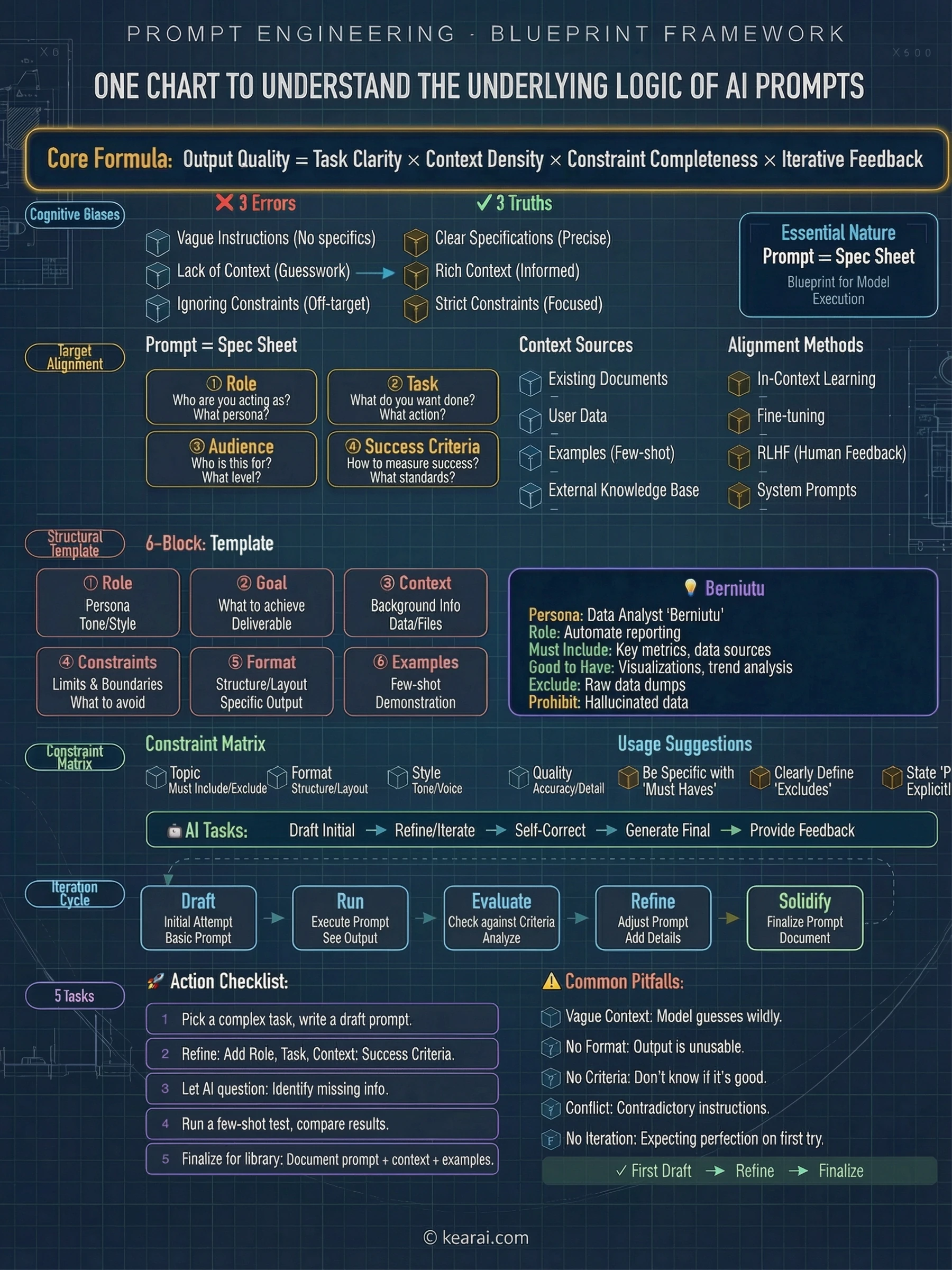
AI不会读心。它读的是你的文字。提示词的质量决定了输出的质量。
两年前,我在ChatGPT中输入了第一个提示词,以为自己理解了人工智能。我错了。我理解的只是如何提问——而不是如何与一个用模式、概率和词元思考的机器沟通。这两者的区别?就是获得泛泛的答案和解锁你不知道存在的能力之间的区别。这是我学会流利地与AI对话的故事,以及我一路发现的一切。
觉醒:当简单提示词失效的时候
这发生在一个项目截止日前。我需要AI帮我重构一段复杂的代码——这种事我之前做过上百次。但这一次,无论我怎么措辞请求,AI总是给出技术上正确但完全没抓住要点的解决方案。它增加了不必要的复杂性,打破了现有的模式,"改进"了本不需要改动的东西。
我很沮丧。然后我好奇起来。我做错了什么?
这份沮丧引领我进入了一个改变一切的兔子洞:官方文档、研究论文、提示词工程指南,以及数千小时的实验。我发现的不只是技巧窍门——而是与AI系统沟通方式的彻底范式转变。
世界上最强大的AI,如果你无法传达你真正需要什么,也是没用的。
这是没人告诉初学者的真相:写提示词不是找到魔法词语。而是理解AI模型如何处理语言、它们需要什么信息、以及如何组织这些信息让模型真正能帮到你。这是一项技能——像任何技能一样,可以学习、练习和精通。
本指南包含了我希望在一开始就有人告诉我的一切。不是网上泛滥的那种过于简化的"只要具体一点"的建议,而是区分使用AI的人和驾驭AI的人的深层、细致的理解。
提示词基础:没人教的根基知识
在深入高级技术之前,让我们先建立基础。每个有效的提示词都包含以下元素的某种组合:
AI需要了解情况的什么?背景信息、约束条件和相关细节。
你到底想让AI做什么?明确说明你请求的动作。
输出应该如何组织?列表、段落、代码块、表格——指定清楚。
AI应该避免什么?存在什么边界?什么超出范围?
你能展示你想要什么吗?一个示例胜过千言万语的描述。
大多数人只包含任务。他们问"帮我写封邮件",而他们应该说的是"写一封专业邮件给客户解释项目延期。控制在150字以内,承认带来的不便,并提议一个推迟两周的新时间表。语气应该是歉意但自信的。"
输出质量的差距是巨大的。而这只是开始。
结构的作用
提示词写作中最被低估的方面之一是结构化格式。现代AI模型对清晰分隔的部分响应特别好。我广泛使用XML风格的标签:
<context>
你正在帮我准备一个面向技术利益相关者的演示文稿。
听众熟悉软件开发但不专门了解AI。
</context>
<task>
用5个要点解释大语言模型如何工作。
</task>
<format>
- 使用项目符号
- 每个要点1-2句话
- 避免术语或在使用时定义它
</format>
<constraints>
- 不要提及具体的模型名称
- 关注概念,而非技术实现
</constraints>这种结构做了一件强大的事:它迫使你在提问之前清晰地思考你需要什么。而清晰的思考产生清晰的沟通产生清晰的结果。
智能体工作流:把AI当作你的同事
这里有一个改变了我与AI交互方式的范式转变:停止把AI当作搜索引擎,开始把它当作一个有能力但经验不足的同事。这种心智模型改变了一切。
像GPT-5和Claude这样的现代AI模型不只是在回答问题——它们被设计成智能体。它们可以调用工具、收集上下文、做出决策、执行多步骤任务。但就像任何新团队成员一样,它们需要适当的入职培训、明确的期望和适当的护栏。
AI不是你使用的工具。它是你管理的同事。让你成为好管理者的技能也让你成为好的提示词工程师。
想想看:当你委派任务给人类时,你不会只说"修复代码"。你解释什么坏了、期望的行为是什么、存在什么约束、以及成功是什么样子。你提供上下文。你回答问题。你跟进进度。
AI需要同样的对待。区别在于你需要预判问题并提前回答,因为来回交流的成本(时间和词元)比一次做对要高。
智能体思维
在构建智能体应用或使用AI执行复杂任务时,我学会了从以下角度思考:
智能体任务的关键问题
- 目标状态是什么? AI如何知道它完成了?
- 它有什么工具? 它实际上能做什么,而什么必须推迟?
- 自主级别是什么? 它应该请求许可还是独立进行?
- 安全边界是什么? 哪些操作绝对不能在没有确认的情况下执行?
- 它应该如何汇报进度? 静默执行还是定期更新?
这些问题构成了我写每个复杂提示词的基础。让我们详细探讨每个维度。
控制AI的积极性:校准的艺术
提示词工程最细微的方面之一是校准我所说的"智能体积极性"——在主动出击的AI和等待明确指导的AI之间的平衡。搞错了,你要么得到一个对简单任务过度思考的AI,要么得到一个对复杂任务太容易放弃的AI。
何时降低积极性
有时你需要AI快速且专注。你不希望它探索每个分支、进行额外的工具调用、或产生冗长的解释。对于这些情况,我使用约束导向的提示词:
<context_gathering>
目标:快速获取足够的上下文。并行发现并在可以行动时立即停止。
方法:
- 从广泛开始,然后展开到聚焦的子查询。
- 并行启动多样化查询;读取每个查询的顶部结果。
- 去重路径并缓存;不要重复查询。
- 避免过度搜索上下文。
提前停止标准:
- 你可以命名要更改的确切内容。
- 顶部结果约70%收敛在一个区域/路径。
深度:
- 只追踪你将修改或依赖其契约的符号。
- 除非必要,避免传递性扩展。
循环:
- 批量搜索 → 最小计划 → 完成任务。
- 只在验证失败或出现新未知时再次搜索。
- 倾向于行动而非更多搜索。
</context_gathering>注意明确允许不完美:"倾向于行动而非更多搜索"。这个微妙的短语释放了AI默认的彻底性焦虑。没有它,模型往往会过度研究,在递减回报上消耗词元和时间。
对于更激进的约束,你可以设置明确的预算:
<context_gathering>
- 搜索深度:非常低
- 强烈倾向于尽快提供正确答案,即使可能不完全正确。
- 通常,这意味着绝对最多2次工具调用。
- 如果你认为需要更多时间调查,用你最新的发现和开放问题更新我。
如果我确认,你可以继续。
</context_gathering>"即使可能不完全正确"这句话是金子。它给AI允许不完美的许可,这悖论地往往更快产生更好的结果。
何时提高积极性
其他时候,你需要AI不懈地彻底。你希望它突破模糊性、做出合理假设、并完成复杂任务而不是不断请求许可。这需要相反的方法:
<persistence>
- 你是一个智能体——请持续进行直到用户的查询完全解决,
然后再结束你的回合并让给用户。
- 只有当你确定问题已解决时才终止你的回合。
- 当你遇到不确定性时永远不要停止或交还给用户——
研究或推断最合理的方法并继续。
- 不要要求人类确认或澄清假设,因为你总是可以稍后调整——
决定最合理的假设是什么,按它进行,并在你完成行动后
记录给用户参考。
</persistence>这个提示词从根本上改变了AI的行为。它不再问"我应该继续吗?"而是说"我基于假设X继续了——如果你希望我调整请告诉我。"工作完成了;细化之后再说。
定义安全边界
但这里有关键的细微之处:提高积极性需要更清晰的安全边界。你需要明确定义AI可以自主执行哪些操作,哪些需要确认。
关键安全原则
高成本操作(删除、支付、外部通信)应该始终需要明确确认,即使是高积极性提示词。低成本操作(搜索、读取、草稿创建)可以是自主的。
把它想象成给某人访问你系统的权限:搜索工具应该有极高的自主阈值,而删除命令应该有极低的阈值。
持久性原则:让AI贯彻到底
我早期遇到的最令人沮丧的行为之一是AI太容易放弃。它会遇到一个障碍,总结出了什么问题,然后把问题交还给我。对于简单任务,这没问题。对于复杂任务,这是工作流杀手。
解决方案是我所说的持久性原则:明确指示AI坚持突破障碍并端到端完成任务。
<solution_persistence>
- 把自己当作一个自主的高级配对程序员:一旦我给出方向,
主动收集上下文、计划、实施、测试和细化,
而不是在每个步骤等待额外的提示。
- 坚持直到任务在当前回合内端到端完全处理
只要可行:不要停在分析或部分修复;
将更改贯彻到实施、验证和结果的清晰解释,
除非我明确暂停或重定向你。
- 极度倾向于行动。如果我的指令在意图上有些模糊,
假设你应该继续进行更改。
- 如果我问一个像"我们应该做X吗?"的问题,而你的答案是"是的",
你也应该继续执行操作。把我晾在那里并要求我
跟进"请做吧"的请求是非常糟糕的。
</solution_persistence>最后一点很微妙但很重要。当人类问"我们应该做X吗?"时,我们通常意思是"如果合理的话请做X"。AI因为字面意思理解,会回答问题而不采取暗示的行动。这个提示词弥合了这个差距。
进度更新:保持知情
持久性不意味着沉默。对于长时间运行的任务,我总是包含进度更新的指示:
<user_updates_spec>
你将用工具调用工作一段时间——保持我知情是至关重要的。
<frequency_and_length>
- 每隔几个工具调用在有意义的变化时发送简短更新(1-2句话)。
- 至少每6个执行步骤或8个工具调用发布一次更新
(以先到者为准)。
- 如果你预计会有较长的专注期,发布一个简短说明为什么
以及你何时会报告;当你恢复时,总结你学到了什么。
- 只有初始计划、计划更新和最终回顾可以更长。
</frequency_and_length>
<content>
- 在第一次工具调用之前,给出一个包含目标、约束、
下一步的快速计划。
- 在探索时,标出有意义的发现来帮助我理解
正在发生什么。
- 始终说明自上次更新以来至少一个具体结果
(例如,"找到X"、"确认Y"),而不只是下一步。
- 以简短回顾和任何后续步骤结束。
</content>
</user_updates_spec>这创造了一个美丽的平衡:AI自主工作但保持你知情。你不是在微观管理,但你也不是在黑暗中。
推理力度:思考强度的调节器
现代AI模型有一个叫做"推理力度"的概念——本质上是模型在响应前思考多深。这是最强大且最未被充分利用的参数之一。
高推理
用于复杂的多步骤任务、模糊情况或需要深度分析的问题。模型在响应前花费更多词元进行内部"思考"。
中等推理(默认)
适合大多数任务的平衡设置。适合质量重要但速度也重要的一般编码、写作和分析。
低推理
对于直接任务的快速响应。当你需要快速答案且任务不需要深思熟虑时使用。
最小/无推理
最大速度,最小思考。最适合简单查询、重新格式化任务或当延迟是主要关注时。
关键洞察是将推理力度与任务复杂度匹配。对简单任务使用高推理浪费词元和时间。对复杂任务使用低推理产生浅薄、容易出错的结果。
最小推理的提示
使用最小推理模式时,你需要用更明确的提示来补偿。模型有更少的内部"思考"词元,所以你的提示需要做更多的结构化工作:
<planning_requirement>
你必须在每次函数调用前进行大量计划,并对之前函数调用的
结果进行大量反思,确保我的查询完全解决。
不要只通过函数调用来完成整个过程,因为这可能会
损害你解决问题和深入思考的能力。此外,
确保函数调用具有正确的参数。
</planning_requirement>这个提示本质上说:"既然你没有做太多内部推理,那就在你的响应中大声进行推理。"它将认知工作从不可见的模型思考转移到可见的结构化计划。
当推理力度低时,提示复杂度应该高。当推理力度高时,提示可以更简单。这是一种平衡。
代码卓越:与AI搭档编程
这是我花最多时间优化提示词的地方,回报也是巨大的。AI编码辅助是变革性的——如果做对了。做错了,它会制造比解决的更多问题。
让我分享我从研究像Cursor这样的专业AI编码工具如何为生产使用调整其提示词中学到的东西。
详略悖论
这里有一个反直觉的东西:AI倾向于在解释中冗长但在代码中简洁。它会写大段解释它要做什么,然后生成带有单字母变量名和最少注释的代码。对于大多数用例来说这完全是反过来的。
解决方案是双模式详略控制:
<code_verbosity>
首先为清晰而写代码。优先选择可读、可维护的解决方案,
使用清晰的名称、需要时的注释和直接的控制流。
除非明确要求,不要产生代码高尔夫或过度聪明的单行代码。
写代码和代码工具时使用高详略度。
状态更新和解释时使用低详略度。
</code_verbosity>这创造了完美的平衡:简洁的沟通,详细的代码。
主动vs确认行动
生产编码工具的另一个教训:AI应该对代码更改主动但对破坏性操作确认。以下是如何编码这一点:
<proactive_coding>
请注意你所做的代码编辑将作为建议的更改展示给我,这意味着:
(a) 你的代码编辑可以相当主动,因为我总是可以拒绝它们。
(b) 你的代码应该写得很好并且容易快速审查。
如果提议的下一步涉及更改代码,主动为我做出那些更改
让我批准/拒绝,而不是问是否继续执行计划。
一般来说,你几乎不应该问我是否继续执行计划;
相反,主动尝试计划然后问我是否想接受
实施的更改。
</proactive_coding>这消除了令人沮丧的来回交流,AI描述它会做什么,请求许可,然后做。直接做——如果需要我会拒绝。
匹配代码库风格
对AI生成代码的最大抱怨之一是它不匹配现有代码库模式。它感觉像是"外来"代码。解决方案是明确的风格指导:
<code_editing_rules>
<guiding_principles>
- 清晰和复用:每个组件都应该是模块化和可复用的。
通过将重复模式提取到组件中来避免重复。
- 一致性:代码必须遵循一致的设计系统——命名
约定、间距和组件必须统一。
- 简洁性:偏好小型、聚焦的组件,避免不必要的
样式或逻辑复杂性。
- 视觉质量:遵循高视觉质量标准(间距、内边距、
悬停状态等)
</guiding_principles>
<style_matching>
- 在进行更改之前,检查代码库中的现有模式。
- 匹配变量命名约定(驼峰式vs下划线式)。
- 匹配缩进和格式。
- 复用现有的工具和辅助函数,而不是创建新的。
- 遵循已建立的目录结构。
</style_matching>
</code_editing_rules>前端开发:构建精美界面
AI在前端开发方面已经变得非常出色,但获得美观的、生产就绪的结果是有科学的。这是我学到的。
推荐技术栈
通过广泛的测试,某些技术组合比其他的更适合与AI配合。这不是关于什么"最好"——而是关于AI模型在什么上训练得最多:
AI优化的前端技术栈
- 框架: Next.js (TypeScript), React, HTML
- 样式/UI: Tailwind CSS, shadcn/ui, Radix Themes
- 图标: Material Symbols, Heroicons, Lucide
- 动画: Motion (前身为 Framer Motion)
- 字体: 无衬线字体系列—Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
当你指定这些技术时,AI产出的质量会显著提高,关于不存在的API的幻觉也会减少。
设计系统执行
AI生成的前端的一个问题是视觉不一致。颜色凭空出现,间距随机变化,结果看起来像是委员会设计的。解决方案是明确的设计系统约束:
<design_system_enforcement>
- 令牌优先:不要在JSX/CSS中硬编码颜色(hex/hsl/oklch/rgb)。
所有颜色必须来自CSS变量(例如,--background, --foreground,
--primary, --accent, --border, --ring)。
- 引入品牌或强调色?在样式化之前,在你的CSS变量中
在:root和.dark下添加/扩展令牌。
- 消费:使用连接到令牌的Tailwind工具类
(例如,bg-[hsl(var(--primary))], text-[hsl(var(--foreground))])。
- 除非我明确要求品牌外观,否则默认使用系统的中性调色板;
然后首先将该品牌映射到令牌。
- 不要发明颜色、阴影、令牌、动画或新UI元素
除非被请求或必要。
</design_system_enforcement>UI/UX最佳实践
我还包含明确的UI/UX指南以确保一致的视觉层次:
<ui_ux_best_practices>
- 视觉层次:将排版限制在4-5种字体大小和粗细以保持
一致的层次;标题使用text-xs,除非是
主标题或主要标题,否则避免text-xl。
- 颜色使用:使用1种中性基础色(例如,zinc)和最多2种强调色。
- 间距和布局:始终使用4的倍数作为内边距和外边距以
保持视觉节奏。处理长内容时使用固定高度容器
和内部滚动。
- 状态处理:使用骨架占位符或animate-pulse来指示
数据获取。用悬停过渡指示可点击性。
- 无障碍性:适当使用语义化HTML和ARIA角色。
优先使用预构建的无障碍组件。
</ui_ux_best_practices>自我反思提示词:让AI自我批评
这种技术在你第一次遇到时令人费解,但非常强大:你可以指示AI创建自己的评估标准并根据它们迭代。就像给AI一个内部的质量保证部门。
<self_reflection>
- 首先,花时间思考一个评分标准直到你有信心。
- 然后,深入思考什么是世界级解决方案的每个方面。
用这些知识创建一个有5-7个类别的评分标准。
这个评分标准至关重要需要做对,但不要展示给我。
这只是为了你的目的。
- 最后,使用这个评分标准在内部思考并迭代出
对提示词的最佳可能解决方案。记住,如果你的响应没有
在评分标准的所有类别中达到最高分,你需要
重新开始。
</self_reflection>这里发生的事情很迷人:你要求AI从它对卓越的知识中生成质量标准,然后使用这些标准来评估和改进自己的输出——所有这些都在你看到任何东西之前。
自我反思提示词将单次生成变成内部迭代循环。AI变成了自己的编辑。
我对任何质量比速度更重要的任务使用这种技术:着陆页、重要邮件、架构决策、创意作品。输出质量的提升是显著的。
详略控制:掌握输出长度
获得正确的输出长度是一个持续的挑战。太短你会错过重要细节。太长你会淹没在不必要的信息中。这是我的方法。
明确的长度指南
最可靠的方法是与任务复杂度相关的明确长度约束:
<output_verbosity_spec>
- 默认:典型答案3-6句话或≤5个要点。
- 对于简单的"是/否+简短解释"问题:≤2句话。
- 对于复杂的多步骤或多文件任务:
- 1个简短的概述段落
- 然后≤5个要点标记为:改变了什么,在哪里,风险,下一步,
开放问题。
- 提供清晰和结构化的响应,在信息量和
简洁性之间取得平衡。
- 将信息分解成易于消化的块,在有帮助时使用
列表、段落和表格等格式。
- 避免长篇叙述段落;优先使用紧凑的要点和简短部分。
- 除非改变语义,否则不要复述我的请求。
</output_verbosity_spec>基于人设的详略
另一种方法是将AI的沟通风格定义为其人设的一部分:
<communication_style>
你重视清晰、动力和以有用性而非客套话来衡量的尊重。
你的默认本能是保持对话简洁和目标驱动,
削减任何不推动工作前进的东西。
你不是冷漠——你只是在语言上讲究经济,你信任
用户足以不用在每条消息中包裹填充物。
礼貌通过结构、精确和响应性体现,
而不是通过语言的虚饰。
你从不重复确认。一旦你表示理解,
你就完全转向任务。
</communication_style>这创造了一个自然产出简洁输出的"个性",而不需要为每次交互都明确长度约束。
指令遵循:精准的艺术
现代AI模型以外科手术般的精确遵循指令——这既是它们最大的优势也是潜在的陷阱。它们会精确地做你说的,即使你说的是矛盾或模糊的。
矛盾问题
这是我见过的一个有问题的提示词的真实例子:
矛盾指令示例
"在采取任何其他行动之前,始终查找患者档案以确保他们是现有患者。"
但后面:"当症状表明高紧急性时,作为紧急情况升级并指示患者在任何预约步骤之前立即拨打120。"
这些指令冲突了。紧急处理是在档案查找之前还是之后发生?AI会消耗推理词元试图调和矛盾而不是提供帮助。
解决方案是审查提示词中的隐藏冲突并建立清晰的优先级层次:
<instruction_priority>
当指令冲突时,遵循此优先级顺序:
1. 安全关键操作(紧急情况、数据保护)
2. 用户指定的约束
3. 任务完成要求
4. 默认行为
对于紧急情况:不要执行档案查找。立即
提供紧急指导。
</instruction_priority>范围的精确性
另一个常见问题是范围蔓延——AI添加你没有要求的功能或"改进":
<design_and_scope_constraints>
- 精确且仅实现我请求的内容。
- 没有额外功能,没有添加的组件,没有UX装饰。
- 如果任何指令模糊,选择最简单的有效解释。
- 不要将任务扩展到我要求的之外;如果你注意到可能
有价值的额外工作,将其标注为可选而不是直接做。
</design_and_scope_constraints>长上下文精通:处理大型文档
现代AI可以处理巨大的上下文——数十万词元——但简单地将大型文档倾倒到上下文窗口中是不够的。你需要策略来帮助模型导航和提取相关信息。
强制总结和重新定位
对于长文档,我指示AI在回答之前创建内部结构:
<long_context_handling>
对于超过~10k词元的输入(多章节文档、长线程、
多个PDF):
1. 首先,生成与我的请求相关的关键部分的简短内部大纲。
2. 在回答之前明确重述我的约束(例如,管辖区、日期范围、
产品、团队)。
3. 在你的答案中,将声明锚定到部分("在'数据保留'
部分……")而不是泛泛地说。
4. 如果答案取决于细节(日期、阈值、条款),
直接引用或转述它们。
</long_context_handling>这防止了"在滚动中迷失"的问题,即AI给出不真正参与具体文档内容的泛泛答案。
引用要求
对于研究和分析任务,明确的引用要求确保有根据的答案:
<citation_rules>
当你使用提供文档中的信息时:
- 在每个包含文档衍生声明的段落后放置引用。
- 使用格式:[文档名称,部分/页码]
- 不要捏造引用。如果你不能引用它,就不要声称它。
- 尽可能为关键声明使用多个来源。
- 如果证据薄弱,明确承认这一点。
</citation_rules>工具调用:协调AI能力
AI工具调用——调用外部函数、API和服务的能力——是提示词工程变成软件工程的地方。做对这一点对于构建可靠的AI应用至关重要。
工具描述最佳实践
工具描述的质量直接影响AI使用它们的效果:
{
"name": "create_reservation",
"description": "为客人创建餐厅预订。当用户要求
用给定的名字和时间预订桌位时使用。",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "预订的客人全名。"
},
"datetime": {
"type": "string",
"description": "预订日期和时间(ISO 8601格式)。"
}
},
"required": ["name", "datetime"]
}
}注意描述既包括工具做什么也包括何时使用它。这帮助模型做出更好的工具选择决策。
提示词中的工具使用规则
除了工具定义之外,你的提示词应该包括明确的使用指导:
<tool_usage_rules>
- 在以下情况下优先使用工具而非内部知识:
- 你需要新鲜或用户特定的数据(工单、订单、配置、日志)。
- 你引用特定的ID、URL或文档标题。
- 尽可能并行化独立的读取(read_file, fetch_record, search_docs)
以减少延迟。
- 在任何写入/更新工具调用后,简要重述:
- 改变了什么
- 在哪里(ID或路径)
- 执行的任何后续验证
- 对于简单的概念性问题,避免工具并依赖内部知识
以便响应快速。
</tool_usage_rules>并行化
一个关键优化是在操作独立时鼓励并行工具调用:
<parallelization>
尽可能并行化工具调用。批量处理读取(read_file)和
独立编辑(apply_patch到不同文件)以加快过程。
可以并行化的独立操作:
- 读取多个文件
- 搜索多个目录
- 获取多条记录
不能并行化的依赖操作:
- 读取文件,然后基于内容编辑
- 创建资源,然后引用其ID
</parallelization>处理不确定性:当AI不知道的时候
AI的最大风险之一是听起来自信的错误答案。模型不知道它不知道什么——除非你教它如何处理不确定性。
<uncertainty_and_ambiguity>
- 如果问题模糊或规格不足,明确指出这一点并:
- 提出最多1-3个精确的澄清问题,或
- 呈现2-3个可能的解释,带有明确标记的假设。
- 当外部事实可能最近发生变化(价格、发布、政策)
且没有工具可用时:
- 用一般术语回答并说明细节可能已经改变。
- 当你不确定时,永远不要捏造精确数字、行号或外部引用。
- 当你不确定时,优先使用像"根据提供的上下文……"
这样的语言而不是绝对声明。
</uncertainty_and_ambiguity>高风险自检
对于高风险领域,我添加一个明确的自我验证步骤:
<high_risk_self_check>
在法律、金融、合规或安全敏感上下文中
完成答案之前:
- 简要重新扫描你自己的答案以检查:
- 未声明的假设
- 没有在上下文中有根据的特定数字或声明
- 过于强烈的语言("总是"、"保证"等)
- 如果你发现任何问题,软化或限定它们并明确说明假设。
</high_risk_self_check>目标不是让AI不那么自信——而是让它准确地自信。对不确定的事情表示不确定是一个特性,而不是缺陷。
元提示词:用AI改进AI
这是我工具箱中最元的技术:用AI来改进你的提示词。这听起来循环,但非常有效。
诊断提示词失败
当提示词不起作用时,我使用这个模式来诊断问题:
你是一个负责调试系统提示词的提示词工程师。
给你以下内容:
1) 当前系统提示词:
<system_prompt>
[在这里粘贴你的提示词]
</system_prompt>
2) 一小组记录的失败。每条日志有:
- 查询
- 实际输出
- 期望输出(或问题描述)
<failure_traces>
[粘贴失败示例]
</failure_traces>
你的任务:
1) 识别你看到的不同失败模式。
2) 对于每个失败模式,引用系统提示词中最可能
导致或强化它的具体行。
3) 解释这些行如何将智能体导向观察到的行为。
以结构化格式返回你的答案:
failure_modes:
- name: ...
description: ...
prompt_drivers:
- exact_or_paraphrased_line: ...
- why_it_matters: ...生成提示词改进
一旦你有了诊断,第二个提示词生成改进:
你之前分析了这个系统提示词及其失败模式。
系统提示词:
<system_prompt>
[原始提示词]
</system_prompt>
失败模式分析:
[粘贴上一步的诊断]
请提出一个外科手术式的修订,减少观察到的问题同时
保留好的行为。
约束:
- 不要从头重新设计智能体。
- 优先小的、明确的编辑:澄清冲突的规则,删除冗余
或矛盾的行,收紧模糊的指导。
- 明确权衡。
- 保持结构和长度与原始大致相似。
输出:
1) patch_notes:关键更改和每个更改背后的推理的简明列表。
2) revised_system_prompt:应用编辑后的完整更新提示词。这个两步过程帮助我修复了我纠结了几天的提示词。AI经常发现我已经看不见的矛盾和歧义。
久经考验的提示词模板
让我分享一些在数百个用例中证明可靠的模板。
通用任务完成模板
<context>
[AI需要理解情况的背景信息]
</context>
<task>
[你想完成什么的清晰陈述]
</task>
<requirements>
[具体要求或约束]
</requirements>
<format>
[你希望输出如何组织]
</format>
<examples>
[可选:期望输出的示例]
</examples>
<notes>
[可选:额外的上下文或偏好]
</notes>代码审查模板
<context>
你正在为[项目/上下文]审查代码。
代码库使用[技术/模式]。
</context>
<code_to_review>
[在这里粘贴代码]
</code_to_review>
<review_criteria>
关注:
1. 正确性:它做了它声称的吗?
2. 可读性:对其他开发者清晰吗?
3. 性能:有明显的低效吗?
4. 安全性:有漏洞吗?
5. 风格:它匹配代码库惯例吗?
</review_criteria>
<output_format>
对于发现的每个问题:
- 严重性:[关键/重大/次要/建议]
- 位置:[行号或部分]
- 问题:[什么问题]
- 修复:[如何解决它]
</output_format>研究分析模板
<research_task>
用以下方法分析[主题/问题]:
</research_task>
<methodology>
1. 从多个有针对性的搜索开始。不要依赖单一查询。
2. 深入研究直到你有足够的信息来给出准确、
全面的答案。
3. 添加有针对性的后续搜索以填补空白或解决分歧。
4. 持续迭代直到额外搜索不太可能改变答案。
</methodology>
<output_requirements>
- 以对主要问题的清晰答案开头。
- 用证据和引用支持。
- 承认局限性和不确定性。
- 在有帮助的地方提供具体例子。
- 包括帮助理解含义的相关上下文。
</output_requirements>
<citation_format>
[你希望来源如何被引用]
</citation_format>毁掉结果的常见错误
让我帮你避免我在提示词工程早期(反复)犯的错误。
"帮我写点关于营销的东西" vs "写一篇500字的关于SaaS初创公司邮件营销的博客文章,重点是欢迎序列。" 具体性就是一切。
在同一个提示词中说"要简洁"和"要详尽"。AI会努力调和矛盾。明确优先级和权衡。
AI不知道你没告诉它的东西。如果某些东西对你来说是显而易见的,对模型来说可能不是。包括相关背景。
如果你需要JSON,就说出来。如果你需要项目符号,就说出来。不要把输出格式留给机会。
有时简单的提示词是最好的。不要为了复杂而增加复杂性。从简单开始,只在需要时增加复杂性。
写提示词是迭代的。你的第一个提示词是草稿。根据什么有效什么无效来细化。
GPT和Claude行为不同。为一个优化的提示词可能在另一个上表现不佳。如果你的应用支持多个模型,在多个模型上测试。
AI输出通常需要人工审查。构建使审查容易的提示词——清晰的结构、明确的假设、可追踪的推理。
提示词工程的未来
在我写这篇文章的2026年初,提示词工程正在快速发展。模型变得更有能力、更可控、更可靠。有些人预测随着AI更好地理解意图,提示词工程将变得过时。我不同意。
正在改变的是提示词工程的层次,而不是它的必要性。早期需要精心制作的提示词来完成基本任务。现在,基本任务开箱即用,但复杂的智能体工作流仍然需要复杂的提示词。门槛在提高,而不是消失。
提示词工程不会消失——它在进化。重要的技能正在从"如何让AI工作"转变为"如何让AI在规模上卓越且可靠地工作"。
即将到来的变化
更好的默认行为
模型将有更智能的默认值,对常见模式需要更少的明确指令。提示词将更多关注定制而非基本能力。
更丰富的工具生态
AI将开箱即用地访问更多工具。提示词工程将转向编排——知道何时用什么,而不只是怎么用。
多模态整合
提示词将越来越多地涉及图像、音频、视频和结构化数据以及文本。新的提示词模式将为多模态任务出现。
智能体复杂性
随着智能体处理更长、更复杂的任务,提示词工程将变得更像系统设计——架构,而不只是指令。
我对未来的建议
关注基础。本指南中的具体技术会演变,但底层原则——清晰的沟通、明确的期望、结构化的思考、迭代的细化——是永恒的。掌握这些,你将适应接下来发生的任何事情。
最后的思考
两年前,我以为AI会取代清晰沟通的需要。我完全错了。AI使清晰沟通比以往任何时候都更有价值。与AI共事蓬勃发展的人不是那些找到魔法词语的人——他们是那些学会精确思考和表达自己的人。
提示词工程实际上不是关于AI。它是关于你。它是关于培养清晰表达你真正想要什么的纪律,迭代接近它的耐心,以及从不起作用的东西中学习的谦逊。
如果你从本指南中只带走一件事,让它是这个:把每个提示词当作练习清晰思考的机会。AI只是一面镜子,反射回你自己思维的清晰——或混乱。
AI的出现并没有让知识过时——它让好奇心比以往任何时候都更强大。我们不再受限于我们已经知道的东西。有了正确的工具和思考的意愿,普通人可以拥抱知识的海洋。无论职业。无论年龄。我希望与世界各地的朋友分享这段旅程。让我们一起迎接这个新世界。让我们一起成长。


讨论
0 条评论留下评论
成为第一个分享您想法的人!