A diferença entre imagens de IA frustrantes e imagens de tirar o fôlego não é talento ou sorte — é aprender a falar a linguagem visual que a máquina entende.
Ainda me lembro do momento exato em que tudo mudou. Eram 2 da manhã de uma terça-feira. Eu estava olhando para a tela há horas, passando por prompt após prompt, assistindo o ChatGPT cuspir imagens que não se pareciam em nada com o que eu havia imaginado. Dedos com anatomia impossível. Texto que derretia em rabiscos. Personagens que pareciam resistir ativamente às minhas intenções. Eu estava pronto para desistir completamente da geração de imagens por IA — para descartá-la como tecnologia exagerada que só funcionava para outras pessoas.
Então tentei algo diferente. Em vez de descrever o que eu queria ver, descrevi o que uma câmera capturaria. Em vez de pedir "um lindo pôr do sol", escrevi "luz da hora dourada fluindo através dos picos das montanhas, fotografado na Canon 5D Mark IV, lente 24-70mm em f/2.8, gradação de cores natural". A imagem que apareceu não foi apenas aceitável — foi impressionante. Fotorrealista. Exatamente o que existia apenas na minha imaginação momentos antes.
Essa única mudança de perspectiva desbloqueou tudo. Nos meses seguintes, mergulhei fundo. Gerei milhares de imagens. Testei todas as técnicas que pude encontrar. Li a documentação da OpenAI de capa a capa. Experimentei o GPT Image 1.5 no dia em que foi lançado. E agora vou compartilhar tudo o que aprendi — não as dicas superficiais que você encontrará em qualquer outro lugar, mas o conhecimento profundo que separa os profissionais dos amadores. Este é o guia que eu gostaria que existisse quando comecei. É assim que você passa de iniciante frustrado a criador confiante.
Minha Jornada na Geração de Imagens por IA
Deixe-me levá-lo de volta para onde tudo começou. Como muitos de vocês lendo isso, eu estava inicialmente cético sobre a geração de imagens por IA. "É apenas um brinquedo para entusiastas de tecnologia", pensei. "Trabalho criativo real ainda requer habilidades reais." Eu não poderia estar mais errado.
Minha primeira necessidade real de imagens de IA veio de um problema prático. Eu estava criando conteúdo para um projeto e precisava de imagens de capa — muitas delas. Eu estava pagando por fotos de banco de imagens, gastando dinheiro em fotos genéricas que todos os outros criadores também estavam usando. As imagens eram boas, mas faltavam alma. Elas pareciam emprestadas, não possuídas.
Um amigo mencionou que o ChatGPT poderia gerar imagens agora. "Apenas descreva o que você quer", disse ela. "É como mágica." Então eu tentei. Meu primeiro prompt foi embaraçosamente ingênuo: "Um lindo pôr do sol sobre as montanhas." O resultado? Uma bagunça borrada que parecia uma pintura em aquarela deixada na chuva. Fiquei desapontado, para dizer o mínimo.
Mas algo continuava me puxando de volta. Tentei novamente. E novamente. Cada falha me ensinava algo novo sobre como a IA interpretava a linguagem. Comecei a notar padrões — certas frases que consistentemente produziam melhores resultados, abordagens estruturais que guiavam o modelo em direção à minha visão, em vez de afastá-lo.
A descoberta veio quando percebi: a geração de imagens por IA não é sobre descrever o que você vê em sua mente — é sobre descrever o que uma câmera capturaria na realidade. Essa única mudança de perspectiva mudou tudo.
Parei de pensar como um sonhador e comecei a pensar como um fotógrafo. Em vez de "lindo pôr do sol", escrevi sobre luz da hora dourada, modelos de câmera específicos, distâncias focais de lente, configurações de abertura, tipos de filme. A IA entendeu essa linguagem porque foi treinada em milhões de imagens que vinham com exatamente esse tipo de metadados técnicos.
Nos meses seguintes, fiquei obcecado. Gerei milhares de imagens em todos os estilos e casos de uso que pude imaginar. Li cada peça de documentação que a OpenAI publicou. Juntei-me a comunidades de criadores empurrando os limites do que era possível. E quando o GPT Image 1.5 foi lançado em janeiro de 2026, eu estava pronto. Eu entendia não apenas como usá-lo, mas por que ele funcionava daquela maneira.
Agora vou compartilhar tudo o que aprendi. Não as dicas superficiais que você encontrará em uma centena de outros guias. O conhecimento profundo que vem de extensa experimentação, testes sistemáticos e inúmeras conversas com outros criadores que estão levando essas ferramentas aos seus limites. Este é o guia completo — aquele que o levará de iniciante confuso a criador confiante.
O Que é o Gerador de Imagens do ChatGPT
Antes de mergulharmos nas técnicas, deixe-me esclarecer exatamente com o que estamos trabalhando. O gerador de imagens do ChatGPT é o sistema integrado de criação e edição de imagens da OpenAI, atualmente alimentado pelo modelo GPT Image 1.5. Ao contrário de ferramentas independentes como Midjourney ou Stable Diffusion, ele é profundamente integrado à interface de conversação do ChatGPT.
Essa integração importa mais do que você imagina. Porque o ChatGPT entende o contexto, ele pode manter a consistência em várias gerações, lembrar suas preferências dentro de uma sessão e até mesmo raciocinar sobre o que você está tentando criar. Diga a ele que você está trabalhando em um livro infantil, e ele ajusta seu estilo de acordo. Mencione que você precisa de imagens para uma apresentação corporativa, e ele muda para uma estética limpa e profissional. Essa consciência contextual é algo que geradores de imagens independentes simplesmente não conseguem igualar.
🎨 Geração de Texto-para-Imagem
Descreva qualquer coisa em linguagem natural e veja se materializar. De retratos fotorrealistas a arte abstrata, de modelos de produtos a paisagens de fantasia — se você pode descrever, a IA pode criar.
✏️ Edição de Imagem de Precisão
Faça upload de imagens existentes e modifique-as com comandos de texto. Mude cores, troque objetos, ajuste a iluminação, transforme estações ou reimagined completamente a cena preservando elementos que você deseja manter.
🔄 Transferência de Estilo
Pegue a linguagem visual de uma imagem — sua paleta, textura, pincelada ou estética — e aplique-a a um conteúdo totalmente novo. Perfeito para manter a consistência da marca ou criar séries coesas.
📝 Renderização de Texto Confiável
Finalmente, IA que realmente sabe soletrar. O GPT Image 1.5 lida com texto em imagens com precisão sem precedentes — perfeito para logotipos, pôsteres, infográficos e materiais de marketing onde as palavras importam.
Como Realmente Funciona
Quando você envia um prompt para o gerador de imagens do ChatGPT, várias coisas acontecem nos bastidores. Primeiro, o próprio ChatGPT processa sua solicitação, potencialmente expandindo ou esclarecendo seu prompt com base no contexto. Ele pode adicionar detalhes que você insinuou, mas não declarou, ou estruturar sua solicitação de uma maneira que o modelo de imagem entenda melhor.
Em seguida, a solicitação vai para o modelo de geração de imagens — atualmente GPT Image 1.5 — que transforma sua descrição de texto em saída visual. Este modelo foi treinado em um enorme conjunto de dados de imagens emparelhadas com descrições detalhadas, aprendendo as intrincadas relações entre linguagem e elementos visuais.
O resultado é um sistema que genuinamente entende o que você está pedindo, não apenas combinando padrões de palavras-chave. Peça um "momento espontâneo fotorrealista" e você terá algo que genuinamente parece não posado. Peça "luz da manhã através de persianas venezianas" e você terá o padrão de listras específico que isso cria.
O GPT Image 1.5 alcançou o primeiro lugar na Artificial Analysis Image Arena tanto para geração de texto-para-imagem quanto para edição de imagens, com uma taxa de conformidade de instrução de 90% — 13 pontos percentuais a mais que seu concorrente mais próximo. Isso não é conversa de marketing; reflete um salto genuíno em capacidade.
A Revolução do GPT Image 1.5
Quando a OpenAI lançou o GPT Image 1.5 em janeiro de 2026, eles não apenas iteraram em seu modelo anterior — eles reconstruíram a base. Eu vinha usando versões anteriores extensivamente, então notei imediatamente a diferença. Esta não foi uma melhoria incremental; foi uma mudança de paradigma.
Deixe-me ser específico sobre o que mudou, porque entender essas melhorias o ajudará a aproveitá-las efetivamente.
Os Três Avanços Que Importam
Modelos anteriores tinham uma tendência frustrante de derivar. Você pedia para mudar uma coisa, e três outras coisas mudavam inesperadamente. Conserte a iluminação, e de repente o rosto do personagem parecia diferente. O GPT Image 1.5 entende genuinamente "mude apenas este elemento" — ele pode modificar partes específicas preservando iluminação, composição, características faciais, até mesmo texturas sutis. Isso torna o refinamento iterativo realmente prático.
A velocidade de geração aumentou até 400% em comparação com versões anteriores. O que costumava levar 30 segundos agora leva 7-8. Mas, mais importante, você pode enfileirar novas gerações enquanto as atuais ainda estão processando. Isso transforma o processo criativo de "enviar e esperar" para "explorar e iterar". A diferença psicológica é significativa — loops de feedback mais rápidos significam mais experimentação.
A renderização de texto em imagens de IA tem sido historicamente um desastre — erros de ortografia, duplicações, letras que derretem em formas abstratas. O GPT Image 1.5 lida com texto denso e pequeno, mantendo tipografia, layout e legibilidade adequados. Isso abre infográficos, materiais de marketing, maquetes de interface do usuário e qualquer caso de uso em que palavras apareçam em imagens. Pela primeira vez, posso gerar slides de apresentação, gráficos de mídia social com legendas e rótulos de produtos que eu realmente usaria.
Entendendo as Configurações de Qualidade
O GPT Image 1.5 oferece diferentes níveis de qualidade, e entender quando usar cada um economizará tempo e melhorará seus resultados. Não se trata apenas de qualidade de saída — trata-se de combinar a ferramenta certa com a tarefa certa.
⚡ Modo de Baixa Qualidade (Low Quality)
Não deixe o nome te enganar — "baixa qualidade" aqui significa "rápido e eficiente". Os resultados ainda são notavelmente bons para a maioria dos casos de uso. Use isso para:
- Exploração de conceito inicial e brainstorming
- Iterações rápidas ao refinar ideias
- Composições simples sem detalhes finos
- Geração de alto volume onde a velocidade importa
- Rascunhos antes de se comprometer com versões finais
✨ Modo de Alta Qualidade (High Quality)
Quando cada pixel importa e você precisa de resultados prontos para publicação. Reserve isso para:
- Imagens finais de produção para entrega
- Trabalho denso de texto e tipografia
- Infográficos complexos com pequenos detalhes
- Retratos fotorrealistas onde a textura importa
- Qualquer imagem onde você precise de fidelidade máxima
A Configuração Oculta de Fidelidade de Entrada
Aqui está algo que a maioria dos guias não lhe dirá: ao editar imagens, há um parâmetro chamado input_fidelity que afeta drasticamente os resultados. Defina-o como "high" (alto) quando precisar preservar características faciais, manter a identidade em edições ou fazer alterações significativas na cena. O modelo trabalha mais para manter as características-chave da imagem original.
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # O molho secreto para preservação de identidade
quality="high",
image=[open("portrait.png", "rb")],
prompt="Change the background to a sunset beach while preserving the person's exact appearance"
)Essa combinação garante a preservação máxima do sujeito original enquanto aplica as alterações solicitadas.
A maior mudança com o GPT Image 1.5 não é técnica — é filosófica. A geração de imagens muda de "prompt e orar" para "instruir e iterar". Isso requer um modelo mental completamente diferente para como você aborda a criação visual.
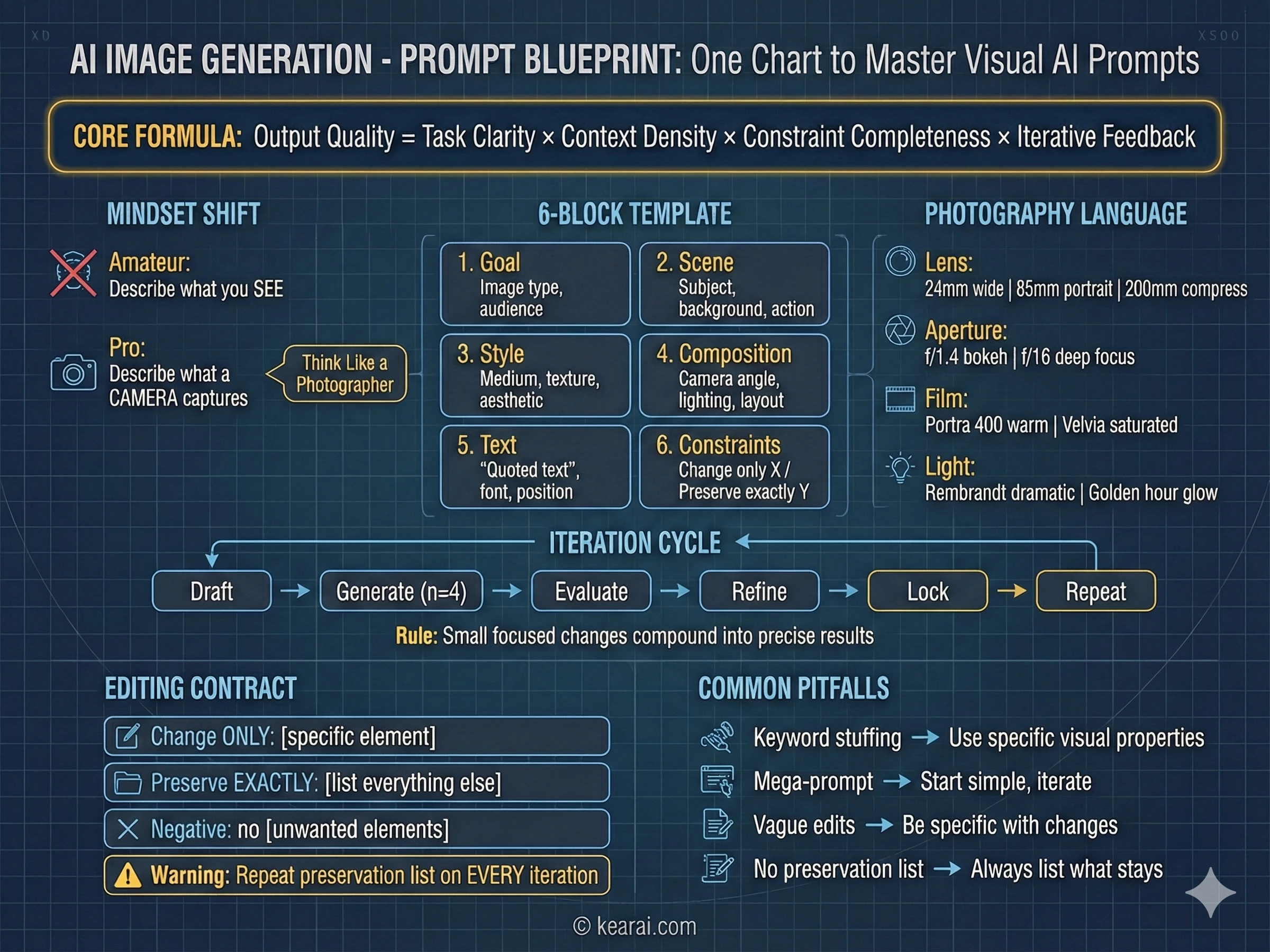
O Framework de Prompt Que Mudou Tudo
Depois de gerar milhares de imagens, desenvolvi um framework que produz consistentemente resultados excepcionais. Esqueça tudo o que você leu sobre adicionar "obra-prima (masterpiece), tendência no ArtStation (trending on ArtStation), ultra-detalhado (ultra-detailed), resolução 8K" aos seus prompts. Essas palavras-chave funcionavam para modelos mais antigos que precisavam de dicas de qualidade, mas o GPT Image 1.5 responde à estrutura e especificidade, não ao preenchimento de palavras-chave.
Eu chamo isso de arquitetura de prompt estruturada, e todo prompt eficaz que escrevo agora segue esse padrão.
Goal/Output (Objetivo/Saída):
- [Type of image: ad, UI mockup, infographic, photo, illustration] (Tipo de imagem: anúncio, maquete de UI, infográfico, foto, ilustração)
- [Intended use and audience] (Uso pretendido e público)
Scene (Cena):
- [Background/environment description] (Descrição do fundo/ambiente)
- [Main subject with specific details] (Assunto principal com detalhes específicos)
- [Action or relationship between elements] (Ação ou relacionamento entre elementos)
Style (Estilo):
- [Medium: photograph, watercolor, 3D render, vector illustration] (Meio: fotografia, aquarela, renderização 3D, ilustração vetorial)
- [Key textures: matte, glossy, grainy, smooth, organic] (Texturas principais: fosco, brilhante, granulado, suave, orgânico)
- [Quality descriptors: realistic imperfections, stylized, minimalist] (Descritores de qualidade: imperfeições realistas, estilizado, minimalista)
Composition/Layout (Composição/Layout):
- [Camera position: close-up, wide shot, aerial view, eye-level] (Posição da câmera: close-up, plano aberto, vista aérea, nível dos olhos)
- [Lighting: golden hour, studio strobes, overcast, dramatic shadows] (Iluminação: hora dourada, estroboscópios de estúdio, nublado, sombras dramáticas)
- [Element placement: centered, rule of thirds, negative space, margins] (Colocação de elementos: centralizado, regra dos terços, espaço negativo, margens)
Text (if any) (Texto, se houver):
- "Exact text in quotes" ("Texto exato entre aspas")
- [Font style, size, color, position] (Estilo da fonte, tamanho, cor, posição)
- [Specify: render only once, no duplicates] (Especifique: renderizar apenas uma vez, sem duplicatas)
Constraints (Restrições):
- Change ONLY: [specific element if editing] (Mudar APENAS: [elemento específico se estiver editando])
- Preserve exactly: [elements that must stay unchanged] (Preservar exatamente: [elementos que devem permanecer inalterados])
- Negative: no watermark, no extra text, no logos, no [unwanted elements] (Negativo: sem marca d'água, sem texto extra, sem logotipos, sem [elementos indesejados])Este framework fornece ao modelo um contexto claro para cada decisão visual que ele precisa tomar.
Os Sete Princípios de Prompting Eficaz
Além da estrutura, esses princípios governam como escrevo cada prompt. Eles são a diferença entre imagens que quase funcionam e imagens que acertam em cheio sua visão.
Estrutura Sobre Palavras-chave
Use uma ordem consistente: fundo → assunto → detalhes → restrições. Para solicitações complexas, use seções rotuladas ou quebras de linha. Parágrafos longos confundem o modelo; estrutura organizada o guia em direção à sua intenção.
Especificidade Sobre Superlativos
Em vez de "alta qualidade" ou "ultra-detalhado", descreva propriedades visuais reais. Materiais, texturas, formas, meios. "Poros da pele visíveis e sardas sutis" vence "rosto altamente detalhado" todas as vezes.
Controle Explícito de Composição
Nomeie seu enquadramento (close-up, plano aberto, olho de pássaro), perspectiva (nível dos olhos, ângulo baixo, ângulo holandês) e clima de iluminação (difusa suave, hora dourada, luz de borda de alto contraste). Não deixe isso ao acaso.
O Contrato Mudar vs. Preservar
Para edição, declare explicitamente o que deve mudar E o que deve permanecer intocado. Use "change only X" (mudar apenas X) e "preserve exactly Y" (preservar exatamente Y). Repita esta lista de preservação em cada iteração para evitar deriva.
Texto Exige Precisão
Coloque o texto necessário em "aspas" ou TUDO MAIÚSCULO. Especifique estilo da fonte, tamanho, cor e posição. Para palavras difíceis ou nomes de marcas, soletre letra por letra. Sempre adicione "render exactly once, no duplicates" (renderizar exatamente uma vez, sem duplicatas).
Clareza de Referência Multi-Imagem
Ao trabalhar com várias imagens de entrada, referencie cada uma por índice e descrição: "Image 1: the product shot, Image 2: the style reference" (Imagem 1: a foto do produto, Imagem 2: a referência de estilo). Declare explicitamente como elas devem interagir.
Iterar em Vez de Sobrecarregar
Comece com um prompt base limpo, depois refine com pequenos acompanhamentos de mudança única. "Torne a iluminação mais quente." "Remova a árvore de fundo." Pequenos passos se somam em resultados precisos.
O Erro Mais Comum
O maior erro que vejo as pessoas cometerem: tentar especificar tudo em um prompt massivo, esperando que o modelo descubra. Isso quase nunca funciona bem. Comece com um prompt mais simples para estabelecer a base, depois itere com refinamentos direcionados. Você obterá melhores resultados em menos tempo com muito menos falhas frustrantes.
A Mentalidade Fotográfica
A maior melhoria individual nos meus resultados veio de uma mudança mental: parei de pensar como um artista descrevendo uma visão e comecei a pensar como um fotógrafo descrevendo uma foto. Isso não é apenas uma metáfora — é uma técnica prática que aproveita como o modelo foi treinado.
Modelos de imagem de IA aprenderam com milhões de fotografias que vieram com metadados: modelos de câmera, especificações de lente, configurações de abertura, condições de iluminação. Quando você usa essa linguagem, está ativando a compreensão profunda do modelo de como câmeras reais capturam cenas reais.
Linguagem Fotográfica Que Funciona
- Escolha da lente: "24mm wide angle" (grande angular 24mm) cria cenas expansivas com distorção nas bordas; "200mm telephoto" (teleobjetiva 200mm) comprime a profundidade e isola os assuntos
- Sensação de abertura: "f/1.4 bokeh" dá desfoque de fundo cremoso para retratos; "f/16 deep focus" (foco profundo f/16) mantém tudo nítido para paisagens
- Tipos de filme: "Kodak Portra 400" para tons de pele quentes e lisonjeiros; "Fuji Velvia" para paisagens vibrantes e saturadas; "Ilford HP5" para preto e branco contrastante
- Configurações de iluminação: "Rembrandt lighting" (iluminação Rembrandt) para retratos dramáticos; "butterfly lighting" (iluminação borboleta) para fotos de beleza; "golden hour backlight" (luz de fundo da hora dourada) para bordas brilhantes etéreas
- Movimento da câmera: "long exposure motion blur" (desfoque de movimento de longa exposição) para energia dinâmica; "high-speed freeze frame" (congelamento de alta velocidade) para capturar ação
Em vez de dizer "faça parecer profissional", tente "shot on Hasselblad medium format, studio strobe lighting, seamless gray backdrop, color-calibrated for print reproduction" (fotografado em formato médio Hasselblad, iluminação estroboscópica de estúdio, fundo cinza sem costura, calibrado por cores para reprodução de impressão). Em vez de "retrato realista", tente "candid photograph, 85mm f/1.4 lens, window light from camera left, subtle fill from reflector, visible skin texture with pores, shot on Sony A7R IV" (fotografia espontânea, lente 85mm f/1.4, luz da janela da esquerda da câmera, preenchimento sutil do refletor, textura da pele visível com poros, fotografado na Sony A7R IV).
❌ BEFORE (Vago):
"A beautiful portrait of an old fisherman, very detailed, high quality, realistic"
(Um lindo retrato de um velho pescador, muito detalhado, alta qualidade, realista)
✅ AFTER (Mentalidade Fotográfica):
"Candid documentary photograph of an elderly fisherman on a weathered wooden boat.
Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind eyes.
Gray stubble. Faded traditional anchor tattoo on forearm. Salt-stained navy wool
sweater, worn cap.
Early morning coastal light, soft fog diffusing the sun. Medium close-up at eye
level, 50mm lens, f/2.8, shallow depth of field. Shot like 35mm film with subtle
grain, natural color balance.
Documentary style — honest, unretouched, capturing a real moment. No glamorization."
(Fotografia documental espontânea de um pescador idoso em um barco de madeira desgastado.
Rosto curtido com rugas visíveis, manchas de sol e poros. Olhos gentis e profundos.
Barba por fazer grisalha. Tatuagem de âncora tradicional desbotada no antebraço.
Suéter de lã azul marinho manchado de sal, boné gasto.
Luz costeira do início da manhã, neblina suave difundindo o sol. Close-up médio ao
nível dos olhos, lente 50mm, f/2.8, profundidade de campo rasa. Fotografado como filme
35mm com grão sutil, equilíbrio de cores natural.
Estilo documental — honesto, sem retoques, capturando um momento real. Sem glamometrização.)A mentalidade fotográfica transforma desejos vagos em especificações visuais precisas que o modelo entende profundamente.
Quando você descreve imagens usando linguagem fotográfica, você não está apenas sendo mais específico — você está falando uma linguagem que o modelo foi treinado para entender. Especificações da câmera, configurações de iluminação e tipos de filme não são palavras-chave arbitrárias; eles codificam informações visuais precisas que o modelo pode decodificar com precisão.
Domínio de Texto-para-Imagem
Criar imagens a partir de descrições de texto puro é onde a maioria das pessoas começa sua jornada de imagem de IA. É também onde a lacuna entre resultados amadores e profissionais é mais visível. Deixe-me guiá-lo pelas técnicas que produzem resultados consistentemente excelentes em diferentes casos de uso.
Imagens Fotorrealistas Que Parecem Naturais
A chave para o fotorrealismo é contraintuitiva: você precisa solicitar imperfeição. Pele perfeita, iluminação perfeita, composição perfeita — isso grita "gerado por IA". A realidade é mais bagunçada, e essa bagunça é o que faz as imagens parecerem autênticas.
Create a photorealistic candid photograph of an elderly sailor standing on a small fishing boat.
(Crie uma fotografia espontânea fotorrealista de um marinheiro idoso em pé em um pequeno barco de pesca.)
Subject: Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind
eyes with crow's feet. Gray stubble, a few days unshaven. Faded traditional anchor
tattoo on forearm. Salt-stained navy wool sweater, worn and pilled. Creased cap
with faded insignia.
(Sujeito: Rosto curtido com rugas visíveis, manchas de sol e poros. Olhos gentis e profundos com pés de galinha. Barba por fazer grisalha, alguns dias sem barbear. Tatuagem de âncora tradicional desbotada no antebraço. Suéter de lã azul marinho manchado de sal, gasto e com bolinhas. Boné amassado com insígnia desbotada.)
Setting: Early morning on the water, soft coastal fog diffusing the light. Aged
wooden boat deck with peeling paint, fishing nets in background, coiled rope.
(Cenário: Início da manhã na água, neblina costeira suave difundindo a luz. Convés de barco de madeira envelhecido com tinta descascando, redes de pesca ao fundo, corda enrolada.)
Technical: Shot like 35mm film photography, medium close-up at eye level, 50mm
lens, shallow depth of field with boat blurred behind him. Subtle film grain,
natural color balance without heavy grading.
(Técnico: Fotografado como fotografia de filme 35mm, close-up médio ao nível dos olhos, lente 50mm, profundidade de campo rasa com barco desfocado atrás dele. Grão de filme sutil, equilíbrio de cores natural sem gradação pesada.)
The image should feel like a real moment captured by a photojournalist — honest,
unposed, with real skin texture, worn materials, and everyday imperfection. No
glamorization, no heavy retouching, no artificial perfection.
(A imagem deve parecer um momento real capturado por um fotojornalista — honesto, não posado, com textura de pele real, materiais gastos e imperfeição cotidiana. Sem glamometrização, sem retoques pesados, sem perfeição artificial.)Observe como solicitamos explicitamente imperfeições — pele curtida, materiais gastos, tinta descascando. A realidade tem textura.
Infográficos e Visualização de Dados
A renderização de texto aprimorada no GPT Image 1.5 torna os infográficos um caso de uso genuinamente prático. Agora crio gráficos de informações de qualidade profissional que realmente uso no meu trabalho.
Create a detailed infographic explaining how a coffee machine works.
(Crie um infográfico detalhado explicando como funciona uma máquina de café.)
Structure (Estrutura):
- Title at top: "The Journey of Your Morning Coffee" (Título no topo: "A Jornada do Seu Café da Manhã")
- Vertical flow diagram showing: bean hopper → grinder → portafilter →
grouphead → water heating → extraction → cup
(Diagrama de fluxo vertical mostrando: funil de grãos → moedor → porta-filtro → cabeça do grupo → aquecimento de água → extração → xícara)
- Each step has an icon and 1-2 sentence explanation (Cada etapa tem um ícone e explicação de 1-2 frases)
- Warm color palette (browns, creams, copper accents) (Paleta de cores quentes: marrons, cremes, detalhes em cobre)
- Clean, modern design with plenty of white space (Design limpo e moderno com bastante espaço em branco)
- Subtle coffee stain texture in background corners (Textura sutil de mancha de café nos cantos do fundo)
Style (Estilo): Professional print-quality infographic, vector-style icons, clear
hierarchy, readable at A4 size. (Infográfico de qualidade de impressão profissional, ícones estilo vetorial, hierarquia clara, legível em tamanho A4.)
Typography (Tipografia): Clean sans-serif headings, readable body text, clear visual
hierarchy between title, section headers, and explanatory text. (Títulos sem serifa limpos, texto do corpo legível, hierarquia visual clara entre título, cabeçalhos de seção e texto explicativo.)
No watermarks. No stock photo elements. Original illustration only. (Sem marcas d'água. Sem elementos de banco de imagens. Apenas ilustração original.)Para texto denso e layouts complexos, sempre use quality="high" para garantir que o texto permaneça nítido e legível.
Design de Logotipo e Marca
A geração de logotipo requer priorizar a simplicidade e a escalabilidade. Um ótimo logotipo funciona em qualquer tamanho, de um pequeno favicon a um outdoor enorme. Veja como solicitar designs que realmente funcionem como logotipos.
Create an original logo for "Field & Flour" — a local artisan bakery.
(Crie um logotipo original para "Field & Flour" — uma padaria artesanal local.)
Brand personality: Warm, authentic, handcrafted, timeless. Not trendy or corporate.
(Personalidade da marca: Quente, autêntica, artesanal, atemporal. Não moderna ou corporativa.)
Design requirements (Requisitos de design):
- Clean vector-style shapes with strong silhouette (Formas limpas estilo vetorial com silhueta forte)
- Balanced negative space (Espaço negativo equilibrado)
- Must read clearly from 16px favicon to large signage (Deve ser lido claramente de favicon 16px a sinalização grande)
- Flat design, minimal strokes, no gradients unless essential (Design plano, traços mínimos, sem gradientes a menos que essencial)
- Earth-tone palette: warm wheat gold, deep brown, cream (Paleta de tons terrosos: ouro trigo quente, marrom profundo, creme)
- Could incorporate subtle wheat or grain element (Poderia incorporar elemento sutil de trigo ou grão)
- Text must be perfectly legible and properly kerned (O texto deve ser perfeitamente legível e com kerning adequado)
Output: Single centered logo on plain cream background. Generous padding around
the design for flexibility. (Saída: Logotipo único centralizado em fundo creme simples. Preenchimento generoso ao redor do design para flexibilidade.)
No watermarks, no mockups, no 3D effects, no complex imagery. Simple, functional,
timeless design. (Sem marcas d'água, sem maquetes, sem efeitos 3D, sem imagens complexas. Design simples, funcional e atemporal.)Use n=4 para gerar múltiplas variações. O design de logotipo é subjetivo — dê a si mesmo opções para escolher.
Maquetes de UI e App
Para design de UI, descreva a interface como se ela já existisse e estivesse sendo enviada para usuários reais. Linguagem de arte conceitual produz arte conceitual. Linguagem de produto produz maquetes utilizáveis.
Create a realistic mobile app UI mockup for a local farmers market app.
(Crie uma maquete realista de UI de aplicativo móvel para um aplicativo de mercado de agricultores local.)
Screen content (from top) (Conteúdo da tela (de cima)):
- Simple header with market name "Riverside Market" and search icon (Cabeçalho simples com nome do mercado "Riverside Market" e ícone de pesquisa)
- Today's featured vendor carousel with square photos (Carrossel de fornecedores em destaque de hoje com fotos quadradas)
- "Fresh Today" section with produce category chips (Vegetables, Fruits, Dairy, Baked) (Seção "Fresh Today" com chips de categoria de produtos (Legumes, Frutas, Laticínios, Assados))
- Vendor list with small photos, names, specialties, and distance (Lista de fornecedores com pequenas fotos, nomes, especialidades e distância)
- Bottom navigation: Home, Map, Favorites, Cart, Profile (Navegação inferior: Início, Mapa, Favoritos, Carrinho, Perfil)
Design language (Linguagem de design):
- White background, subtle natural green accents (Fundo branco, detalhes em verde natural sutis)
- Clear typography hierarchy (system fonts feel) (Hierarquia de tipografia clara (sensação de fontes do sistema))
- Generous padding and touch-friendly targets (Preenchimento generoso e alvos amigáveis ao toque)
- Looks like a real shipped product, not a concept (Parece um produto real enviado, não um conceito)
- Uses realistic vendor names and produce photos (Usa nomes de fornecedores realistas e fotos de produtos)
Frame: Place the UI inside an iPhone 15 Pro device frame, slight perspective
tilt, subtle shadow beneath. (Moldura: Coloque a UI dentro de uma moldura de dispositivo iPhone 15 Pro, leve inclinação de perspectiva, sombra sutil abaixo.)Concentre-se no layout, hierarquia, espaçamento e elementos de interface realistas. Evite linguagem conceitual ou artística.
Tiras de Quadrinhos e Arte Sequencial
Criar quadrinhos de vários painéis requer definir a narrativa como uma sequência de batidas visuais claras, uma por painel. Mantenha as descrições concretas e focadas na ação.
Create a 4-panel vertical comic strip. Equal panel sizes, clear panel borders.
(Crie uma tira de quadrinhos vertical de 4 painéis. Tamanhos de painel iguais, bordas de painel claras.)
Panel 1: Pet owner walks out the front door, keys in hand. Through the window
behind them, we see their cat watching — paws pressed against glass, eyes wide
with apparent sadness. The house suddenly feels empty.
(Painel 1: O dono do animal sai pela porta da frente, chaves na mão. Pela janela atrás deles, vemos seu gato observando — patas pressionadas contra o vidro, olhos arregalados com aparente tristeza. A casa de repente parece vazia.)
Panel 2: The door clicks shut. The cat slowly turns away from the window toward
the empty house. Its posture shifts from forlorn to interested. Eyes narrow with
possibility.
(Painel 2: A porta se fecha. O gato lentamente se afasta da janela em direção à casa vazia. Sua postura muda de desolada para interessada. Olhos se estreitam com possibilidade.)
Panel 3: Total chaos. Cat sprawled across the forbidden couch like royalty.
Knocked over plant on the floor. Papers scattered. Sunbeam spotlighting the
scene of domestic crime.
(Painel 3: Caos total. Gato esparramado no sofá proibido como a realeza. Planta derrubada no chão. Papéis espalhados. Raio de sol iluminando a cena do crime doméstico.)
Panel 4: Door handle turns. Cat sits perfectly upright by the entrance,
composed and innocent, tail wrapped neatly around paws. Not a hair out of
place. As if nothing happened.
(Painel 4: A maçaneta da porta gira. O gato senta-se perfeitamente ereto na entrada, composto e inocente, cauda enrolada ordenadamente em torno das patas. Nem um fio de cabelo fora do lugar. Como se nada tivesse acontecido.)
Style: Warm illustrated style with expressive characters, clear visual
storytelling that reads without text. Consistent character design across
all panels.
(Estilo: Estilo ilustrado quente com personagens expressivos, narrativa visual clara que se lê sem texto. Design de personagem consistente em todos os painéis.)
No speech bubbles or text. Let the visuals tell the story. (Sem balões de fala ou texto. Deixe o visual contar a história.)Defina cada painel como uma batida visual distinta com ação clara. O modelo lida com o layout do painel e a continuidade visual.
Ilustrações de Livros Infantis
A ilustração de livros infantis requer uma abordagem específica: design de personagem memorável, estilo acessível e acolhedor, e composições que funcionem com sobreposições de texto.
Create a children's book illustration introducing the main character.
(Crie uma ilustração de livro infantil apresentando o personagem principal.)
Character: Young forest hero, around 8 years old. (Personagem: Jovem herói da floresta, cerca de 8 anos.)
- Green hooded tunic (think woodland adventurer, not Robin Hood) (Túnica com capuz verde (pense em aventureiro da floresta, não Robin Hood))
- Soft brown boots, well-worn (Botas marrons macias, bem usadas)
- Small belt pouch for collecting treasures (Pequena bolsa de cinto para coletar tesouros)
- Carries a tiny wooden bow (symbolic, for helping not hurting) (Carrega um pequeno arco de madeira (simbólico, para ajudar, não machucar))
- Kind expression, bright curious eyes, brave but gentle demeanor (Expressão gentil, olhos curiosos brilhantes, comportamento corajoso, mas gentil)
- Slightly oversized head for picture book proportions (Cabeça ligeiramente grande para proporções de livro ilustrado)
Theme: This character protects and rescues small forest animals in trouble.
(Tema: Este personagem protege e resgata pequenos animais da floresta em apuros.)
Style: Hand-painted watercolor look with soft outlines, warm earthy palette
with forest greens and autumn oranges. Whimsical, friendly, inviting for
young readers ages 4-8.
(Estilo: Aparência de aquarela pintada à mão com contornos suaves, paleta terrosa quente com verdes florestais e laranjas de outono. Caprichoso, amigável, convidativo para jovens leitores de 4 a 8 anos.)
Composition: Character standing in simple forest glade, dappled sunlight,
leaving room for title text above. Character clearly showcased.
(Composição: Personagem em pé em clareira simples da floresta, luz solar manchada, deixando espaço para texto do título acima. Personagem claramente exibido.)
Original character design only. No text. No watermarks. No copyrighted
character references. (Apenas design de personagem original. Sem texto. Sem marcas d'água. Sem referências a personagens protegidos por direitos autorais.)Salve esta imagem de referência do personagem — você a usará para manter a consistência nas ilustrações subsequentes.
Aproveitando o Conhecimento de Mundo
Um dos recursos mais subestimados do GPT Image 1.5 é seu conhecimento de mundo integrado. O modelo pode inferir o contexto a partir de dicas sutis, gerando imagens histórica e culturalmente apropriadas sem instrução explícita.
Create a realistic outdoor crowd scene in Bethel, New York on August 16, 1969.
(Crie uma cena de multidão ao ar livre realista em Bethel, Nova York, em 16 de agosto de 1969.)
Photorealistic, period-accurate clothing, staging, and environment.
(Fotorrealista, roupas, encenação e ambiente precisos para a época.)
Documentary photography style, shot on film, natural lighting.
(Estilo de fotografia documental, filmado em filme, iluminação natural.)O modelo sabe que isso é Woodstock sem ser informado. Ele gera hippies, moda da época, a atmosfera do festival — tudo apenas a partir da data e local.
Esse conhecimento de mundo se estende à arquitetura através das eras, moda através das décadas, eventos culturais, marcos geográficos, movimentos artísticos e até mesmo estética fotográfica específica. Quando a precisão importa, fornecer tempo e lugar geralmente produz melhores resultados do que descrições longas do que você espera ver.
A Arte da Edição de Precisão
A geração de texto-para-imagem é impressionante, mas a edição de imagens é onde o GPT Image 1.5 realmente brilha. A capacidade de modificar imagens existentes com precisão, preservando tudo o mais, abre fluxos de trabalho profissionais que antes eram impossíveis sem habilidades especializadas em Photoshop.
A Regra de Ouro da Edição
Toda edição bem-sucedida segue o mesmo padrão: declare explicitamente o que muda, declare explicitamente o que permanece o mesmo. Isso soa óbvio, mas o nível de especificidade exigido é maior do que a maioria das pessoas imagina.
Sempre estruture prompts de edição como: "Change ONLY [X]. Preserve EXACTLY: [comprehensive list of everything else]." (Mude APENAS [X]. Preserve EXATAMENTE: [lista abrangente de tudo o mais].) Em seguida, repita sua lista de preservação em cada edição de acompanhamento para evitar desvio gradual do original.
Provador Virtual de Roupas
O comércio eletrônico está sendo transformado por recursos de provador virtual de IA. Aqui está a estrutura de prompt que uso para trocas de roupas que mantêm a identidade perfeitamente.
Edit the image to dress this person in the provided clothing items.
(Edite a imagem para vestir esta pessoa com os itens de vestuário fornecidos.)
MUST PRESERVE (do not change in any way) (DEVE PRESERVAR (não altere de forma alguma)):
- Face, facial features, expression, skin tone (Rosto, características faciais, expressão, tom de pele)
- Body shape, proportions, and pose (Forma do corpo, proporções e pose)
- Hairstyle and hair color (Penteado e cor do cabelo)
- Background and environment (Fundo e ambiente)
- Camera angle, framing, and composition (Ângulo da câmera, enquadramento e composição)
- Overall lighting direction and quality (Direção geral e qualidade da iluminação)
CHANGE ONLY (MUDE APENAS):
- Replace current clothing with provided garment images (Substitua a roupa atual por imagens de vestuário fornecidas)
- Fit garments naturally to body geometry (Ajuste as roupas naturalmente à geometria do corpo)
- Show realistic fabric draping, folds, and behavior (Mostre o caimento, dobras e comportamento realistas do tecido)
- Match lighting and shadows on fabric to original photo (Combine iluminação e sombras no tecido com a foto original)
REQUIREMENTS (REQUISITOS):
- Photorealistic integration — outfit should look worn, not pasted (Integração fotorrealista — a roupa deve parecer usada, não colada)
- Maintain color temperature of original image (Mantenha a temperatura de cor da imagem original)
- No accessories, text, logos, or watermarks added (Nenhum acessório, texto, logotipo ou marca d'água adicionado)
- Identity must remain clearly recognizable (A identidade deve permanecer claramente reconhecível)Para provador virtual, sempre use input_fidelity="high" para garantir que a semelhança facial seja mantida.
Transferência de Estilo
A transferência de estilo pega a linguagem visual de uma imagem — sua paleta, textura, pincelada, estética — e a aplica a um novo conteúdo. Isso é inestimável para manter a consistência da marca ou criar séries coesas.
Using the EXACT visual style of the reference image (Image 1), create:
(Usando o estilo visual EXATO da imagem de referência (Imagem 1), crie:)
A man riding a motorcycle on a winding mountain road.
(Um homem andando de moto em uma estrada sinuosa na montanha.)
STYLE ELEMENTS TO MATCH PRECISELY from reference (ELEMENTOS DE ESTILO PARA CORRESPONDER PRECISAMENTE da referência):
- Color palette and saturation levels (Paleta de cores e níveis de saturação)
- Line quality and weight (Qualidade e peso da linha)
- Texture treatment and brushwork (Tratamento de textura e pincelada)
- Lighting style and direction (Estilo e direção de iluminação)
- Level of detail vs. abstraction (Nível de detalhe vs. abstração)
- Overall artistic aesthetic (Estética artística geral)
APPLY TO NEW CONTENT (APLICAR AO NOVO CONTEÚDO):
- Single subject (man on motorcycle) (Assunto único (homem na motocicleta))
- Clear composition with visual interest (Composição clara com interesse visual)
- Mountain road environment with curves (Ambiente de estrada de montanha com curvas)
- Sense of motion and freedom (Senso de movimento e liberdade)
The new image should look like it came from the same artist or series as
the reference. Maintain stylistic consistency exactly.
(A nova imagem deve parecer que veio do mesmo artista ou série que a referência. Mantenha a consistência estilística exatamente.)A transferência de estilo funciona melhor quando você é específico sobre quais elementos de estilo preservar e quais elementos de conteúdo mudar.
Substituição de Objeto
Trocar objetos mantendo o fotorrealismo agora é prático. O segredo é descrever não apenas o que adicionar, mas como deve se integrar à cena existente.
In this room photo, replace ONLY the white plastic chairs with
mid-century modern wooden chairs (walnut finish, tapered legs,
woven seat).
(Nesta foto da sala, substitua APENAS as cadeiras de plástico branco por cadeiras de madeira modernas de meados do século (acabamento em nogueira, pernas cônicas, assento tecido).)
PRESERVE COMPLETELY (PRESERVAR COMPLETAMENTE):
- Camera angle and perspective (Ângulo da câmera e perspectiva)
- Room lighting direction and quality (Direção e qualidade da iluminação da sala)
- All other furniture and objects (Todos os outros móveis e objetos)
- Wall colors and decorations (Cores das paredes e decorações)
- Floor material and shadows (Material do chão e sombras)
- Overall image quality and color grading (Qualidade geral da imagem e gradação de cores)
INTEGRATION REQUIREMENTS (REQUISITOS DE INTEGRAÇÃO):
- Chairs must match room's perspective exactly (As cadeiras devem corresponder exatamente à perspectiva da sala)
- Wood grain should catch existing light realistically (O grão da madeira deve capturar a luz existente de forma realista)
- Contact shadows must be natural and match light source (As sombras de contato devem ser naturais e corresponder à fonte de luz)
- Scale must be accurate relative to table height (A escala deve ser precisa em relação à altura da mesa)
- New chairs should look like they belong in this room (As novas cadeiras devem parecer pertencer a esta sala)
Photorealistic result — should look like the original photograph.
(Resultado fotorrealista — deve parecer a fotografia original.)A visualização de design de interiores é uma das aplicações de edição mais valiosas comercialmente.
Esboço para Renderização Fotorrealista
Transformar esboços brutos em renderizações polidas é incrivelmente útil para design de produtos, arquitetura e desenvolvimento de conceito. O prompt precisa tratar o esboço como uma especificação a seguir.
Transform this hand-drawn sketch into a photorealistic image.
(Transforme este esboço desenhado à mão em uma imagem fotorrealista.)
PRESERVE FROM SKETCH (PRESERVAR DO ESBOÇO):
- Exact layout and proportions (Layout e proporções exatos)
- Perspective and viewing angle (Perspectiva e ângulo de visão)
- Element placement and relationships (Colocação de elementos e relacionamentos)
- Implied depth and layering (Profundidade e camadas implícitas)
ADD FOR REALISM (ADICIONAR PARA REALISMO):
- Appropriate real-world materials and textures (Materiais e texturas apropriados do mundo real)
- Consistent natural lighting (interpret from sketch shading) (Iluminação natural consistente (interpretar do sombreamento do esboço))
- Environmental context matching the implied setting (Contexto ambiental correspondente ao cenário implícito)
- Surface imperfections and wear appropriate to materials (Imperfeições de superfície e desgaste apropriados aos materiais)
CONSTRAINTS (RESTRIÇÕES):
- Do not add new elements not present in sketch (Não adicione novos elementos não presentes no esboço)
- Do not add text or watermarks (Não adicione texto ou marcas d'água)
- Treat the sketch as an architectural blueprint to follow exactly (Trate o esboço como um projeto arquitetônico para seguir exatamente)
- Fill in realistic details while honoring the original composition (Preencha detalhes realistas honrando a composição original)O modelo interpreta a intenção do esboço e preenche detalhes realistas, mantendo a composição original.
Transformação de Iluminação e Clima
Mudar as condições ambientais preservando a geometria da cena é uma das minhas aplicações de edição favoritas. Perfeito para criar variantes sazonais, alternativas de hora do dia ou ajustes de humor.
Transform this daytime summer scene into a winter evening with snowfall.
(Transforme esta cena de verão diurna em uma noite de inverno com queda de neve.)
CHANGE (MUDAR):
- Time of day: from afternoon to dusk (warm interior lights visible) (Hora do dia: de tarde para crepúsculo (luzes interiores quentes visíveis))
- Season: summer to deep winter (Estação: verão para inverno profundo)
- Weather: clear to active snowfall (Clima: claro para queda de neve ativa)
- Ground: grass to fresh snow coverage (Solo: grama para cobertura de neve fresca)
- Trees: summer foliage to bare branches with snow (Árvores: folhagem de verão para galhos nus com neve)
- Atmosphere: add visible breath if people present (Atmosfera: adicione respiração visível se houver pessoas presentes)
- Surfaces: add frost on windows and metal (Superfícies: adicione geada em janelas e metal)
PRESERVE (PRESERVAR):
- Camera position and angle exactly (Posição e ângulo da câmera exatamente)
- All objects and their exact positions (Todos os objetos e suas posições exatas)
- Architecture and structural elements (Arquitetura e elementos estruturais)
- People and their poses (update clothing appropriately) (Pessoas e suas poses (atualize as roupas apropriadamente))
- Overall composition and framing (Composição geral e enquadramento)
Style: Photorealistic, natural atmospheric perspective, visible
snowflakes in air, cozy contrast between warm interior lights and
cold exterior. Should feel photographed, not filtered.
(Estilo: Fotorrealista, perspectiva atmosférica natural, flocos de neve visíveis no ar, contraste aconchegante entre luzes interiores quentes e exterior frio. Deve parecer fotografado, não filtrado.)Use input_fidelity="high" e quality="high" para obter melhores resultados em transformações ambientais.
Composição Multi-Imagem
Combinar elementos de várias imagens de origem requer instruções claras sobre o que vem de onde e como os elementos devem se integrar perfeitamente.
I'm providing 2 images:
(Estou fornecendo 2 imagens:)
- Image 1: Beach scene with woman standing on shore at sunset (Imagem 1: Cena de praia com mulher em pé na costa ao pôr do sol)
- Image 2: Golden retriever sitting in a studio setting (Imagem 2: Golden retriever sentado em um cenário de estúdio)
Task: Place the dog from Image 2 into the beach scene from Image 1,
positioned next to the woman, looking up at her.
(Tarefa: Coloque o cachorro da Imagem 2 na cena da praia da Imagem 1, posicionado ao lado da mulher, olhando para ela.)
MATCHING REQUIREMENTS (REQUISITOS DE CORRESPONDÊNCIA):
- Dog's lighting must match beach sunset (warm golden light from left) (A iluminação do cachorro deve corresponder ao pôr do sol da praia (luz dourada quente da esquerda))
- Scale dog appropriately relative to woman's height (Dimensione o cachorro apropriadamente em relação à altura da mulher)
- Dog should cast shadow consistent with scene's sun angle (O cachorro deve projetar sombra consistente com o ângulo do sol da cena)
- Sand texture should show around and under dog's paws (A textura da areia deve aparecer ao redor e sob as patas do cachorro)
- Fur should catch the same golden hour highlights as scene (O pelo deve capturar os mesmos destaques da hora dourada que a cena)
PRESERVE FROM IMAGE 1 (PRESERVAR DA IMAGEM 1):
- Woman's exact appearance, position, and pose (Aparência exata, posição e pose da mulher)
- Beach background completely unchanged (Fundo da praia completamente inalterado)
- Original photo's color grading and mood (Gradação de cores e humor da foto original)
The composite should look like a single photograph taken on location.
No visible compositing artifacts.
(A composição deve parecer uma única fotografia tirada no local. Sem artefatos de composição visíveis.)Referencie imagens por número e seja explícito sobre quais elementos são transferidos e quais permanecem fixos.
Tradução de Texto em Imagens
Localizar conteúdo visual para mercados internacionais é drasticamente simplificado com os recursos de texto do GPT Image 1.5.
Translate all text in this infographic from English to Japanese.
(Traduza todo o texto neste infográfico de inglês para japonês.)
MUST PRESERVE (DEVE PRESERVAR):
- Exact layout, spacing, and positioning of all elements (Layout exato, espaçamento e posicionamento de todos os elementos)
- All visual elements, icons, illustrations, and graphics (Todos os elementos visuais, ícones, ilustrações e gráficos)
- Typography hierarchy (headlines vs body text relationships) (Hierarquia tipográfica (manchetes vs relacionamentos de texto do corpo))
- Color scheme and overall design aesthetic (Esquema de cores e estética geral do design)
- Font weights and relative sizes (Pesos da fonte e tamanhos relativos)
TRANSLATION REQUIREMENTS (REQUISITOS DE TRADUÇÃO):
- Accurate Japanese translation with natural phrasing (Tradução japonesa precisa com fraseado natural)
- Match visual weight and style to original fonts (Combine peso visual e estilo com fontes originais)
- Adjust character spacing for Japanese typographic norms (Ajuste o espaçamento de caracteres para normas tipográficas japonesas)
- No text truncation or overflow outside original bounds (Sem truncamento de texto ou estouro fora dos limites originais)
Do not modify any non-text elements. Only change the language.
(Não modifique nenhum elemento não textual. Mude apenas o idioma.)Este fluxo de trabalho lida com materiais de marketing, capturas de tela da interface do usuário, embalagens e infográficos sem reconstruir do zero.
Técnicas Avançadas para Profissionais
Depois de dominar os fundamentos, essas técnicas avançadas elevarão seu trabalho a níveis verdadeiramente profissionais. Esses são padrões que desenvolvi através de extensa experimentação — técnicas que produzem consistentemente resultados superiores.
Consistência de Personagem em Imagens
Um dos maiores desafios na geração de imagens por IA é manter a consistência do personagem em várias imagens. Para livros infantis, mascotes de marca ou qualquer projeto que exija o mesmo personagem em cenas diferentes, aqui está meu fluxo de trabalho comprovado.
Gere uma imagem de referência detalhada que estabeleça a aparência definitiva do personagem. Inclua todos os detalhes principais: roupa, proporções, expressão, paleta de cores. Salve esta imagem — ela se torna sua fonte de verdade.
Escreva uma descrição de texto detalhada do personagem que você referenciará em todos os prompts futuros. Seja específico sobre cada elemento visual. Esta âncora textual complementa a visual.
Ao criar novas cenas, sempre inclua a imagem âncora como entrada e instrua explicitamente "maintain exact character appearance from reference image" (mantenha a aparência exata do personagem da imagem de referência).
O modelo mantém o contexto dentro de uma sessão de conversa. Construa sobre imagens de sucesso em vez de começar do zero para cada cena. Faça referência às gerações anteriores diretamente.
Continue the children's book story using the character from the reference image.
(Continue a história do livro infantil usando o personagem da imagem de referência.)
New Scene (Nova Cena):
The same young forest hero is gently helping a frightened squirrel out
of a fallen hollow tree after a winter storm. Snow on the ground, bare
branches above, warm light filtering through clouds.
(O mesmo jovem herói da floresta está gentilmente ajudando um esquilo assustado a sair de uma árvore oca caída após uma tempestade de inverno. Neve no chão, galhos nus acima, luz quente filtrando através das nuvens.)
CHARACTER CONSISTENCY (from reference) (CONSISTÊNCIA DO PERSONAGEM (da referência)):
- Same green hooded tunic, exact shade and style (Mesma túnica verde com capuz, tom e estilo exatos)
- Same soft brown boots (Mesmas botas marrons macias)
- Same belt pouch (Mesma bolsa de cinto)
- Same facial features, proportions, and color palette (Mesmas características faciais, proporções e paleta de cores)
- Same gentle, heroic personality in expression (Mesma personalidade gentil e heróica na expressão)
- Same children's book proportions (Mesmas proporções de livro infantil)
STYLE CONSISTENCY (from reference) (CONSISTÊNCIA DE ESTILO (da referência)):
- Same watercolor illustration style (Mesmo estilo de ilustração em aquarela)
- Same soft outlines (Mesmos contornos suaves)
- Same warm earthy color treatment (Mesmo tratamento de cor terrosa quente)
- Same whimsical, friendly aesthetic (Mesma estética caprichosa e amigável)
New elements: winter forest environment, frightened squirrel, fallen
tree with hollow. (Novos elementos: ambiente de floresta de inverno, esquilo assustado, árvore caída com oco.)
Do not redesign the character. Do not change the artistic style.
No text. No watermarks.
(Não redesenhe o personagem. Não mude o estilo artístico. Sem texto. Sem marcas d'água.)Referencie a imagem âncora e repita os detalhes principais do personagem para manter a consistência em todo o livro.
A Técnica de Retrato Estilizado 3D
Criar retratos 3D hiper-estilizados a partir de fotos de referência tornou-se uma das minhas saídas exclusivas. A chave é a extrema especificidade sobre a estética desejada.
Create a hyper-stylized 3D floating head portrait based on this person.
(Crie um retrato de cabeça flutuante 3D hiper-estilizado com base nesta pessoa.)
STYLE CHARACTERISTICS (CARACTERÍSTICAS DE ESTILO):
- Smooth skin with glossy vinyl-finish surface (Pele lisa com superfície de acabamento vinílico brilhante)
- Strong highlighter on cheekbones and nose tip catching soft light (Iluminador forte nas maçãs do rosto e ponta do nariz capturando luz suave)
- Holographic, iridescent eyeshadow (purple to teal color shift) (Sombra holográfica e iridescente (mudança de cor roxa para verde-azulado))
- Thick hair sculpted in slick, glossy waves like polished acrylic (Cabelo grosso esculpido em ondas lisas e brilhantes como acrílico polido)
- Small metallic chrome nose piercing with brushed reflections (Pequeno piercing de nariz cromado metálico com reflexos escovados)
EXPRESSION (EXPRESSÃO):
Confident, slightly unimpressed look — half-lidded eyes, subtly
arched brow, the sophisticated "too cool" attitude.
(Olhar confiante, ligeiramente não impressionado — olhos semicerrados, sobrancelha sutilmente arqueada, a atitude sofisticada "muito legal".)
TECHNICAL SPECIFICATIONS (ESPECIFICAÇÕES TÉCNICAS):
- Head floats isolated against plain white background (A cabeça flutua isolada contra fundo branco simples)
- Slight 15-degree tilt (premium product render feeling) (Leve inclinação de 15 graus (sensação de renderização de produto premium))
- Bright, diffuse studio lighting with no harsh shadows (Iluminação de estúdio brilhante e difusa, sem sombras duras)
- Emphasis on glossy, plastic, subsurface scattering effects (Ênfase em efeitos brilhantes, plásticos e de dispersão de subsuperfície)
- Ultra-smooth textures throughout (Texturas ultra-suaves por toda parte)
- Close-up portrait angle, straight-on, 85mm lens feel (Ângulo de retrato em close-up, direto, sensação de lente 85mm)
The result should look like a high-end 3D character render or
collectible figure — plastic perfection with personality.
(O resultado deve parecer uma renderização de personagem 3D de ponta ou figura colecionável — perfeição plástica com personalidade.)Esse nível de detalhe estético produz resultados notavelmente consistentes em diferentes assuntos.
Transformação de Personagem Chibi
Converter fotos em adoráveis personagens no estilo chibi funciona surpreendentemente bem para mascotes de marca, avatares de mídia social e mercadorias.
Transform this person into an adorable chibi-style character.
(Transforme esta pessoa em um personagem adorável no estilo chibi.)
CHIBI PROPORTIONS (PROPORÇÕES CHIBI):
- Tiny body (about 1 head-height tall) (Corpo minúsculo (cerca de 1 altura de cabeça))
- Oversized head (3x body proportions) (Cabeça grande demais (3x proporções do corpo))
- Large, sparkling eyes with cute highlights (Olhos grandes e brilhantes com reflexos fofos)
- Soft, rounded facial features (Características faciais suaves e arredondadas)
- Cheerful, expressive pose with personality (Pose alegre e expressiva com personalidade)
PRESERVE FROM ORIGINAL (PRESERVAR DO ORIGINAL):
- Recognizable facial features (simplified but identifiable) (Características faciais reconhecíveis (simplificadas, mas identificáveis))
- Hairstyle, length, and hair color (Penteado, comprimento e cor do cabelo)
- Distinctive clothing style or accessories (Estilo de roupa distinto ou acessórios)
- Any notable characteristics (glasses, jewelry, etc.) (Quaisquer características notáveis (óculos, joias, etc.))
- Overall personality and vibe (Personalidade e vibração geral)
STYLE (ESTILO):
- Smooth pastel shading (Sombreamento pastel suave)
- Clean lines and simplified details (Linhas limpas e detalhes simplificados)
- Bright, expressive colors (Cores brilhantes e expressivas)
- Collectible figure aesthetic (Estética de figura colecionável)
Background: Simple gradient or plain color to showcase character.
(Fundo: Gradiente simples ou cor sólida para mostrar o personagem.)
The result should feel like an irresistible chibi mascot that
clearly represents the original person.
(O resultado deve parecer um mascote chibi irresistível que representa claramente a pessoa original.)Transformações Chibi funcionam bem para branding pessoal, avatares de equipe e designs de mercadorias.
Criativos de Marketing com Texto Perfeito
Criar materiais de marketing com texto preciso requer controle rigoroso de tipografia e especificações de texto explícitas.
Create a realistic highway billboard mockup featuring this product.
(Crie uma maquete realista de outdoor de rodovia apresentando este produto.)
BILLBOARD CONTENT (CONTEÚDO DO OUTDOOR):
- Product bottle prominently displayed on left third (Garrafa do produto exibida com destaque no terço esquerdo)
- Main headline on right (EXACT TEXT, render verbatim): (Manchete principal à direita (TEXTO EXATO, renderizar literalmente):)
"Fresh & Clean — Every Day"
- Tagline below headline: "Nature's Best Ingredients" (Slogan abaixo da manchete: "Nature's Best Ingredients")
- Small logo placeholder area in bottom right corner (Pequena área de espaço reservado para logotipo no canto inferior direito)
TYPOGRAPHY SPECIFICATIONS (ESPECIFICAÇÕES DE TIPOGRAFIA):
- Headline: Bold sans-serif, white text, high contrast (Manchete: Sans-serif em negrito, texto branco, alto contraste)
- Tagline: Light sans-serif, slightly smaller, same white (Slogan: Sans-serif leve, um pouco menor, mesmo branco)
- Clean kerning, centered alignment within text area (Kerning limpo, alinhamento centralizado dentro da área de texto)
- Text appears EXACTLY ONCE — no duplicates anywhere (O texto aparece EXATAMENTE UMA VEZ — sem duplicatas em lugar nenhum)
SCENE (CENA):
- Billboard on highway overpass or roadside structure (Outdoor em viaduto de rodovia ou estrutura à beira da estrada)
- Sunset lighting creating warm, appealing atmosphere (Iluminação do pôr do sol criando uma atmosfera quente e atraente)
- Photorealistic environment with motion-blurred vehicles below (Ambiente fotorrealista com veículos com desfoque de movimento abaixo)
- Professional advertising photography feel (Sensação de fotografia publicitária profissional)
No watermarks. No additional marketing copy. No logos unless
specified. Text must be perfectly legible and correctly spelled.
(Sem marcas d'água. Sem cópia de marketing adicional. Sem logotipos a menos que especificado. O texto deve ser perfeitamente legível e escrito corretamente.)Sempre use quality="high" para materiais de marketing com texto. Verifique a ortografia antes do uso final.
Extração de Fotografia de Produto
Criar fotos de produtos limpas com assuntos isolados é essencial para o comércio eletrônico. Aqui está o prompt que funciona.
Extract the product from this image for e-commerce use.
(Extraia o produto desta imagem para uso em comércio eletrônico.)
OUTPUT SPECIFICATIONS (ESPECIFICAÇÕES DE SAÍDA):
- Transparent background (RGBA PNG format) (Fundo transparente (formato RGBA PNG))
- Crisp silhouette with clean edges (Silhueta nítida com bordas limpas)
- No halos or color fringing around product (Sem halos ou franjas de cor ao redor do produto)
- All product labels and text perfectly preserved (Todos os rótulos e textos do produto perfeitamente preservados)
- Exact product geometry and proportions maintained (Geometria e proporções exatas do produto mantidas)
OPTIONAL ENHANCEMENT (MELHORIA OPCIONAL):
- Add subtle, realistic contact shadow (Adicione sombra de contato sutil e realista)
- Shadow should be soft and natural, no hard edges (A sombra deve ser suave e natural, sem bordas duras)
- Shadow works with the transparent background (A sombra funciona com o fundo transparente)
CRITICAL CONSTRAINTS (RESTRIÇÕES CRÍTICAS):
- Do NOT restyle or recolor the product (NÃO reestilize ou recolora o produto)
- Do NOT modify product appearance in any way (NÃO modifique a aparência do produto de forma alguma)
- Only remove background and add optional shadow (Apenas remova o fundo e adicione sombra opcional)
- Preserve every detail of the original product exactly (Preserve exatamente cada detalhe do produto original)Nota: O modelo atual renderiza o padrão quadriculado para transparência — pode precisar de pós-processamento para o canal alfa verdadeiro.
Limitação Conhecida
A remoção de fundo atualmente renderiza um padrão quadriculado visual para indicar transparência em vez de produzir transparência RGBA verdadeira no arquivo de saída. Para uso em produção, pode ser necessário pós-processar a saída para converter o quadriculado em transparência real usando software de edição de imagem.
O Loop de Refinamento Iterativo
Não tente alcançar a perfeição em um único prompt. Resultados profissionais vêm da iteração sistemática.
O Processo de Refinamento
- Gerar: Crie imagem inicial com elementos principais e composição geral
- Avaliar: Identifique os 1-2 problemas mais importantes para resolver primeiro
- Refinar: Corrija apenas esses problemas específicos, preservando explicitamente todo o resto
- Bloquear: Salve o estado atual antes de tentar a próxima iteração
- Repetir: Continue até ficar satisfeito, construindo incrementalmente
Cada pequena mudança focada se soma em resultados finais precisos com muito menos frustração do que tentar tudo de uma vez.
Fluxos de Trabalho Profissionais do Mundo Real
A teoria é valiosa, mas ver como as técnicas se combinam em fluxos de trabalho completos é onde a compreensão se cristaliza. Aqui estão os fluxos de trabalho que uso com mais frequência na prática profissional.
Pipeline de Fotografia de Produto de E-Commerce
Sistema Visual de Produto Completo
- Extração de produto: Remova fundos de fotos brutas de produtos, crie fotos isoladas limpas
- Contextos de estilo de vida: Gere cenas ambientais (cozinha, escritório, exterior) e componha produtos nelas
- Variantes de cor: Crie variações de cor do produto através de edição direcionada sem refilmar
- Criativos de marketing: Gere maquetes de outdoor, gráficos de mídia social, anúncios de banner com integração de produto
- Localização: Traduza texto em materiais de marketing para diferentes mercados, preservando o design
Um pipeline completo de fotografia de produto que anteriormente exigia tempo de estúdio, experiência em Photoshop e vários especialistas agora é executado por meio de uma série de prompts de IA.
Biblioteca Visual de Criador de Conteúdo
Construindo Ativos de Marca Consistentes
- Desenvolvimento de personagem: Crie mascote da marca ou avatar pessoal com imagem âncora detalhada
- Geração de guia de estilo: Produza referências de paleta de cores, painéis de humor e exemplos estéticos
- Fábrica de miniaturas: Gere miniaturas consistentes para YouTube/social usando personagem e estilo estabelecidos
- Biblioteca de fundo: Crie fundos de cena que correspondam à estética da marca para vários tipos de conteúdo
- Expansão de variação: Use transferência de estilo para manter a consistência visual em todo o novo conteúdo
Construa sua fundação visual uma vez, depois itere de forma eficiente. Cria o tipo de consistência de marca que anteriormente exigia uma equipe de design dedicada.
Prototipagem Rápida de Design
Do Conceito ao Visual em Minutos
- Esboço bruto: Desenhe o conceito básico à mão (qualidade de guardanapo é boa — formas e layout brutos)
- Renderização inicial: Converta o esboço em imagem fotorrealista ou estilizada preservando sua composição
- Ciclo de iteração: Refine através de edições direcionadas ("iluminação mais quente", "material diferente", "mais contraste")
- Exploração de variantes: Gere múltiplas variações (n=4) para apresentação ao cliente ou tomada de decisão
- Polimento final: Exportação de alta qualidade da direção selecionada com detalhes refinados
Designers relatam iteração de conceito dramaticamente mais rápida em comparação com fluxos de trabalho tradicionais de criação digital.
Pipeline de Ilustração de Livro Infantil
Criando Livros Ilustrados Consistentes
- Design de personagem: Crie folha de referência detalhada do personagem estabelecendo a aparência definitiva
- Estabelecimento de estilo: Gere 2-3 páginas de amostra para bloquear o estilo de ilustração, escolha a melhor
- Geração cena por cena: Trabalhe na história página por página, sempre referenciando âncoras de personagem e estilo
- Revisão de consistência: Visualize todas as páginas juntas, use a edição para corrigir qualquer desvio de personagem ou inconsistências de estilo
- Refinamento final: Polir páginas individuais conforme necessário, mantendo a aparência estabelecida
A abordagem de imagem âncora torna a ilustração consistente de personagens em um livro inteiro genuinamente alcançável.
Os Erros Que Estavam Matando Meus Resultados
Depois de ver a mim mesmo e inúmeras outras pessoas lutarem com a geração de imagens de IA, identifiquei os padrões que separam o sucesso da frustração. Aqui estão os erros que eu costumava cometer — e como eu os corrigi.
❌ Recheio de Palavras-Chave
O erro: Adicionar "highly detailed, 8K, photorealistic, trending on ArtStation, masterpiece" (altamente detalhado, 8K, fotorrealista, tendência no ArtStation, obra-prima) a cada único prompt.
A correção: Descreva propriedades visuais específicas. "Visible skin pores, morning window light, 50mm lens depth of field" (Poros da pele visíveis, luz da janela da manhã, profundidade de campo da lente de 50mm) comunica muito mais do que palavras-chave de qualidade genéricas.
❌ O Mega-Prompt
O erro: Tentar especificar cada detalhe possível em um prompt massivo, esperando que o modelo de alguma forma descubra minha visão completa.
A correção: Comece simples. Obtenha uma imagem base sólida primeiro, depois refine com prompts de acompanhamento direcionados. Construir incrementalmente produz resultados muito melhores.
❌ Instruções de Edição Vagas
O erro: Dizer "make it better" (faça melhor) ou "fix the lighting" (conserte a iluminação) sem especificar o que "melhor" significa ou como a iluminação deve mudar.
A correção: Seja específico sobre a mudança. "Shift lighting from harsh overhead to soft window light from the left, with warmer color temperature." (Mude a iluminação de cima dura para luz suave da janela da esquerda, com temperatura de cor mais quente.)
❌ Esquecendo a Lista de Preservação
O erro: Solicitar alterações sem declarar explicitamente o que deve permanecer inalterado, e depois se surpreender quando outros elementos mudam.
A correção: Cada prompt de edição inclui requisitos de preservação explícitos. Repita-os em cada iteração porque o modelo não se lembra de restrições anteriores.
❌ Amnésia de Contexto
O erro: Iniciar novas conversas para imagens relacionadas, perdendo todo o contexto e consistência construídos.
A correção: Construa dentro de sessões para trabalhos relacionados. Referencie gerações anteriores diretamente. Use frases como "same style as the previous image" (mesmo estilo da imagem anterior) para aproveitar o contexto.
❌ Configurações de Qualidade Erradas
O erro: Sempre usando alta qualidade (lento e caro para iteração) ou sempre usando baixa qualidade (perdendo detalhes cruciais quando importa).
A correção: Combine as configurações com a tarefa. Baixa qualidade para exploração e iteração; alta qualidade para saídas finais e qualquer coisa com texto.
❌ Lutando contra o Modelo
O erro: Executar o mesmo prompt repetidamente, esperando resultados diferentes, ou forçar uma direção que o modelo resiste consistentemente.
A correção: Se um prompt não estiver funcionando, reformule em vez de repetir. Palavras diferentes ativam padrões diferentes. Às vezes, sua abordagem precisa mudar, não apenas a saída do modelo.
❌ Ignorando a Estocasticidade
O erro: Esperar resultados idênticos de prompts idênticos, ficando frustrado quando as saídas variam.
A correção: Gere múltiplas variações (n=4) e escolha a melhor. Abrace a variabilidade como uma fonte de opções criativas em vez de uma falha a ser superada.
A única mudança mais impactante que a maioria das pessoas pode fazer: pare de tratar prompts como desejos e comece a tratá-los como especificações. Seja tão preciso quanto você seria em um resumo de design para um colaborador humano. O modelo é notavelmente capaz — mas precisa de direção clara para mostrar essa capacidade.
Integração de API para Desenvolvedores
Se você está integrando o GPT Image 1.5 em aplicativos programaticamente, aqui estão os detalhes técnicos e as melhores práticas que você precisa.
Configuração Básica da API
import os
import base64
from openai import OpenAI
client = OpenAI()
# Create output directory (Criar diretório de saída)
os.makedirs("output_images", exist_ok=True)
def save_image(result, filename: str) -> None:
"""Save base64 image response to file."""
image_base64 = result.data[0].b64_json
with open(f"output_images/{filename}", "wb") as f:
f.write(base64.b64decode(image_base64))
# Basic text-to-image generation (Geração básica de texto-para-imagem)
result = client.images.generate(
model="gpt-image-1.5",
prompt="Your detailed prompt here",
quality="high", # or "low" for faster iteration (ou "low" para iteração mais rápida)
n=1 # number of variations (número de variações)
)
save_image(result, "output.png")Edição de Imagem com Múltiplas Entradas
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # Essential for identity preservation (Essencial para preservação de identidade)
quality="high",
image=[
open("input_images/source.png", "rb"),
open("input_images/style_reference.png", "rb"),
],
prompt="""
Apply the artistic style from Image 2 to the subject in Image 1.
(Aplique o estilo artístico da Imagem 2 ao assunto na Imagem 1.)
PRESERVE: subject's identity, pose, and composition
(PRESERVAR: identidade do assunto, pose e composição)
CHANGE: artistic style, color palette, texture treatment
(MUDAR: estilo artístico, paleta de cores, tratamento de textura)
Do not add new elements. Maintain subject likeness exactly.
(Não adicione novos elementos. Mantenha a semelhança do assunto exatamente.)
"""
)
save_image(result, "styled_output.png")Parâmetros Chave da API
Parâmetros de Geração
model
"gpt-image-1.5" — o modelo principal mais recente com melhores capacidades
prompt
Sua descrição de texto — estrutura importa mais que comprimento
quality
"high" para detalhes e trabalho de texto, "low" para velocidade e iteração
n
Número de variações para gerar (1-4 tipicamente, maior para exploração)
Parâmetros de Edição
image
Objeto de arquivo ou lista de objetos de arquivo para entradas multi-imagem
input_fidelity
"high" para preservação de identidade, crítico para trabalho de retrato
Considerações de Preço
Estrutura de Custo da API
- Preço baseado em Tokens: Os custos escalam com resolução e configurações de qualidade
- 1MP alta qualidade: Aproximadamente $133 por 1.000 imagens
- 1MP baixa qualidade: Aproximadamente $9 por 1.000 imagens
- Economia de custo: Custos de entrada/saída de imagem são 20% menores que GPT Image 1
Para aplicações de alto volume, sempre comece com baixa qualidade e atualize apenas para saídas finais ou imagens com muito texto.
Como Se Compara a Outras Ferramentas
Passei um tempo significativo com todas as principais ferramentas de geração de imagens de IA. Aqui está minha avaliação honesta de como o gerador de imagens do ChatGPT (GPT Image 1.5) se compara à concorrência.
GPT Image 1.5 vs Gemini 3.0 Pro Image
GPT Image 1.5 ganha: Conformidade de instrução (90% vs 77%), precisão de renderização de texto, edição de precisão, qualidade de integração de API
Gemini 3.0 Pro ganha: Qualidade geral da imagem em alguns benchmarks, interpretação criativa, cenas complexas de múltiplas figuras
Minha opinião: GPT Image 1.5 para trabalho profissional exigindo precisão e consistência; Gemini para exploração criativa onde você quer mais interpretação
GPT Image 1.5 vs Midjourney
GPT Image 1.5 ganha: Seguimento de instruções, capacidades de edição de imagem, acesso à API, renderização de texto, resultados previsíveis
Midjourney ganha: Estética artística e "fator uau", recursos de comunidade e compartilhamento, estilos pictóricos
Minha opinião: GPT Image 1.5 para trabalho profissional/comercial onde você precisa de resultados específicos; Midjourney para exploração artística e arte conceitual
GPT Image 1.5 vs DALL-E 3
GPT Image 1.5 ganha: Capacidades de edição, velocidade (4x mais rápido), consistência entre iterações, conformidade de instrução
DALL-E 3 ganha: Nada significativo — GPT Image 1.5 é o sucessor e melhora em todas as dimensões
Minha opinião: Se você ainda está usando DALL-E 3, atualize imediatamente. O GPT Image 1.5 é estritamente melhor.
GPT Image 1.5 vs Stable Diffusion
GPT Image 1.5 ganha: Facilidade de uso, nenhuma configuração necessária, seguimento de instruções, renderização de texto, qualidade consistente
Stable Diffusion ganha: Personalização total, controle local, geração gratuita ilimitada, ajuste fino, modelos especializados
Minha opinião: GPT Image 1.5 para velocidade e facilidade; Stable Diffusion para controle, personalização e trabalho de alto volume consciente de custos
Em testes de benchmark, o GPT Image 1.5 alcançou a posição #1 nas categorias de geração de texto-para-imagem e edição de imagens na Artificial Analysis Image Arena. Para trabalho de produção exigindo resultados confiáveis e previsíveis com controle preciso, é atualmente a melhor opção disponível.
A resposta real? A melhor ferramenta depende de suas necessidades específicas. Mantenho acesso a múltiplas ferramentas porque cada uma se destaca em coisas diferentes. Mas se eu pudesse ter apenas uma para trabalho profissional, escolheria o GPT Image 1.5 por sua confiabilidade, precisão e capacidades de edição.
Segredos de Usuários Avançados
Estas são as dicas que me levaram de resultados "muito bons" para "qualidade profissional". Cada uma foi aprendida através de extensa experimentação e às vezes falha dolorosa.
Comece Novo para Novos Projetos
Comece cada novo projeto em uma nova conversa. O contexto de projetos antigos pode vazar para novas gerações e causar resultados inesperados. Ardósia limpa, resultados limpos.
A Regra 80/20
Acerte 80% na primeira geração. Use edição para os 20% finais. Tentar alcançar a perfeição em um único prompt leva à frustração e perda de tempo.
Específico Vence Superlativo
"Shot on medium format film with natural grain" (Fotografado em filme de formato médio com grão natural) vence "ultra-high-quality amazing detailed" (ultra-alta qualidade incrível detalhado) todas as vezes. Específicos guiam o modelo; superlativos apenas adicionam ruído.
Cite Seu Texto
Sempre coloque o texto necessário entre "aspas" e especifique que deve aparecer "exactly once, no duplicates" (exatamente uma vez, sem duplicatas). Isso evita a duplicação e erros de ortografia que atormentam a renderização de texto.
Termine com Negativos
Termine cada prompt com o que você não quer: "No watermarks, no text unless specified, no logos, no excessive saturation, no artificial bokeh." (Sem marcas d'água, sem texto a menos que especificado, sem logotipos, sem saturação excessiva, sem bokeh artificial.) Prevenção vence correção.
Salve Seus Vencedores
Quando você obtiver um ótimo resultado, salve tanto a imagem QUANTO o prompt completo. Construa uma biblioteca pessoal de prompts comprovados que você pode adaptar para projetos futuros.
Reformule, Não Repita
Se um prompt não está funcionando, não o execute novamente esperando por sorte. Reformule-o. Palavras diferentes ativam padrões diferentes no modelo. Mude sua abordagem.
Alta Qualidade para Texto Sempre
Sempre que sua imagem incluir texto — qualquer texto — use o modo de alta qualidade. Texto de baixa qualidade é frequentemente ilegível, tornando a economia de velocidade inútil.
Entendendo a Estocasticidade
Aqui está algo crucial: a geração de imagens por IA é fundamentalmente estocástica. O mesmo prompt pode produzir resultados diferentes a cada vez. Isso não é um bug — é a natureza da tecnologia.
Abrace a Variância
Em vez de lutar contra a aleatoriedade, use-a. Gere 4 variações e escolha a melhor. Às vezes, a interpretação "inesperada" leva a algum lugar melhor do que o que você imaginou originalmente. Os melhores artistas de IA que conheço se inclinam para acidentes felizes enquanto mantêm controle suficiente para atingir seus objetivos. A variabilidade é um recurso, não uma falha.
Resolução de Problemas Comuns
Após milhares de gerações, encontrei todos os problemas imagináveis. Veja como corrigir os problemas mais comuns que frustram os criadores.
Problema: O Texto Está Com Erro Ortográfico ou Duplicado
Solução
Coloque o texto exato entre aspas: "RESTAURANT" não restaurant. Adicione instrução explícita: "render exactly once, no duplicates" (renderizar exatamente uma vez, sem duplicatas). Para palavras difíceis, soletre letra por letra: "R-E-S-T-A-U-R-A-N-T". Sempre use quality="high" para qualquer imagem contendo texto. Verifique a saída antes de usar.
Problema: O Personagem Parece Diferente em Imagens
Solução
Crie uma imagem âncora de personagem detalhada primeiro e salve-a. Inclua esta âncora como entrada para cada geração subsequente. Escreva uma bíblia de personagem listando cada detalhe visual. Instrua explicitamente "maintain exact character appearance from reference image" (mantenha a aparência exata do personagem da imagem de referência). Use input_fidelity="high" em chamadas de API. Trabalhe dentro de sessões únicas quando possível.
Problema: Edições Mudam Mais Do Que o Solicitado
Solução
Seja mais explícito sobre a preservação. Estruture prompts como "Change ONLY: [X]. Preserve EXACTLY: [list everything else in detail]." (Mude APENAS: [X]. Preserve EXATAMENTE: [liste todo o resto em detalhes].) Repita a lista completa de preservação em cada iteração de edição — o modelo não se lembra de restrições anteriores. Use input_fidelity="high" para elementos importantes.
Problema: Imagens Parecem Obviamente "Geradas por IA"
Solução
Adicione imperfeições realistas: "subtle film grain" (grão de filme sutil), "slight lens vignette" (leve vinheta de lente), "natural skin texture with pores and subtle blemishes" (textura de pele natural com poros e manchas sutis), "dust particles visible in sunbeam" (partículas de poeira visíveis no raio de sol), "minor wear on materials" (desgaste menor em materiais). Perfeição parece falso. A realidade é bagunçada. Descreva o que as câmeras realmente capturam, não versões idealizadas.
Problema: Cores Parecem Supersaturadas ou Não Naturais
Solução
Especifique o tratamento de cores explicitamente: "natural color grading" (gradação de cores natural), "true-to-life colors" (cores fiéis à vida), "muted earth tones" (tons terrosos suaves), "not oversaturated" (não supersaturado), "color-accurate" (cores precisas). Referencie estoques de filme específicos para orientação de cores: "Kodak Portra color science" (ciência de cores Kodak Portra) ou "documentary color grading" (gradação de cores documental). Adicione "realistic color balance, no HDR look" (equilíbrio de cores realista, sem aparência HDR).
Problema: Remoção de Fundo Cria Halos ou Artefatos
Solução
Solicite explicitamente: "transparent background (RGBA PNG format), crisp silhouette, no halos, no color fringing, clean edges, no artifacts" (fundo transparente (formato RGBA PNG), silhueta nítida, sem halos, sem franjas de cor, bordas limpas, sem artefatos). Observe que o modelo atual renderiza padrão quadriculado para transparência — pós-processamento pode ser necessário para canal alfa verdadeiro em produção.
Problema: Composições Parecem Desequilibradas ou Estranhas
Solução
Especifique a composição explicitamente: "subject positioned using rule of thirds" (assunto posicionado usando a regra dos terços), "centered with symmetrical framing" (centralizado com enquadramento simétrico), "generous negative space on left for text overlay" (espaço negativo generoso à esquerda para sobreposição de texto), "eye-level camera angle" (ângulo da câmera ao nível dos olhos), "subject fills 60% of frame" (assunto preenche 60% do quadro). Não deixe a composição ao acaso — descreva exatamente o que você quer.
O Futuro da Geração de Imagens por IA
Estamos vivendo uma revolução. O que era ficção científica há dois anos agora é uma mercadoria que qualquer um pode acessar. Mas ainda estamos nos primeiros capítulos desta história. Aqui está o que vejo chegando.
O Que Está no Horizonte
🎬 Integração de Vídeo Perfeita
A linha entre imagens estáticas e vídeo está se confundindo rapidamente. Espere transições suaves da geração de imagens para sequências animadas dentro da mesma interface. Versões iniciais já estão aqui (Sora, Runway), e estão melhorando rapidamente. Seus prompts de imagem se tornarão prompts de vídeo com adaptação mínima.
🎯 Consistência Perfeita
Consistência de personagem e estilo em imagens ilimitadas sem esforço manual. O fluxo de trabalho de âncora e referência se tornará automático. Treine o modelo em alguns exemplos do seu personagem, e ele mantém a consistência perfeita para sempre. O problema de "deriva" será resolvido completamente.
✏️ Edição Colaborativa em Tempo Real
Edição interativa onde você pinta, arrasta e manipula elementos conversacionalmente em tempo real. Imagine o Photoshop onde cada pincelada aciona uma resposta de IA, e edições complexas acontecem através de conversas em vez de ferramentas técnicas.
🎨 Aprendizado de Estilo Pessoal
Treine o modelo em sua estética com um punhado de exemplos. Seu próprio artista de IA pessoal que entende seu gosto, sua marca, sua linguagem visual — e aplica isso consistentemente a tudo o que você cria.
A Democratização da Criação Visual
O que estamos testemunhando é nada menos que a democratização da criação visual. Habilidades que antes exigiam anos de treinamento — fotografia de produto, design gráfico, ilustração, arte conceitual — estão se tornando acessíveis a qualquer pessoa que possa descrever o que quer ver.
Isso não elimina o valor da criatividade humana. Se alguma coisa, eleva-a. Quando a execução se torna fácil, a visão se torna tudo. As pessoas que prosperarem nesta nova paisagem não serão aquelas que podem renderizar as mãos mais realistas — a IA lida com isso agora. Serão aquelas que têm algo que vale a pena dizer, algo que vale a pena mostrar, algo que move as pessoas.
Os fotógrafos que prosperaram na transição do filme para o digital não foram aqueles que resistiram à mudança. Foram aqueles que abraçaram novas ferramentas enquanto mantinham sua visão artística. A geração de imagens por IA é o mesmo tipo de transição, apenas mais dramática e rápida.
As melhores imagens geradas por IA sempre serão criadas por pessoas que entendem tanto a tecnologia QUANTO a arte. Domine as ferramentas, mas nunca esqueça que as ferramentas servem à visão. A tecnologia amplifica a criatividade humana — ela não a substitui.
Considerações Finais
Miniaturas, gráficos e conteúdo social em minutos em vez de horas
Fotografia de produto, variantes e marketing em escala sem precedentes
Conceituação rápida e apresentações de clientes que costumavam levar dias
Acesso programático robusto para construir aplicativos habilitados para imagem
A linguagem natural torna a entrada mais fácil do que ferramentas de design tradicionais
Qualidade e consistência suficientes para trabalho comercial
Comecei esta jornada frustrado e cético. Eu tinha ouvido o hype sobre a geração de imagens por IA, mas repetidamente bati na parede entre promessas de marketing e realidade prática. Dedos com anatomia impossível. Texto que derretia em formas abstratas. Composições que lutavam ativamente contra minhas intenções. Eu estava pronto para descartar tudo como tecnologia exagerada.
Então aprendi a falar a linguagem da máquina. Parei de descrever o que eu queria ver e comecei a descrever o que uma câmera capturaria. Parei de esperar pela sorte e comecei a construir sistematicamente. Parei de lutar contra o modelo e comecei a colaborar com ele.
O GPT Image 1.5 não apenas melhorou os problemas anteriores — mudou fundamentalmente meu relacionamento com a criação visual. Agora penso em termos de prompts e iterações em vez de pincéis e camadas. Abordo desafios visuais com confiança de que há uma estrutura de prompt que produzirá o que preciso. As imagens que crio hoje teriam levado dias para serem produzidas há apenas dois anos. As ideias que posso explorar são limitadas apenas pela imaginação, não pela habilidade técnica.
A curva de aprendizado é real. Você não vai dominar isso da noite para o dia. Mas os princípios deste guia — estrutura sobre palavras-chave, especificidade sobre superlativos, iteração sobre perfeição, a mentalidade fotográfica — comprimirão semanas de experimentação frustrante em aprendizado focado e produtivo.
Mais do que qualquer coisa, espero que este guia lhe dê o que eu gostaria de ter quando comecei: não apenas técnicas, mas um modelo mental. Uma compreensão de como essa tecnologia interpreta a linguagem, ao que ela responde e como falar sua linguagem visual fluentemente.
A lacuna entre as imagens em sua mente e as imagens em sua tela nunca foi tão pequena. E com a abordagem certa, essa lacuna continua a diminuir a cada prompt que você escreve.
Agora vá fazer algo bonito.
Lembro-me daquele momento às 2 da manhã quando tudo clicou — quando a imagem que apareceu não foi apenas aceitável, mas exatamente o que eu havia imaginado. Esse sentimento está disponível para você agora. A tecnologia chegou. As técnicas estão documentadas. A única coisa que resta é sua imaginação e sua vontade de aprender uma nova linguagem. O gerador de imagens do ChatGPT não é apenas uma ferramenta — é um parceiro criativo que amplifica a visão humana de maneiras que estamos apenas começando a entender. Bem-vindo ao futuro da criação visual. As imagens que você tem visto em sua mente? Elas estão mais perto da realidade do que nunca.
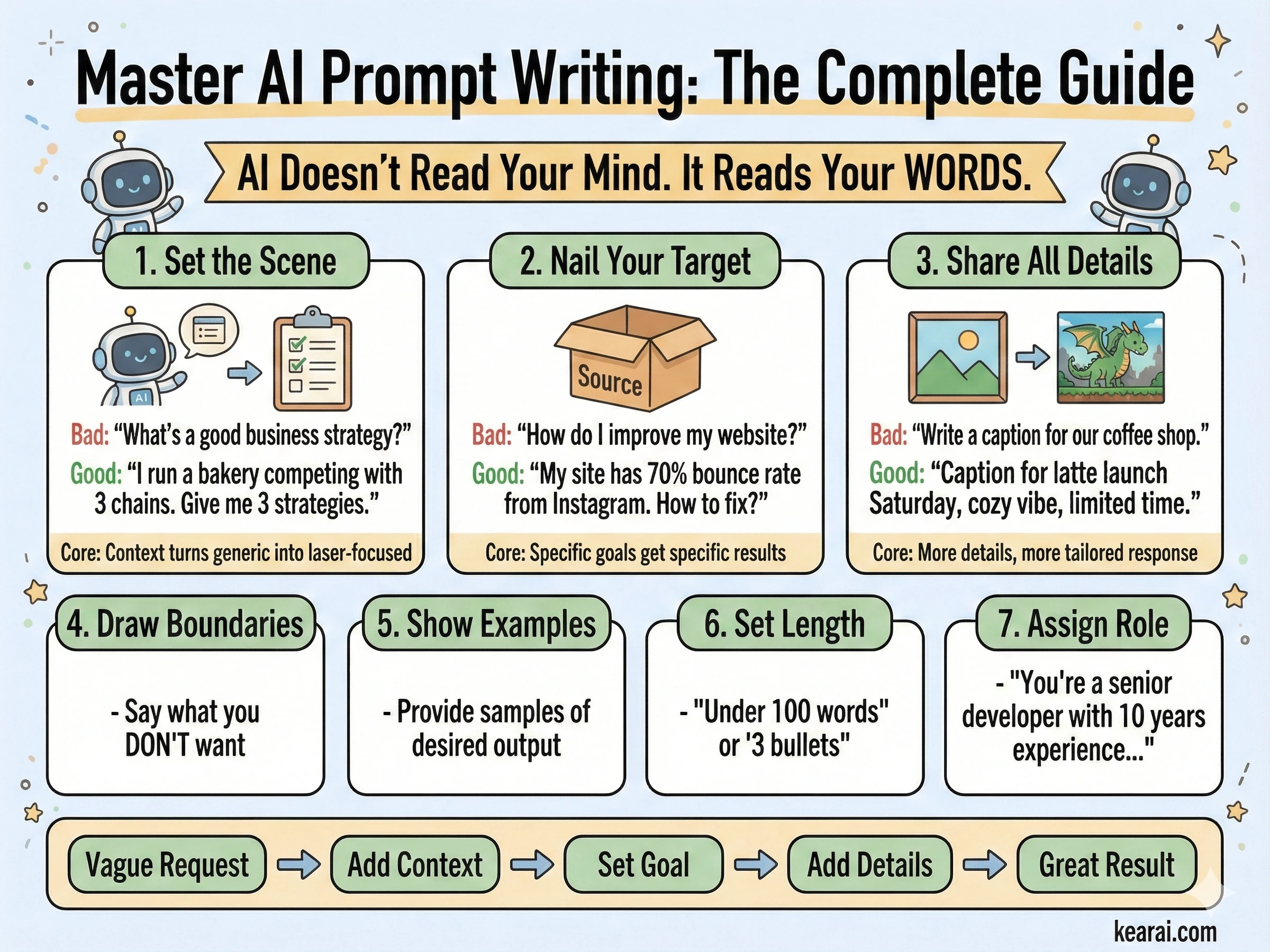
Discussão
0 comentáriosDeixe um comentário
Seja o primeiro a compartilhar seus pensamentos!