私の最初のプロンプトは恥ずかしいほど単純でした。「山にかかる美しい夕日。」結果は?雨の中に放置された水彩画のような、ぼやけた混乱でした。控えめに言っても、感銘を受けませんでした。
しかし、何かが私を引き戻し続けました。私はもう一度試しました。そしてもう一度。失敗するたびに、AIが言語をどのように解釈するかについて新しいことを学びました。私はパターンに気づき始めました — 一貫してより良い結果を生み出す特定のフレーズ、モデルを私のビジョンから遠ざけるのではなく、そこへ導く構造的なアプローチ。
ブレークスルーは、私が気づいたときに起こりました:AI画像生成とは、心の中で見ているものを説明することではなく、カメラが実際に捉えるものを説明することなのです。そのたった一つの視点の転換がすべてを変えました。
私は夢想家のように考えるのをやめ、写真家のように考え始めました。「美しい夕日」の代わりに、ゴールデンアワーの光、特定のカメラモデル、レンズの焦点距離、絞り設定、フィルムの種類について書きました。AIはこの言語を理解しました。なぜなら、AIは何百万もの画像でトレーニングされており、それらの画像にはまさにこの種の技術的なメタデータが付いていたからです。
それからの数ヶ月間、私は夢中になりました。想像できる限りのあらゆるスタイルやユースケースで何千もの画像を生成しました。OpenAIが公開したすべてのドキュメントを読みました。可能性の限界を押し広げているクリエイターのコミュニティに参加しました。そして、2026年1月にGPT Image 1.5がリリースされたとき、私は準備ができていました。私は単に使い方を理解していただけでなく、なぜそのように機能するのかを理解していました。
今、私が学んだことのすべてを共有します。他の100のガイドで見つかるような表面的なヒントではありません。広範な実験、体系的なテスト、そしてこれらのツールを限界まで押し上げている他のクリエイターとの数え切れないほどの会話から得られた深い知識です。これは完全なガイドです — 混乱している初心者から自信に満ちたクリエイターへとあなたを導くものです。
ChatGPT画像ジェネレーターとは
テクニックに入る前に、私たちが正確に何を扱っているのかを明確にしましょう。ChatGPT画像ジェネレーターは、OpenAIの統合された画像作成および編集システムであり、現在はGPT Image 1.5モデルを搭載しています。MidjourneyやStable Diffusionのようなスタンドアロンのツールとは異なり、ChatGPTの会話インターフェースに深く統合されています。
この統合は、あなたが思っている以上に意味があります。ChatGPTはコンテキストを理解するため、複数の生成にわたって一貫性を維持し、セッション内の好みを記憶し、さらにはあなたが何を作成しようとしているのかを推論することさえできます。絵本に取り組んでいると言えば、それに応じてスタイルを調整します。企業プレゼンテーション用の画像が必要だと言えば、クリーンでプロフェッショナルな美学へとシフトします。この文脈認識は、スタンドアロンの画像ジェネレーターでは太刀打ちできないものです。
🎨 テキストから画像への生成(Text-to-Image)
自然言語で何かを説明すると、それが具現化されるのを見てください。フォトリアリスティックなポートレートから抽象芸術、製品モックアップからファンタジーの風景まで — あなたが説明できれば、AIはそれを作成できます。
✏️ 精密な画像編集
既存の画像をアップロードし、テキストコマンドで変更します。色の変更、オブジェクトの交換、照明の調整、季節の変更、または残したい要素を保持したままシーン全体を再想像します。
🔄 スタイル転送
画像の視覚言語 — そのパレット、テクスチャ、筆使い、または美学 — を取得し、それをまったく新しいコンテンツに適用します。ブランドの一貫性を維持したり、まとまりのあるシリーズを作成したりするのに最適です。
📝 信頼性の高いテキストレンダリング
ついに、実際にスペルを綴ることができるAIが登場しました。GPT Image 1.5は、かつてない精度で画像内のテキストを処理します — 言葉が重要なロゴ、ポスター、インフォグラフィック、マーケティング資料に最適です。
実際にどのように機能するか
ChatGPTの画像ジェネレーターにプロンプトを送信すると、舞台裏ではいくつかのことが起こります。まず、ChatGPT自体があなたのリクエストを処理し、コンテキストに基づいてプロンプトを拡張または明確化する可能性があります。あなたが暗示したが指定しなかった詳細を追加したり、画像モデルがよりよく理解できる方法でリクエストを構成したりするかもしれません。
その後、リクエストは画像生成モデル — 現在はGPT Image 1.5 — に送られ、テキストの説明が視覚的な出力に変換されます。このモデルは、詳細な説明とペアになった膨大なデータセットでトレーニングされており、言語と視覚的要素の間の複雑な関係を学習しています。
その結果、単なるキーワードのマッチングではなく、あなたが求めているものを真に理解するシステムが生まれます。「フォトリアリスティックで率直な瞬間」を求めれば、ポーズをとっていないように心から感じられるものが得られます。「ブラインド越しの朝の光」を求めれば、それが作り出す特定の縞模様が得られます。
GPT Image 1.5は、Artificial Analysis Image Arenaにおいて、テキストから画像への生成と画像編集の両方で1位を獲得し、指示に従う率は90%でした — これは最も近い競合他社より13ポイント高い数値です。これはマーケティングトークではありません。能力の真の飛躍を反映しています。
GPT Image 1.5革命
OpenAIが2026年1月にGPT Image 1.5をリリースしたとき、彼らは単に以前のモデルを反復しただけではありませんでした — 彼らは基盤を再構築しました。私は以前のバージョンを広範囲に使用していたので、違いにすぐに気づきました。これは漸進的な改善ではありませんでした。パラダイムシフトでした。
何が変わったのか具体的に説明しましょう。これらの改善点を理解することで、それらを効果的に活用できるようになります。
重要な3つのブレークスルー
以前のモデルには、ドリフト(意図しない変化)するというイライラする傾向がありました。1つのことを変更するように頼むと、他の3つのことが予期せず変更されました。照明を修正すると、突然キャラクターの顔が違って見えました。GPT Image 1.5は「この要素だけを変更する」ということを心から理解しています — 照明、構図、顔の特徴、さらには微妙なテクスチャを維持しながら、特定の部分を変更できます。これにより、反復的な微調整が実際に実用的になります。
生成速度は以前のバージョンと比較して最大400%向上しました。以前は30秒かかっていたものが、今では7〜8秒で済みます。しかし、さらに重要なのは、現在の処理が行われている間に新しい生成をキューに入れることができることです。これにより、クリエイティブなプロセスが「送信して待つ」から「探索して反復する」へと変わります。心理的な違いは重要です — フィードバックループが速いほど、より多くの実験が可能になります。
AI画像におけるテキストのレンダリングは、歴史的に大惨事でした — スペルミス、重複、抽象的な形に溶ける文字。GPT Image 1.5は、正しいタイポグラフィ、レイアウト、読みやすさを維持しながら、高密度で小さなテキストを処理します。これにより、インフォグラフィック、マーケティング資料、UIモックアップ、および画像に言葉が表示されるあらゆるユースケースが可能になります。初めて、プレゼンテーションスライド、キャプション付きのソーシャルメディアグラフィック、製品ラベルを、実際に使用できるレベルで生成できるようになりました。
品質設定の理解
GPT Image 1.5はさまざまな品質レベルを提供しており、それぞれをいつ使用するかを理解することで、時間を節約し、結果を向上させることができます。これは単に出力品質の問題ではありません — 正しいタスクに正しいツールを合わせるということです。
⚡ 低品質モード(Low Quality)
名前に惑わされないでください — ここの「低品質」は「高速で効率的」を意味します。結果は、ほとんどのユースケースで依然として驚くほど良好です。次の場合に使用してください:
- 初期のコンセプト探索とブレインストーミング
- アイデアを洗練させる際の迅速な反復
- 細かいディテールのないシンプルな構図
- スピードが重要な大量生成
- 最終バージョンにコミットする前のドラフト
✨ 高品質モード(High Quality)
すべてのピクセルが重要で、公開可能な結果が必要な場合。次の場合に予約してください:
- 納品用の最終制作画像
- 高密度のテキストとタイポグラフィ作業
- 細部までこだわった複雑なインフォグラフィック
- テクスチャが重要なフォトリアリスティックなポートレート
- 最大の忠実度が必要なあらゆる画像
隠された入力忠実度(Input Fidelity)設定
これはほとんどのガイドが教えてくれないことです:画像を編集する際、input_fidelityというパラメータがあり、これが結果に劇的な影響を与えます。「high」に設定すると、顔の特徴を保持したり、編集間でアイデンティティを維持したり、シーンを大きく変更したりする必要がある場合に有効です。モデルは、元の画像の主要な属性を維持するためにさらに懸命に働きます。
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # アイデンティティ保持のための秘密の成分
quality="high",
image=[open("portrait.png", "rb")],
prompt="Change the background to a sunset beach while preserving the person's exact appearance"
)この組み合わせにより、要求された変更を適用しながら、元の被写体の保存を最大限に確保します。
GPT Image 1.5での最大のシフトは技術的なものではありません — 哲学的なものです。画像生成は「プロンプトを出して祈る」から「指示して反復する」へと移行しています。これには、視覚的な創造にどうアプローチするかについての全く異なるメンタルモデルが必要です。
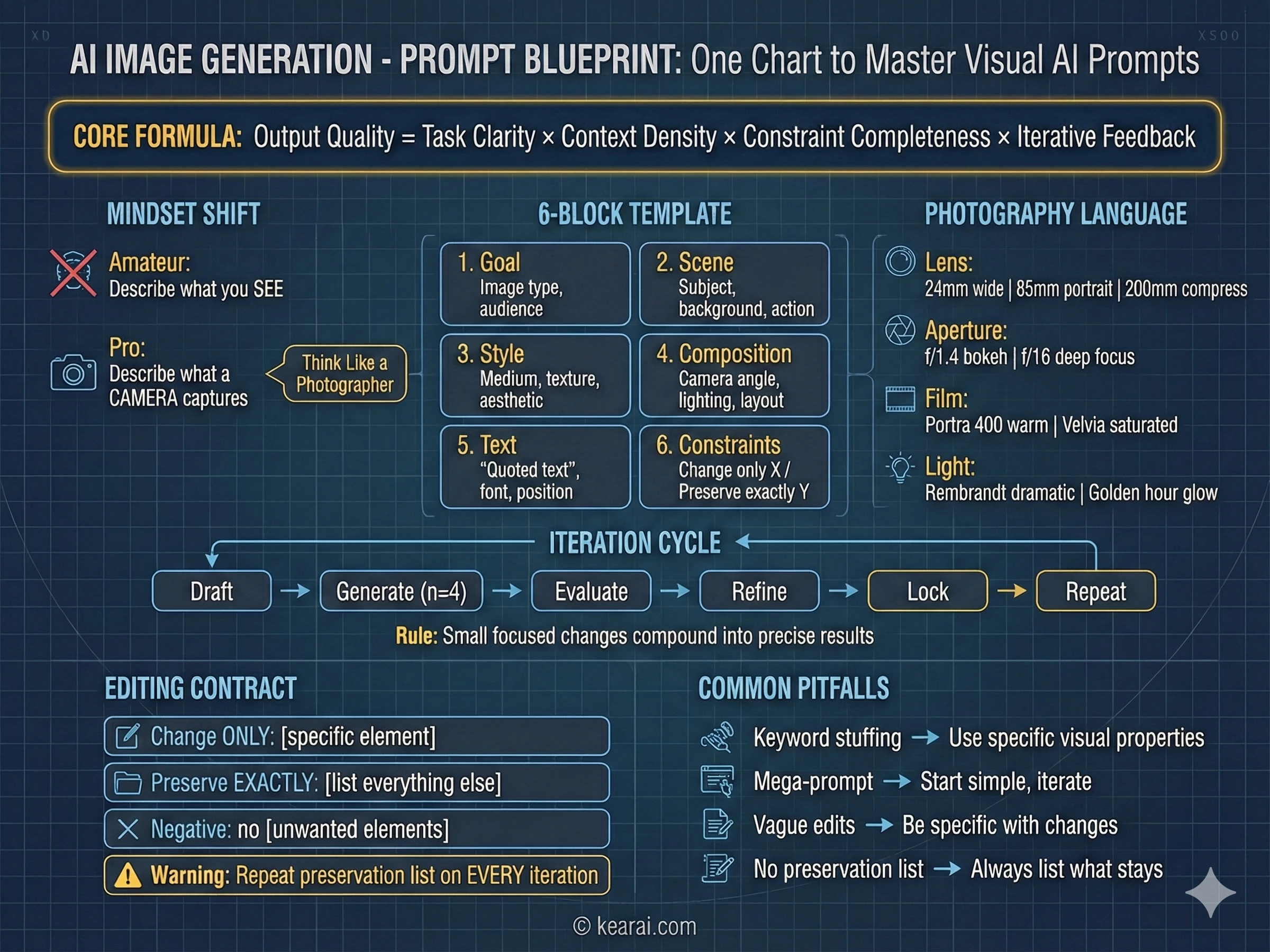
すべてを変えたプロンプトフレームワーク
何千もの画像を生成した後、私は一貫して例外的な結果を生み出すフレームワークを開発しました。「masterpiece, trending on ArtStation, ultra-detailed, 8K resolution」をプロンプトに追加することについて読んだことはすべて忘れてください。これらのキーワードは、品質の手がかりを必要とする古いモデルには機能しましたが、GPT Image 1.5はキーワードの詰め込みではなく、構造と具体性に反応します。
私はこれを構造化プロンプトアーキテクチャと呼んでおり、私が現在書いているすべての効果的なプロンプトはこのパターンに従っています。
Goal/Output:
- [Type of image: ad, UI mockup, infographic, photo, illustration]
- [Intended use and audience]
Scene:
- [Background/environment description]
- [Main subject with specific details]
- [Action or relationship between elements]
Style:
- [Medium: photograph, watercolor, 3D render, vector illustration]
- [Key textures: matte, glossy, grainy, smooth, organic]
- [Quality descriptors: realistic imperfections, stylized, minimalist]
Composition/Layout:
- [Camera position: close-up, wide shot, aerial view, eye-level]
- [Lighting: golden hour, studio strobes, overcast, dramatic shadows]
- [Element placement: centered, rule of thirds, negative space, margins]
Text (if any):
- "Exact text in quotes"
- [Font style, size, color, position]
- [Specify: render only once, no duplicates]
Constraints:
- Change ONLY: [specific element if editing]
- Preserve exactly: [elements that must stay unchanged]
- Negative: no watermark, no extra text, no logos, no [unwanted elements]このフレームワークは、モデルが行わなければならないすべての視覚的決定に対して明確なコンテキストを提供します。
効果的なプロンプティングのための7つの原則
構造に加えて、これらの原則が私が各プロンプトを書く方法を導いています。これらは、ほぼ機能する画像と、あなたのビジョンを完全に捉える画像の違いです。
キーワードよりも構造
一貫した順序を使用します:背景 → 被写体 → 詳細 → 制約。複雑なリクエストには、ラベル付きのセクションまたは改行を使用します。長い段落はモデルを混乱させます。整理された構造は、モデルをあなたの意図へと導きます。
最上級よりも具体性
「高品質」や「超詳細」の代わりに、実際の視覚的属性を記述します。素材、テクスチャ、形状、媒体。「目に見える毛穴と微妙なそばかす」は、「非常に詳細な顔」に毎回勝ちます。
明示的な構図コントロール
フレーミング(クローズアップ、ワイドショット、鳥瞰図)、視点(目の高さ、ローアングル、ダッチアングル)、照明のムード(ソフトな拡散光、ゴールデンアワー、高コントラストの逆光)を指定します。これらを偶然に任せてはいけません。
変更 vs. 保持の契約
編集の場合、何を変更し、何を変更しないかを明示的に述べます。「change only X」と「preserve exactly Y」を使用します。ドリフトを防ぐために、この保持リストを反復ごとに繰り返します。
テキストには精度が必要
必要なテキストを「引用符」または大文字に入れます。フォント、サイズ、色、位置を指定します。難しい単語やブランド名については、一文字ずつ綴ります。常に「render exactly once, no duplicates」を追加します。
複数の画像を参照する際の明確さ
複数の入力画像を扱う場合、それぞれにインデックスと説明で言及します:「Image 1: the product shot, Image 2: the style reference.」それらがどのように相互作用すべきかを明示的に述べます。
過負荷にするのではなく反復する
クリーンなベースプロンプトから始め、小さく単一の変更で洗練させます。「照明を暖かくする。」「背景の木を削除する。」小さなステップが正確な結果に積み重なります。
最も一般的な間違い
私が人々が犯すのを見る最大の間違い:モデルが何とかして解決してくれることを期待して、1つの巨大なプロンプトですべてを指定しようとすること。これはほとんどの場合うまくいきません。ベースを確立するためにより単純なプロンプトから始め、ターゲットを絞った改良で反復します。より短い時間で、イライラする失敗をはるかに少なくして、より良い結果を得ることができます。
写真撮影のマインドセット
私の結果における唯一の最大の改善は、精神的なシフトから来ました:私はビジョンを説明するアーティストのように考えるのをやめ、ショットを説明する写真家のように考え始めました。これは単なる比喩ではありません — モデルがどのようにトレーニングされたかを利用する実用的なテクニックです。
AI画像モデルは、メタデータ(カメラモデル、レンズ仕様、絞り設定、照明条件)が付いた何百万もの写真から学習しました。この言語を使用すると、実際のカメラが実際のシーンをどのように捉えるかについてのモデルの深い理解が活性化されます。
機能する写真用語
- レンズ選択: "24mm wide angle" は端に歪みのある広大なシーンを作成し、"200mm telephoto" は奥行きを圧縮して被写体を分離します
- 絞りの感触: "f/1.4 bokeh" はポートレートにクリーミーな背景のぼかしを与え、"f/16 deep focus" は風景ですべてをシャープに保ちます
- フィルムタイプ: "Kodak Portra 400" は暖かく、魅力的な肌のトーンに、"Fuji Velvia" はパンチの効いた彩度の高い風景に、"Ilford HP5" はコントラストのある白黒に
- 照明設定: "Rembrandt lighting" は劇的なポートレートに、"butterfly lighting" はビューティーショットに、"golden hour backlight" は幻想的な輝くエッジに
- カメラの動き: "long exposure motion blur" はダイナミックなエネルギーに、"high-speed freeze frame" はアクションを捉えるために
「プロフェッショナルに見せて」と言う代わりに、「shot on Hasselblad medium format, studio strobe lighting, seamless gray backdrop, color-calibrated for print reproduction」と試してみてください。「リアルなポートレート」の代わりに、「candid photograph, 85mm f/1.4 lens, window light from camera left, subtle fill from reflector, visible skin texture with pores, shot on Sony A7R IV」と試してみてください。
❌ BEFORE(曖昧):
"A beautiful portrait of an old fisherman, very detailed, high quality, realistic"
✅ AFTER(写真撮影のマインドセット):
"Candid documentary photograph of an elderly fisherman on a weathered wooden boat.
Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind eyes.
Gray stubble. Faded traditional anchor tattoo on forearm. Salt-stained navy wool
sweater, worn cap.
Early morning coastal light, soft fog diffusing the sun. Medium close-up at eye
level, 50mm lens, f/2.8, shallow depth of field. Shot like 35mm film with subtle
grain, natural color balance.
Documentary style — honest, unretouched, capturing a real moment. No glamorization."写真撮影のマインドセットは、曖昧な希望を、モデルが深く理解できる正確な視覚的仕様に変換します。
写真用語を使用して画像を説明するとき、あなたは単により具体的になっているだけではありません — モデルが理解するようにトレーニングされた言語を話しているのです。カメラの仕様、照明設定、フィルムタイプは任意のキーワードではありません。それらは、モデルが正確にデコードできる正確な視覚情報をエンコードしています。
テキストから画像への変換(Text-to-Image)の習得
純粋なテキスト記述から画像を作成することは、ほとんどの人がAI画像の旅を始めるところです。それはまた、アマチュアとプロの結果の差が最も顕著なところでもあります。一貫して優れた結果を生み出すテクニックを、さまざまなユースケースにわたってガイドしましょう。
自然に感じられるフォトリアリスティックな画像
フォトリアリズムの鍵は直感に反します:不完全さをプロンプトする必要があります。完璧な肌、完璧な照明、完璧な構図 — これらは「AI生成」と叫んでいます。現実はもっと乱雑で、その乱雑さが画像を本物に感じさせるのです。
Create a photorealistic candid photograph of an elderly sailor standing on a small fishing boat.
Subject: Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind
eyes with crow's feet. Gray stubble, a few days unshaven. Faded traditional anchor
tattoo on forearm. Salt-stained navy wool sweater, worn and pilled. Creased cap
with faded insignia.
Setting: Early morning on the water, soft coastal fog diffusing the light. Aged
wooden boat deck with peeling paint, fishing nets in background, coiled rope.
Technical: Shot like 35mm film photography, medium close-up at eye level, 50mm
lens, shallow depth of field with boat blurred behind him. Subtle film grain,
natural color balance without heavy grading.
The image should feel like a real moment captured by a photojournalist — honest,
unposed, with real skin texture, worn materials, and everyday imperfection. No
glamorization, no heavy retouching, no artificial perfection.風化した肌、使い古した素材、剥がれたペンキなど、不完全さを明示的に要求していることに注目してください。現実にはテクスチャがあります。
インフォグラフィックとデータ可視化
GPT Image 1.5におけるテキストレンダリングの改善により、インフォグラフィックは真に実用的なユースケースになりました。私は今、仕事で実際に使用するプロ品質の情報グラフィックを作成しています。
Create a detailed infographic explaining how a coffee machine works.
Structure:
- Title at top: "The Journey of Your Morning Coffee"
- Vertical flow diagram showing: bean hopper → grinder → portafilter →
grouphead → water heating → extraction → cup
- Each step has an icon and 1-2 sentence explanation
- Warm color palette (browns, creams, copper accents)
- Clean, modern design with plenty of white space
- Subtle coffee stain texture in background corners
Style: Professional print-quality infographic, vector-style icons, clear
hierarchy, readable at A4 size.
Typography: Clean sans-serif headings, readable body text, clear visual
hierarchy between title, section headers, and explanatory text.
No watermarks. No stock photo elements. Original illustration only.高密度のテキストと複雑なレイアウトの場合は、常にquality="high"を使用して、テキストが鮮明で読みやすい状態を維持するようにしてください。
ロゴとブランドデザイン
ロゴ生成には、シンプルさとスケーラビリティを優先する必要があります。優れたロゴは、小さなファビコンから巨大な看板まで、あらゆるサイズで機能します。実際にロゴとして機能するデザインをプロンプトする方法は次のとおりです。
Create an original logo for "Field & Flour" — a local artisan bakery.
Brand personality: Warm, authentic, handcrafted, timeless. Not trendy or corporate.
Design requirements:
- Clean vector-style shapes with strong silhouette
- Balanced negative space
- Must read clearly from 16px favicon to large signage
- Flat design, minimal strokes, no gradients unless essential
- Earth-tone palette: warm wheat gold, deep brown, cream
- Could incorporate subtle wheat or grain element
- Text must be perfectly legible and properly kerned
Output: Single centered logo on plain cream background. Generous padding around
the design for flexibility.
No watermarks, no mockups, no 3D effects, no complex imagery. Simple, functional,
timeless design.複数のバリエーションを生成するにはn=4を使用します。ロゴデザインは主観的なものです — 選択肢を用意しましょう。
UIとアプリのモックアップ
UIデザインの場合、インターフェースがすでに存在し、実際のユーザーに出荷されているかのように説明します。コンセプトアート言語はコンセプトアートを生み出します。製品言語は使用可能なモックアップを生み出します。
Create a realistic mobile app UI mockup for a local farmers market app.
Screen content (from top):
- Simple header with market name "Riverside Market" and search icon
- Today's featured vendor carousel with square photos
- "Fresh Today" section with produce category chips (Vegetables, Fruits, Dairy, Baked)
- Vendor list with small photos, names, specialties, and distance
- Bottom navigation: Home, Map, Favorites, Cart, Profile
Design language:
- White background, subtle natural green accents
- Clear typography hierarchy (system fonts feel)
- Generous padding and touch-friendly targets
- Looks like a real shipped product, not a concept
- Uses realistic vendor names and produce photos
Frame: Place the UI inside an iPhone 15 Pro device frame, slight perspective
tilt, subtle shadow beneath.レイアウト、階層、間隔、リアルなインターフェース要素に焦点を当てます。概念的または芸術的な言葉は避けてください。
コミックとシーケンシャルアート
マルチパネルコミックの作成には、物語を明確な視覚的ビートのシーケンスとして定義する必要があります(1パネルにつき1つ)。説明は具体的でアクション指向に保ちます。
Create a 4-panel vertical comic strip. Equal panel sizes, clear panel borders.
Panel 1: Pet owner walks out the front door, keys in hand. Through the window
behind them, we see their cat watching — paws pressed against glass, eyes wide
with apparent sadness. The house suddenly feels empty.
Panel 2: The door clicks shut. The cat slowly turns away from the window toward
the empty house. Its posture shifts from forlorn to interested. Eyes narrow with
possibility.
Panel 3: Total chaos. Cat sprawled across the forbidden couch like royalty.
Knocked over plant on the floor. Papers scattered. Sunbeam spotlighting the
scene of domestic crime.
Panel 4: Door handle turns. Cat sits perfectly upright by the entrance,
composed and innocent, tail wrapped neatly around paws. Not a hair out of
place. As if nothing happened.
Style: Warm illustrated style with expressive characters, clear visual
storytelling that reads without text. Consistent character design across
all panels.
No speech bubbles or text. Let the visuals tell the story.各パネルを明確なアクションを伴う個別の視覚的ビートとして定義します。モデルはパネルレイアウトと視覚的な連続性を処理します。
児童書のイラスト
児童書のイラストには特定のアプローチが必要です:記憶に残るキャラクターデザイン、温かみのある親しみやすいスタイル、テキストオーバーレイで機能する構図。
Create a children's book illustration introducing the main character.
Character: Young forest hero, around 8 years old.
- Green hooded tunic (think woodland adventurer, not Robin Hood)
- Soft brown boots, well-worn
- Small belt pouch for collecting treasures
- Carries a tiny wooden bow (symbolic, for helping not hurting)
- Kind expression, bright curious eyes, brave but gentle demeanor
- Slightly oversized head for picture book proportions
Theme: This character protects and rescues small forest animals in trouble.
Style: Hand-painted watercolor look with soft outlines, warm earthy palette
with forest greens and autumn oranges. Whimsical, friendly, inviting for
young readers ages 4-8.
Composition: Character standing in simple forest glade, dappled sunlight,
leaving room for title text above. Character clearly showcased.
Original character design only. No text. No watermarks. No copyrighted
character references.このキャラクター参照画像を保存してください — 後のイラストで一貫性を維持するために必要になります。
世界知識の活用
GPT Image 1.5の最も過小評価されている能力の1つは、その内蔵された世界知識です。モデルは微妙な手がかりからコンテキストを推測し、明示的な指示なしに歴史的および文化的に適切な画像を生成できます。
Create a realistic outdoor crowd scene in Bethel, New York on August 16, 1969.
Photorealistic, period-accurate clothing, staging, and environment.
Documentary photography style, shot on film, natural lighting.モデルは言われなくてもこれがウッドストックであることを知っています。日付と場所だけで、ヒッピー、当時のファッション、フェスティバルの雰囲気を生成します。
この世界知識は、時代を超えた建築、数十年にわたるファッション、文化的イベント、地理的ランドマーク、芸術運動、さらには特定の写真の美学にまで及びます。正確さが重要な場合、時間と場所を指定することで、見たいものを長々と説明するよりも良い結果が得られることがよくあります。
精密な編集の技術
テキストから画像への生成は印象的ですが、画像編集こそがGPT Image 1.5が真に輝く場所です。すべてをそのままにして既存の画像を正確に変更できる機能は、以前はPhotoshopの専門知識なしでは不可能だったプロフェッショナルなワークフローを開放します。
編集の黄金律
成功する編集はすべて同じパターンに従います:何を変更するかを明示的に述べ、何が同じままであるかを明示的に述べます。これは当たり前のように聞こえますが、必要な具体性のレベルはほとんどの人が認識しているよりも高いです。
編集プロンプトは常に次のように構成してください:「Change ONLY [X]. Preserve EXACTLY: [comprehensive list of everything else].」そして、元の状態から徐々にずれていくのを防ぐために、後続の編集ごとに保存リストを繰り返します。
バーチャル試着
EコマースはAIの試着機能によって変革されています。アイデンティティを完全に維持する服の変更に使用するプロンプト構造は次のとおりです。
Edit the image to dress this person in the provided clothing items.
MUST PRESERVE (do not change in any way):
- Face, facial features, expression, skin tone
- Body shape, proportions, and pose
- Hairstyle and hair color
- Background and environment
- Camera angle, framing, and composition
- Overall lighting direction and quality
CHANGE ONLY:
- Replace current clothing with provided garment images
- Fit garments naturally to body geometry
- Show realistic fabric draping, folds, and behavior
- Match lighting and shadows on fabric to original photo
REQUIREMENTS:
- Photorealistic integration — outfit should look worn, not pasted
- Maintain color temperature of original image
- No accessories, text, logos, or watermarks added
- Identity must remain clearly recognizableバーチャル試着には、顔の類似性を確実に保持するために常にinput_fidelity="high"を使用してください。
スタイル転送
スタイル転送は、画像の視覚言語 — そのパレット、テクスチャ、筆使い、美学 — を取得し、それを新しいコンテンツに適用します。これは、ブランドの一貫性を維持したり、まとまりのあるシリーズを作成したりするのに非常に貴重です。
Using the EXACT visual style of the reference image (Image 1), create:
A man riding a motorcycle on a winding mountain road.
STYLE ELEMENTS TO MATCH PRECISELY from reference:
- Color palette and saturation levels
- Line quality and weight
- Texture treatment and brushwork
- Lighting style and direction
- Level of detail vs. abstraction
- Overall artistic aesthetic
APPLY TO NEW CONTENT:
- Single subject (man on motorcycle)
- Clear composition with visual interest
- Mountain road environment with curves
- Sense of motion and freedom
The new image should look like it came from the same artist or series as
the reference. Maintain stylistic consistency exactly.スタイル転送は、どのスタイル要素を保持し、どのコンテンツ要素を変更するかを具体的に指定した場合に最もよく機能します。
オブジェクトの交換
フォトリアリズムを維持しながらオブジェクトを交換することが実用的になりました。秘訣は、何を追加するかだけでなく、それが既存のシーンとどのように統合されるべきかを説明することです。
In this room photo, replace ONLY the white plastic chairs with
mid-century modern wooden chairs (walnut finish, tapered legs,
woven seat).
PRESERVE COMPLETELY:
- Camera angle and perspective
- Room lighting direction and quality
- All other furniture and objects
- Wall colors and decorations
- Floor material and shadows
- Overall image quality and color grading
INTEGRATION REQUIREMENTS:
- Chairs must match room's perspective exactly
- Wood grain should catch existing light realistically
- Contact shadows must be natural and match light source
- Scale must be accurate relative to table height
- New chairs should look like they belong in this room
Photorealistic result — should look like the original photograph.インテリアデザインの視覚化は、最も商業的に価値のある編集アプリケーションの1つです。
スケッチからフォトリアリスティックなレンダリングへ
ラフスケッチを洗練されたレンダリングに変換することは、製品デザイン、建築、コンセプト開発において非常に役立ちます。プロンプトは、スケッチを従うべき仕様として扱う必要があります。
Transform this hand-drawn sketch into a photorealistic image.
PRESERVE FROM SKETCH:
- Exact layout and proportions
- Perspective and viewing angle
- Element placement and relationships
- Implied depth and layering
ADD FOR REALISM:
- Appropriate real-world materials and textures
- Consistent natural lighting (interpret from sketch shading)
- Environmental context matching the implied setting
- Surface imperfections and wear appropriate to materials
CONSTRAINTS:
- Do not add new elements not present in sketch
- Do not add text or watermarks
- Treat the sketch as an architectural blueprint to follow exactly
- Fill in realistic details while honoring the original compositionモデルはスケッチの意図を解釈し、元の構図を尊重しながらリアルな詳細を埋めます。
照明と天候の変換
シーンのジオメトリを維持しながら環境条件を変更することは、私のお気に入りの編集アプリケーションの1つです。季節のバリエーション、時間帯の代替案、またはムードの調整を作成するのに最適です。
Transform this daytime summer scene into a winter evening with snowfall.
CHANGE:
- Time of day: from afternoon to dusk (warm interior lights visible)
- Season: summer to deep winter
- Weather: clear to active snowfall
- Ground: grass to fresh snow coverage
- Trees: summer foliage to bare branches with snow
- Atmosphere: add visible breath if people present
- Surfaces: add frost on windows and metal
PRESERVE:
- Camera position and angle exactly
- All objects and their exact positions
- Architecture and structural elements
- People and their poses (update clothing appropriately)
- Overall composition and framing
Style: Photorealistic, natural atmospheric perspective, visible
snowflakes in air, cozy contrast between warm interior lights and
cold exterior. Should feel photographed, not filtered.環境変換で最良の結果を得るには、input_fidelity="high"とquality="high"を使用してください。
マルチ画像合成
複数のソース画像からの要素を組み合わせるには、何がどこから来るのか、そして要素がどのようにシームレスに統合されるべきかについての明確な指示が必要です。
I'm providing 2 images:
- Image 1: Beach scene with woman standing on shore at sunset
- Image 2: Golden retriever sitting in a studio setting
Task: Place the dog from Image 2 into the beach scene from Image 1,
positioned next to the woman, looking up at her.
MATCHING REQUIREMENTS:
- Dog's lighting must match beach sunset (warm golden light from left)
- Scale dog appropriately relative to woman's height
- Dog should cast shadow consistent with scene's sun angle
- Sand texture should show around and under dog's paws
- Fur should catch the same golden hour highlights as scene
PRESERVE FROM IMAGE 1:
- Woman's exact appearance, position, and pose
- Beach background completely unchanged
- Original photo's color grading and mood
The composite should look like a single photograph taken on location.
No visible compositing artifacts.番号で画像を参照し、どの要素が転送され、どの要素が固定されたままであるかを明示してください。
画像内のテキスト翻訳
GPT Image 1.5のテキスト機能により、視覚コンテンツを国際市場向けにローカライズすることが劇的に簡素化されました。
Translate all text in this infographic from English to Japanese.
MUST PRESERVE:
- Exact layout, spacing, and positioning of all elements
- All visual elements, icons, illustrations, and graphics
- Typography hierarchy (headlines vs body text relationships)
- Color scheme and overall design aesthetic
- Font weights and relative sizes
TRANSLATION REQUIREMENTS:
- Accurate Japanese translation with natural phrasing
- Match visual weight and style to original fonts
- Adjust character spacing for Japanese typographic norms
- No text truncation or overflow outside original bounds
Do not modify any non-text elements. Only change the language.このワークフローは、ゼロから構築することなく、マーケティング資料、UIスクリーンショット、パッケージング、インフォグラフィックを処理します。
プロのための高度なテクニック
基本を習得したら、これらの高度なテクニックがあなたの仕事を真にプロフェッショナルなレベルに引き上げます。これらは、私が広範な実験を通じて開発したパターンであり、一貫して優れた結果を生み出すテクニックです。
画像間でのキャラクターの一貫性
AI画像生成における最大の課題の1つは、複数の画像間でキャラクターの一貫性を維持することです。児童書、ブランドマスコット、またはさまざまなシーンで同じキャラクターを必要とするプロジェクトのために、ここに私の実証済みのワークフローがあります。
キャラクターの決定的な外観を確立する詳細な参照画像を生成します。衣装、プロポーション、表情、カラーパレットなど、すべての重要な詳細を含めます。この画像を保存します — これがあなたの真実の源となります。
将来のすべてのプロンプトで参照するキャラクターの詳細なテキスト説明を書きます。各視覚的要素について具体的に記述します。このテキストアンカーは視覚的アンカーを補完します。
新しいシーンを作成するときは、常に入力としてアンカー画像を含め、「maintain exact character appearance from reference image」と明示的に指示します。
モデルは会話セッション内でコンテキストを維持します。シーンごとに最初からやり直すのではなく、成功した画像に基づいて構築します。以前の生成物を直接参照します。
Continue the children's book story using the character from the reference image.
New Scene:
The same young forest hero is gently helping a frightened squirrel out
of a fallen hollow tree after a winter storm. Snow on the ground, bare
branches above, warm light filtering through clouds.
CHARACTER CONSISTENCY (from reference):
- Same green hooded tunic, exact shade and style
- Same soft brown boots
- Same belt pouch
- Same facial features, proportions, and color palette
- Same gentle, heroic personality in expression
- Same children's book proportions
STYLE CONSISTENCY (from reference):
- Same watercolor illustration style
- Same soft outlines
- Same warm earthy color treatment
- Same whimsical, friendly aesthetic
New elements: winter forest environment, frightened squirrel, fallen
tree with hollow.
Do not redesign the character. Do not change the artistic style.
No text. No watermarks.本全体で一貫性を維持するために、アンカー画像を参照し、主要なキャラクターの詳細を繰り返します。
様式化された3Dポートレートテクニック
参照写真からハイパー様式化された3Dポートレートを作成することは、私の代表的な出力の1つになりました。鍵は、望ましい美学に関する極端な具体性です。
Create a hyper-stylized 3D floating head portrait based on this person.
STYLE CHARACTERISTICS:
- Smooth skin with glossy vinyl-finish surface
- Strong highlighter on cheekbones and nose tip catching soft light
- Holographic, iridescent eyeshadow (purple to teal color shift)
- Thick hair sculpted in slick, glossy waves like polished acrylic
- Small metallic chrome nose piercing with brushed reflections
EXPRESSION:
Confident, slightly unimpressed look — half-lidded eyes, subtly
arched brow, the sophisticated "too cool" attitude.
TECHNICAL SPECIFICATIONS:
- Head floats isolated against plain white background
- Slight 15-degree tilt (premium product render feeling)
- Bright, diffuse studio lighting with no harsh shadows
- Emphasis on glossy, plastic, subsurface scattering effects
- Ultra-smooth textures throughout
- Close-up portrait angle, straight-on, 85mm lens feel
The result should look like a high-end 3D character render or
collectible figure — plastic perfection with personality.このレベルの美的詳細は、さまざまな被写体に対して驚くほど一貫した結果を生み出します。
ちびキャラ変換
写真をかわいいちびスタイルのキャラクターに変換することは、ブランドマスコット、ソーシャルメディアアバター、商品化において驚くほど効果的です。
Transform this person into an adorable chibi-style character.
CHIBI PROPORTIONS:
- Tiny body (about 1 head-height tall)
- Oversized head (3x body proportions)
- Large, sparkling eyes with cute highlights
- Soft, rounded facial features
- Cheerful, expressive pose with personality
PRESERVE FROM ORIGINAL:
- Recognizable facial features (simplified but identifiable)
- Hairstyle, length, and hair color
- Distinctive clothing style or accessories
- Any notable characteristics (glasses, jewelry, etc.)
- Overall personality and vibe
STYLE:
- Smooth pastel shading
- Clean lines and simplified details
- Bright, expressive colors
- Collectible figure aesthetic
Background: Simple gradient or plain color to showcase character.
The result should feel like an irresistible chibi mascot that
clearly represents the original person.ちび変換は、パーソナルブランディング、チームアバター、商品デザインに適しています。
完璧なテキストを含むマーケティングクリエイティブ
正確なテキストを含むマーケティング資料を作成するには、厳格なタイポグラフィ制御と明示的なテキスト仕様が必要です。
Create a realistic highway billboard mockup featuring this product.
BILLBOARD CONTENT:
- Product bottle prominently displayed on left third
- Main headline on right (EXACT TEXT, render verbatim):
"Fresh & Clean — Every Day"
- Tagline below headline: "Nature's Best Ingredients"
- Small logo placeholder area in bottom right corner
TYPOGRAPHY SPECIFICATIONS:
- Headline: Bold sans-serif, white text, high contrast
- Tagline: Light sans-serif, slightly smaller, same white
- Clean kerning, centered alignment within text area
- Text appears EXACTLY ONCE — no duplicates anywhere
SCENE:
- Billboard on highway overpass or roadside structure
- Sunset lighting creating warm, appealing atmosphere
- Photorealistic environment with motion-blurred vehicles below
- Professional advertising photography feel
No watermarks. No additional marketing copy. No logos unless
specified. Text must be perfectly legible and correctly spelled.テキストを含むマーケティング資料には常にquality="high"を使用してください。最終使用前にスペルを確認してください。
製品写真の抽出
Eコマースには、被写体が分離されたきれいな製品ショットを作成することが不可欠です。これが機能するプロンプトです。
Extract the product from this image for e-commerce use.
OUTPUT SPECIFICATIONS:
- Transparent background (RGBA PNG format)
- Crisp silhouette with clean edges
- No halos or color fringing around product
- All product labels and text perfectly preserved
- Exact product geometry and proportions maintained
OPTIONAL ENHANCEMENT:
- Add subtle, realistic contact shadow
- Shadow should be soft and natural, no hard edges
- Shadow works with the transparent background
CRITICAL CONSTRAINTS:
- Do NOT restyle or recolor the product
- Do NOT modify product appearance in any way
- Only remove background and add optional shadow
- Preserve every detail of the original product exactly注意:現在のモデルは、透明度を示すために市松模様をレンダリングします — 真のアルファチャネルには後処理が必要な場合があります。
既知の制限
背景の削除は現在、出力ファイルで真のRGBA透明度を生成するのではなく、透明度を示す視覚的な市松模様をレンダリングします。本番使用の場合は、画像編集ソフトウェアを使用して市松模様を実際の透明度に変換するために出力を後処理する必要がある場合があります。
反復的な改良ループ
1つのプロンプトで完璧さを達成しようとしないでください。プロフェッショナルな結果は、体系的な反復から生まれます。
改良プロセス
- 生成: 核となる要素と全体的な構図で初期画像を作成します
- 評価: 最初に対処すべき最も重要な1〜2の問題を特定します
- 改良: それらの特定の問題のみを修正し、他のすべてを明示的に保持します
- ロック: 次の反復を試みる前に現在の状態を保存します
- 繰り返し: 満足するまで続け、段階的に構築します
それぞれの小さく集中した変更は、一度にすべてを試みるよりもはるかに少ないフラストレーションで、正確な最終結果に積み重なります。
実際のプロフェッショナルワークフロー
理論は貴重ですが、テクニックがどのように組み合わさって完全なワークフローになるかを見ることで、理解が結晶化します。ここでは、私がプロの現場で最も頻繁に使用するワークフローを紹介します。
Eコマース製品写真パイプライン
完全な製品ビジュアルシステム
- 製品の抽出: 生の製品写真から背景を削除し、きれいな分離ショットを作成します
- ライフスタイルコンテキスト: 環境シーン(キッチン、オフィス、屋外)を生成し、製品をそれらに合成します
- カラーバリエーション: 再撮影することなく、ターゲットを絞った編集で製品のカラーバリエーションを作成します
- マーケティングクリエイティブ: 製品統合を備えたビルボードモックアップ、ソーシャルメディアグラフィック、バナー広告を生成します
- ローカリゼーション: デザインを維持しながら、マーケティング資料のテキストをさまざまな市場向けに翻訳します
以前はスタジオ時間、Photoshopの専門知識、複数のスペシャリストを必要としていた完全な製品写真パイプラインが、今では一連のAIプロンプトを通じて実行されます。
コンテンツクリエイターのビジュアルライブラリ
一貫したブランド資産の構築
- キャラクター開発: 詳細なアンカー画像でブランドマスコットや個人のアバターを作成します
- スタイルガイド生成: カラーパレットのリファレンス、ムードボード、美的例を作成します
- サムネイルファクトリー: 確立されたキャラクターとスタイルを使用して、一貫したYouTube/ソーシャルのサムネイルを生成します
- 背景ライブラリ: さまざまなコンテンツタイプに合わせて、ブランドの美学に一致するシーンの背景を作成します
- バリエーションの拡大: スタイル転送を使用して、すべての新しいコンテンツで視覚的な一貫性を維持します
視覚的な基盤を一度構築し、その後効率的に反復します。以前は専任のデザインチームが必要だったようなブランドの一貫性を生み出します。
迅速なデザインプロトタイピング
コンセプトからビジュアルまで数分で
- ラフスケッチ: 基本的なコンセプトを手描きします(ナプキンの品質で十分です — 大まかな形状とレイアウト)
- 初期レンダリング: スケッチをフォトリアリスティックまたは様式化された画像に変換し、構図を維持します
- 反復サイクル: ターゲットを絞った編集で改良します(「より暖かい照明」、「異なる素材」、「より高いコントラスト」)
- バリアントの探索: クライアントへのプレゼンテーションや意思決定のために、複数のバリエーション(n=4)を生成します
- 最終的な磨き上げ: 洗練された詳細を備えた、選択した方向性の高品質なエクスポート
デザイナーは、従来のデジタル作成ワークフローと比較して、コンセプトの反復が劇的に速くなったと報告しています。
児童書イラストパイプライン
一貫した絵本の作成
- キャラクターデザイン: 決定的な外観を確立する詳細なキャラクター参照シートを作成します
- スタイルの確立: イラストのスタイルをロックするために2〜3のサンプルページを生成し、最適なものを選択します
- シーンごとの生成: キャラクターとスタイルのアンカーを常に参照しながら、ストーリーをページごとに進めます
- 一貫性チェック: すべてのページを一緒に表示し、編集を使用してキャラクターのずれやスタイルの不一致を修正します
- 最終的な改良: 確立された外観を維持しながら、必要に応じて個々のページを磨きます
アンカー画像のアプローチにより、本全体を通して一貫したキャラクターイラストが真に達成可能になります。
私の結果を台無しにした間違い
私自身や他の多くの人々がAI画像生成に苦労しているのを見て、成功とフラストレーションを分けるパターンを特定しました。これらは私がかつて犯した間違いであり、それをどのように修正したかです。
❌ キーワードの詰め込み
間違い: すべてのプロンプトに「highly detailed, 8K, photorealistic, trending on ArtStation, masterpiece」を追加すること。
解決策: 代わりに具体的な視覚的属性を記述します。「Visible skin pores, morning window light, 50mm lens depth of field」は、一般的な品質キーワードよりもはるかに多くのことを伝えます。
❌ メガプロンプト
間違い: モデルが何とかして私の完全なビジョンを理解してくれることを期待して、すべての詳細を1つの巨大なプロンプトで指定しようとすること。
解決策: シンプルに始めます。まずしっかりしたベース画像を取得し、ターゲットを絞ったフォローアッププロンプトで改良します。段階的に構築する方がはるかに良い結果を生み出します。
❌ 曖昧な編集指示
間違い: 「より良くする」の意味や照明がどのように変わるべきかを指定せずに、「より良くする」または「照明を修正する」と言うこと。
解決策: 変更について具体的にします。「照明を厳しい頭上の光から、左からの柔らかい窓の光に変更し、色温度を暖かくする。」
❌ 保持リストを忘れる
間違い: 何を変更しないでおくべきかを明示的に述べずに変更を要求し、他の要素がずれたときに驚くこと。
解決策: すべての編集プロンプトには、明示的な保持要件が含まれています。モデルは以前の制約を覚えていないため、反復ごとにそれらを繰り返します。
❌ コンテキスト健忘症
間違い: 関連する画像のために新しい会話を開始し、構築されたすべてのコンテキストと一貫性を失うこと。
解決策: 関連する作業についてはセッション内で構築します。以前の生成物を直接参照します。コンテキストを活用するために「前の画像と同じスタイル」などのフレーズを使用します。
❌ 間違った品質設定
間違い: 常に高品質を使用する(反復には遅くて高価)、または常に低品質を使用する(重要なときに決定的な詳細が欠けている)。
解決策: 設定をタスクに合わせます。探索と反復には低品質、最終出力とテキストを含むすべてのものには高品質。
❌ モデルと戦う
間違い: まったく同じプロンプトを繰り返し実行して異なる結果を期待したり、モデルが一貫して抵抗する方向を強制したりすること。
解決策: プロンプトが機能しない場合は、繰り返すのではなく言い換えます。異なる言葉はモデル内の異なるパターンを活性化します。アプローチを変えてください。
❌ 確率性の無視
間違い: 同一のプロンプトから同一の結果を期待し、出力が変動するとイライラすること。
解決策: 複数のバリエーション(n=4)を生成し、最適なものを選択します。変動性を克服すべき欠陥ではなく、創造的な可能性の源として受け入れます。
ほとんどの人ができる最も効果的な変更は1つだけです:プロンプトを願い事として扱うのをやめ、仕様書として扱い始めることです。人間の協力者に対するデザインブリーフと同じくらい正確であってください。モデルは驚くほど有能ですが、その能力を発揮するには明確な方向性が必要です。
開発者のためのAPI統合
GPT Image 1.5をプログラムでアプリケーションに統合する場合、必要な技術的な詳細とベストプラクティスは次のとおりです。
基本的なAPIセットアップ
import os
import base64
from openai import OpenAI
client = OpenAI()
# Create output directory
os.makedirs("output_images", exist_ok=True)
def save_image(result, filename: str) -> None:
"""Save base64 image response to file."""
image_base64 = result.data[0].b64_json
with open(f"output_images/{filename}", "wb") as f:
f.write(base64.b64decode(image_base64))
# Basic text-to-image generation
result = client.images.generate(
model="gpt-image-1.5",
prompt="Your detailed prompt here",
quality="high", # or "low" for faster iteration
n=1 # number of variations
)
save_image(result, "output.png")複数の入力による画像編集
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # Essential for identity preservation
quality="high",
image=[
open("input_images/source.png", "rb"),
open("input_images/style_reference.png", "rb"),
],
prompt="""
Apply the artistic style from Image 2 to the subject in Image 1.
PRESERVE: subject's identity, pose, and composition
CHANGE: artistic style, color palette, texture treatment
Do not add new elements. Maintain subject likeness exactly.
"""
)
save_image(result, "styled_output.png")主要なAPIパラメータ
生成パラメータ
model
"gpt-image-1.5" — 最高の機能を備えた最新のフラッグシップモデル
prompt
テキスト記述 — 長さよりも構造が重要
quality
詳細とテキスト作業には"high"、速度と反復には"low"
n
生成するバリエーションの数(通常は1〜4、探索の場合はそれ以上)
編集パラメータ
image
ファイルオブジェクトまたは複数画像入力用のファイルオブジェクトのリスト
input_fidelity
"high"はアイデンティティ保持に、ポートレート作業に重要
価格に関する考慮事項
APIコスト構造
- トークンベースの価格設定: コストは解像度と品質設定によって異なります
- 1MP 高品質: 画像1,000枚あたり約133ドル
- 1MP 低品質: 画像1,000枚あたり約9ドル
- コスト削減: 画像の入出力コストはGPT Image 1より20%低い
大量のアプリケーションの場合は、常に低品質から始め、最終出力やテキストを多く含む画像の場合にのみアップグレードしてください。
他のツールとの比較
私は主要なAI画像生成ツールのそれぞれにかなりの時間を費やしてきました。ChatGPT画像ジェネレーター(GPT Image 1.5)が競合他社と比べてどうなのか、私の正直な評価は次のとおりです。
GPT Image 1.5 vs Gemini 3.0 Pro Image
GPT Image 1.5の勝利: 指示の順守(90% vs 77%)、テキストレンダリングの精度、精密編集、API統合の品質
Gemini 3.0 Proの勝利: 特定のベンチマークにおける全体的な画質、創造的な解釈、複雑な多キャラクターシーン
私の見解: 精度と一貫性を必要とするプロの仕事にはGPT Image 1.5。より多くの解釈が必要な創造的な探索にはGemini。
GPT Image 1.5 vs Midjourney
GPT Image 1.5の勝利: 指示に従うこと、画像編集機能、APIアクセス、テキストレンダリング、予測可能な結果
Midjourneyの勝利: 芸術的な美学と「驚き要素」、コミュニティと共有機能、絵画的なスタイル
私の見解: 特定の結果が必要なプロ/商業的な仕事にはGPT Image 1.5。芸術的な探索とコンセプトアートにはMidjourney。
GPT Image 1.5 vs DALL-E 3
GPT Image 1.5の勝利: 編集機能、速度(4倍速い)、反復間の一貫性、指示の順守
DALL-E 3の勝利: 特になし — GPT Image 1.5は後継であり、あらゆる次元で改善されています
私の見解: まだDALL-E 3を使用している場合は、すぐにアップグレードしてください。GPT Image 1.5の方が確実に優れています。
GPT Image 1.5 vs Stable Diffusion
GPT Image 1.5の勝利: 使いやすさ、セットアップ不要、指示に従うこと、テキストレンダリング、一貫した品質
Stable Diffusionの勝利: 完全なカスタマイズ、ローカルコントロール、無制限の無料生成、微調整、特殊なモデル
私の見解: 速度と簡単さにはGPT Image 1.5。制御、カスタマイズ、およびコスト意識の高い大量の作業にはStable Diffusion。
ベンチマークテストにおいて、GPT Image 1.5はArtificial Analysis Image Arenaのテキストから画像への生成と画像編集の両方のカテゴリで1位を獲得しました。正確な制御で信頼性の高い、予測可能な結果を必要とする制作作業において、現在利用可能な最良のオプションです。
正解は?最適なツールは特定のニーズによって異なります。私は複数のツールへのアクセスを維持しています。なぜなら、それぞれが異なる点で優れているからです。しかし、プロの仕事のために1つだけしか持てないとしたら、信頼性、精度、編集機能の点からGPT Image 1.5を選びます。
パワーユーザーの秘密
これらは、私を「まあまあ」から「プロ品質」の結果へと導いたヒントです。それぞれが広範な実験と、時には痛みを伴う失敗を通じて学んだものです。
新しいプロジェクトはクリーンな状態で開始する
新しいプロジェクトはすべて新しい会話で開始します。古いプロジェクトからのコンテキストが新しい生成に漏れ出し、予期しない結果を引き起こす可能性があります。クリーンな状態、クリーンな結果。
80/20の法則
最初の生成で80%正解させます。残りの20%には編集を使用します。1つのプロンプトで完璧を目指そうとすると、フラストレーションと時間の無駄につながります。
具体性が最上級に勝る
「Shot on medium format film with natural grain」は「ultra-high-quality amazing detailed」に毎回勝ちます。仕様はモデルを導きます。最上級は単にノイズを加えるだけです。
テキストを引用する
必要なテキストは常に「引用符」に入れ、「exactly once, no duplicates」と表示されるように指定します。これにより、テキストレンダリングを悩ませる重複やスペルミスを防ぎます。
否定形で終わる
すべてのプロンプトを、望まないもので終了します:「No watermarks, no text unless specified, no logos, no excessive saturation, no artificial bokeh.」予防は修正に勝ります。
勝者を保存する
良い結果が得られたら、画像だけでなく完全なプロンプトも保存します。将来のプロジェクトに適応できる実証済みのプロンプトの個人的なライブラリを構築します。
言い換える、繰り返さない
プロンプトが機能しない場合は、運を期待して再度実行しないでください。言い換えてください。異なる言葉はモデル内の異なるパターンを活性化します。アプローチを変えてください。
テキストには常に高品質
画像にテキスト(あらゆるテキスト)が含まれる場合は常に、高品質モードを使用してください。低品質のテキストはしばしば判読不能であり、速度の節約を無意味にします。
確率性の理解
ここに決定的なことがあります:AI画像生成は根本的に確率的です。同じプロンプトでも毎回異なる結果が生じる可能性があります。これはバグではありません — テクノロジーの性質です。
分散を受け入れる
ランダム性と戦うのではなく、それを利用してください。4つのバリエーションを生成し、最適なものを選択します。時には、「予期しない」解釈が、最初に想像していたよりも良い場所につながることがあります。私が知っている最高のAIアーティストは、目標を達成するための十分なコントロールを維持しながら、幸運な偶然に頼っています。変動性は機能であり、バグではありません。
一般的な問題のトラブルシューティング
何千もの生成を経て、私は考えられるあらゆる問題に遭遇しました。ここでは、クリエイターをイライラさせる最も一般的な問題を修正する方法を紹介します。
問題:テキストのスペルミスまたは重複
解決策
正確なテキストを引用符に入れます:「RESTAURANT」であり、restaurantではありません。明示的な指示を追加します:「render exactly once, no duplicates.」難しい単語の場合は、一文字ずつ綴ります:「R-E-S-T-A-U-R-A-N-T」。テキストを含む画像には常にquality="high"を使用してください。使用前に出力を確認してください。
問題:画像間でキャラクターが異なって見える
解決策
まず詳細なキャラクターアンカー画像を作成して保存します。このアンカーを後続の各生成の入力として含めます。各視覚的詳細をリストしたキャラクターバイブルを作成します。「maintain exact character appearance from reference image」と明示的に指示します。API呼び出しでinput_fidelity="high"を使用します。可能な場合は単一のセッション内で作業します。
問題:編集が要求以上に変更してしまう
解決策
保存についてより明確にします。プロンプトを「Change ONLY: [X]. Preserve EXACTLY: [list everything else in detail].」のように構成します。モデルは以前の制約を覚えていないため、編集の反復ごとに完全な保存リストを繰り返します。重要な要素にはinput_fidelity="high"を使用します。
問題:画像が明らかに「AI生成」に見える
解決策
リアルな不完全さを追加します:「subtle film grain」、「slight lens vignette」、「natural skin texture with pores and subtle blemishes」、「dust particles visible in sunbeam」、「minor wear on materials」。完璧さは偽物に見えます。現実は乱雑です。理想化されたバージョンではなく、カメラが実際に捉えるものを説明してください。
問題:色が過飽和または不自然に見える
解決策
色の扱いを明示的に指定します:「natural color grading」、「true-to-life colors」、「muted earth tones」、「not oversaturated」、「color-accurate」。色のガイダンスとして特定のフィルムタイプを参照します:「Kodak Portra color science」または「documentary color grading」。「realistic color balance, no HDR look」を追加します。
問題:背景削除がハローやアーティファクトを作成する
解決策
明示的に要求します:「transparent background (RGBA PNG format), crisp silhouette, no halos, no color fringing, clean edges, no artifacts」。現在のモデルは透明度を示すために市松模様をレンダリングすることに注意してください — 本番環境で真のアルファチャネルを使用するには後処理が必要になる場合があります。
問題:構図が不均衡またはぎこちなく感じる
解決策
構図を明示的に指定します:「subject positioned using rule of thirds」、「centered with symmetrical framing」、「generous negative space on left for text overlay」、「eye-level camera angle」、「subject fills 60% of frame」。構図を偶然に任せないでください — 欲しいものを正確に説明してください。
AI画像生成の未来
私たちは革命の中を生きています。2年前にはサイエンスフィクションだったものが、今では誰もがアクセスできる商品になりました。しかし、私たちはまだこの物語の初期の章にいます。これから起こると私が考えていることは次のとおりです。
地平線上にあるもの
🎬 シームレスなビデオ統合
静止画とビデオの境界線は急速に曖昧になっています。同じインターフェース内で、画像生成からアニメーションシーケンスへのスムーズな移行が期待されます。初期バージョンはすでにここにあり(Sora、Runway)、急速に改善されています。あなたの画像プロンプトは、最小限の調整でビデオプロンプトになります。
🎯 完璧な一貫性
手作業なしで、無制限の画像にわたるキャラクターとスタイルの一貫性。アンカーと参照のワークフローは自動化されます。キャラクターの例をいくつかモデルにトレーニングさせれば、それは永遠に完璧な一貫性を維持します。「ドリフト」の問題は完全に解決されます。
✏️ リアルタイムコラボレーション編集
リアルタイムで会話しながら要素をペイント、ドラッグ、操作するインタラクティブな編集。ブラシストロークごとにAIの反応がトリガーされ、複雑な編集が技術的なツールではなく会話を通じて行われるPhotoshopを想像してください。
🎨 パーソナライズされたスタイル学習
ほんの一握りの例であなたの美学をモデルにトレーニングさせます。あなたの好み、ブランド、視覚言語を理解し、それをあなたが作成するすべてのものに一貫して適用する、あなただけの個人的なAIアーティストです。
視覚的創造の民主化
私たちが目撃しているのは、視覚的創造の民主化にほかなりません。かつては何年ものトレーニングを必要としたスキル — 製品写真、グラフィックデザイン、イラストレーション、コンセプトアート — が、見たいものを説明できる人なら誰でも利用できるようになりつつあります。
これは人間の創造性の価値をなくすものではありません。どちらかといえば、それを高めます。実行が容易になると、ビジョンがすべてになります。この新しい風景で成功する人々は、最もリアルな手をレンダリングできる人々ではありません — AIがそれを処理します。それは、言うべき価値のある何か、見せるべき価値のある何か、人々を動かす何かを持っている人々です。
フィルムからデジタルへの移行で成功した写真家は、変化に抵抗した人々ではありませんでした。彼らは、芸術的なビジョンを維持しながら新しいツールを受け入れた人々でした。AI画像生成は同じ種類の移行ですが、より劇的で高速です。
最高のAI生成画像は、常にテクノロジーと芸術の両方を理解している人間によって作成されます。ツールをマスターしてください。しかし、ツールはビジョンに奉仕するものであることを決して忘れないでください。テクノロジーは人間の創造性を増幅させます — それを置き換えるものではありません。
最後に
サムネイル、グラフィック、ソーシャルコンテンツを数時間ではなく数分で作成
かつてない規模での製品写真、バリエーション、マーケティング
以前は数日かかっていた迅速なコンセプト開発とクライアントプレゼンテーション
画像対応アプリケーションを構築するための堅牢なプログラムによるアクセス
自然言語により、従来のデザインツールよりも参入が容易
商業的な仕事に十分な品質と一貫性
私はフラストレーションと懐疑心を持ってこの旅を始めました。AI画像生成の誇大宣伝を聞いていましたが、マーケティングの約束と実際の現実との間の壁に繰り返しぶつかりました。ありえない解剖学的構造の指。抽象的な形に溶けるテキスト。私の意図に積極的に反撃する構図。私はそれをすべて過大評価されたテクノロジーとして却下する準備ができていました。
そして、私は機械の言語を話すことを学びました。見たいものを説明するのをやめ、カメラが何を捉えるかを説明し始めました。運を期待するのをやめ、体系的に構築し始めました。モデルと戦うのをやめ、協力し始めました。
GPT Image 1.5は以前の問題を改善しただけでなく、私の視覚的創造との関係を根本的に変えました。私は今、ブラシやレイヤーではなく、プロンプトと反復という観点で考えています。私は、必要なものを生成するプロンプト構造があると確信して、視覚的な課題にアプローチします。私が今日作成する画像は、わずか2年前には作成に数日かかっていたでしょう。私が探求できるアイデアは、技術的なスキルではなく、想像力によってのみ制限されます。
学習曲線は本物です。一夜にしてこれをマスターすることはできません。しかし、このガイドの原則 — キーワードよりも構造、最上級よりも具体性、完璧さよりも反復、写真撮影のマインドセット — は、数週間のイライラする実験を、集中的で生産的な学習に凝縮します。
何よりも、このガイドが、私が始めたときに持っていたかったもの、つまり単なるテクニックではなく、メンタルモデルを提供してくれることを願っています。このテクノロジーがどのように言語を解釈し、何に反応し、その視覚言語を流暢に話す方法についての理解です。
あなたの心の中にある画像と画面上の画像の間のギャップは、かつてないほど小さくなっています。そして、正しいアプローチをとれば、あなたが書くプロンプトごとにそのギャップは縮まり続けます。
さあ、外に出て何か美しいものを作りましょう。
深夜2時のあの瞬間、すべてがカチッとはまったときのことを覚えています — 現れた画像が単に許容範囲内というだけでなく、まさに私が想像していたものであったときのこと。その感覚は今、あなたにも手に入ります。テクノロジーは到着しました。テクニックは文書化されました。残っているのは、あなたの想像力と、新しい言語を学ぶ意欲だけです。ChatGPT画像ジェネレーターは単なるツールではありません — それは、私たちが理解し始めたばかりの方法で人間の視覚を増幅するクリエイティブなパートナーです。視覚的創造の未来へようこそ。あなたが心の中で見てきた画像?それらはかつてないほど現実に近づいています。

ディスカッション
0 コメントコメントを残す
この記事についてご感想をお聞かせください!