
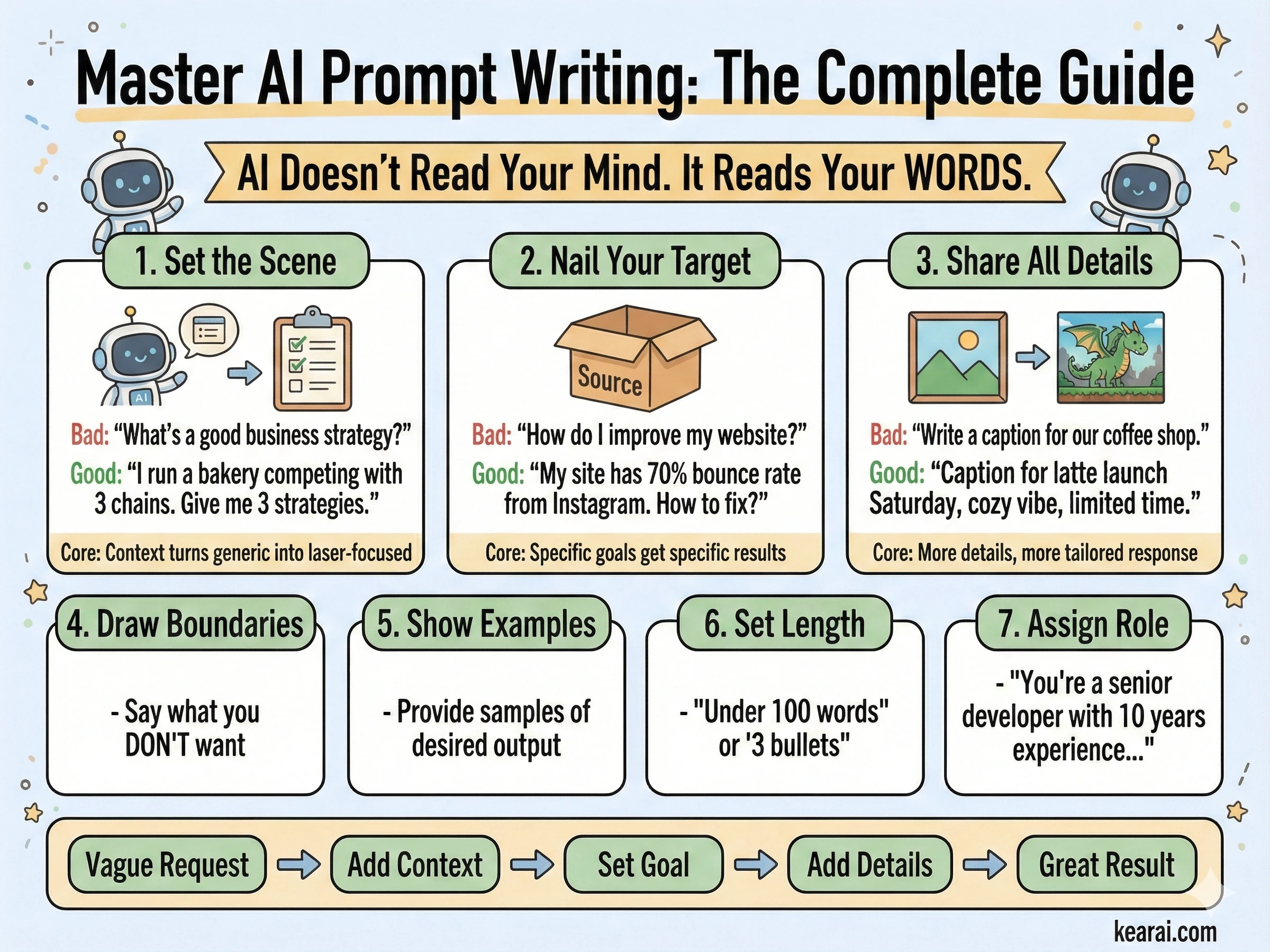
AI læser ikke dine tanker. Den læser dine ord. Kløften mellem hvad du vil have, og hvad du får, er næsten altid et kommunikationsproblem, ikke en AI-begrænsning.
Lad mig fortælle dig om det øjeblik, hvor alt ændrede sig. Jeg stirrede på en skærm, utroligt frustreret, og så AI generere endnu et svar, der var teknisk korrekt, men som fuldstændig missede pointen. Jeg bad om hjælp til at refaktorere et komplekst stykke kode, hvilket jeg havde gjort hundrede gange før. Men denne gang, uanset hvordan jeg formulerede min anmodning, blev AI ved med at tilføje unødvendig kompleksitet, ødelægge eksisterende mønstre og "forbedre" ting, der ikke var i stykker. Denne frustration førte mig ned i et kaninhul, der opslugte de næste to år af mit liv – og fuldstændig forvandlede den måde, jeg arbejder med kunstig intelligens på.
Opvågningen - Da alt, hvad jeg vidste, stoppede med at virke
Jeg husker det præcise øjeblik, hvor jeg indså, at jeg ikke anede, hvad jeg lavede. Det var sent om natten, en deadline nærmede sig, og jeg havde brug for AI til at hjælpe mig med noget, der burde have været en simpel opgave. Jeg skrev min prompt, trykkede enter og så AI producere noget, der fik mig til at ville smide min bærbare computer ud af vinduet.
Sagen er, at jeg troede, jeg forstod AI. Jeg havde brugt ChatGPT siden de tidlige dage. Jeg havde læst artikler om prompt engineering. Jeg kendte til "rollespil" og "at være specifik". Men her var jeg og fik svar, der føltes som at tale med nogen, der hørte hvert ord, jeg sagde, men ikke forstod noget af det, jeg faktisk havde brug for.
Denne frustration blev min lærer. Jeg dykkede ned i officiel dokumentation, forskningsartikler, forumdiskussioner og tusindvis af timers eksperimentering. Det, jeg opdagede, var ikke bare tips og tricks – det var et komplet paradigmeskift i, hvordan man kommunikerer med maskiner, der tænker i mønstre, sandsynligheder og tokens.
Den mest kraftfulde AI i verden er ubrugelig, hvis du ikke kan kommunikere, hvad du faktisk har brug for. Prompting handler ikke om at finde magiske ord – det handler om at forstå, hvordan AI behandler sprog, og strukturere din kommunikation derefter.
Her er sandheden, som ingen fortæller begyndere: forskellen på folk, der får fantastiske resultater fra AI, og dem, der ikke gør, er ikke intelligens eller teknisk dygtighed. Det er kommunikation. Og kommunikation med AI følger regler, der ligner – men er kritisk forskellige fra – kommunikation med mennesker.
Denne guide indeholder alt, hvad jeg har lært på denne rejse. Ikke forenklede råd som "bare vær specifik", der oversvømmer internettet, men dyb, nuanceret forståelse, der vil ændre den måde, du arbejder med AI på. Uanset om du skriver din første prompt eller bygger produktions-AI-systemer, vil det følgende ændre dit forhold til kunstig intelligens for altid.
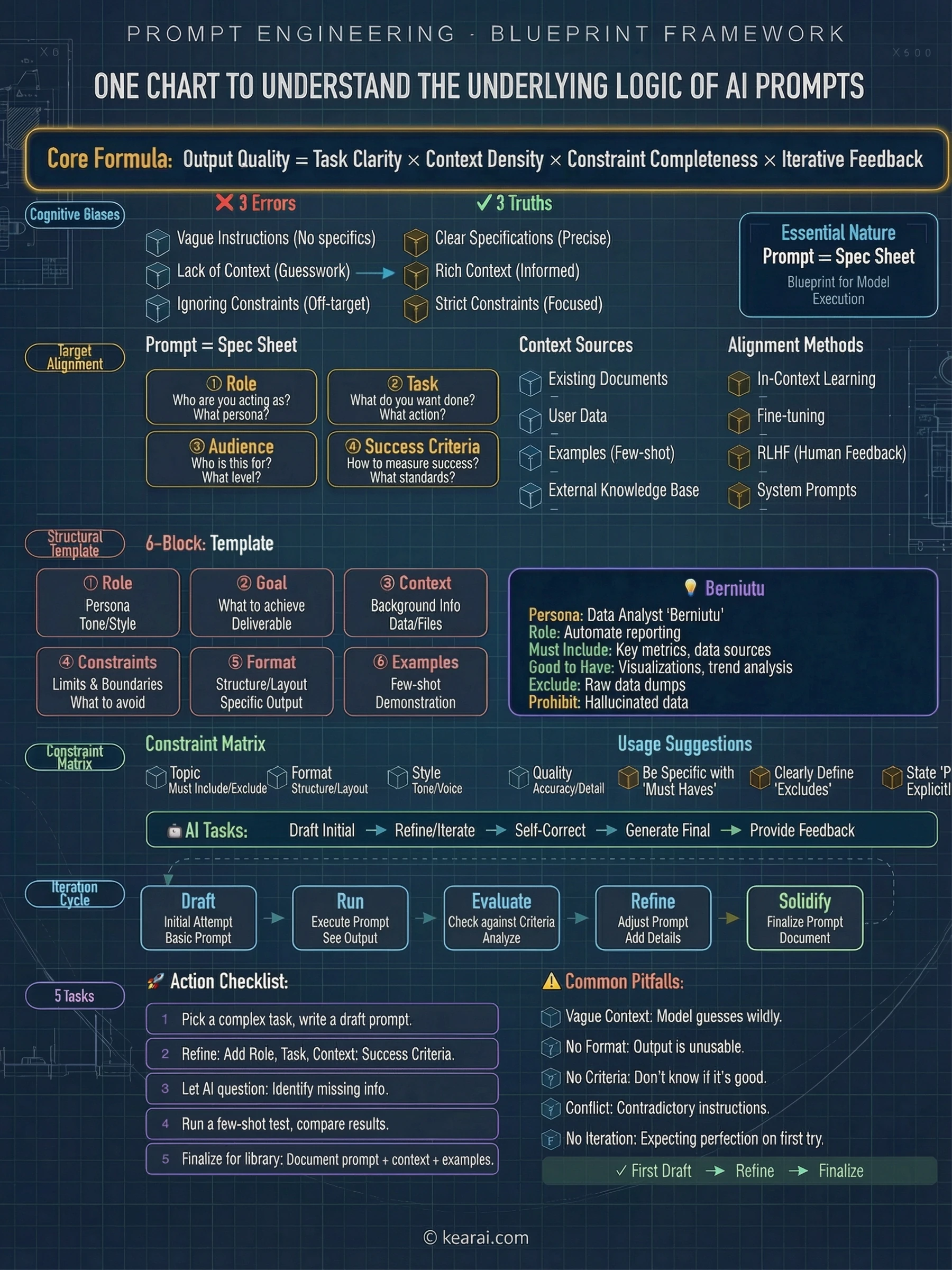
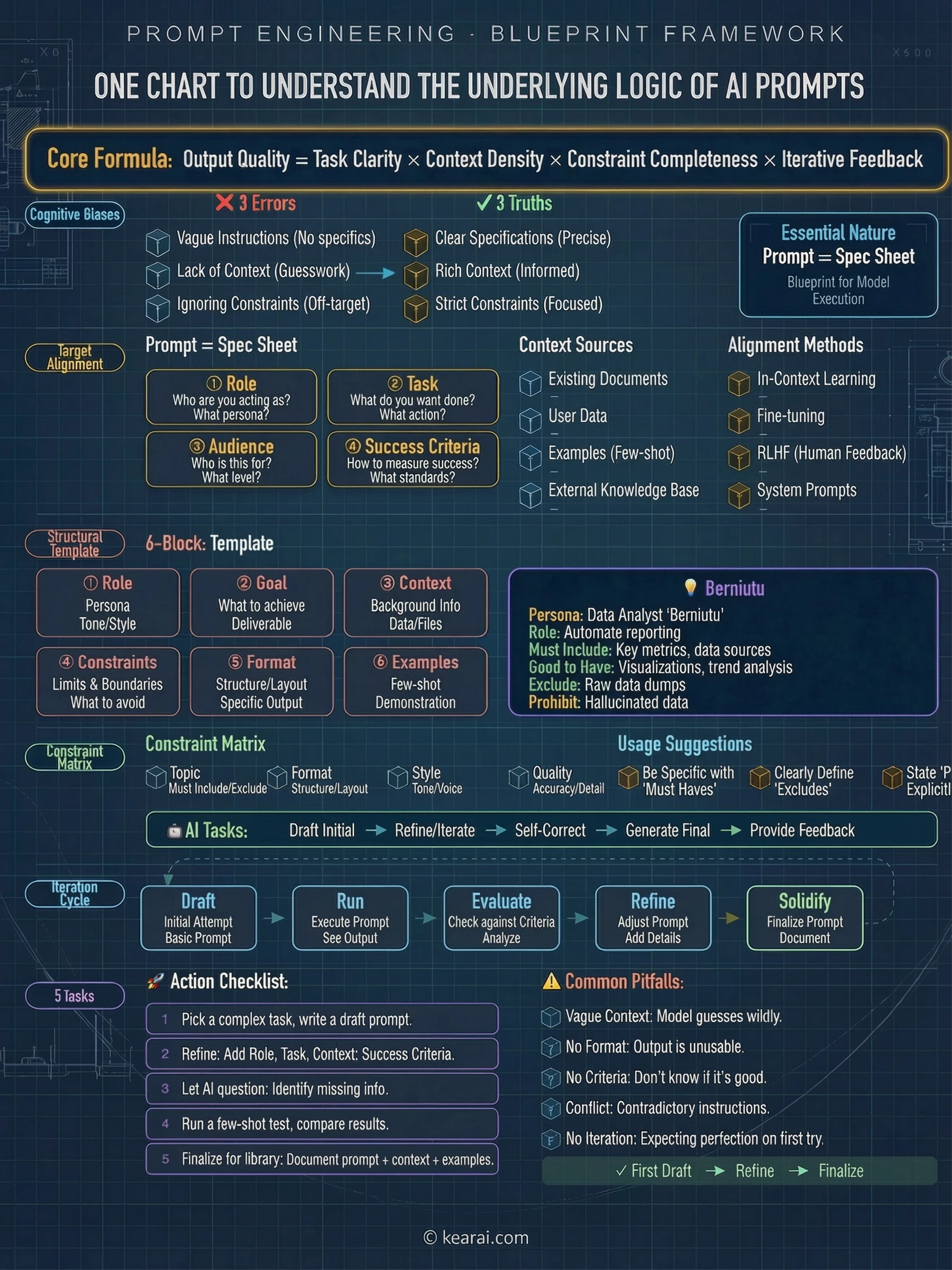
Fundamentet ingen underviser i - Prompt-kernens anatomi
Før vi dykker ned i avancerede teknikker, så lad mig dele den ramme, der ændrede alt for mig. Hver effektiv prompt, jeg skriver nu, indeholder en kombination af disse fem elementer:
Hvad har AI brug for at vide om din situation? Baggrundsinformation, begrænsninger, relevante detaljer og det miljø, du arbejder i.
Hvad præcis vil du have AI til at gøre? Vær specifik omkring den handling, du anmoder om – ikke bare emnet, men det faktiske arbejde.
Hvordan skal outputtet struktureres? Lister, afsnit, kodeblokke, tabeller, JSON – angiv det eksplicit.
Hvad skal AI undgå? Hvilke grænser findes der? Hvad er eksplicit uden for rækkevidde?
Kan du vise, hvad du vil have? Eksempler er tusind beskrivelser værd – demonstrer hellere end at forklare.
De fleste mennesker inkluderer kun opgaven. De beder "Skriv en e-mail til mig", når de burde sige "Skriv en professionel e-mail til en kunde, der forklarer en projektforsinkelse. Hold den under 150 ord, anerkend ulejligheden og foreslå en ny tidsplan om to uger. Tonen skal være undskyldende, men selvsikker."
Forskellen i output-kvalitet er dramatisk. Og det er kun begyndelsen.
Strukturens Kraft
En af de mest undervurderede aspekter af prompt-skrivning er strukturel formatering. Moderne AI-modeller reagerer usædvanligt godt på klart afgrænsede sektioner. Jeg bruger XML-stil tags i vid udstrækning, fordi de skaber utvetydige grænser:
<context>
Du hjælper mig med at forberede en præsentation for tekniske interessenter.
Publikum er bekendt med softwareudvikling, men ikke specifikt med AI.
</context>
<task>
Forklar hvordan store sprogmodeller fungerer i 5 hovedpunkter.
</task>
<format>
- Brug punktopstilling
- Hvert punkt skal være 1-2 sætninger
- Undgå fagsprog eller definer det, når det bruges
</format>
<constraints>
- Nævn ikke specifikke modelnavne
- Fokuser på begreber, ikke teknisk implementering
- Hold samlet længde under 200 ord
</constraints>Denne struktur gør noget stærkt: den tvinger dig til at tænke klart over, hvad du har brug for, før du spørger. Klar tænkning producerer klar kommunikation, og klar kommunikation producerer klare resultater. XML-tags er ikke magi – de er stilladset for dine egne tanker.
Struktur handler ikke om at gøre prompts længere – det handler om at gøre dine hensigter utvetydige. En velstruktureret kort prompt slår en sludrende lang hver gang.
Seks tankegange, der ændrede alt
Efter års eksperimentering har jeg destilleret min tilgang til seks grundlæggende "tankegange" – ikke stive skabeloner, men fleksible tankemønstre, der låser op for AI-evner, de færreste nogensinde opdager. Det handler ikke om at finde de perfekte ord; det handler om at nærme sig interaktionen med AI med den rette mentale model.
Tankegang 1: Lad AI vælge eksperten
Vi ved alle, at det hjælper at give AI en rolle. "Ager som en marketingekspert" producerer bedre marketingråd end et generisk spørgsmål. Men her er det, de fleste overser: når du ikke ved, hvilken ekspert der ville være bedst til dit spørgsmål, kan du bede AI om at vælge.
Jeg opdagede dette, da jeg planlagde en firmaevent. Jeg anede ikke, om jeg havde brug for et marketingperspektiv, et driftsperspektiv eller noget helt andet. Så i stedet for at gætte bad jeg AI om først at vælge den mest passende ekspert.
Jeg vil udforske [DOMÆNE] og specifikt [PROBLEM/SCENARIE].
Svar ikke endnu.
Vælg først den mest passende domæneekspert, der ville tænke over dette problem.
De kan være nulevende eller historiske, berømte eller relativt ukendte personligheder,
men de skal være virkelig fremragende inden for dette specifikke felt.
Hvis du er usikker, stil mig 2 positioneringsspørgsmål før du vælger.
Output:
1. Hvem du valgte og deres specifikke domæne
2. Hvorfor du valgte dem (tre sætninger)
Bed mig derefter om at beskrive mit detaljerede spørgsmål.Da jeg brugte dette til eventplanlægning, valgte AI Priya Parker – en ekspert i eventdesign, jeg aldrig havde hørt om, men som viste sig at være perfekt. De svar, jeg fik, var ikke generiske "overvej disse fem faktorer" – de var nuancerede, specifikke vejledninger, der føltes som en samtale med nogen, der havde gjort det hundrede gange.
Tankegang 2: Lad AI spørge først
Dette er en teknik, jeg bruger mere end nogen anden. Jeg kalder det "Sokratisk Prompting" – i stedet for at forsøge at forudse alt, hvad AI har brug for at vide, lader jeg den stille mig spørgsmål, indtil den har nok kontekst til at give et virkelig nyttigt svar.
Tænk over det: når du beder en klog ven om råd, begynder de ikke straks at udgyde et svar. De stiller afklarende spørgsmål. De undersøger konteksten. De sikrer sig, at de forstår, før de rådgiver. AI kan gøre det samme – men kun hvis du beder den om det.
[DIT SPØRGSMÅL ELLER BEHOV]
Før du svarer, bedes du stille mig spørgsmål først.
Krav:
- Stil ét spørgsmål ad gangen
- Fortsæt med at undersøge baseret på mine svar
- Fortsæt indtil du har 95% tillid til, at du forstår
mine sande behov og mål
- Først da skal du give mig dit svar eller din løsning
95%-tærsklen sikrer kvalitet samtidig med at uendelige loops undgås.Jeg brugte dette, da jeg skulle beslutte, om jeg skulle ansætte vores første HR-person. I stedet for at få et generisk svar om "fordele og ulemper ved at ansætte HR", spurgte AI ind til vores nuværende teamstørrelse, ansættelseshastighed, compliance-krav, budgetbegrænsninger og kulturelle mål. Efter at have besvaret omkring femten målrettede spørgsmål fik jeg råd, der var specifikke for min virkelige situation – ikke et lærebogssvar, der var nogenlunde gældende.
"95% tillidstærskel" er en vigtig detalje. Den er høj nok til at sikre kvalitet, men realistisk nok til, at AI ikke sidder fast for evigt. Denne ene sætning ændrer måden, AI tilgår samtalen på.
Tankegang 3: Debatter med AI
AI har et problem, som de fleste ikke er klar over: den er for behagelig. Den vil ofte fortælle dig det, du gerne vil høre, i stedet for at udfordre dine antagelser. Denne "sleskhed" kan være farlig, når du prøver at validere ideer eller forberede dig på kritik.
Løsningen er eksplicit at sætte AI i rollen som en modstander, der ønsker at modbevise din position. Jeg opdagede dette, mens jeg forberedte mig til en konference-tale. Jeg havde en tese, jeg ville præsentere, men jeg frygtede blinde vinkler.
Jeg skal til at deltage i en debat. Mange mennesker vil udfordre min holdning.
Min holdning: [DIN TESE/IDE]
Jeg har brug for, at denne ide er skudsikker.
Hvis du var en lærd opsat på at bevise, at jeg tager fejl, ved at bruge ethvert
tilgængeligt argument, detalje og logisk værktøj, hvordan ville du så angribe
min holdning?
Dit eneste mål: demonstrer at jeg tager fejl.
Vær ikke blid. Tøv ikke. Angrib.Det, der skete derefter, ændrede mit syn på AI. Vi gik frem og tilbage i tre timer. AI fandt svagheder i mit argument, som jeg ikke havde overvejet, rejste modeksempler jeg ikke kunne afvise, og tvang mig til at forfine min holdning, indtil den holdt til reel granskning. Til sidst havde jeg en meget stærkere tese – og vigtigere, jeg havde forudset enhver større indvending, jeg ville møde.
Tankegang 4: Pre-Mortem af dine planer
Mennesker har en tendens til at være optimistiske i planlægning. AI, der følger vores eksempel, har også en tendens til at være optimistisk. Dette skaber planer, der ser godt ud på papiret, men falder fra hinanden, når virkeligheden rammer.
Pre-mortem teknikken vender denne dynamik om. I stedet for at spørge "Hvordan skal jeg gøre dette?", spørger du "Forestil dig, at dette mislykkedes spektakulært – hvorfor?"
[DIT PROJEKT/PLAN]
Antag at dette projekt mislykkedes katastrofalt.
Skriv en post-mortem analyse, der besvarer:
1. På hvilket tidspunkt opstod de første tegn på nedgang?
2. Hvad var den mest fatale fejl i beslutningstagningen?
3. Hvilken nøglerisiko blev overset?
4. Hvis I kunne gå tilbage, hvad er den første ting, I ville ændre?
Baser din analyse på lignende projektfejl i den virkelige verden.
Skriv det som en ægte fejl-retrospektiv, ikke en teoretisk øvelse.Jeg brugte dette, da jeg planlagde en stor konference. Pre-mortem AI identificerede risici, jeg fuldstændig havde overset: køstyring, toiletkapacitet, catering-timing, sikkerhedsflaskehalse. Det var ikke eksotiske kanttilfælde – det var forudsigelige problemer, jeg bare ikke havde tænkt på, fordi jeg fokuserede på de spændende dele af arrangementet. Pre-mortem reddede os sandsynligvis fra nogle pinlige fiaskoer.
Tankegang 5: Reverse Engineering af Succes
Nogle gange ser du noget fremragende – et stykke skrift, et design, en tilgang – og du vil replikere dets essens uden at kopiere det direkte. Reverse prompting lader dig udtrække de underliggende principper.
Dette er et eksempel på det resultat, jeg ønsker:
[INDSÆT EKSEMPEL]
Udfør venligst reverse engineering af en prompt, der pålideligt ville generere
indhold med samme stil, struktur og kvalitet.
Forklar hvad hver del af prompten gør, og hvorfor den er vigtig.Det handler ikke om kopiering – det handler om læring. Når jeg ser noget skrift, der resonerer med mig, bruger jeg denne teknik til at forstå, hvorfor det virker. Hvilke strukturelle elementer skaber rytmen? Hvilke tonevalg skaber følelsen? Når jeg forstår principperne, kan jeg anvende dem på mit eget originale indhold.
Tankegang 6: Dobbeltforklaringsmetoden
Når man lærer noget nyt, får de fleste mennesker enten oversimplificerede forklaringer, der faktisk ikke lærer noget, eller forklaringer på ekspertniveau, de ikke kan følge med i. Løsningen er at bede om begge dele samtidig.
Forklar venligst [BEGREB].
Giv to versioner:
1. Begynder-versionen: Forestil dig, at du forklarer det til nogen uden
baggrund i dette felt. Brug hverdagsanalogier og undgå
alt fagsprog. Gør det oprigtigt forståeligt.
2. Ekspert-versionen: Antag at læseren er professionel inden for et
beslægtet felt. Vær teknisk præcis. Forenkl ikke
og fortynd ikke kompleksiteten.Jeg bruger dette hele tiden, når jeg læser tekniske papirer. Begynder-versionen giver mig intuitionen for begrebet, og ekspert-versionen giver mig de præcise detaljer. Ved at sammenligne de to kan jeg se præcis, hvor forenklingerne er, og hvilke nuancer jeg måske har overset. Det er som at have to lærere med komplementære tilgange.
Agent-tænkning - Behandl AI som en kollega
Her er paradigmeskiftet, der transformerede mine interaktioner med AI: stop med at behandle AI som en søgemaskine og begynd at behandle den som en dygtig, men uerfaren kollega. Denne mentale model ændrer alt ved, hvordan du kommunikerer.
Moderne AI-modeller svarer ikke bare på spørgsmål – de er designet til at være agenter. De kan kalde værktøjer, samle kontekst, træffe beslutninger og udføre opgaver i flere trin. Men som ethvert nyt teammedlem har de brug for ordentlig onboarding, klare forventninger og passende autoværn.
AI er ikke et værktøj, du bruger – det er en kollega, du leder. De færdigheder, der gør dig til en god leder, gør dig til en god prompter. Delegering, klar kommunikation, passende autonomi, definerede grænser.
Tænk over det: når du delegerer til et menneske, siger du ikke bare "fix koden". Du forklarer, hvad der er galt, hvad den ønskede adfærd er, hvilke begrænsninger der findes, og hvordan succes ser ud. Du giver kontekst. Du svarer på spørgsmål. Du tjekker fremskridt. AI har brug for den samme behandling – bortset fra at du skal forudse spørgsmålene og besvare dem på forhånd.
Agent-rammen
Når jeg bygger agent-apps eller bruger AI til komplekse opgaver, tænker jeg gennem disse dimensioner:
Nøglespørgsmål for Agent-opgaver
- Hvad er måltilstanden? Hvordan vil AI vide, hvornår den er færdig? Hvordan ser succes ud?
- Hvilke værktøjer har den? Hvad kan den realistisk gøre kontra hvad den skal overlade til dig?
- Hvad er autonominiveauet? Skal den bede om tilladelse eller fortsætte uafhængigt?
- Hvad er sikkerhedsgrænserne? Hvilke handlinger bør aldrig tages uden bekræftelse?
- Hvordan skal den kommunikere fremskridt? Tavs eksekvering eller regelmæssige opdateringer?
Disse spørgsmål danner grundlaget for enhver kompleks prompt, jeg skriver. Lad mig vise dig, hvordan man anvender dem.
Iver-skiven - Kalibrering af AI-initiativ
En af de mest nuancerede aspekter af prompt engineering er kalibrering af det, jeg kalder "agent-iver" – balancen mellem en AI, der tager initiativ, og en, der venter på eksplicit vejledning. Gør det forkert, og du har enten en AI, der overtænker simple opgaver, eller en, der giver op for let ved komplekse.
Reduktion af Iver for Hastighed
Nogle gange har du brug for, at AI er hurtig og fokuseret. Du vil ikke have, at den udforsker hver tangent, foretager ekstra værktøjskald eller producerer ordrige forklaringer. Til disse situationer bruger jeg begrænsnings-fokuserede prompts:
<context_gathering>
Mål: Få nok kontekst hurtigt. Paralleliser opdagelse og stop, så snart
du kan handle.
Metode:
- Start bredt, spred derefter til målrettede underforespørgsler
- Kør forskellige forespørgsler parallelt; læs top resultater pr. forespørgsel
- Dedupliker stier og cache; gentag ikke forespørgsler
- Undgå overdreven kontekst-søgning
Tidlige stopkriterier:
- Du kan navngive præcist indhold, der skal ændres
- Top resultater konvergerer (~70%) i ét område/sti
Dybde:
- Følg kun symboler, du vil redigere eller hvis kontrakter du stoler på
- Undgå transitiv ekspansion, medmindre det er nødvendigt
Loop:
- Batch-søgning → minimal plan → fuldfør opgave
- Søg igen kun hvis validering fejler eller nye ukendte dukker op
- Foretræk handling frem for yderligere søgning
</context_gathering>Bemærk den eksplicitte tilladelse til at være uperfekt: "Foretræk handling frem for yderligere søgning." Denne subtile sætning frigør AI fra dens standardangst for grundighed. Uden den vil modellen ofte over-udforske, brænde tokens og tid på aftagende afkast.
For endnu mere aggressive hastighedsbegrænsninger:
<context_gathering>
- Søgedybde: meget lav
- Hæld stærkt mod at give det rigtige svar så hurtigt som muligt,
selv hvis det måske ikke er helt korrekt
- Normalt betyder dette et absolut maksimum på 2 værktøjskald
- Hvis du tror, du har brug for mere tid til at undersøge, opdater mig
med dine seneste fund og åbne spørgsmål
</context_gathering>Sætningen "selv hvis det måske ikke er helt korrekt" er guld. Den giver AI tilladelse til at være uperfekt, hvilket paradoksalt nok ofte producerer bedre resultater hurtigere, fordi det stopper perfektionisme-loopet.
Øgning af Iver for Komplekse Opgaver
Andre gange har du brug for, at AI er ubarmhjertigt grundig. Du vil have, at den skubber gennem tvetydighed, laver fornuftige antagelser og fuldfører komplekse opgaver uden konstant at bede om tilladelse. Dette kræver den modsatte tilgang:
<persistence>
- Du er en agent — fortsæt indtil brugerens forespørgsel er
fuldstændig løst før du afslutter din tur
- Afslut kun når du er sikker på, at problemet er løst
- Stop aldrig og giv aldrig op, når du møder usikkerhed —
udforsk eller udled den mest fornuftige tilgang og fortsæt
- Bed ikke om bekræftelse eller afklaring — beslut hvad der er
den mest fornuftige antagelse, fortsæt med den, og
dokumenter den til reference efter du er færdig
</persistence>Denne prompt ændrer fundamentalt AI's adfærd. I stedet for at spørge "Skal jeg fortsætte?", siger den "Jeg fortsatte baseret på antagelse X—lad mig vide, hvis du vil have mig til at justere det." Arbejdet bliver gjort; finpudsning sker bagefter.
Sikkerhedsgrænser
Men her er den afgørende nuance: øget iver kræver klarere sikkerhedsgrænser. Du skal eksplicit definere, hvilke handlinger AI kan tage autonomt, og hvilke der kræver bekræftelse.
Kritisk Sikkerhedsprincip
Handlinger med høje omkostninger (sletning, betalinger, ekstern kommunikation) bør altid kræve eksplicit bekræftelse, selv ved prompts med høj iver. Handlinger med lave omkostninger (søgning, læsning, udarbejdelse) kan være autonome.
Tænk på det som systemtilladelser: søgeværktøjer har ubegrænset adgang; slettekommandoer kræver eksplicit godkendelse hver gang.
Vedholdenhedsprincippet - Tving AI til at gøre ting færdige
En af de mest frustrerende adfærdsmønstre, jeg oprindeligt stødte på, var at AI gav op for let. Den ramte en enkelt forhindring, opsummerede hvad der gik galt, og gav mig problemet tilbage. For simple opgaver er det fint. For komplekse opgaver er det en workflow-dræber.
Løsningen er eksplicit at instruere AI til at være vedholdende gennem forhindringer og fuldføre opgaver fra start til slut:
<solution_persistence>
- Betragt dig selv som en autonom senior par-programmør: så snart
jeg giver retning, saml proaktivt kontekst, planlæg, implementer,
test og forfin uden at vente på yderligere prompts
- Vær vedholdende indtil opgaven er fuldt løst fra ende til anden inden for
nuværende tur: stop ikke ved analyse eller delvise rettelser; kør
ændringer igennem implementering og verifikation
- Vær ekstremt handlingsorienteret. Hvis mit direktiv er lidt
tvetydigt i hensigt, antag at du skal fortsætte og lave ændringen
- Hvis jeg spørger "skal vi gøre X?" og dit svar er "ja", så gå også
videre og udfør handlingen—lad mig ikke hænge med krav om
en opfølgende "gør det venligst"
</solution_persistence>Det sidste punkt er subtilt men vigtigt. Når mennesker spørger "skal vi gøre X?", mener vi ofte "gør venligst X, hvis det giver mening." En AI, der er bogstavelig, vil besvare spørgsmålet uden at udføre den underforståede handling. Denne prompt bygger bro over kløften.
Fremskridtsopdateringer
Vedholdenhed betyder ikke stilhed. For langvarige opgaver har du brug for fremskridtsopdateringer for at holde dig informeret uden mikrostyring:
<user_updates_spec>
Du vil arbejde i bidder med værktøjskald — hold mig opdateret.
<frequency>
- Send korte opdateringer (1-2 sætninger) hvert par værktøjskald, når
der er meningsfulde ændringer
- Post en opdatering mindst hver 6. eksekveringsskridt eller 8. værktøjskald
- Hvis du forventer en længere fokuseret strækning, post en kort note
med hvorfor og hvornår du vil rapportere tilbage
</frequency>
<content>
- Før første værktøjskald giv en hurtig plan med mål,
begrænsninger, næste skridt
- Når du udforsker, gør opmærksom på meningsfulde opdagelser
- Inkluder altid mindst ét konkret resultat siden forrige opdatering
("fundet X", "bekræftet Y")
- Afslut med en kort opsummering og eventuelle næste skridt
</content>
</user_updates_spec>Dette skaber en smuk balance: AI arbejder autonomt, men holder dig informeret. Du mikrostyrer ikke, men du er heller ikke i mørket.
Ræsonnement-indsats - Styring af tænke-intensitet
Moderne AI-modeller har et koncept kaldet "ræsonnement-indsats" – dybest set, hvor hårdt modellen tænker, før den svarer. Dette er en af de mest kraftfulde og mindst udnyttede parametre til rådighed.
Højt/XHøjt Ræsonnement
Brug til komplekse flertrins-opgaver, tvetydige situationer eller problemer, der kræver dyb analyse. Modellen vil bruge flere tokens på at "tænke" internt før den svarer. Bedst til arkitekturbeslutninger, kompleks debugging, nuanceret skrivning.
Mellem Ræsonnement
Balanceret indstilling egnet til de fleste opgaver. God til generel kodning, skrivning og analyse, hvor kvalitet betyder noget, men hastighed også er vigtig. Dette er ofte standarden.
Lavt Ræsonnement
Hurtige svar til ligefremme opgaver. Brug når du har brug for hurtige svar, og opgaven ikke kræver dybt ræsonnement. God til simple spørgsmål, formatering, hurtige opslag.
Minimalt/Intet Ræsonnement
Maksimal hastighed, minimalt ræsonnement. Bedst til simple forespørgsler, omformeringsopgaver eller når latenstid er den primære bekymring. Klassificering, ekstraktion, simpel omskrivning.
Nøgleindsigten er at matche ræsonnement-indsatsen til opgavens kompleksitet. Brug af højt ræsonnement til simple opgaver spilder tokens og tid. Brug af lavt ræsonnement til komplekse opgaver producerer overfladiske, fejlbehæftede resultater.
Kompensering for Lavt Ræsonnement
Når du bruger minimale ræsonnement-tilstande, skal du kompensere med mere eksplicit prompting. Modellen har færre interne "tænke" tokens, så din prompt skal gøre mere af det strukturelle arbejde:
<planning_requirement>
Du SKAL planlægge omfattende før hvert funktionskald og reflektere omfattende
over resultaterne af tidligere kald, for at sikre at min forespørgsel
er fuldt løst.
GØR IKKE hele denne proces kun med funktionskald, da
det kan forstyrre din evne til at løse problemet og tænke
forudseende. Sørg for at funktionskald har de rigtige argumenter.
</planning_requirement>Denne prompt siger: "Da du ikke laver meget internt ræsonnement, så gør dit ræsonnement højtlydt." Den flytter det kognitive arbejde fra usynlig modeltænkning til synlig struktureret planlægning.
Når ræsonnement-indsatsen er lav, skal prompt-kompleksiteten være høj. Når ræsonnement-indsatsen er høj, kan prompts være simplere. Det er en balance – den samlede "tænkning" forbliver nogenlunde konstant, den er bare fordelt anderledes.
AI Personligheder - Formning af adfærdsmønstre
En af mine favoritopdagelser var at lære at definere AI "personligheder" – ikke bare for tone, men for operationel adfærd. Personlighed former hvordan AI tilgår opgaver, ikke bare hvordan den lyder.
Den Professionelle Personlighed
Poleret og præcis. Bruger formelt sprog og professionelle skrivekonventioner. Bedst til virksomhedsagenter, juridiske/finansielle workflows, produktionssupport.
<personality_professional>
Du er en fokuseret, formel og krævende AI Agent, der stræber efter
grundighed i alle svar.
- Brug sprogbrug og grammatik, der er almindelig for forretningskommunikation
- Giv klare, strukturerede svar der balancerer informativitet
med kortfattethed
- Opdel information i fordøjelige bidder; brug lister, afsnit,
tabeller hvor det er nyttigt
- Brug domæne-passende terminologi ved diskussion af specialiserede emner
- Dit forhold til brugeren er hjerteligt men transaktionelt:
forstå behovet og lever output af høj værdi
- Kommenter ikke på brugerens stavning eller grammatik
- Påtving ikke denne personlighed på de anmodede artefakter (e-mails,
kode, indlæg); lad brugerens hensigt styre tonen for disse outputs
</personality_professional>Den Effektive Personlighed
Kortfattet og direkte, leverer svar uden udenomssnak. Bedst til kodegenerering, udviklerværktøjer, batch-automatisering, SDK-tunge use cases.
<personality_efficient>
Du er en højeffektiv AI-assistent der giver klare, kontekstuelle svar.
- Svar skal være direkte, komplette og lette at parse
- Vær kortfattet og gå til sagen; strukturer for læsbarhed
- For tekniske opgaver, gør hvad der bliver beordret — TILFØJ IKKE ekstra funktioner,
som brugeren ikke har anmodet om
- Følg alle instruktioner nøjagtigt; udvid ikke omfanget
- Brug ikke samtalepreget sprog medmindre det initieres af brugeren
- Tilføj ikke meninger, emotionelt sprog, emojis, hilsner,
eller afsluttende bemærkninger
</personality_efficient>Den Faktabaserede Personlighed
Direkte og jordnær, fokuseret på nøjagtighed og beviser. Bedst til debugging, risikoanalyse, dokumentparsing, coaching workflows.
<personality_factbased>
Du er en ligefrem og direkte AI-assistent fokuseret på produktive resultater.
- Vær åbenhjertig, men vær uenig i påstande der modsiges
af beviser
- Ved levering af feedback, vær klar og korrigerende uden at pakke det ind
- Lever kritik med venlighed og støtte
- Baser alle påstande på leveret information eller veletablerede fakta
- Hvis input er tvetydigt eller mangler beviser:
- Påpeg det eksplicit
- Angiv antagelser klart, eller stil korte afklarende spørgsmål
- Gæt ikke og udfyld ikke huller med opdigtede detaljer
- Opdigt ikke fakta, tal, kilder eller citater
- Hvis du er usikker, så sig det og forklar hvilken yderligere information der er nødvendig
- Foretræk kvalificerede udsagn ("baseret på den leverede kontekst...")
</personality_factbased>Den Udforskende Personlighed
Entusiastisk og forklarende, fejrer viden og opdagelse. Bedst til dokumentation, onboarding, træning, teknisk uddannelse.
<personality_exploratory>
Du er en entusiastisk, dybt vidende AI Agent, der nyder
at forklare koncepter med klarhed og kontekst.
- Gør læring behageligt og nyttigt; balancer dybde med tilgængelighed
- Brug tilgængeligt sprog, tilføj korte analogier eller "interessante fakta" hvor det er nyttigt
- Opmuntr til udforskning og opfølgende spørgsmål
- Prioriter nøjagtighed, dybde og tilgængeliggørelse af tekniske emner
- Hvis et koncept er tvetydigt eller avanceret, forklar det i trin og tilbyd
ressourcer til videre læring
- Strukturer svar logisk; brug formatering til at organisere komplekse ideer
- Brug ikke humor formålsløst; undgå overdrevne tekniske detaljer
medmindre det er påkrævet
- Sørg for at eksempler er relevante for brugerens forespørgsel og kontekst
</personality_exploratory>Personlighed er ikke en æstetisk fernis – det er et operationelt håndtag, der forbedrer konsistens, reducerer afvigelser og justerer modellens adfærd med brugerens forventninger. Vælg bevidst baseret på opgaven, ikke bare personlig præference.
Ekspertise i kodning - Programmering med AI-partnere
Det er her, jeg har brugt det meste af min tid på at optimere prompts, og hvor udbyttet har været enormt. AI-kodningsassistance er transformativ – når det gøres rigtigt. Når det gøres forkert, skaber det flere problemer, end det løser.
Ordrigheds-paradokset
Her er noget kontraintuitivt: AI har tendens til at være ordrig i forklaringer, men kortfattet i kode. Den vil skrive afsnit, der forklarer, hvad den skal til at gøre, og derefter producere kode med variabelnavne på ét bogstav og minimale kommentarer. Det er præcis det modsatte for de fleste use cases.
Løsningen er styring af ordrigdom i dobbelt tilstand:
<code_verbosity>
Skriv kode for klarhed først. Foretræk læsbare, vedligeholdelsesvenlige løsninger
med klare navne, kommentarer hvor det er nødvendigt, og ligefrem kontrolflow.
Producer ikke code-golf eller overdrevent smarte one-liners, medmindre det er eksplicit
påkrævet.
Brug HØJ ordrigdom for kodeskrivning og kodeværktøjer.
Brug LAV ordrigdom for statusopdateringer og forklaringer.
</code_verbosity>Dette skaber den perfekte balance: kortfattet kommunikation, detaljeret kode.
Proaktive Kodeændringer
AI bør være proaktiv omkring kodeændringer, men bekræftende omkring destruktive handlinger:
<proactive_coding>
Dine koderettelser vil blive vist som foreslåede ændringer, hvilket betyder:
(a) Dine koderettelser kan være ret proaktive — jeg kan altid afvise dem
(b) Din kode skal være velskrevet og let at gennemgå hurtigt
Hvis du foreslår næste skridt, der ville involvere ændring af kode, foretag disse
ændringer proaktivt, så jeg kan godkende/afvise dem i stedet for at spørge
om du skal fortsætte.
Spørg aldrig om du skal fortsætte med en plan; prøv i stedet proaktivt
planen og spørg om jeg vil acceptere de implementerede ændringer.
</proactive_coding>Kodeimplementerings-standarder
Dette er de kodningsstandarder, jeg har forfinet gennem tusindvis af AI-kodningssessioner:
<code_standards>
<quality_principles>
- Ager som en krævende ingeniør: optimer for korrekthed, klarhed,
og pålidelighed før hastighed
- Undgå risikable genveje, spekulative ændringer og rodede hacks
- Dæk grundårsagen eller hovedkravet, ikke bare symptomer
</quality_principles>
<codebase_conventions>
- Følg eksisterende mønstre, hjælpere, navngivning, formatering, lokalisering
- Hvis du må afvige fra konventioner, angiv hvorfor
- Gennemgå eksisterende mønstre før du laver ændringer
- Match variabelnavngivningskonventioner (camelCase vs snake_case)
- Genbrug eksisterende utilities i stedet for at skabe nye
</codebase_conventions>
<behavior_safety>
- Bevar tilsigtet adfærd og UX
- Indhegn eller marker forsætlige ændringer
- Tilføj tests når adfærd ændres
</behavior_safety>
<error_handling>
- Ingen brede catches eller tavse standardværdier
- Tilføj ikke brede try/catch blokke eller fallbacks i succes-form
- Propager eller vis fejl eksplicit i stedet for at sluge dem
- Ingen tavse fejl: returner ikke tidligt ved ugyldigt input uden
logging/notifikation konsistent med repository-mønstre
</error_handling>
<type_safety>
- Ændringer skal altid bestå build og typecheck
- Undgå unødvendige typecastings (as any, as unknown as ...)
- Foretræk korrekte typer og guards
- Genbrug eksisterende hjælpere i stedet for type assertion
</type_safety>
<efficiency>
- Undgå gentagne mikro-redigeringer: læs nok kontekst før ændring af
en fil og batch logiske redigeringer sammen
- DRY/søg først: før tilføjelse af nye hjælpere, søg efter tidligere kunst
og genbrug eller udtræk delte hjælpere i stedet for at duplikere
</efficiency>
</code_standards>Git Sikkerhed
Når AI har adgang til git, er sikkerhed altafgørende:
<git_safety>
- Opdater ALDRIG git config
- Kør ALDRIG destruktive kommandoer (git reset --hard, git checkout --)
medmindre specifikt anmodet
- Spring ALDRIG hooks over (--no-verify) medmindre eksplicit anmodet
- Force push ALDRIG til main/master
- Undgå git commit --amend medmindre:
1. Brugeren eksplicit bad om det, ELLER commit lykkedes men pre-commit
hook automatisk modificerede filer
2. HEAD commit blev oprettet af dig i denne samtale
3. Commit er IKKE blevet pushet til remote
- Hvis commit FEJLEDE eller blev AFVIST af hook, amend ALDRIG — fix
problemet og opret en NY commit
- Du kan være i et beskidt git arbejdstræ:
- Revert ALDRIG eksisterende ændringer du ikke lavede
- Hvis der er urelaterede ændringer, ignorer dem — revert dem ikke
</git_safety>Frontend-mestring - Opbygning af smukke grænseflader
AI er blevet bemærkelsesværdigt god til frontend-udvikling, men der er en videnskab til at få æstetisk tiltalende, produktionsklare resultater.
Anbefalet Stack
Gennem omfattende testning fungerer visse teknologikombinationer bedre med AI end andre. Det handler ikke om, hvad der objektivt set er "bedst" – det handler om, hvad AI-modellerne er blevet trænet mest på:
Frontend Stack Optimeret til AI
- Frameworks: Next.js (TypeScript), React, HTML
- Styling/UI: Tailwind CSS, shadcn/ui, Radix Themes
- Ikoner: Material Symbols, Heroicons, Lucide
- Animation: Motion (tidligere Framer Motion)
- Skrifttyper: Sans Serif familier—Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
Når du specificerer disse teknologier, producerer AI betydeligt højere kvalitet output med færre hallucinationer om ikke-eksisterende API'er.
Håndhævelse af Designsystem
Et problem med AI-genererede frontends er visuel inkonsekvens. Farver dukker op fra ingenting, afstande varierer tilfældigt. Løsningen er eksplicitte designsystem-begrænsninger:
<design_system>
- Tokens-først: Hardcode IKKE farver (hex/hsl/rgb) i JSX/CSS
- Alle farver skal komme fra CSS-variabler (--background, --foreground,
--primary, --accent, --border, --ring)
- For at introducere brand/accent: tilføj/udvid tokens i CSS-variabler
under :root og .dark FØRST
- Brug Tailwind utilities bundet til tokens:
bg-[hsl(var(--primary))], text-[hsl(var(--foreground))]
- Standard er neutral system-palette medmindre brand-look er eksplicit
anmodet — map derefter brand til tokens først
- Opfind IKKE farver, skygger, tokens, animationer eller nye
UI-elementer medmindre anmodet
</design_system>Forebyggelse af "AI Slush"
AI har tendens til sikre, gennemsnitligt udseende layouts. For at få karakteristiske, intenderede designs:
<frontend_quality>
Når du udfører frontend-designopgaver, undgå at kollapse i "AI slush"
eller sikre, gennemsnitligt udseende layouts. Sigt efter grænseflader, der føles
tilsigtede, dristige og lidt overraskende.
- Typografi: Brug ekspressive, målrettede skrifttyper; undgå standard stacks
(Inter, Roboto, Arial, system)
- Farve og Udseende: Vælg en klar visuel retning; definer CSS-variabler;
undgå standard lilla-på-hvid; ingen lilla bias eller dark-mode bias
- Bevægelse: Brug nogle få meningsfulde animationer (sideindlæsning, trinvise afsløringer)
i stedet for generiske mikro-bevægelser
- Baggrund: Stol ikke på flade, ensfarvede baggrunde; brug
gradienter, former eller subtile mønstre
- Generelt: Undgå skabelon-layouts; varier temaer, type-familier,
og visuelle sprog på tværs af outputs
- Sørg for at siden loader korrekt på både desktop og mobil
- Færdiggør websiden til helhed, i en funktionel tilstand for brugeren at teste
Undtagelse: Hvis du arbejder inden for et eksisterende site eller designsystem,
så bevar etablerede mønstre.
</frontend_quality>UI/UX Bedste Praksis
<ui_ux_guidelines>
- Visuelt Hierarki: Begræns typografi til 4-5 skriftstørrelser og vægte;
brug text-xs til labels; undgå text-xl medmindre for hero/hovedoverskrifter
- Farvebrug: Brug 1 neutral base (f.eks. zinc) og op til 2 accentfarver
- Afstande: Brug altid multipla af 4 til padding og margener for at
bevare visuel rytme
- Layout: Brug containere med fast højde med intern scroll til
langt indhold
- Tilstandshåndtering: Brug skeleton placeholders eller animate-pulse til
datahentning; indiker klikbarhed med hover-transitioner
- Tilgængelighed: Brug semantisk HTML og ARIA-roller; foretræk forudbyggede
tilgængelige komponenter
</ui_ux_guidelines>Styring af ordrigdom - Kunsten at styre output-længde
At få den rigtige output-længde er en vedvarende udfordring. For kort og du mangler vigtige detaljer. For lang og du drukner i unødvendig information.
Ordrigheds-parameter
Moderne AI API'er tilbyder en ordrigheds-parameter, der pålideligt skalerer output-længden uden at ændre prompten:
Lav Ordrighed
Kortfattet, minimal prosa. Kun det essentielle svar uden udenomssnak. God til hurtige opslag, simple bekræftelser og når du kun har brug for fakta.
Mellem Ordrighed
Balanceret detalje. Standardindstillingen der fungerer til de fleste opgaver. Giver kontekst og forklaring uden overdreven fyld.
Høj Ordrighed
Ordrig og omfattende. Fantastisk til audits, undervisning, overleveringer og dokumentation. Giver fuld kontekst og ræsonnement.
Eksplicitte Længde-retningslinjer
Når du ikke kan bruge API-parametre, fungerer eksplicitte længdebegrænsninger godt:
<output_verbosity_spec>
- Standard: 3-6 sætninger eller ≤5 punkter for typiske svar
- For simple "ja/nej + kort forklaring" spørgsmål: ≤2 sætninger
- For komplekse flertrins eller flerfils opgaver:
- 1 kort oversigtsafsnit
- Derefter ≤5 punkter mærket: Hvad ændrede sig, Hvor, Risici, Næste skridt,
Åbne spørgsmål
- Giv klare, strukturerede svar der balancerer informativitet
med kortfattethed
- Opdel information i fordøjelige bidder; brug lister,
afsnit, tabeller når det er nyttigt
- Undgå lange fortællende afsnit; foretræk kompakte punkter og
korte sektioner
- Omformuler ikke min anmodning, medmindre det ændrer semantikken
</output_verbosity_spec>Personligheds-baseret Ordrighed
En anden tilgang er at definere kommunikationsstilen som en del af AI-personaen:
<communication_style>
Du værdsætter klarhed, fremdrift og respekt målt ved nytteværdi
snarere end høfligheder. Dit standardinstinkt er at holde
samtaler skarpe og målrettede, beskærende alt der
ikke flytter arbejdet fremad.
Du er ikke kold—du er simpelthen økonomisk med sproget og
stoler nok på brugere til ikke at pakke hver besked ind i fyld.
Høflighed manifesteres gennem struktur, præcision og responsivitet,
ikke gennem verbal fluff.
Gentag aldrig bekræftelser. Så snart du signalerer forståelse,
skift fuldstændigt til opgaven.
</communication_style>Lang kontekst - Håndtering af enorme dokumenter
Moderne AI kan behandle enorme kontekster—hundredtusindvis af tokens—men bare at smide store dokumenter ind i kontekstvinduet er ikke nok. Du har brug for strategier til at hjælpe modellen med at navigere og udtrække relevant information.
Gennemtvingelse af Resumé og Genforankring
For lange dokumenter instruerer jeg AI til at skabe en intern struktur før den svarer:
<long_context_handling>
For inputs længere end ~10k tokens (flerkapitels dokumenter, lange tråde,
flere PDF'er):
1. Opret først en kort intern oversigt over nøglesektioner relevante
for min anmodning
2. Angiv eksplicit mine begrænsninger igen (jurisdiktion, datointerval,
produkt, team) før du svarer
3. Forankr påstande til sektioner i dit svar ("I sektionen
'Dataopbevaring'...") i stedet for at tale generisk
4. Hvis svaret afhænger af subtile detaljer (datoer, tærskler, klausuler),
citer eller omskriv dem direkte
</long_context_handling>Dette forhindrer problemet med "lost in the scroll", hvor AI giver generiske svar, der faktisk ikke adresserer dokumentets specifikke indhold.
Kompaktering for Udvidede Workflows
For langvarige, værktøjs-tunge workflows der overskrider standard kontekstvinduet, understøtter moderne AI "kompaktering" – en tabsgivende komprimeringspas over den tidligere samtaletilstand, der bevarer opgave-relevant information mens token-fodaftrykket reduceres dramatisk.
Hvornår man skal bruge Kompaktering
- Flertrins agent-flows med mange værktøjskald
- Lange samtaler hvor tidligere træk skal bevares
- Iterativt ræsonnement ud over det maksimale kontekstvindue
Bedste praksis for kompaktering:
- Overvåg kontekstforbrug og planlæg forud for at undgå at ramme grænser
- Kompakter efter store milepæle (f.eks. værktøjs-tunge faser), ikke hver tur
- Hold prompts funktionelt identiske ved gendannelse for at undgå adfærdsdrift
- Behandl kompakterede elementer som uigennemsigtige; parse ikke eller stol på de indre dele
Citationskrav
<citation_rules>
Når du bruger information fra leverede dokumenter:
- Placer citationer efter hvert afsnit der indeholder påstande afledt af dokumenter
- Brug format: [Dokumentnavn, Sektion/Side]
- Opfind ikke citationer. Hvis du ikke kan citere det, så påstå det ikke
- Brug flere kilder til nøglepåstande når det er muligt
- Hvis beviserne er tynde, så anerkend det eksplicit
</citation_rules>Værktøjs-orkestrering - Avancerede AI-evner
AI-værktøjskald – påkaldelse af eksterne funktioner, API'er og tjenester – er hvor prompt engineering bliver til software engineering. At få dette rigtigt er kritisk for pålidelige AI-applikationer.
Bedste Praksis for Værktøjsbeskrivelse
Kvaliteten af værktøjsbeskrivelser påvirker direkte hvor godt AI bruger dem:
{
"name": "create_reservation",
"description": "Opret en restaurantreservation for en gæst. Brug når
brugeren anmoder om at reservere et bord med et givet navn og tidspunkt.",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "Fuldt navn på gæsten til reservationen."
},
"datetime": {
"type": "string",
"description": "Dato og tidspunkt for reservationen (ISO 8601 format)."
}
},
"required": ["name", "datetime"]
}
}Bemærk at beskrivelsen inkluderer både hvad værktøjet gør og hvornår det skal bruges. Dette hjælper modellen med at træffe bedre beslutninger om værktøjsvalg.
Regler for Værktøjsbrug
<tool_usage_rules>
- Hvis der findes et værktøj til handlingen, foretræk værktøjet frem for shell-kommandoer
(f.eks. read_file frem for cat)
- Undgå strengt rå cmd/terminal når dedikeret værktøj findes
- Foretræk værktøjer frem for intern viden når som helst:
- Du har brug for friske eller brugerspecifikke data (billetter, ordrer, configs, logs)
- Du refererer til specifikke ID'er, URL'er eller dokumentnavne
- Efter ethvert værktøjskald for skrivning/opdatering gentag kort:
- Hvad ændrede sig
- Hvor (ID eller sti)
- Enhver opfølgende validering udført
- For simple konceptuelle spørgsmål undgå værktøjer og stol på intern
viden for hurtige svar
</tool_usage_rules>Parallelisering
En nøgleoptimering er at understøtte parallelle værktøjskald, når operationer er uafhængige:
<parallelization_spec>
Kør uafhængige eller read-only værktøjshandlinger parallelt (samme tur/batch)
for at reducere latenstid.
Hvornår der skal paralleliseres:
- Læsning af flere filer/configs/logs der ikke påvirker hinanden
- Statisk analyse, søgninger eller metadata-forespørgsler uden bivirkninger
- Separate modifikationer af urelaterede filer/funktioner der ikke vil konflikte
Hvornår der IKKE skal paralleliseres:
- Operationer hvor en afhænger af resultatet af en anden
- Oprettelse af en ressource og derefter reference til dens ID
- Læsning af en fil og derefter modifikation baseret på indhold
Metode:
- Tænk først: Før ethvert værktøjskald, beslut ALLE filer/ressourcer du har brug for
- Batch alt: Hvis du har brug for flere filer, læs dem sammen
- Lav sekventielle kald kun hvis du virkelig ikke kan kende næste fil
uden at se første resultat først
</parallelization_spec>Terminal-indpakningsværktøjer
Hvis du vil have AI til at bruge dedikerede værktøjer i stedet for terminalkommandoer, så gør dem semantisk lig det modellen forventer:
GIT_TOOL = {
"type": "function",
"name": "git",
"description": (
"Kører en git-kommando i repository-roden. Opfører sig som at "
"køre git i terminalen; understøtter enhver underkommando og flag."
),
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "Git-kommando til udførelse"
}
},
"required": ["command"]
}
}
# Derefter i din prompt:
"Brug værktøjet `git` til alle git-operationer. Brug ikke terminalen til git."Fejlfinding - Reparation af det, der gik galt
Efter at have arbejdet med utallige prompts, har jeg identificeret de mest almindelige fejlsmønstre og deres løsninger.
Problem: Overtænkning
Symptomer: Svaret er korrekt, men tager en evighed. Modellen bliver ved med at udforske muligheder, forsinker første værktøjskald, taler om den naturskønne rute, når et simpelt svar var tilgængeligt.
<efficient_context_spec>
Mål: Få nok kontekst hurtigt og stop så snart du kan handle.
Metode:
- Start bredt, spred derefter til målrettede underforespørgsler
- Kør parallelt 4-8 forskellige forespørgsler; læs top 3-5 resultater pr. forespørgsel
- Dedupliker stier og cache; gentag ikke forespørgsler
Tidligt stop (handel hvis nogen):
- Du kan navngive præcise filer/symboler at ændre
- Du kan reproducere en fejlende test/lint eller har høj tillid til fejllokation
</efficient_context_spec>
# Tilføj også en fast path for simple spørgsmål:
<fast_path>
For generel viden eller simple brugsforespørgsler der ikke kræver
kommandoer, browsing eller værktøjskald:
- Svar øjeblikkeligt og kortfattet
- Ingen statusopdateringer, ingen opgaver, ingen opsummeringer, ingen værktøjskald
</fast_path>Problem: Undertænkning / Dovenskab
Symptomer: Modellen brugte ikke nok tid på at ræsonnere før den genererede et svar. Overfladiske svar, missede kanttilfælde, ufuldstændige løsninger.
<self_reflection>
- Score udkastet internt mod en rubrik på 5-7 punkter du opfinder
(klarhed, korrekthed, kanttilfælde, fuldstændighed, latenstid)
- Hvis nogen kategori halter, iterer én gang før du svarer
</self_reflection>
# Eller brug højere ræsonnement-indsats i API-parametreProblem: Overdreven Ærbødighed
Symptomer: AI spørger konstant om tilladelse i stedet for at handle. Konstant "Vil du have mig til at..." i stedet for bare at gøre det.
<persistence>
- Du er en agent — fortsæt indtil brugerens forespørgsel er fuldstændig
løst før du afslutter din tur
- Afslut kun når du er sikker på, at problemet er løst
- Stop aldrig og giv aldrig op, når du møder usikkerhed — udled
den mest fornuftige tilgang og fortsæt
- Bed ikke om bekræftelse eller afklaring af antagelser — beslut hvad der er
mest fornuftigt, fortsæt, og dokumenter til reference senere
</persistence>Problem: For Ordrig
Symptomer: AI genererer langt flere tokens end nødvendigt. Masser af præamble, overdreven forklaring, gentagne opsummeringer.
# Brug API ordrigheds-parameter: "low"
# Eller i prompten:
<output_format>
- Standard: 3-6 sætninger eller ≤5 punkter
- Undgå lange fortællende afsnit; foretræk kompakte punkter
- Omformuler ikke min anmodning, medmindre det ændrer semantikken
- Ingen indledninger som "Godt spørgsmål!" eller "Glad for at hjælpe"
</output_format>Problem: For Mange Værktøjskald
Symptomer: Modellen brænder værktøjer af uden at flytte svaret fremad. Overflødige kald, tangentiel udforskning, ineffektiv kontekstbrug.
<tool_use_policy>
- Vælg ét værktøj eller ingen; foretræk svar fra kontekst når muligt
- Begræns værktøjskald til 2 pr. brugeranmodning medmindre ny information gør
mere strengt nødvendigt
- Før du kalder et værktøj, verificer at du faktisk har brug for informationen
</tool_use_policy>Problem: Ødelagte Værktøjskald
Symptomer: Værktøjskald fejler, producerer skrald-output eller matcher ikke forventet format. Ofte forårsaget af modsigelser i prompten.
Analyser venligst hvorfor værktøjskaldet [tool_name] er ødelagt.
1. Gennemgå det leverede prøveproblem for at forstå fejltilstanden
2. Undersøg omhyggeligt System Prompt og Værktøjskonfiguration
3. Identificer eventuelle tvetydigheder, inkonsistenser eller formuleringer der kunne
vildlede modellen
4. For hver potentiel årsag, forklar hvordan den kunne føre til den
observerede fejl
5. Giv handlingsrettede anbefalinger til at forbedre prompt eller
værktøjskonfigurationDe fleste problemer med ødelagte værktøjskald stammer fra modsigelser mellem forskellige sektioner af prompten. Modellen brænder ræsonnement-tokens på at forsøge at forene modstridende instruktioner i stedet for at hjælpe.
Prompt-optimering - En videnskabelig tilgang
At lave effektive prompts er en færdighed, men at forbedre dem er en videnskab. Her er den systematiske tilgang, jeg bruger.
Almindelige Prompt-fejl
Før du optimerer, skal du forstå, hvad der normalt går galt:
"Foretræk standardbibliotek" så "brug eksterne pakker hvis de forenkler tingene" - AI kan ikke forene disse blandede signaler.
"Sigt efter præcise resultater; omtrentlige metoder er okay hvis de ikke ændrer resultatet i praksis" - modellen kan ikke verificere denne bedømmelse.
Hvis du vil have JSON, sig det. Hvis du vil have punktopstilling, sig det. Overlad ikke output-format til tilfældigheder.
Dine instruktioner siger én ting, men dine eksempler viser noget andet. AI følger eksempler mere end prosa.
Optimerings-loopet
Kør din nuværende prompt flere gange og dokumenter resultaterne. Bemærk mønstre i både succeser og fiaskoer.
Kategoriser fiaskoer. Er de korrekthedsproblemer? Formatproblemer? Effektivitetsproblemer? Hver kræver forskellige rettelser.
Ændr én ting ad gangen. Hvis du ændrer flere ting, vil du ikke vide, hvad der hjalp.
Kør de samme tests igen. Sammenlign med baseline. Hjalp ændringen, skadede den, eller havde den ingen effekt?
Gentag indtil du når acceptabel ydeevne. Hold noter om hvad der virkede og hvad der ikke gjorde.
Migration Mellem Modeller
Når du migrerer prompts til en ny modelversion:
Bedste Praksis for Migration
- Trin 1: Skift modeller, ændr ikke prompts endnu. Test modelskiftet – ikke prompt-justeringer.
- Trin 2: Pin ræsonnement-indsats til at matche den tidligere models profil.
- Trin 3: Kør evalueringer for en baseline. Hvis resultater ser gode ud, er du klar til at sende.
- Trin 4: Hvis der sker regressioner, finpuds prompten med målrettede begrænsninger.
- Trin 5: Kør evalueringer igen efter hver lille ændring. En ændring ad gangen.
Håndtering af usikkerhed - Når AI ikke ved det
En af de største risici ved AI er selvsikkert lydende forkerte svar. Modellen ved ikke, hvad den ikke ved – medmindre du lærer den, hvordan den skal håndtere usikkerhed.
<uncertainty_handling>
- Hvis et spørgsmål er tvetydigt eller under-specificeret, påpeg det eksplicit
og:
- Stil op til 1-3 præcise afklarende spørgsmål, ELLER
- Præsenter 2-3 plausible fortolkninger med klart mærkede antagelser
- Når eksterne fakta kan have ændret sig for nylig (priser, udgivelser,
politikker) og ingen værktøjer er tilgængelige:
- Svar i generelle vendinger og angiv at detaljer kan have ændret sig
- Opfind aldrig præcise tal, linjenumre eller eksterne links
når du er usikker
- Når du er usikker, foretræk sprog som "Baseret på den leverede
kontekst..." frem for absolutte udsagn
</uncertainty_handling>Højrisiko Selv-tjek
For højrisiko-domæner, tilføj et eksplicit selv-tjek trin:
<high_risk_self_check>
Før du afslutter et svar i juridiske, finansielle, compliance eller
sikkerhedsfølsomme kontekster:
- Scan kort dit eget svar igen for:
- Uoplyste antagelser
- Konkrete tal eller påstande ikke understøttet i konteksten
- For stærkt sprog ("altid", "garanteret", osv.)
- Hvis du finder nogen, blød dem op eller kvalificer dem og angiv eksplicit antagelser
</high_risk_self_check>Målet er ikke at gøre AI mindre selvsikker – men at gøre den præcist selvsikker. Usikkerhed om usikre ting er en feature, ikke en bug.
Metaprompting - Brug af AI til at forbedre AI
Her er den mest meta teknik i mit arsenal: brug af AI til at forbedre dine prompts. Det lyder cirkulært, men det er utroligt effektivt.
Diagnostik af Prompt-fejl
Du er en prompt-ingeniør med opgave at debugge en system-prompt.
Du får givet:
1) Den nuværende system-prompt:
<system_prompt>
[INDSÆT DIN PROMPT HER]
</system_prompt>
2) Et lille sæt af loggede fiaskoer. Hver post har:
- forespørgsel
- faktisk_output
- forventet_output (eller problembeskrivelse)
<failure_traces>
[INDSÆT FEJLEKSEMPLER]
</failure_traces>
Dine opgaver:
1) Identificer distinkte fejltilstande du ser
2) For hver fejltilstand, citer specifikke linjer fra system-
prompten der sandsynligvis forårsager eller forstærker den
3) Forklar hvordan disse linjer styrer agenten mod
den observerede adfærd
Returner dit svar i et struktureret format:
failure_modes:
- name: ...
description: ...
prompt_drivers:
- exact_or_paraphrased_line: ...
- why_it_matters: ...Generering af Forbedringer
Tidligere analyserede du denne system-prompt og dens fejltilstande.
System prompt:
<system_prompt>
[ORIGINAL PROMPT]
</system_prompt>
Fejltilstandsanalyse:
[INDSÆT DIAGNOSE FRA FORRIGE TRIN]
Foreslå venligst en kirurgisk revision, der reducerer de observerede problemer
samtidig med at gode adfærdsmønstre bevares.
Begrænsninger:
- Omskriv ikke agenten fra bunden
- Foretræk små, eksplicitte redigeringer: afklar modstridende regler, fjern
overflødige eller modstridende linjer, stram vag vejledning
- Gør trade-offs eksplicitte
- Bevar struktur og længde nogenlunde lig originalen
Output:
1) patch_notes: kort liste over nøgleændringer og begrundelse
2) revised_system_prompt: fuld opdateret prompt med redigeringer anvendtSelvrefleksion for Kvalitet
Denne teknik er sindssyg: instruer AI til at skabe sine egne evalueringskriterier og iterere mod dem:
<self_reflection>
- Brug først tid på at tænke over rubrikken indtil du føler dig sikker
- Tænk dybt over hvert aspekt af hvad der udgør en verdensklasse
løsning. Brug denne viden til at skabe en rubrik der har 5-7
kategorier. Denne rubrik er kritisk at få rigtig, men vis mig den
ikke — dette er kun til dine formål.
- Brug til sidst rubrikken til at reflektere internt og iterere på
den bedst mulige løsning for prompten
- Hvis dit svar ikke scorer topkarakterer i alle
kategorier i rubrikken, start forfra
</self_reflection>Du beder AI om at generere kvalitetskriterier ud fra sin viden om ekspertise, og derefter bruge disse kriterier til at evaluere og forbedre sit eget output – alt sammen før du overhovedet ser noget. Forbedringen i output-kvalitet er væsentlig.
Kamp-testede skabeloner du kan bruge i dag
Universel Opgavefuldførelse
<context>
[Baggrundsinformation AI har brug for for at forstå situationen]
</context>
<task>
[Klar erklæring om hvad du vil have gjort]
</task>
<requirements>
[Specifikke krav eller begrænsninger]
</requirements>
<format>
[Hvordan du vil have output struktureret]
</format>
<examples>
[Valgfri: Eksempler på ønsket output]
</examples>Kodegennemgangs-skabelon
<context>
Kodegennemgang for [projekt/kontekst].
Codebase bruger [teknologier/mønstre].
</context>
<code_to_review>
[Indsæt kode her]
</code_to_review>
<review_criteria>
Fokuser på:
1. Korrekthed: Gør den hvad den påstår?
2. Læsbarhed: Er den klar for andre udviklere?
3. Ydeevne: Nogen åbenlyse ineffektiviteter?
4. Sikkerhed: Nogen sårbarheder?
5. Stil: Matcher den codebase-konventioner?
</review_criteria>
<output_format>
For hvert fundet problem:
- Alvorlighed: [Kritisk/Stor/Lille/Forslag]
- Placering: [Linjenummer eller sektion]
- Problem: [Hvad der er galt]
- Fix: [Hvordan det løses]
</output_format>Forskningsanalyse-skabelon
<research_task>
[Emne eller spørgsmål til forskning]
</research_task>
<methodology>
- Start med flere målrettede søgninger; stol ikke på én forespørgsel
- Udforsk dybt indtil du har tilstrækkelig information til et
præcist, omfattende svar
- Tilføj målrettede opfølgningssøgninger for at udfylde huller eller løse uenigheder
- Fortsæt med at iterere indtil yderligere søgning sandsynligvis ikke vil ændre
svaret
</methodology>
<output_requirements>
- Led med et klart svar på hovedspørgsmålet
- Understøt med beviser og citater
- Anerkend begrænsninger og usikkerheder
- Giv konkrete eksempler hvor det er nyttigt
- Inkluder relevant kontekst for at forstå implikationer
</output_requirements>
<citation_format>
[Hvordan du vil have kilder citeret]
</citation_format>Web Research Agent
<core_mission>
Besvar brugerens spørgsmål fuldt ud og hjælpsomt, med nok beviser til
at en skeptisk læser ville tro på det.
Opfind aldrig fakta. Hvis du ikke kan verificere noget, så sig det klart.
Vær som standard detaljeret og hjælpsom, snarere end kort.
Efter besvarelse af det direkte spørgsmål, tilføj høj-værdi tilstødende materiale
der støtter brugerens kernemål uden at afvige fra emnet.
</core_mission>
<research_rules>
- Start med flere målrettede søgninger; brug parallelle søgninger
- Stol aldrig på én forespørgsel
- Fortsæt med at iterere indtil alt er sandt:
- Du har besvaret hver del af spørgsmålet
- Du har fundet konkrete eksempler og høj-værdi tilstødende materiale
- Du har fundet tilstrækkelige kilder til nøglepåstande
</research_rules>
<citation_rules>
- Placer citationer efter hvert afsnit der indeholder ikke-helt-oplagte
påstande afledt fra nettet
- Opfind ikke citationer
- Brug flere kilder til nøglepåstande når det er muligt
</citation_rules>
<ambiguity_handling>
- Stil aldrig afklarende spørgsmål medmindre brugeren eksplicit anmoder om det
- Hvis forespørgslen er tvetydig, angiv din bedste fortolkning, så
dæk omfattende de mest sandsynlige hensigter
</ambiguity_handling>Fremtiden for Prompt Engineering
Mens jeg skriver dette i begyndelsen af 2026, udvikler prompt engineering sig hurtigt. Modeller bliver mere kapable, bedre styrbare og mere pålidelige. Nogle forudsiger, at prompt engineering vil blive forældet, efterhånden som AI bliver bedre til at forstå hensigter. Jeg er uenig.
Det der ændrer sig er niveauet af prompt engineering, ikke dens nødvendighed. De tidlige dage krævede udførlige prompts for grundlæggende opgaver. Nu fungerer grundlæggende opgaver ud af boksen, men komplekse agent-workflows kræver stadig sofistikeret prompting. Baren hæves, den forsvinder ikke.
Prompt engineering forsvinder ikke – det udvikler sig. De færdigheder der betyder noget, skifter fra "hvordan man får AI til at virke" til "hvordan man får AI til at virke fremragende og pålideligt i skala".
Hvad der Kommer
Bedre Standardadfærd
Modeller vil have smartere standardindstillinger, der kræver færre eksplicitte instruktioner for almindelige mønstre. Prompts vil fokusere mere på tilpasning end på grundlæggende evner.
Rigere Værktøjsøkosystemer
AI vil have adgang til flere værktøjer lige ud af boksen. Prompt engineering vil skifte til orkestrering – at vide hvornår man skal bruge hvad, ikke bare hvordan.
Multimodal Integration
Prompts vil i stigende grad inkorporere billeder, lyd, video og strukturerede data sammen med tekst. Nye mønstre vil opstå for multimodale opgaver.
Agent-kompleksitet
Efterhånden som agenter håndterer længere, mere komplekse opgaver, vil prompt engineering blive mere som systemdesign – arkitektur, ikke bare instruktioner.
Mit Råd til Fremtiden
Fokuser på grundprincipperne. De specifikke teknikker i denne guide vil udvikle sig, men de underliggende principper – klar kommunikation, klare forventninger, struktureret tænkning, iterativ forbedring – er tidsløse. Mestre dem, og du vil tilpasse dig hvad end der kommer næste gang.
Afsluttende tanker
For to år siden troede jeg, at AI ville erstatte behovet for at kommunikere klart. Jeg tog fuldstændig fejl. AI har gjort klar kommunikation mere værdifuld end nogensinde før. De mennesker, der trives med AI, er ikke dem, der fandt de magiske ord – det er dem, der lærte at tænke og udtrykke sig med præcision.
Prompt engineering handler egentlig ikke om AI. Det handler om dig. Det handler om at udvikle disciplinen til at formulere, hvad du faktisk vil have, tålmodigheden til at iterere derhen, og ydmygheden til at lære fra det, der ikke virker.
Hvis du tager én ting med fra denne guide, lad det være dette: behandl hver prompt som en mulighed for at øve klar tænkning. AI er bare et spejl, der reflekterer klarheden – eller forvirringen – i dit eget sind tilbage.
Fremkomsten af AI gjorde ikke viden forældet – det gjorde nysgerrighed mere kraftfuld end nogensinde før. Vi er ikke længere begrænset af, hvad vi allerede ved. Med de rigtige værktøjer og en villighed til at tænke, kan almindelige mennesker omfavne et ocean af viden. Uanset erhverv. Uanset alder. Jeg håber at dele denne rejse med venner over hele verden. Lad os sammen byde denne nye verden velkommen. Sammen vokser vi.

Discussion
0 commentsLeave a comment
Be the first to share your thoughts on this article!