Der Unterschied zwischen frustrierenden KI-Bildern und atemberaubenden ist nicht Talent oder Glück — es ist zu lernen, die visuelle Sprache zu sprechen, die die Maschine versteht.
Ich erinnere mich noch genau an den Moment, als sich alles änderte. Es war 2 Uhr morgens an einem Dienstag. Ich hatte stundenlang auf meinen Bildschirm gestarrt, Prompt für Prompt durchgegangen und zugesehen, wie ChatGPT Bilder ausspuckte, die nichts mit dem zu tun hatten, was ich mir vorgestellt hatte. Finger mit unmöglicher Anatomie. Text, der zu Kauderwelsch verschmolz. Charaktere, die sich aktiv meinen Absichten zu widersetzen schienen. Ich war bereit, die KI-Bildgenerierung ganz aufzugeben — sie als überbewertete Technologie abzutun, die nur für andere Leute funktionierte.
Dann versuchte ich etwas anderes. Anstatt zu beschreiben, was ich sehen wollte, beschrieb ich, was eine Kamera einfangen würde. Anstatt nach "einem schönen Sonnenuntergang" zu fragen, schrieb ich "Licht der goldenen Stunde, das durch Berggipfel strömt, aufgenommen mit Canon 5D Mark IV, 24-70mm Objektiv bei f/2.8, natürliche Farbkorrektur". Das Bild, das erschien, war nicht nur akzeptabel — es war atemberaubend. Fotorealistisch. Genau das, was Momente zuvor nur in meiner Vorstellung existiert hatte.
Dieser einzige Perspektivwechsel hat alles freigeschaltet. In den folgenden Monaten ging ich in die Tiefe. Ich generierte Tausende von Bildern. Ich testete jede Technik, die ich finden konnte. Ich las die Dokumentation von OpenAI von vorne bis hinten. Ich experimentierte mit GPT Image 1.5 an dem Tag, als es startete. Und jetzt werde ich alles teilen, was ich gelernt habe — nicht die oberflächlichen Tipps, die Sie überall sonst finden, sondern das tiefgehende Wissen, das Profis von Hobbyisten trennt. Dies ist der Leitfaden, den ich mir gewünscht hätte, als ich anfing. So werden Sie vom frustrierten Anfänger zum selbstbewussten Schöpfer.
Meine Reise in die KI-Bildgenerierung
Lassen Sie mich Sie dorthin zurückbringen, wo alles begann. Wie viele von Ihnen, die dies lesen, war ich anfangs skeptisch gegenüber der KI-Bildgenerierung. "Das ist nur ein Spielzeug für Technikbegeisterte", dachte ich. "Echte kreative Arbeit erfordert immer noch echte Fähigkeiten." Ich hätte nicht falscher liegen können.
Mein erster wirklicher Bedarf an KI-Bildern entstand aus einem praktischen Problem. Ich erstellte Inhalte für ein Projekt und brauchte Titelbilder — viele davon. Ich hatte für Stockfotos bezahlt und Geld für generische Aufnahmen ausgegeben, die jeder andere Schöpfer auch benutzte. Die Bilder waren in Ordnung, aber ihnen fehlte die Seele. Sie fühlten sich geliehen an, nicht eigen.
Eine Freundin erwähnte, dass ChatGPT jetzt Bilder generieren könne. "Beschreibe einfach, was du willst", sagte sie. "Es ist wie Magie." Also probierte ich es aus. Mein erster Prompt war peinlich naiv: "Ein schöner Sonnenuntergang über Bergen." Das Ergebnis? Ein verschmiertes Chaos, das wie ein Aquarellgemälde aussah, das im Regen liegen gelassen wurde. Ich war gelinde gesagt unbeeindruckt.
Aber etwas zog mich immer wieder zurück. Ich versuchte es erneut. Und wieder. Jeder Misserfolg lehrte mich etwas Neues darüber, wie die KI Sprache interpretierte. Ich begann Muster zu bemerken — bestimmte Phrasen, die konsistent bessere Ergebnisse lieferten, strukturelle Ansätze, die das Modell in Richtung meiner Vision führten, anstatt davon weg.
Der Durchbruch kam, als mir klar wurde: Bei der KI-Bildgenerierung geht es nicht darum zu beschreiben, was man in seinem Kopf sieht — es geht darum zu beschreiben, was eine Kamera in der Realität einfangen würde. Dieser einzige Perspektivwechsel hat alles verändert.
Ich hörte auf, wie ein Träumer zu denken, und fing an, wie ein Fotograf zu denken. Anstatt "schöner Sonnenuntergang" schrieb ich über das Licht der goldenen Stunde, spezifische Kameramodelle, Objektivbrennweiten, Blendeneinstellungen, Filmmaterial. Die KI verstand diese Sprache, weil sie auf Millionen von Bildern trainiert wurde, die genau mit dieser Art von technischen Metadaten versehen waren.
In den folgenden Monaten wurde ich besessen. Ich generierte Tausende von Bildern in jedem Stil und Anwendungsfall, den ich mir vorstellen konnte. Ich las jedes Stück Dokumentation, das OpenAI veröffentlichte. Ich trat Communities von Schöpfern bei, die die Grenzen des Möglichen verschoben. Und als GPT Image 1.5 im Januar 2026 startete, war ich bereit. Ich verstand nicht nur, wie man es benutzt, sondern warum es so funktionierte, wie es funktionierte.
Jetzt werde ich alles teilen, was ich gelernt habe. Nicht die oberflächlichen Tipps, die Sie in hundert anderen Leitfäden finden. Das tiefgehende Wissen, das aus umfangreichen Experimenten, systematischen Tests und unzähligen Gesprächen mit anderen Schöpfern stammt, die diese Tools an ihre Grenzen bringen. Dies ist der komplette Leitfaden — derjenige, der Sie vom verwirrten Anfänger zum selbstbewussten Schöpfer bringt.
Was ist der ChatGPT Bildgenerator
Bevor wir in die Techniken eintauchen, lassen Sie mich klären, womit wir es genau zu tun haben. Der ChatGPT Bildgenerator ist OpenAIs integriertes Bilderstellungs- und Bearbeitungssystem, das derzeit von ihrem GPT Image 1.5 Modell angetrieben wird. Im Gegensatz zu eigenständigen Tools wie Midjourney oder Stable Diffusion ist es tief in die Konversationsschnittstelle von ChatGPT integriert.
Diese Integration ist wichtiger, als Sie vielleicht denken. Da ChatGPT den Kontext versteht, kann es die Konsistenz über mehrere Generationen hinweg aufrechterhalten, sich Ihre Vorlieben innerhalb einer Sitzung merken und sogar darüber nachdenken, was Sie zu erstellen versuchen. Sagen Sie ihm, dass Sie an einem Kinderbuch arbeiten, und es passt seinen Stil entsprechend an. Erwähnen Sie, dass Sie Bilder für eine Unternehmenspräsentation benötigen, und es verschiebt sich hin zu einer sauberen, professionellen Ästhetik. Dieses kontextbezogene Bewusstsein ist etwas, das eigenständige Bildgeneratoren einfach nicht erreichen können.
🎨 Text-zu-Bild-Generierung
Beschreiben Sie alles in natürlicher Sprache und sehen Sie zu, wie es sich materialisiert. Von fotorealistischen Porträts bis hin zu abstrakter Kunst, von Produkt-Mockups bis hin zu Fantasielandschaften — wenn Sie es beschreiben können, kann die KI es erschaffen.
✏️ Präzise Bildbearbeitung
Laden Sie bestehende Bilder hoch und modifizieren Sie sie mit Textbefehlen. Ändern Sie Farben, tauschen Sie Objekte aus, passen Sie die Beleuchtung an, transformieren Sie Jahreszeiten oder erfinden Sie die Szene komplett neu, während Sie Elemente bewahren, die Sie behalten möchten.
🔄 Stilübertragung
Nehmen Sie die visuelle Sprache eines Bildes — seine Palette, Textur, Pinselstriche oder Ästhetik — und wenden Sie sie auf völlig neue Inhalte an. Perfekt für die Aufrechterhaltung der Markenidentität oder das Erstellen kohärenter Serien.
📝 Zuverlässiges Text-Rendering
Endlich eine KI, die tatsächlich buchstabieren kann. GPT Image 1.5 verarbeitet Text in Bildern mit beispielloser Genauigkeit — perfekt für Logos, Poster, Infografiken und Marketingmaterialien, bei denen Worte zählen.
Wie es tatsächlich funktioniert
Wenn Sie einen Prompt an den ChatGPT Bildgenerator senden, geschehen hinter den Kulissen mehrere Dinge. Zuerst verarbeitet ChatGPT selbst Ihre Anfrage und erweitert oder klärt Ihren Prompt möglicherweise basierend auf dem Kontext. Es könnte Details hinzufügen, die Sie impliziert, aber nicht ausgesprochen haben, oder Ihre Anfrage so strukturieren, wie es das Bildmodell besser versteht.
Dann geht die Anfrage an das Bildgenerierungsmodell — derzeit GPT Image 1.5 — das Ihre Textbeschreibung in visuelle Ausgabe umwandelt. Dieses Modell wurde an einem riesigen Datensatz von Bildern trainiert, die mit detaillierten Beschreibungen gepaart waren, und lernte die komplizierten Beziehungen zwischen Sprache und visuellen Elementen.
Das Ergebnis ist ein System, das wirklich versteht, was Sie verlangen, und nicht nur Schlüsselwörter abgleicht. Bitten Sie um "einen fotorealistischen offenen Moment" und Sie erhalten etwas, das sich wirklich ungezwungen anfühlt. Fordern Sie "Morgenlicht durch Jalousien" an und Sie erhalten das spezifische Streifenmuster, das dadurch entsteht.
GPT Image 1.5 erreichte den ersten Platz in der Artificial Analysis Image Arena sowohl für Text-zu-Bild-Generierung als auch für Bildbearbeitung, mit einer Instruktionsbefolgungsrate von 90% — 13 Prozentpunkte höher als sein engster Konkurrent. Das ist kein Marketing-Sprech; es spiegelt einen echten Leistungssprung wider.
Die GPT Image 1.5 Revolution
Als OpenAI im Januar 2026 GPT Image 1.5 veröffentlichte, haben sie nicht nur ihr vorheriges Modell überarbeitet — sie haben das Fundament neu gebaut. Ich hatte frühere Versionen intensiv genutzt, also bemerkte ich sofort den Unterschied. Das war keine inkrementelle Verbesserung; es war ein Paradigmenwechsel.
Lassen Sie mich spezifisch darüber sein, was sich geändert hat, denn das Verständnis dieser Verbesserungen wird Ihnen helfen, sie effektiv zu nutzen.
Die drei Durchbrüche, die zählen
Frühere Modelle neigten frustrierenderweise dazu, abzudriften. Man bat darum, eine Sache zu ändern, und drei andere Dinge verschoben sich unerwartet. Korrigierte man die Beleuchtung, sah das Gesicht des Charakters plötzlich anders aus. GPT Image 1.5 versteht wirklich "ändere nur dieses Element" — es kann spezifische Teile modifizieren, während Beleuchtung, Komposition, Gesichtszüge und sogar subtile Texturen erhalten bleiben. Dies macht iterative Verfeinerung tatsächlich praktisch.
Die Generierungsgeschwindigkeit stieg um bis zu 400% im Vergleich zu früheren Versionen. Was früher 30 Sekunden dauerte, dauert jetzt 7-8. Aber noch wichtiger ist, dass Sie neue Generationen in die Warteschlange stellen können, während die aktuellen noch verarbeitet werden. Dies verwandelt den kreativen Prozess von "abschicken und warten" zu "erkunden und iterieren". Der psychologische Unterschied ist signifikant — schnellere Feedbackschleifen bedeuten mehr Experimentieren.
Text-Rendering in KI-Bildern war historisch gesehen eine Katastrophe — Rechtschreibfehler, Duplikationen, Buchstaben, die zu abstrakten Formen verschmelzen. GPT Image 1.5 handhabt dichten, kleinen Text unter Beibehaltung korrekter Typografie, Layout und Lesbarkeit. Dies eröffnet Infografiken, Marketingmaterialien, UI-Mockups und jeden Anwendungsfall, bei dem Wörter in Bildern erscheinen. Zum ersten Mal kann ich Präsentationsfolien, Social-Media-Grafiken mit Bildunterschriften und Produktetiketten generieren, die ich tatsächlich verwenden würde.
Verständnis der Qualitätseinstellungen
GPT Image 1.5 bietet verschiedene Qualitätsstufen, und zu verstehen, wann welche zu verwenden ist, spart Ihnen Zeit und verbessert Ihre Ergebnisse. Es geht nicht nur um die Ausgabequalität — es geht darum, das richtige Werkzeug für die richtige Aufgabe zu wählen.
⚡ Modus niedrige Qualität
Lassen Sie sich vom Namen nicht täuschen — "niedrige Qualität" bedeutet hier "schnell und effizient". Die Ergebnisse sind für die meisten Anwendungsfälle immer noch bemerkenswert gut. Verwenden Sie dies für:
- Initiale Konzerpterkundung und Brainstorming
- Schnelle Iterationen beim Verfeinern von Ideen
- Einfache Kompositionen ohne feine Details
- Generierung großer Mengen, wo Geschwindigkeit zählt
- Entwürfe vor der Festlegung auf endgültige Versionen
✨ Modus hohe Qualität
Wenn jedes Pixel zählt und Sie publikationsreife Ergebnisse benötigen. Reservieren Sie dies für:
- Endgültige Produktionsbilder zur Lieferung
- Dichte Text- und Typografiearbeit
- Komplexe Infografiken mit kleinen Details
- Fotorealistische Porträts, wo Textur zählt
- Jedes Bild, bei dem Sie maximale Wiedergabetreue benötigen
Die versteckte Eingabetreue-Einstellung
Hier ist etwas, das Ihnen die meisten Leitfäden nicht sagen werden: Beim Bearbeiten von Bildern gibt es einen Parameter namens input_fidelity, der die Ergebnisse dramatisch beeinflusst. Setzen Sie ihn auf "high" (hoch), wenn Sie Gesichtszüge bewahren, die Identität über Bearbeitungen hinweg beibehalten oder signifikante Szenenänderungen vornehmen müssen. Das Modell arbeitet härter daran, die Schlüsselmerkmale des Originalbildes beizubehalten.
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # Die Geheimzutat für Identitätsbewahrung
quality="high",
image=[open("portrait.png", "rb")],
prompt="Change the background to a sunset beach while preserving the person's exact appearance"
)Diese Kombination gewährleistet maximale Bewahrung des Originalsubjekts bei gleichzeitiger Anwendung Ihrer angeforderten Änderungen.
Die größte Verschiebung mit GPT Image 1.5 ist nicht technisch — sie ist philosophisch. Die Bildgenerierung bewegt sich von "prompten und beten" zu "instruieren und iterieren". Dies erfordert ein völlig anderes mentales Modell dafür, wie Sie visuelle Kreation angehen.
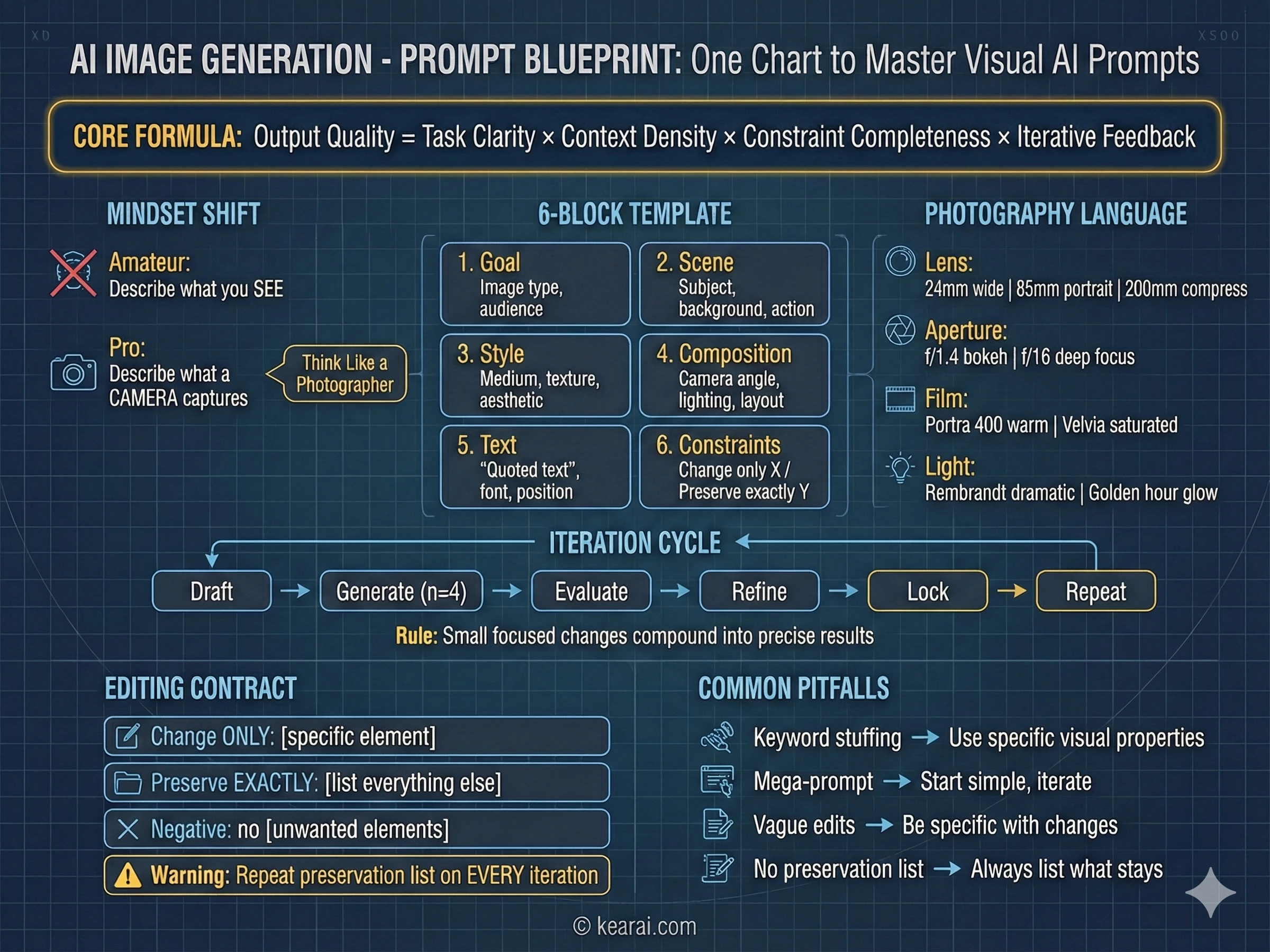
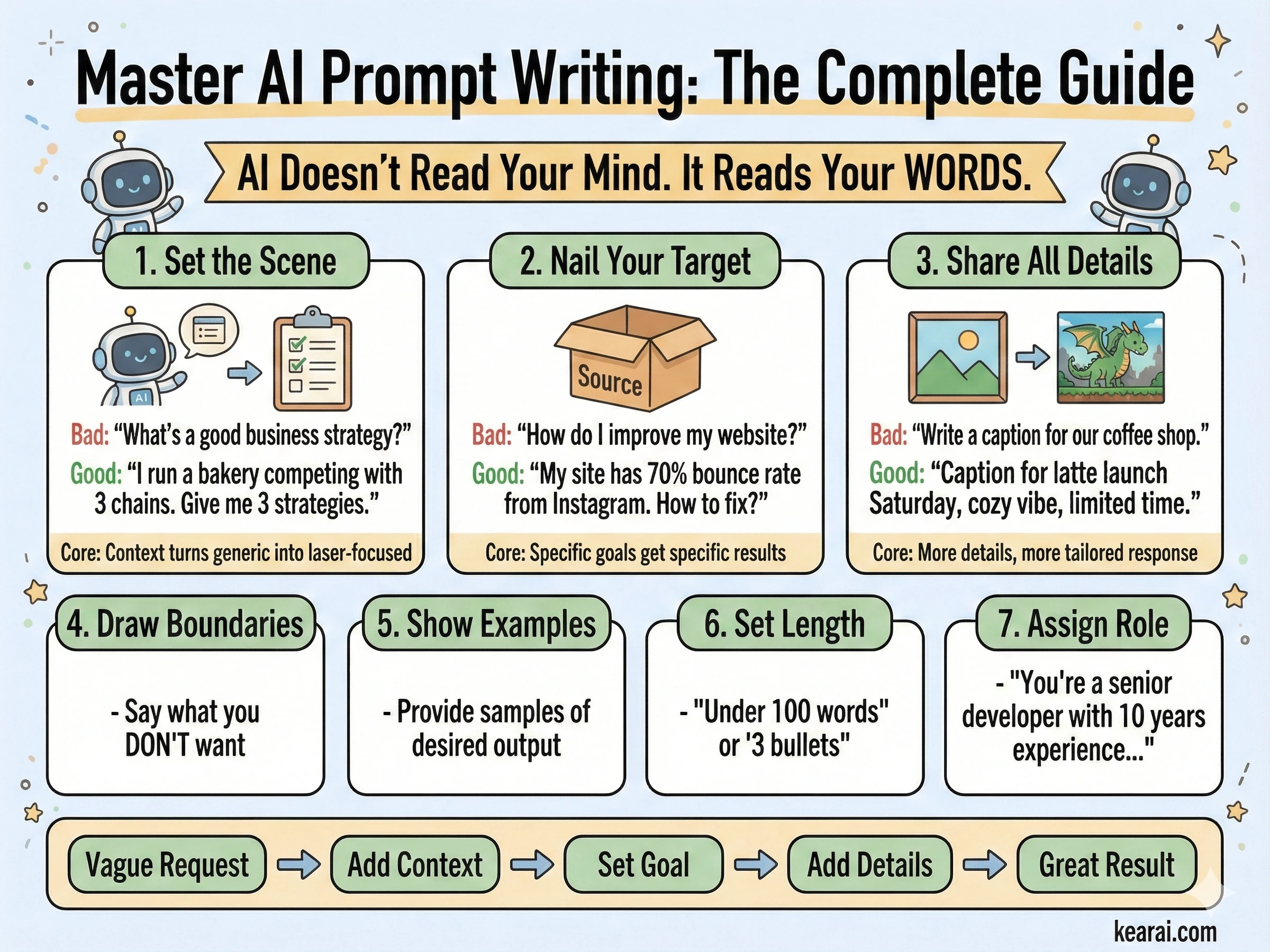
Das Prompt-Framework, das alles veränderte
Nachdem ich Tausende von Bildern generiert hatte, entwickelte ich ein Framework, das konsistent außergewöhnliche Ergebnisse liefert. Vergessen Sie alles, was Sie über das Hinzufügen von "masterpiece, trending on ArtStation, ultra-detailed, 8K resolution" zu Ihren Prompts gelesen haben. Diese Schlüsselwörter funktionierten für ältere Modelle, die Qualitätshinweise benötigten, aber GPT Image 1.5 reagiert auf Struktur und Spezifität, nicht auf Keyword-Stuffing.
Ich nenne es die strukturierte Prompt-Architektur, und jeder effektive Prompt, den ich jetzt schreibe, folgt diesem Muster.
Goal/Output (Ziel/Ausgabe):
- [Type of image: ad, UI mockup, infographic, photo, illustration] (Bildtyp)
- [Intended use and audience] (Verwendungszweck und Zielgruppe)
Scene (Szene):
- [Background/environment description] (Hintergrund-/Umgebungsbeschreibung)
- [Main subject with specific details] (Hauptsubjekt mit spezifischen Details)
- [Action or relationship between elements] (Handlung oder Beziehung zwischen Elementen)
Style (Stil):
- [Medium: photograph, watercolor, 3D render, vector illustration] (Medium)
- [Key textures: matte, glossy, grainy, smooth, organic] (Schlüsseltexturen)
- [Quality descriptors: realistic imperfections, stylized, minimalist] (Qualitätsdeskriptoren)
Composition/Layout (Komposition/Layout):
- [Camera position: close-up, wide shot, aerial view, eye-level] (Kameraposition)
- [Lighting: golden hour, studio strobes, overcast, dramatic shadows] (Beleuchtung)
- [Element placement: centered, rule of thirds, negative space, margins] (Platzierung der Elemente)
Text (if any) (Text falls vorhanden):
- "Exact text in quotes" ("Exakter Text in Anführungszeichen")
- [Font style, size, color, position] (Schriftstil, Größe, Farbe, Position)
- [Specify: render only once, no duplicates] (Angeben: nur einmal rendern)
Constraints (Einschränkungen):
- Change ONLY: [specific element if editing] (Ändere NUR)
- Preserve exactly: [elements that must stay unchanged] (Bewahre exakt)
- Negative: no watermark, no extra text, no logos, no [unwanted elements] (Negativ)Dieses Framework gibt dem Modell klaren Kontext für jede visuelle Entscheidung, die es treffen muss.
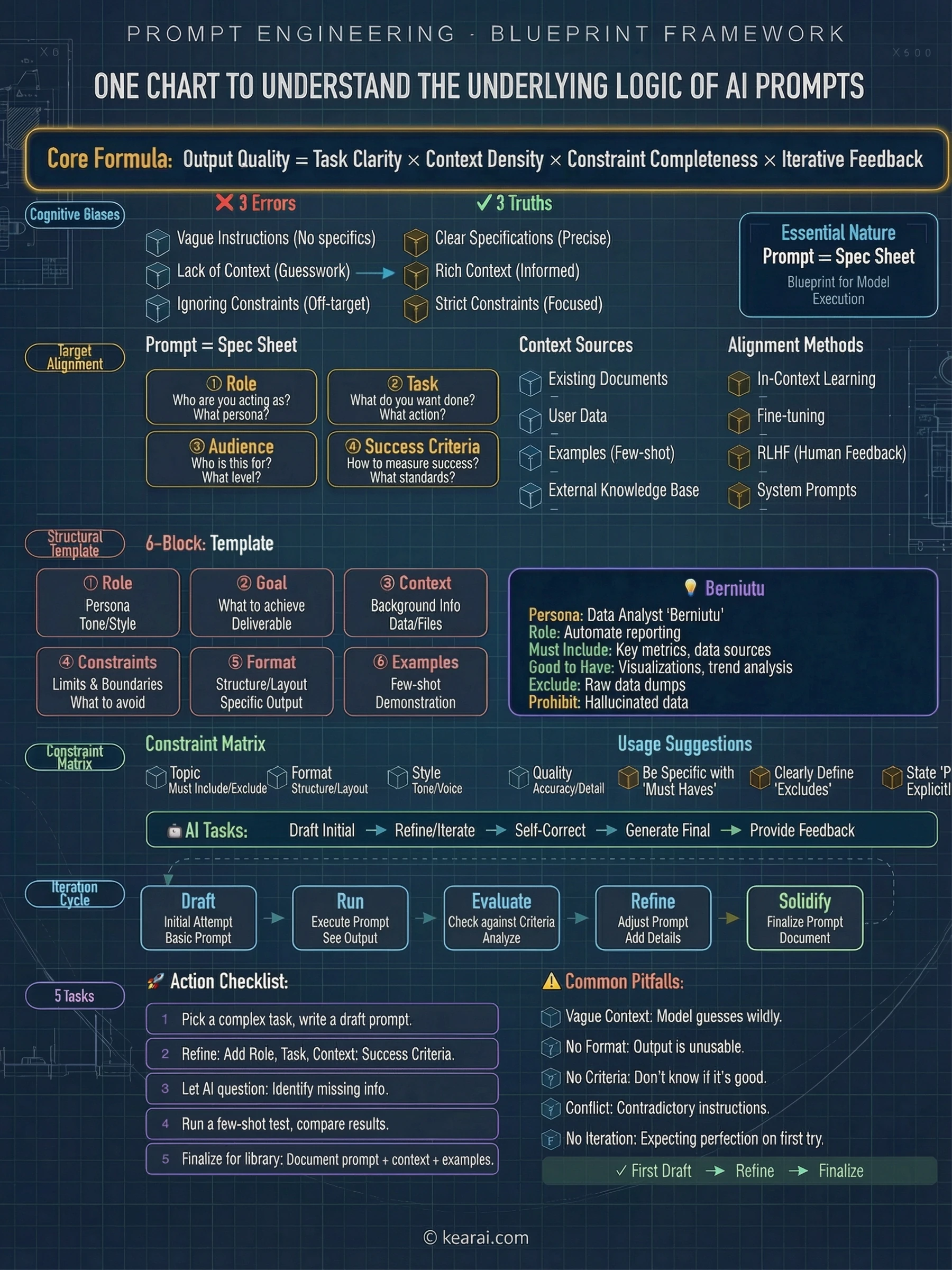
Die sieben Prinzipien des effektiven Promptings
Jenseits der Struktur regeln diese Prinzipien, wie ich jeden Prompt schreibe. Sie sind der Unterschied zwischen Bildern, die fast funktionieren, und Bildern, die Ihre Vision treffen.
Struktur über Schlüsselwörter
Verwenden Sie eine konsistente Reihenfolge: Hintergrund → Subjekt → Details → Einschränkungen. Für komplexe Anfragen verwenden Sie beschriftete Abschnitte oder Zeilenumbrüche. Lange Absätze verwirren das Modell; organisierte Struktur führt es zu Ihrer Absicht.
Spezifität über Superlative
Anstatt "hohe Qualität" oder "ultra-detailliert", beschreiben Sie tatsächliche visuelle Eigenschaften. Materialien, Texturen, Formen, Medien. "Sichtbare Hautporen und subtile Sommersprossen" schlägt "hochdetailliertes Gesicht" jedes Mal.
Explizite Kompositionskontrolle
Benennen Sie Ihren Bildausschnitt (Nahaufnahme, Weitwinkel, Vogelperspektive), Perspektive (Augenhöhe, Froschperspektive, Dutch Angle) und Lichtstimmung (weich diffus, goldene Stunde, kontrastreiches Randlicht). Überlassen Sie dies nicht dem Zufall.
Der Vertrag zwischen Ändern und Bewahren
Für die Bearbeitung geben Sie explizit an, was sich ändern soll UND was unberührt bleiben soll. Verwenden Sie "change only X" und "preserve exactly Y". Wiederholen Sie diese Bewahrungsliste bei jeder Iteration, um Abdrift zu verhindern.
Text verlangt Präzision
Setzen Sie erforderlichen Text in "Anführungszeichen" oder GROSSBUCHSTABEN. Geben Sie Schriftstil, Größe, Farbe und Position an. Für schwierige Wörter oder Markennamen buchstabieren Sie sie Buchstabe für Buchstabe. Fügen Sie immer "render exactly once, no duplicates" hinzu.
Klarheit bei Mehrbildreferenzen
Wenn Sie mit mehreren Eingabebildern arbeiten, verweisen Sie auf jedes durch Index und Beschreibung: "Bild 1: die Produktaufnahme, Bild 2: die Stilreferenz". Geben Sie explizit an, wie sie interagieren sollen.
Iterieren statt Überladen
Beginnen Sie mit einem sauberen Basis-Prompt, dann verfeinern Sie mit kleinen Follow-ups, die nur eine Änderung beinhalten. "Make the lighting warmer." "Remove the background tree." Kleine Schritte summieren sich zu präzisen Ergebnissen.
Der häufigste Fehler
Der größte Fehler, den ich Leute machen sehe: der Versuch, alles in einem massiven Prompt zu spezifizieren, in der Hoffnung, dass das Modell es irgendwie herausfindet. Das funktioniert fast nie gut. Beginnen Sie mit einem einfacheren Prompt, um die Basis zu etablieren, dann iterieren Sie mit gezielten Verfeinerungen. Sie erhalten bessere Ergebnisse in weniger Zeit mit weit weniger frustrierenden Misserfolgen.
Das Fotografie-Mindset
Die größte einzelne Verbesserung meiner Ergebnisse kam durch einen mentalen Wechsel: Ich hörte auf, wie ein Künstler zu denken, der eine Vision beschreibt, und begann, wie ein Fotograf zu denken, der eine Aufnahme beschreibt. Das ist nicht nur eine Metapher — es ist eine praktische Technik, die nutzt, wie das Modell trainiert wurde.
KI-Bildmodelle haben von Millionen von Fotografien gelernt, die mit Metadaten versehen waren: Kameramodelle, Objektivspezifikationen, Blendeneinstellungen, Lichtverhältnisse. Wenn Sie diese Sprache verwenden, aktivieren Sie das tiefe Verständnis des Modells dafür, wie echte Kameras echte Szenen einfangen.
Fotografiesprache, die funktioniert
- Objektivwahl: "24mm wide angle" (Weitwinkel) erzeugt weite Szenen mit Verzerrung an den Rändern; "200mm telephoto" (Teleobjektiv) komprimiert die Tiefe und isoliert Subjekte
- Blendengefühl: "f/1.4 bokeh" ergibt cremige Hintergrundunschärfe für Porträts; "f/16 deep focus" (Tiefenschärfe) hält alles scharf für Landschaften
- Filmmaterial: "Kodak Portra 400" für warme, schmeichelhafte Hauttöne; "Fuji Velvia" für kräftige, gesättigte Landschaften; "Ilford HP5" für kontrastreiches Schwarzweiß
- Beleuchtungs-Setups: "Rembrandt lighting" für dramatische Porträts; "butterfly lighting" für Beauty-Aufnahmen; "golden hour backlight" für ätherische leuchtende Kanten
- Kamerabewegung: "long exposure motion blur" für dynamische Energie; "high-speed freeze frame" zum Einfangen von Action
Anstatt zu sagen "make it look professional" (lass es professionell aussehen), versuchen Sie "shot on Hasselblad medium format, studio strobe lighting, seamless gray backdrop, color-calibrated for print reproduction". Anstatt "realistic portrait" (realistisches Porträt), versuchen Sie "candid photograph, 85mm f/1.4 lens, window light from camera left, subtle fill from reflector, visible skin texture with pores, shot on Sony A7R IV".
❌ VORHER (Vage):
"A beautiful portrait of an old fisherman, very detailed, high quality, realistic"
✅ NACHHER (Fotografie-Mindset):
"Candid documentary photograph of an elderly fisherman on a weathered wooden boat.
Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind eyes.
Gray stubble. Faded traditional anchor tattoo on forearm. Salt-stained navy wool
sweater, worn cap.
Early morning coastal light, soft fog diffusing the sun. Medium close-up at eye
level, 50mm lens, f/2.8, shallow depth of field. Shot like 35mm film with subtle
grain, natural color balance.
Documentary style — honest, unretouched, capturing a real moment. No glamorization."Das Fotografie-Mindset verwandelt vage Wünsche in präzise visuelle Spezifikationen, die das Modell tiefgehend versteht.
Wenn Sie Bilder mit Fotografiesprache beschreiben, sind Sie nicht nur spezifischer — Sie sprechen eine Sprache, die das Modell zu verstehen gelernt hat. Kameraspezifikationen, Beleuchtungs-Setups und Filmmaterialien sind keine willkürlichen Schlüsselwörter; sie kodieren präzise visuelle Informationen, die das Modell genau dekodieren kann.
Text-zu-Bild-Meisterschaft
Bilder aus reinem Text zu erstellen, ist der Punkt, an dem die meisten Menschen ihre KI-Bildreise beginnen. Es ist auch der Punkt, an dem die Kluft zwischen Amateur- und Profiergebnissen am sichtbarsten ist. Lassen Sie mich Sie durch die Techniken führen, die konsistent herausragende Ergebnisse in verschiedenen Anwendungsfällen produzieren.
Fotorealistische Bilder, die sich natürlich anfühlen
Der Schlüssel zum Fotorealismus ist kontraintuitiv: Sie müssen nach Unvollkommenheit fragen. Perfekte Haut, perfekte Beleuchtung, perfekte Komposition — das schreit "KI-generiert". Die Realität ist chaotischer, und dieses Chaos macht Bilder authentisch.
Create a photorealistic candid photograph of an elderly sailor standing on a small fishing boat.
Subject: Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind
eyes with crow's feet. Gray stubble, a few days unshaven. Faded traditional anchor
tattoo on forearm. Salt-stained navy wool sweater, worn and pilled. Creased cap
with faded insignia.
Setting: Early morning on the water, soft coastal fog diffusing the light. Aged
wooden boat deck with peeling paint, fishing nets in background, coiled rope.
Technical: Shot like 35mm film photography, medium close-up at eye level, 50mm
lens, shallow depth of field with boat blurred behind him. Subtle film grain,
natural color balance without heavy grading.
The image should feel like a real moment captured by a photojournalist — honest,
unposed, with real skin texture, worn materials, and everyday imperfection. No
glamorization, no heavy retouching, no artificial perfection.Beachten Sie, wie wir explizit Unvollkommenheiten anfordern — verwitterte Haut, abgenutzte Materialien, abblätternde Farbe. Realität hat Textur.
Infografiken und Datenvisualisierung
Das verbesserte Text-Rendering in GPT Image 1.5 macht Infografiken zu einem wirklich praktischen Anwendungsfall. Ich erstelle jetzt Informationsgrafiken in professioneller Qualität, die ich tatsächlich in meiner Arbeit verwende.
Create a detailed infographic explaining how a coffee machine works.
Structure:
- Title at top: "The Journey of Your Morning Coffee"
- Vertical flow diagram showing: bean hopper → grinder → portafilter →
grouphead → water heating → extraction → cup
- Each step has an icon and 1-2 sentence explanation
- Warm color palette (browns, creams, copper accents)
- Clean, modern design with plenty of white space
- Subtle coffee stain texture in background corners
Style: Professional print-quality infographic, vector-style icons, clear
hierarchy, readable at A4 size.
Typography: Clean sans-serif headings, readable body text, clear visual
hierarchy between title, section headers, and explanatory text.
No watermarks. No stock photo elements. Original illustration only.Für dichten Text und komplexe Layouts verwenden Sie immer quality="high", um sicherzustellen, dass der Text scharf und lesbar bleibt.
Logo- und Markendesign
Logo-Generierung erfordert die Priorisierung von Einfachheit und Skalierbarkeit. Ein großartiges Logo funktioniert in jeder Größe, vom winzigen Favicon bis zum riesigen Billboard. Hier erfahren Sie, wie Sie Designs anfordern, die tatsächlich als Logos funktionieren.
Create an original logo for "Field & Flour" — a local artisan bakery.
Brand personality: Warm, authentic, handcrafted, timeless. Not trendy or corporate.
Design requirements:
- Clean vector-style shapes with strong silhouette
- Balanced negative space
- Must read clearly from 16px favicon to large signage
- Flat design, minimal strokes, no gradients unless essential
- Earth-tone palette: warm wheat gold, deep brown, cream
- Could incorporate subtle wheat or grain element
- Text must be perfectly legible and properly kerned
Output: Single centered logo on plain cream background. Generous padding around
the design for flexibility.
No watermarks, no mockups, no 3D effects, no complex imagery. Simple, functional,
timeless design.Verwenden Sie n=4, um mehrere Variationen zu generieren. Logo-Design ist subjektiv — geben Sie sich Optionen zur Auswahl.
UI- und App-Mockups
Für UI-Design beschreiben Sie die Oberfläche so, als ob sie bereits existiert und an echte Benutzer ausgeliefert wird. Concept-Art-Sprache produziert Concept Art. Produktsprache produziert verwendbare Mockups.
Create a realistic mobile app UI mockup for a local farmers market app.
Screen content (from top):
- Simple header with market name "Riverside Market" and search icon
- Today's featured vendor carousel with square photos
- "Fresh Today" section with produce category chips (Vegetables, Fruits, Dairy, Baked)
- Vendor list with small photos, names, specialties, and distance
- Bottom navigation: Home, Map, Favorites, Cart, Profile
Design language:
- White background, subtle natural green accents
- Clear typography hierarchy (system fonts feel)
- Generous padding and touch-friendly targets
- Looks like a real shipped product, not a concept
- Uses realistic vendor names and produce photos
Frame: Place the UI inside an iPhone 15 Pro device frame, slight perspective
tilt, subtle shadow beneath.Konzentrieren Sie sich auf Layout, Hierarchie, Abstände und realistische Oberflächenelemente. Vermeiden Sie konzeptionelle oder künstlerische Sprache.
Comicstreifen und Sequenzielle Kunst
Das Erstellen von mehrteiligen Comics erfordert die Definition der Erzählung als eine Sequenz klarer visueller Beats, einer pro Panel. Halten Sie Beschreibungen konkret und handlungsorientiert.
Create a 4-panel vertical comic strip. Equal panel sizes, clear panel borders.
Panel 1: Pet owner walks out the front door, keys in hand. Through the window
behind them, we see their cat watching — paws pressed against glass, eyes wide
with apparent sadness. The house suddenly feels empty.
Panel 2: The door clicks shut. The cat slowly turns away from the window toward
the empty house. Its posture shifts from forlorn to interested. Eyes narrow with
possibility.
Panel 3: Total chaos. Cat sprawled across the forbidden couch like royalty.
Knocked over plant on the floor. Papers scattered. Sunbeam spotlighting the
scene of domestic crime.
Panel 4: Door handle turns. Cat sits perfectly upright by the entrance,
composed and innocent, tail wrapped neatly around paws. Not a hair out of
place. As if nothing happened.
Style: Warm illustrated style with expressive characters, clear visual
storytelling that reads without text. Consistent character design across
all panels.
No speech bubbles or text. Let the visuals tell the story.Definieren Sie jedes Panel als einen eigenen visuellen Beat mit klarer Handlung. Das Modell kümmert sich um das Panel-Layout und die visuelle Kontinuität.
Kinderbuchillustrationen
Kinderbuchillustration erfordert einen spezifischen Ansatz: einprägsames Charakterdesign, warmen zugänglichen Stil und Kompositionen, die mit Textüberlagerungen funktionieren.
Create a children's book illustration introducing the main character.
Character: Young forest hero, around 8 years old.
- Green hooded tunic (think woodland adventurer, not Robin Hood)
- Soft brown boots, well-worn
- Small belt pouch for collecting treasures
- Carries a tiny wooden bow (symbolic, for helping not hurting)
- Kind expression, bright curious eyes, brave but gentle demeanor
- Slightly oversized head for picture book proportions
Theme: This character protects and rescues small forest animals in trouble.
Style: Hand-painted watercolor look with soft outlines, warm earthy palette
with forest greens and autumn oranges. Whimsical, friendly, inviting for
young readers ages 4-8.
Composition: Character standing in simple forest glade, dappled sunlight,
leaving room for title text above. Character clearly showcased.
Original character design only. No text. No watermarks. No copyrighted
character references.Speichern Sie dieses Charakter-Referenzbild — Sie werden es verwenden, um die Konsistenz über nachfolgende Illustrationen hinweg aufrechtzuerhalten.
Nutzung von Weltwissen
Eine der am meisten unterschätzten Fähigkeiten von GPT Image 1.5 ist sein eingebautes Weltwissen. Das Modell kann Kontext aus subtilen Hinweisen ableiten und historisch und kulturell angemessene Bilder ohne explizite Anweisung generieren.
Create a realistic outdoor crowd scene in Bethel, New York on August 16, 1969.
Photorealistic, period-accurate clothing, staging, and environment.
Documentary photography style, shot on film, natural lighting.Das Modell weiß, dass dies Woodstock ist, ohne dass es gesagt wird. Es generiert Hippies, zeitgenössische Mode, die Festivalatmosphäre — alles allein aus Datum und Ort.
Dieses Weltwissen erstreckt sich auf Architektur durch Epochen, Mode durch Jahrzehnte, kulturelle Ereignisse, geografische Wahrzeichen, künstlerische Bewegungen und sogar spezifische Fotografieästhetik. Wenn Genauigkeit zählt, liefert die Angabe von Zeit und Ort oft bessere Ergebnisse als lange Beschreibungen dessen, was Sie zu sehen erwarten.
Die Kunst der präzisen Bearbeitung
Text-zu-Bild-Generierung ist beeindruckend, aber Bildbearbeitung ist das, wo GPT Image 1.5 wirklich glänzt. Die Fähigkeit, bestehende Bilder präzise zu modifizieren, während alles andere erhalten bleibt, eröffnet professionelle Workflows, die zuvor ohne Experten-Photoshop-Kenntnisse unmöglich waren.
Die goldene Regel der Bearbeitung
Jede erfolgreiche Bearbeitung folgt demselben Muster: Geben Sie explizit an, was sich ändert, geben Sie explizit an, was gleich bleibt. Das klingt offensichtlich, aber der Grad an erforderlicher Spezifität ist größer, als die meisten Menschen realisieren.
Strukturieren Sie Bearbeitungs-Prompts immer als: "Change ONLY [X]. Preserve EXACTLY: [comprehensive list of everything else]." Wiederholen Sie dann Ihre Bewahrungsliste bei jeder Folge-Bearbeitung, um ein allmähliches Abdriften vom Original zu verhindern.
Virtuelle Kleideranprobe
Der E-Commerce wird durch KI-Anprobemöglichkeiten transformiert. Hier ist die Prompt-Struktur, die ich für Kleidungstausche verwende, die die Identität perfekt bewahren.
Edit the image to dress this person in the provided clothing items.
MUST PRESERVE (do not change in any way):
- Face, facial features, expression, skin tone
- Body shape, proportions, and pose
- Hairstyle and hair color
- Background and environment
- Camera angle, framing, and composition
- Overall lighting direction and quality
CHANGE ONLY:
- Replace current clothing with provided garment images
- Fit garments naturally to body geometry
- Show realistic fabric draping, folds, and behavior
- Match lighting and shadows on fabric to original photo
REQUIREMENTS:
- Photorealistic integration — outfit should look worn, not pasted
- Maintain color temperature of original image
- No accessories, text, logos, or watermarks added
- Identity must remain clearly recognizableFür virtuelle Anproben verwenden Sie immer input_fidelity="high", um sicherzustellen, dass die Gesichtsähnlichkeit erhalten bleibt.
Stilübertragung
Stilübertragung nimmt die visuelle Sprache eines Bildes — seine Palette, Textur, Pinselstriche, Ästhetik — und wendet sie auf neue Inhalte an. Dies ist von unschätzbarem Wert für die Aufrechterhaltung der Markenkonsistenz oder die Erstellung kohärenter Serien.
Using the EXACT visual style of the reference image (Image 1), create:
A man riding a motorcycle on a winding mountain road.
STYLE ELEMENTS TO MATCH PRECISELY from reference:
- Color palette and saturation levels
- Line quality and weight
- Texture treatment and brushwork
- Lighting style and direction
- Level of detail vs. abstraction
- Overall artistic aesthetic
APPLY TO NEW CONTENT:
- Single subject (man on motorcycle)
- Clear composition with visual interest
- Mountain road environment with curves
- Sense of motion and freedom
The new image should look like it came from the same artist or series as
the reference. Maintain stylistic consistency exactly.Stilübertragung funktioniert am besten, wenn Sie spezifisch darüber sind, welche Stilelemente bewahrt und welche Inhaltselemente geändert werden sollen.
Objektaustausch
Objekte auszutauschen und dabei den Fotorealismus beizubehalten, ist jetzt praktisch möglich. Das Geheimnis ist, nicht nur zu beschreiben, was hinzugefügt werden soll, sondern wie es sich in die bestehende Szene integrieren soll.
In this room photo, replace ONLY the white plastic chairs with
mid-century modern wooden chairs (walnut finish, tapered legs,
woven seat).
PRESERVE COMPLETELY:
- Camera angle and perspective
- Room lighting direction and quality
- All other furniture and objects
- Wall colors and decorations
- Floor material and shadows
- Overall image quality and color grading
INTEGRATION REQUIREMENTS:
- Chairs must match room's perspective exactly
- Wood grain should catch existing light realistically
- Contact shadows must be natural and match light source
- Scale must be accurate relative to table height
- New chairs should look like they belong in this room
Photorealistic result — should look like the original photograph.Innenarchitektur-Visualisierung ist eine der kommerziell wertvollsten Bearbeitungsanwendungen.
Skizze zu fotorealistischem Render
Grobe Skizzen in polierte Renderings zu verwandeln, ist unglaublich nützlich für Produktdesign, Architektur und Konzeptentwicklung. Der Prompt muss die Skizze als zu befolgende Spezifikation behandeln.
Transform this hand-drawn sketch into a photorealistic image.
PRESERVE FROM SKETCH:
- Exact layout and proportions
- Perspective and viewing angle
- Element placement and relationships
- Implied depth and layering
ADD FOR REALISM:
- Appropriate real-world materials and textures
- Consistent natural lighting (interpret from sketch shading)
- Environmental context matching the implied setting
- Surface imperfections and wear appropriate to materials
CONSTRAINTS:
- Do not add new elements not present in sketch
- Do not add text or watermarks
- Treat the sketch as an architectural blueprint to follow exactly
- Fill in realistic details while honoring the original compositionDas Modell interpretiert die Absicht der Skizze und füllt realistische Details ein, während die ursprüngliche Komposition beibehalten wird.
Beleuchtungs- und Wettertransformation
Umgebungsbedingungen zu ändern, während die Szenengeometrie erhalten bleibt, ist eine meiner Lieblings-Bearbeitungsanwendungen. Perfekt für das Erstellen von saisonalen Varianten, Tageszeit-Alternativen oder Stimmungsanpassungen.
Transform this daytime summer scene into a winter evening with snowfall.
CHANGE:
- Time of day: from afternoon to dusk (warm interior lights visible)
- Season: summer to deep winter
- Weather: clear to active snowfall
- Ground: grass to fresh snow coverage
- Trees: summer foliage to bare branches with snow
- Atmosphere: add visible breath if people present
- Surfaces: add frost on windows and metal
PRESERVE:
- Camera position and angle exactly
- All objects and their exact positions
- Architecture and structural elements
- People and their poses (update clothing appropriately)
- Overall composition and framing
Style: Photorealistic, natural atmospheric perspective, visible
snowflakes in air, cozy contrast between warm interior lights and
cold exterior. Should feel photographed, not filtered.Verwenden Sie input_fidelity="high" und quality="high" für beste Ergebnisse bei Umgebungstransformationen.
Mehrbild-Compositing
Das Kombinieren von Elementen aus mehreren Quellbildern erfordert klare Anweisungen darüber, was woher kommt und wie sich Elemente nahtlos integrieren sollen.
I'm providing 2 images:
- Image 1: Beach scene with woman standing on shore at sunset
- Image 2: Golden retriever sitting in a studio setting
Task: Place the dog from Image 2 into the beach scene from Image 1,
positioned next to the woman, looking up at her.
MATCHING REQUIREMENTS:
- Dog's lighting must match beach sunset (warm golden light from left)
- Scale dog appropriately relative to woman's height
- Dog should cast shadow consistent with scene's sun angle
- Sand texture should show around and under dog's paws
- Fur should catch the same golden hour highlights as scene
PRESERVE FROM IMAGE 1:
- Woman's exact appearance, position, and pose
- Beach background completely unchanged
- Original photo's color grading and mood
The composite should look like a single photograph taken on location.
No visible compositing artifacts.Verweisen Sie auf Bilder nach Nummer und seien Sie explizit darüber, welche Elemente übertragen werden und welche fixiert bleiben.
Textübersetzung in Bildern
Die Lokalisierung visueller Inhalte für internationale Märkte wird mit den Textfähigkeiten von GPT Image 1.5 dramatisch vereinfacht.
Translate all text in this infographic from English to Japanese.
MUST PRESERVE:
- Exact layout, spacing, and positioning of all elements
- All visual elements, icons, illustrations, and graphics
- Typography hierarchy (headlines vs body text relationships)
- Color scheme and overall design aesthetic
- Font weights and relative sizes
TRANSLATION REQUIREMENTS:
- Accurate Japanese translation with natural phrasing
- Match visual weight and style to original fonts
- Adjust character spacing for Japanese typographic norms
- No text truncation or overflow outside original bounds
Do not modify any non-text elements. Only change the language.Dieser Workflow handhabt Marketingmaterialien, UI-Screenshots, Verpackungen und Infografiken ohne Neuaufbau von Grund auf.
Fortgeschrittene Techniken für Profis
Sobald Sie die Grundlagen gemeistert haben, werden diese fortgeschrittenen Techniken Ihre Arbeit auf ein wirklich professionelles Niveau heben. Dies sind Muster, die ich durch umfangreiche Experimente entwickelt habe — Techniken, die konsistent überlegene Ergebnisse liefern.
Charakterkonsistenz über Bilder hinweg
Eine der größten Herausforderungen bei der KI-Bildgenerierung ist die Aufrechterhaltung der Charakterkonsistenz über mehrere Bilder hinweg. Für Kinderbücher, Markenmaskottchen oder jedes Projekt, das denselben Charakter in verschiedenen Szenen erfordert, ist hier mein bewährter Workflow.
Generieren Sie ein detailliertes Referenzbild, das das definitive Erscheinungsbild des Charakters festlegt. Fügen Sie alle Schlüsselsdetails hinzu: Outfit, Proportionen, Ausdruck, Farbpalette. Speichern Sie dieses Bild — es wird Ihre Quelle der Wahrheit.
Schreiben Sie eine detaillierte Textbeschreibung des Charakters, auf die Sie in allen zukünftigen Prompts verweisen werden. Seien Sie spezifisch zu jedem visuellen Element. Dieser Textanker ergänzt den visuellen.
Beim Erstellen neuer Szenen schließen Sie immer das Ankerbild als Eingabe ein und weisen explizit an "maintain exact character appearance from reference image" (genaues Erscheinungsbild des Charakters aus dem Referenzbild beibehalten).
Das Modell behält den Kontext innerhalb einer Konversationssitzung bei. Bauen Sie auf erfolgreichen Bildern auf, anstatt für jede Szene neu zu beginnen. Verweisen Sie direkt auf vorherige Generationen.
Continue the children's book story using the character from the reference image.
New Scene:
The same young forest hero is gently helping a frightened squirrel out
of a fallen hollow tree after a winter storm. Snow on the ground, bare
branches above, warm light filtering through clouds.
CHARACTER CONSISTENCY (from reference):
- Same green hooded tunic, exact shade and style
- Same soft brown boots
- Same belt pouch
- Same facial features, proportions, and color palette
- Same gentle, heroic personality in expression
- Same children's book proportions
STYLE CONSISTENCY (from reference):
- Same watercolor illustration style
- Same soft outlines
- Same warm earthy color treatment
- Same whimsical, friendly aesthetic
New elements: winter forest environment, frightened squirrel, fallen
tree with hollow.
Do not redesign the character. Do not change the artistic style.
No text. No watermarks.Verweisen Sie auf das Ankerbild und wiederholen Sie wichtige Charakterdetails, um die Konsistenz über das gesamte Buch hinweg aufrechtzuerhalten.
Die 3D-stilisierte Porträttechnik
Das Erstellen von hyper-stilisierten 3D-Porträts aus Referenzfotos ist zu einer meiner Signatur-Ausgaben geworden. Der Schlüssel ist extreme Spezifität in Bezug auf die gewünschte Ästhetik.
Create a hyper-stylized 3D floating head portrait based on this person.
STYLE CHARACTERISTICS:
- Smooth skin with glossy vinyl-finish surface
- Strong highlighter on cheekbones and nose tip catching soft light
- Holographic, iridescent eyeshadow (purple to teal color shift)
- Thick hair sculpted in slick, glossy waves like polished acrylic
- Small metallic chrome nose piercing with brushed reflections
EXPRESSION:
- Confident, slightly unimpressed look — half-lidded eyes, subtly
arched brow, the sophisticated "too cool" attitude.
TECHNICAL SPECIFICATIONS:
- Head floats isolated against plain white background
- Slight 15-degree tilt (premium product render feeling)
- Bright, diffuse studio lighting with no harsh shadows
- Emphasis on glossy, plastic, subsurface scattering effects
- Ultra-smooth textures throughout
- Close-up portrait angle, straight-on, 85mm lens feel
The result should look like a high-end 3D character render or
collectible figure — plastic perfection with personality.Dieser Detaillierungsgrad der Ästhetik erzeugt bemerkenswert konsistente Ergebnisse bei verschiedenen Subjekten.
Chibi-Charakter-Transformation
Das Konvertieren von Fotos in entzückende Charaktere im Chibi-Stil funktioniert überraschend gut für Markenmaskottchen, Social-Media-Avatare und Merchandise.
Transform this person into an adorable chibi-style character.
CHIBI PROPORTIONS:
- Tiny body (about 1 head-height tall)
- Oversized head (3x body proportions)
- Large, sparkling eyes with cute highlights
- Soft, rounded facial features
- Cheerful, expressive pose with personality
PRESERVE FROM ORIGINAL:
- Recognizable facial features (simplified but identifiable)
- Hairstyle, length, and hair color
- Distinctive clothing style or accessories
- Any notable characteristics (glasses, jewelry, etc.)
- Overall personality and vibe
STYLE:
- Smooth pastel shading
- Clean lines and simplified details
- Bright, expressive colors
- Collectible figure aesthetic
Background: Simple gradient or plain color to showcase character.
The result should feel like an irresistible chibi mascot that
clearly represents the original person.Chibi-Transformationen funktionieren gut für Personal Branding, Team-Avatare und Merchandise-Designs.
Marketing-Creatives mit perfektem Text
Das Erstellen von Marketingmaterialien mit genauem Text erfordert strenge Typografiekontrolle und explizite Textspezifikationen.
Create a realistic highway billboard mockup featuring this product.
BILLBOARD CONTENT:
- Product bottle prominently displayed on left third
- Main headline on right (EXACT TEXT, render verbatim):
"Fresh & Clean — Every Day"
- Tagline below headline: "Nature's Best Ingredients"
- Small logo placeholder area in bottom right corner
TYPOGRAPHY SPECIFICATIONS:
- Headline: Bold sans-serif, white text, high contrast
- Tagline: Light sans-serif, slightly smaller, same white
- Clean kerning, centered alignment within text area
- Text appears EXACTLY ONCE — no duplicates anywhere
SCENE:
- Billboard on highway overpass or roadside structure
- Sunset lighting creating warm, appealing atmosphere
- Photorealistic environment with motion-blurred vehicles below
- Professional advertising photography feel
No watermarks. No additional marketing copy. No logos unless
specified. Text must be perfectly legible and correctly spelled.Verwenden Sie immer quality="high" für Marketingmaterialien mit Text. Überprüfen Sie die Rechtschreibung vor der endgültigen Verwendung.
Produktfotografie-Extraktion
Das Erstellen sauberer Produktaufnahmen mit isolierten Subjekten ist für den E-Commerce unerlässlich. Hier ist der Prompt, der funktioniert.
Extract the product from this image for e-commerce use.
OUTPUT SPECIFICATIONS:
- Transparent background (RGBA PNG format)
- Crisp silhouette with clean edges
- No halos or color fringing around product
- All product labels and text perfectly preserved
- Exact product geometry and proportions maintained
OPTIONAL ENHANCEMENT:
- Add subtle, realistic contact shadow
- Shadow should be soft and natural, no hard edges
- Shadow works with the transparent background
CRITICAL CONSTRAINTS:
- Do NOT restyle or recolor the product
- Do NOT modify product appearance in any way
- Only remove background and add optional shadow
- Preserve every detail of the original product exactlyHinweis: Das aktuelle Modell rendert ein Schachbrettmuster für Transparenz — erfordert möglicherweise Nachbearbeitung für echten Alphakanal.
Bekannte Einschränkung
Die Hintergrundentfernung rendert derzeit ein visuelles Schachbrettmuster, um Transparenz anzuzeigen, anstatt echte RGBA-Transparenz in der Ausgabedatei zu erzeugen. Für den Produktionseinsatz müssen Sie die Ausgabe möglicherweise nachbearbeiten, um das Schachbrettmuster mit Bildbearbeitungssoftware in tatsächliche Transparenz umzuwandeln.
Die iterative Verfeinerungsschleife
Versuchen Sie nicht, Perfektion in einem einzigen Prompt zu erreichen. Professionelle Ergebnisse entstehen durch systematische Iteration.
Der Verfeinerungsprozess
- Generieren: Erstellen Sie das Anfangsbild mit Kernelementen und Gesamtkomposition
- Bewerten: Identifizieren Sie die 1-2 wichtigsten Probleme, die zuerst angegangen werden müssen
- Verfeinern: Beheben Sie nur diese spezifischen Probleme und bewahren Sie explizit alles andere
- Sperren: Speichern Sie den aktuellen Zustand, bevor Sie die nächste Iteration versuchen
- Wiederholen: Fahren Sie fort, bis Sie zufrieden sind, und bauen Sie inkrementell auf
Jede kleine, fokussierte Änderung summiert sich zu präzisen Endergebnissen mit weit weniger Frustration, als alles auf einmal zu versuchen.
Professionelle Workflows in der Praxis
Theorie ist wertvoll, aber zu sehen, wie sich Techniken zu kompletten Workflows verbinden, ist der Punkt, an dem sich das Verständnis kristallisiert. Hier sind die Workflows, die ich in der beruflichen Praxis am häufigsten verwende.
E-Commerce Produktfotografie-Pipeline
Komplettes Produkt-Visuell-System
- Produktextraktion: Entfernen Sie Hintergründe von rohen Produktfotos, erstellen Sie saubere isolierte Aufnahmen
- Lifestyle-Kontexte: Generieren Sie Umgebungsszenen (Küche, Büro, Außenbereich) und setzen Sie Produkte darin ein
- Farbvarianten: Erstellen Sie Produktfarbvarianten durch gezielte Bearbeitung ohne erneutes Fotografieren
- Marketing-Creatives: Generieren Sie Billboard-Mockups, Social-Media-Grafiken, Banneranzeigen mit Produktintegration
- Lokalisierung: Übersetzen Sie Text in Marketingmaterialien für verschiedene Märkte bei gleichzeitiger Beibehaltung des Designs
Eine komplette Produktfotografie-Pipeline, die zuvor Studiozeit, Photoshop-Expertise und mehrere Spezialisten erforderte, läuft jetzt durch eine Reihe von KI-Prompts.
Content-Creator Visuelle Bibliothek
Aufbau konsistenter Marken-Assets
- Charakterentwicklung: Erstellen Sie ein Markenmaskottchen oder einen persönlichen Avatar mit detailliertem Ankerbild
- Styleguide-Generierung: Erstellen Sie Farbpalettenreferenzen, Moodboards und ästhetische Beispiele
- Thumbnail-Fabrik: Generieren Sie konsistente YouTube/Social-Thumbnails unter Verwendung des etablierten Charakters und Stils
- Hintergrundbibliothek: Erstellen Sie Szenenhintergründe, die zur Markenästhetik passen, für verschiedene Inhaltstypen
- Variationserweiterung: Verwenden Sie Stilübertragung, um visuelle Konsistenz über alle neuen Inhalte hinweg aufrechtzuerhalten
Bauen Sie Ihr visuelles Fundament einmal auf und iterieren Sie dann effizient. Schafft die Art von Markenkonsistenz, die zuvor ein dediziertes Designteam erforderte.
Schnelles Design-Prototyping
Vom Konzept zum Visuellen in Minuten
- Grobskizze: Handgezeichnetes Basiskonzept (Serviettenqualität ist in Ordnung — grobe Formen und Layout)
- Anfangs-Render: Konvertieren Sie die Skizze in ein fotorealistisches oder stilisiertes Bild unter Beibehaltung Ihrer Komposition
- Iterationszyklus: Verfeinern Sie durch gezielte Bearbeitungen ("wärmeres Licht", "anderes Material", "mehr Kontrast")
- Variantenerkundung: Generieren Sie mehrere Variationen (n=4) für Kundenpräsentation oder Entscheidungsfindung
- Endpolitur: Hochwertiger Export der ausgewählten Richtung mit verfeinerten Details
Designer berichten von dramatisch schnellerer Konzepterstellung im Vergleich zu traditionellen digitalen Erstellungsworkflows.
Kinderbuch-Illustrations-Pipeline
Erstellung konsistenter illustrierter Bücher
- Charakterdesign: Erstellen Sie ein detailliertes Charakter-Referenzblatt, das das definitive Erscheinungsbild festlegt
- Stiletalblierung: Generieren Sie 2-3 Beispielseiten, um den Illustrationsstil festzulegen, wählen Sie die beste aus
- Szene-für-Szene-Generierung: Arbeiten Sie die Geschichte Seite für Seite durch und verweisen Sie immer sowohl auf Charakter- als auch auf Stilanker
- Konsistenzprüfung: Sehen Sie alle Seiten zusammen an, verwenden Sie die Bearbeitung, um Charakterabweichungen oder Stilinkonsistenzen zu beheben
- Endgültige Verfeinerung: Polieren Sie einzelne Seiten nach Bedarf, während Sie den etablierten Look beibehalten
Der Ankerbild-Ansatz macht konsistente Charakterillustration über ein ganzes Buch hinweg wirklich erreichbar.
Die Fehler, die meine Ergebnisse ruinierten
Nachdem ich mir selbst und unzähligen anderen dabei zugesehen habe, wie sie mit der KI-Bildgenerierung kämpfen, habe ich die Muster identifiziert, die Erfolg von Frustration trennen. Hier sind die Fehler, die ich früher gemacht habe — und wie ich sie behoben habe.
❌ Keyword-Stuffing
Der Fehler: Das Hinzufügen von "highly detailed, 8K, photorealistic, trending on ArtStation, masterpiece" zu jedem einzelnen Prompt.
Die Lösung: Beschreiben Sie stattdessen spezifische visuelle Eigenschaften. "Sichtbare Hautporen, morgendliches Fensterlicht, 50mm Objektiv Tiefenschärfe" kommuniziert weit mehr als generische Qualitätsschlüsselwörter.
❌ Der Mega-Prompt
Der Fehler: Der Versuch, jedes mögliche Detail in einem massiven Prompt zu spezifizieren, in der Hoffnung, dass das Modell irgendwie meine komplette Vision herausfindet.
Die Lösung: Beginnen Sie einfach. Holen Sie sich zuerst ein solides Basisbild, dann verfeinern Sie mit gezielten Folge-Prompts. Inkrementelles Aufbauen liefert weit bessere Ergebnisse.
❌ Vage Bearbeitungsanweisungen
Der Fehler: Zu sagen "mach es besser" oder "korrigiere die Beleuchtung", ohne zu spezifizieren, was "besser" bedeutet oder wie sich die Beleuchtung ändern soll.
Die Lösung: Seien Sie spezifisch bezüglich der Änderung. "Verschiebe die Beleuchtung von hartem Oberlicht zu weichem Fensterlicht von links, mit wärmerer Farbtemperatur."
❌ Vergessen der Bewahrungsliste
Der Fehler: Änderungen anzufordern, ohne explizit anzugeben, was unverändert bleiben soll, und dann überrascht zu sein, wenn andere Elemente abdriften.
Die Lösung: Jeder Bearbeitungs-Prompt enthält explizite Bewahrungsanforderungen. Wiederholen Sie sie bei jeder Iteration, da sich das Modell nicht an frühere Einschränkungen erinnert.
❌ Kontext-Amnesie
Der Fehler: Neue Konversationen für verwandte Bilder zu beginnen und den gesamten aufgebauten Kontext und die Konsistenz zu verlieren.
Die Lösung: Bauen Sie innerhalb von Sitzungen für verwandte Arbeit. Verweisen Sie direkt auf vorherige Generationen. Verwenden Sie Phrasen wie "gleicher Stil wie das vorherige Bild", um Kontext zu nutzen.
❌ Falsche Qualitätseinstellungen
Der Fehler: Immer hohe Qualität (langsam und teuer für Iteration) oder immer niedrige Qualität (fehlende entscheidende Details, wenn es darauf ankommt) zu verwenden.
Die Lösung: Passen Sie die Einstellungen an die Aufgabe an. Niedrige Qualität für Erkundung und Iteration; hohe Qualität für endgültige Ausgaben und alles mit Text.
❌ Den Modell bekämpfen
Der Fehler: Den exakt gleichen Prompt wiederholt auszuführen und unterschiedliche Ergebnisse zu erwarten, oder eine Richtung zu erzwingen, der das Modell konsistent widersteht.
Die Lösung: Wenn ein Prompt nicht funktioniert, formulieren Sie ihn um, anstatt ihn zu wiederholen. Andere Wörter aktivieren andere Muster. Manchmal muss sich Ihr Ansatz ändern, nicht nur die Ausgabe des Modells.
❌ Ignorieren der Stochastik
Der Fehler: Identische Ergebnisse von identischen Prompts zu erwarten, Frustration, wenn Ausgaben variieren.
Die Lösung: Generieren Sie mehrere Variationen (n=4) und wählen Sie die beste. Umarmen Sie die Variabilität als Quelle kreativer Optionen anstatt als Fehler, den es zu überwinden gilt.
Die einzige wirkungsvollste Änderung, die die meisten Menschen vornehmen können: Hören Sie auf, Prompts als Wünsche zu behandeln, und fangen Sie an, sie als Spezifikationen zu behandeln. Seien Sie so präzise, wie Sie es in einem Design-Briefing für einen menschlichen Mitarbeiter wären. Das Modell ist bemerkenswert fähig — aber es braucht klare Anweisungen, um diese Fähigkeit zu zeigen.
API-Integration für Entwickler
Wenn Sie GPT Image 1.5 programmgesteuert in Anwendungen integrieren, finden Sie hier die technischen Details und Best Practices, die Sie benötigen.
Grundlegende API-Einrichtung
import os
import base64
from openai import OpenAI
client = OpenAI()
# Create output directory
os.makedirs("output_images", exist_ok=True)
def save_image(result, filename: str) -> None:
"""Save base64 image response to file."""
image_base64 = result.data[0].b64_json
with open(f"output_images/{filename}", "wb") as f:
f.write(base64.b64decode(image_base64))
# Basic text-to-image generation
result = client.images.generate(
model="gpt-image-1.5",
prompt="Your detailed prompt here",
quality="high", # or "low" for faster iteration
n=1 # number of variations
)
save_image(result, "output.png")Bildbearbeitung mit mehreren Eingaben
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # Essential for identity preservation
quality="high",
image=[
open("input_images/source.png", "rb"),
open("input_images/style_reference.png", "rb"),
],
prompt="""
Apply the artistic style from Image 2 to the subject in Image 1.
PRESERVE: subject's identity, pose, and composition
CHANGE: artistic style, color palette, texture treatment
Do not add new elements. Maintain subject likeness exactly.
"""
)
save_image(result, "styled_output.png")Wichtige API-Parameter
Generierungsparameter
model
"gpt-image-1.5" — das neueste Flaggschiffmodell mit den besten Fähigkeiten
prompt
Ihre Textbeschreibung — Struktur zählt mehr als Länge
quality
"high" (hoch) für Detail und Textarbeit, "low" (niedrig) für Geschwindigkeit und Iteration
n
Anzahl der zu generierenden Variationen (typischerweise 1-4, höher für Erkundung)
Bearbeitungsparameter
image
Dateiobjekt oder Liste von Dateiobjekten für Mehrbild-Eingaben
input_fidelity
"high" (hoch) für Identitätsbewahrung, kritisch für Porträtarbeit
Preiserwägungen
API-Kostenstruktur
- Token-basierte Preisgestaltung: Kosten skalieren mit Auflösung und Qualitätseinstellungen
- 1MP hohe Qualität: Ungefähr $133 pro 1.000 Bilder
- 1MP niedrige Qualität: Ungefähr $9 pro 1.000 Bilder
- Kosteneinsparungen: Bildeingabe/-ausgabe-Kosten sind 20% niedriger als bei GPT Image 1
Für Anwendungen mit hohem Volumen beginnen Sie immer mit niedriger Qualität und aktualisieren Sie nur für endgültige Ausgaben oder textlastige Bilder.
Wie es im Vergleich zu anderen Tools abschneidet
Ich habe viel Zeit mit jedem großen KI-Bildgenerierungstool verbracht. Hier ist meine ehrliche Einschätzung, wie der Bildgenerator von ChatGPT (GPT Image 1.5) im Vergleich zur Konkurrenz abschneidet.
GPT Image 1.5 vs Gemini 3.0 Pro Image
GPT Image 1.5 gewinnt: Instruktionsbefolgung (90% vs 77%), Text-Rendering-Genauigkeit, präzise Bearbeitung, API-Integrationsqualität
Gemini 3.0 Pro gewinnt: Gesamtbildqualität bei einigen Benchmarks, kreative Interpretation, komplexe Szenen mit mehreren Figuren
Meine Meinung: GPT Image 1.5 für professionelle Arbeit, die Präzision und Konsistenz erfordert; Gemini für kreative Erkundung, wo Sie mehr Interpretation wünschen
GPT Image 1.5 vs Midjourney
GPT Image 1.5 gewinnt: Befolgen von Anweisungen, Bildbearbeitungsfähigkeiten, API-Zugriff, Text-Rendering, vorhersehbare Ergebnisse
Midjourney gewinnt: Künstlerische Ästhetik und "Wow-Faktor", Community- und Sharing-Funktionen, malerische Stile
Meine Meinung: GPT Image 1.5 für professionelle/kommerzielle Arbeit, wo Sie spezifische Ergebnisse benötigen; Midjourney für künstlerische Erkundung und Concept Art
GPT Image 1.5 vs DALL-E 3
GPT Image 1.5 gewinnt: Bearbeitungsfähigkeiten, Geschwindigkeit (4x schneller), Konsistenz über Iterationen hinweg, Instruktionsbefolgung
DALL-E 3 gewinnt: Nichts Signifikantes — GPT Image 1.5 ist der Nachfolger und verbessert jede Dimension
Meine Meinung: Wenn Sie noch DALL-E 3 verwenden, führen Sie sofort ein Upgrade durch. GPT Image 1.5 ist strikt besser.
GPT Image 1.5 vs Stable Diffusion
GPT Image 1.5 gewinnt: Benutzerfreundlichkeit, keine Einrichtung erforderlich, Instruktionsbefolgung, Text-Rendering, konsistente Qualität
Stable Diffusion gewinnt: Volle Anpassbarkeit, lokale Kontrolle, unbegrenzte kostenlose Generierung, Feinabstimmung, spezialisierte Modelle
Meine Meinung: GPT Image 1.5 für Geschwindigkeit und Leichtigkeit; Stable Diffusion für Kontrolle, Anpassung und kostenbewusste Arbeit mit hohem Volumen
In Benchmark-Tests erreichte GPT Image 1.5 die Position #1 sowohl in den Kategorien Text-zu-Bild als auch Bildbearbeitung in der Artificial Analysis Image Arena. Für Produktionsarbeit, die zuverlässige, vorhersehbare Ergebnisse mit präziser Kontrolle erfordert, ist es derzeit die beste verfügbare Option.
Die wahre Antwort? Das beste Tool hängt von Ihren spezifischen Bedürfnissen ab. Ich pflege den Zugang zu mehreren Tools, weil jedes in verschiedenen Dingen hervorragend ist. Aber wenn ich nur eines für professionelle Arbeit haben könnte, würde ich GPT Image 1.5 wegen seiner Zuverlässigkeit, Präzision und Bearbeitungsfähigkeiten wählen.
Power-User-Geheimnisse
Dies sind die Tipps, die mich von "ziemlich guten" zu "professionellen" Ergebnissen brachten. Jeder einzelne wurde durch umfangreiche Experimente und manchmal schmerzhafte Misserfolge gelernt.
Starten Sie frisch für neue Projekte
Beginnen Sie jedes neue Projekt in einer neuen Konversation. Kontext aus alten Projekten kann in neue Generationen einsickern und unerwartete Ergebnisse verursachen. Sauberes Blatt, saubere Ergebnisse.
Die 80/20-Regel
Holen Sie 80% richtig in der ersten Generation. Verwenden Sie die Bearbeitung für die letzten 20%. Der Versuch, Perfektion in einem einzigen Prompt zu erreichen, führt zu Frustration und Zeitverschwendung.
Spezifisch schlägt Superlativ
"Aufgenommen auf Mittelformatfilm mit natürlichem Korn" schlägt "ultra-hohe Qualität erstaunlich detailliert" jedes Mal. Spezifika leiten das Modell; Superlative fügen nur Rauschen hinzu.
Zitieren Sie Ihren Text
Setzen Sie erforderlichen Text immer in "Anführungszeichen" und spezifizieren Sie, dass er "genau einmal, keine Duplikate" erscheinen soll. Dies verhindert die Duplikation und Rechtschreibfehler, die das Text-Rendering plagen.
Enden Sie mit Negativen
Beenden Sie jeden Prompt mit dem, was Sie nicht wollen: "No watermarks, no text unless specified, no logos, no excessive saturation, no artificial bokeh". Prävention schlägt Korrektur.
Speichern Sie Ihre Gewinner
Wenn Sie ein großartiges Ergebnis erzielen, speichern Sie sowohl das Bild ALS AUCH den kompletten Prompt. Bauen Sie eine persönliche Bibliothek bewährter Prompts auf, die Sie für zukünftige Projekte anpassen können.
Umformulieren, nicht wiederholen
Wenn ein Prompt nicht funktioniert, führen Sie ihn nicht erneut aus in der Hoffnung auf Glück. Formulieren Sie ihn um. Andere Wörter aktivieren andere Muster im Modell. Ändern Sie Ihren Ansatz.
Immer hohe Qualität für Text
Wann immer Ihr Bild Text enthält — überhaupt irgendeinen Text — verwenden Sie den Modus hohe Qualität. Text in niedriger Qualität ist oft unleserlich, was die Geschwindigkeitseinsparungen wertlos macht.
Verständnis der Stochastik
Hier ist etwas Entscheidendes: KI-Bildgenerierung ist fundamental stochastisch. Derselbe Prompt kann jedes Mal unterschiedliche Ergebnisse liefern. Das ist kein Fehler — es ist die Natur der Technologie.
Umarmen Sie die Varianz
Anstatt die Zufälligkeit zu bekämpfen, nutzen Sie sie. Generieren Sie 4 Variationen und wählen Sie die beste. Manchmal führt die "unerwartete" Interpretation zu etwas Besserem, als Sie sich ursprünglich vorgestellt haben. Die besten KI-Künstler, die ich kenne, stützen sich auf glückliche Zufälle, während sie genug Kontrolle behalten, um ihre Ziele zu erreichen. Variabilität ist ein Feature, kein Fehler.
Fehlerbehebung bei häufigen Problemen
Nach Tausenden von Generationen bin ich auf jedes denkbare Problem gestoßen. Hier erfahren Sie, wie Sie die häufigsten Probleme beheben, die Schöpfer frustrieren.
Problem: Text ist falsch geschrieben oder dupliziert
Lösung
Setzen Sie exakten Text in Anführungszeichen: "RESTAURANT" nicht restaurant. Fügen Sie explizite Anweisung hinzu: "render exactly once, no duplicates". Für schwierige Wörter buchstabieren Sie Buchstabe für Buchstabe: "R-E-S-T-A-U-R-A-N-T". Verwenden Sie immer quality="high" für jedes Bild, das Text enthält. Überprüfen Sie die Ausgabe vor der Verwendung.
Problem: Charakter sieht auf Bildern unterschiedlich aus
Lösung
Erstellen Sie zuerst ein detailliertes Charakter-Ankerbild und speichern Sie es. Schließen Sie diesen Anker als Eingabe für jede nachfolgende Generation ein. Schreiben Sie eine Charakter-Bibel, die jedes visuelle Detail auflistet. Weisen Sie explizit an "maintain exact character appearance from reference image". Verwenden Sie input_fidelity="high" in API-Aufrufen. Arbeiten Sie nach Möglichkeit in Einzelsitzungen.
Problem: Bearbeitungen ändern mehr als angefordert
Lösung
Seien Sie expliziter bezüglich der Bewahrung. Strukturieren Sie Prompts als "Change ONLY: [X]. Preserve EXACTLY: [Liste alles andere im Detail]". Wiederholen Sie die vollständige Bewahrungsliste bei jeder Bearbeitungsiteration — das Modell erinnert sich nicht an frühere Einschränkungen. Verwenden Sie input_fidelity="high" für wichtige Elemente.
Problem: Bilder sehen offensichtlich "KI-generiert" aus
Lösung
Fügen Sie realistische Unvollkommenheiten hinzu: "subtle film grain", "slight lens vignette", "natural skin texture with pores and subtle blemishes", "dust particles visible in sunbeam", "minor wear on materials". Perfektion sieht falsch aus. Realität ist chaotisch. Beschreiben Sie, was Kameras tatsächlich einfangen, nicht idealisierte Versionen.
Problem: Farben sehen übersättigt oder unnatürlich aus
Lösung
Spezifizieren Sie die Farbbehandlung explizit: "natural color grading", "true-to-life colors", "muted earth tones", "not oversaturated", "color-accurate". Verweisen Sie auf spezifische Filmmaterialien für Farbleitung: "Kodak Portra color science" oder "documentary color grading". Fügen Sie "realistic color balance, no HDR look" hinzu.
Problem: Hintergrundentfernung erzeugt Halos oder Artefakte
Lösung
Fordern Sie explizit an: "transparent background (RGBA PNG format), crisp silhouette, no halos, no color fringing, clean edges, no artifacts". Beachten Sie, dass das aktuelle Modell ein Schachbrettmuster für Transparenz rendert — Nachbearbeitung kann für echten Alphakanal in der Produktion erforderlich sein.
Problem: Kompositionen fühlen sich unausgewogen oder ungeschickt an
Lösung
Spezifizieren Sie die Komposition explizit: "subject positioned using rule of thirds", "centered with symmetrical framing", "generous negative space on left for text overlay", "eye-level camera angle", "subject fills 60% of frame". Überlassen Sie die Komposition nicht dem Zufall — beschreiben Sie genau, was Sie wollen.
Die Zukunft der KI-Bildgenerierung
Wir erleben gerade eine Revolution. Was vor zwei Jahren noch Science-Fiction war, ist heute eine Ware, auf die jeder zugreifen kann. Aber wir befinden uns noch in den frühen Kapiteln dieser Geschichte. Hier ist, was ich kommen sehe.
Was am Horizont steht
🎬 Nahtlose Videointegration
Die Grenze zwischen Standbildern und Video verschwimmt schnell. Erwarten Sie nahtlose Übergänge von der Bildgenerierung zu animierten Sequenzen innerhalb derselben Schnittstelle. Frühe Versionen sind bereits hier (Sora, Runway), und sie verbessern sich schnell. Ihre Bild-Prompts werden mit minimaler Anpassung zu Video-Prompts.
🎯 Perfekte Konsistenz
Charakter- und Stilkonsistenz über unbegrenzte Bilder hinweg ohne manuellen Aufwand. Der Anker-und-Referenz-Workflow wird automatisch werden. Trainieren Sie das Modell an wenigen Beispielen Ihres Charakters, und es behält die perfekte Konsistenz für immer bei. Das "Drift"-Problem wird vollständig gelöst sein.
✏️ Kollaborative Bearbeitung in Echtzeit
Interaktive Bearbeitung, bei der Sie Elemente konversationell in Echtzeit malen, ziehen und manipulieren. Stellen Sie sich Photoshop vor, wo jeder Pinselstrich eine KI-Antwort auslöst und komplexe Bearbeitungen durch Konversation statt durch technische Werkzeuge geschehen.
🎨 Persönliches Stiellernen
Trainieren Sie das Modell an Ihrer Ästhetik mit einer Handvoll Beispielen. Ihr eigener persönlicher KI-Künstler, der Ihren Geschmack, Ihre Marke, Ihre visuelle Sprache versteht — und sie konsistent auf alles anwendet, was Sie erstellen.
Die Demokratisierung der visuellen Kreation
Was wir beobachten, ist nichts weniger als die Demokratisierung der visuellen Kreation. Fähigkeiten, die einst jahrelanges Training erforderten — Produktfotografie, Grafikdesign, Illustration, Concept Art — werden für jeden zugänglich, der beschreiben kann, was er sehen möchte.
Dies eliminiert nicht den Wert menschlicher Kreativität. Wenn überhaupt, hebt es ihn. Wenn Ausführung einfach wird, wird Vision alles. Die Menschen, die in dieser neuen Landschaft gedeihen, werden nicht diejenigen sein, die die realistischsten Hände rendern können — die KI erledigt das jetzt. Es werden diejenigen sein, die etwas zu sagen haben, etwas zu zeigen haben, etwas, das Menschen bewegt.
Die Fotografen, die beim Übergang von Film zu Digital erfolgreich waren, waren nicht diejenigen, die sich dem Wandel widersetzten. Es waren diejenigen, die neue Werkzeuge annahmen, während sie ihre künstlerische Vision beibehielten. KI-Bildgenerierung ist die gleiche Art von Übergang, nur dramatischer und schneller.
Die besten KI-generierten Bilder werden immer von Menschen erstellt werden, die sowohl die Technologie ALS AUCH die Kunst verstehen. Meistern Sie die Werkzeuge, aber vergessen Sie nie, dass Werkzeuge der Vision dienen. Die Technologie verstärkt menschliche Kreativität — sie ersetzt sie nicht.
Abschließende Gedanken
Thumbnails, Grafiken und soziale Inhalte in Minuten statt Stunden
Produktfotografie, Varianten und Marketing in beispiellosem Maßstab
Schnelle Konzepte und Kundenpräsentationen, die früher Tage dauerten
Robuster programmatischer Zugriff zum Erstellen bildfähiger Anwendungen
Natürliche Sprache macht den Einstieg einfacher als traditionelle Designwerkzeuge
Qualität und Konsistenz ausreichend für kommerzielle Arbeit
Ich begann diese Reise frustriert und skeptisch. Ich hatte den Hype um KI-Bildgenerierung gehört, stieß aber wiederholt gegen die Wand zwischen Marketingversprechen und praktischer Realität. Finger mit unmöglicher Anatomie. Text, der zu abstrakten Formen verschmolz. Kompositionen, die aktiv gegen meine Absichten kämpften. Ich war bereit, alles als überbewertete Technologie abzutun.
Dann lernte ich, die Sprache der Maschine zu sprechen. Ich hörte auf zu beschreiben, was ich sehen wollte, und fing an zu beschreiben, was eine Kamera einfangen würde. Ich hörte auf, auf Glück zu hoffen, und fing an, systematisch zu bauen. Ich hörte auf, gegen das Modell zu kämpfen, und fing an, mit ihm zusammenzuarbeiten.
GPT Image 1.5 hat nicht nur frühere Probleme verbessert — es hat meine Beziehung zur visuellen Kreation grundlegend verändert. Ich denke jetzt in Begriffen von Prompts und Iterationen statt Pinseln und Ebenen. Ich gehe visuelle Herausforderungen mit der Zuversicht an, dass es eine Prompt-Struktur gibt, die das produziert, was ich brauche. Die Bilder, die ich heute erstelle, hätten vor nur zwei Jahren Tage gebraucht, um produziert zu werden. Die Ideen, die ich erkunden kann, sind nur durch Vorstellungskraft begrenzt, nicht durch technische Fähigkeiten.
Die Lernkurve ist real. Sie werden dies nicht über Nacht meistern. Aber die Prinzipien in diesem Leitfaden — Struktur über Schlüsselwörter, Spezifität über Superlative, Iteration über Perfektion, das Fotografie-Mindset — werden Wochen frustrierenden Experimentierens in fokussiertes, produktives Lernen komprimieren.
Mehr als alles andere hoffe ich, dass dieser Leitfaden Ihnen das gibt, was ich mir gewünscht hätte, als ich anfing: nicht nur Techniken, sondern ein mentales Modell. Ein Verständnis dafür, wie diese Technologie Sprache interpretiert, worauf sie reagiert und wie man ihre visuelle Sprache fließend spricht.
Die Lücke zwischen den Bildern in Ihrem Kopf und den Bildern auf Ihrem Bildschirm war noch nie kleiner. Und mit dem richtigen Ansatz schrumpft diese Lücke mit jedem Prompt, den Sie schreiben, weiter.
Jetzt gehen Sie los und machen Sie etwas Schönes.
Ich erinnere mich an diesen Moment um 2 Uhr morgens, als alles Klick machte — als das Bild, das erschien, nicht nur akzeptabel war, sondern genau das, was ich mir vorgestellt hatte. Dieses Gefühl ist jetzt für Sie verfügbar. Die Technologie ist angekommen. Die Techniken sind dokumentiert. Das Einzige, was übrig bleibt, ist Ihre Vorstellungskraft und Ihre Bereitschaft, eine neue Sprache zu lernen. Der ChatGPT Bildgenerator ist nicht nur ein Werkzeug — er ist ein kreativer Partner, der die menschliche Vision auf Weisen verstärkt, die wir gerade erst zu verstehen beginnen. Willkommen in der Zukunft der visuellen Kreation. Die Bilder, die Sie in Ihrem Kopf gesehen haben? Sie sind näher an der Realität als je zuvor.
Diskussion
0 KommentareKommentar hinterlassen
Seien Sie der Erste, der seine Gedanken teilt!