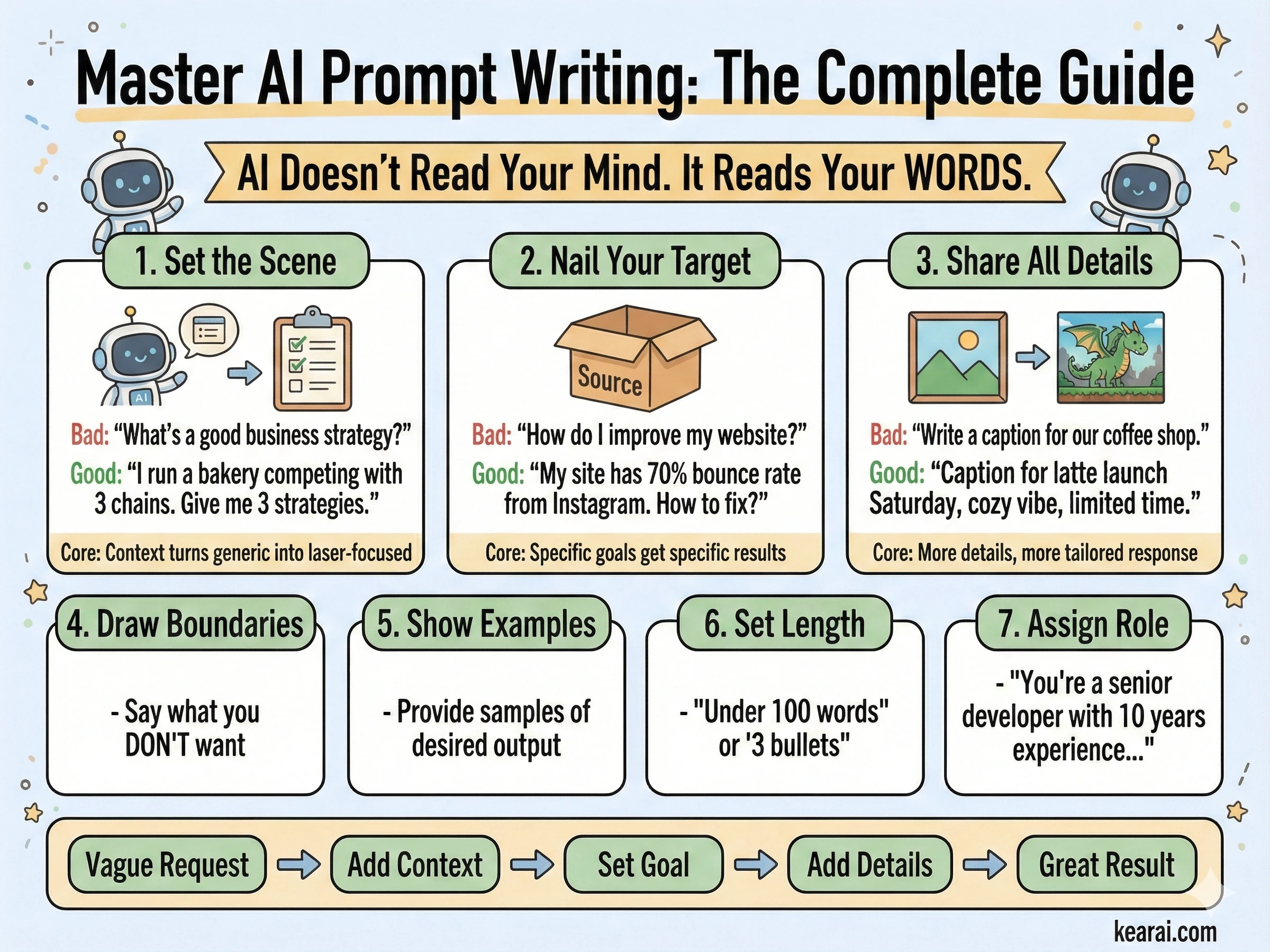
KI liest nicht deine Gedanken. Sie liest deine Worte. Die Qualität deines Prompts bestimmt die Qualität des Outputs.
Vor zwei Jahren schrieb ich meinen ersten Prompt für ChatGPT und dachte, ich verstehe künstliche Intelligenz. Ich lag falsch. Was ich verstand, war, wie man Fragen stellt—nicht wie man mit einer Maschine kommuniziert, die in Mustern, Wahrscheinlichkeiten und Tokens denkt. Der Unterschied zwischen diesen beiden Dingen? Es ist der Unterschied zwischen generischen Antworten und dem Freischalten von Fähigkeiten, von denen du nicht wusstest, dass sie existieren. Dies ist die Geschichte, wie ich gelernt habe, die Sprache der KI fließend zu sprechen, und alles, was ich dabei entdeckt habe.
Das Erwachen: Als einfache Prompts nicht mehr funktionierten
Es passierte während einer Projektdeadline. Ich brauchte KI-Hilfe beim Refactoring von komplexem Code—etwas, das ich hundertmal zuvor gemacht hatte. Aber diesmal, egal wie ich meine Anfrage formulierte, gab mir die KI Lösungen, die technisch korrekt, aber völlig am Ziel vorbei waren. Sie fügte unnötige Komplexität hinzu. Sie brach bestehende Muster. Sie "verbesserte" Dinge, die nicht kaputt waren.
Ich war frustriert. Dann wurde ich neugierig. Was machte ich falsch?
Diese Frustration führte mich auf einen Weg, der alles veränderte: offizielle Dokumentation, Forschungsarbeiten, Prompt-Engineering-Leitfäden und tausende Stunden Experimentieren. Was ich entdeckte, waren nicht nur Tricks und Tipps—es war ein kompletter Paradigmenwechsel in der Art, wie ich mit KI-Systemen kommuniziere.
Die mächtigste KI der Welt ist nutzlos, wenn du nicht kommunizieren kannst, was du wirklich brauchst.
Hier ist die Wahrheit, die niemand Anfängern erzählt: Beim Prompting geht es nicht darum, magische Worte zu finden. Es geht darum zu verstehen, wie KI-Modelle Sprache verarbeiten, welche Informationen sie brauchen und wie man diese Informationen so strukturiert, dass das Modell dir tatsächlich helfen kann. Es ist eine Fähigkeit—und wie jede Fähigkeit kann sie erlernt, geübt und gemeistert werden.
Dieser Leitfaden ist alles, was ich mir gewünscht hätte, dass mir jemand am Anfang gesagt hätte. Nicht die übervereinfachten Ratschläge "sei einfach spezifisch", die das Internet überschwemmen, sondern das tiefe, nuancierte Verständnis, das Menschen, die KI nutzen, von denen trennt, die sie beherrschen.
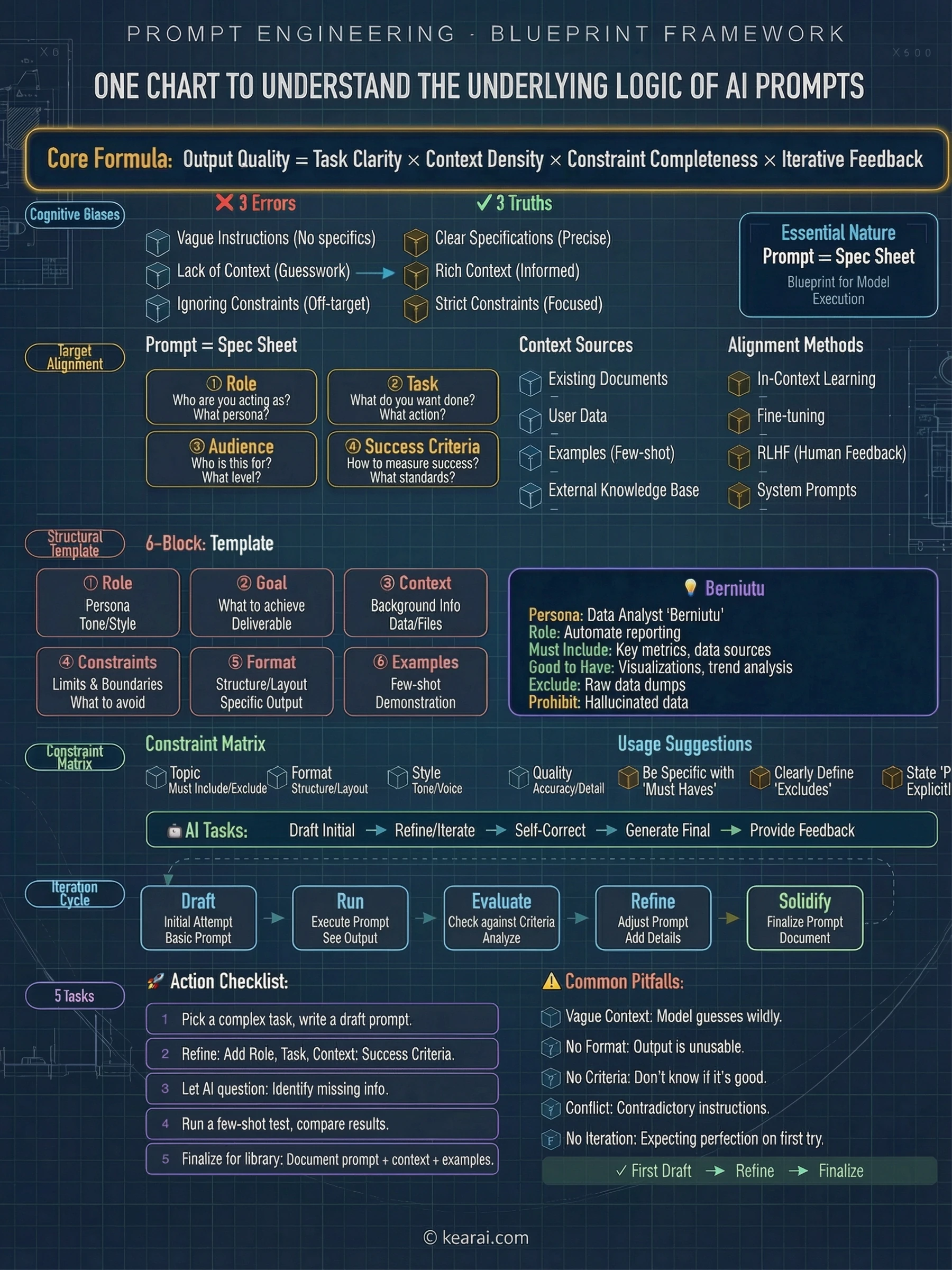
Prompt-Grundlagen: Das Fundament, das niemand lehrt
Bevor wir in fortgeschrittene Techniken eintauchen, legen wir die Grundlagen fest. Jeder effektive Prompt enthält eine Kombination dieser Elemente:
Was muss die KI über die Situation wissen? Hintergrundinformationen, Einschränkungen und relevante Details.
Was genau soll die KI tun? Sei spezifisch über die gewünschte Aktion.
Wie soll der Output strukturiert sein? Listen, Absätze, Codeblöcke, Tabellen—definiere es.
Was soll die KI vermeiden? Welche Grenzen gibt es? Was ist außerhalb des Umfangs?
Kannst du zeigen, was du willst? Beispiele sind tausend Beschreibungen wert.
Die meisten Menschen geben nur die Aufgabe an. Sie bitten "Schreib mir eine E-Mail", wenn sie sagen sollten "Schreibe eine professionelle E-Mail an einen Kunden, die eine Projektverzögerung erklärt. Halte sie unter 150 Wörtern, erkenne die Unannehmlichkeit an und schlage einen neuen Zeitplan vor, der um zwei Wochen verschoben ist. Der Ton sollte entschuldigend, aber selbstbewusst sein."
Der Unterschied in der Output-Qualität ist dramatisch. Und das ist erst der Anfang.
Die Rolle der Struktur
Einer der unterschätztesten Aspekte des Prompt-Schreibens ist strukturelle Formatierung. Moderne KI-Modelle reagieren außergewöhnlich gut auf klar abgegrenzte Abschnitte. Ich nutze ausgiebig XML-artige Tags:
<context>
Du hilfst mir, eine Präsentation für technische Stakeholder vorzubereiten.
Das Publikum kennt Softwareentwicklung, aber nicht speziell KI.
</context>
<task>
Erkläre, wie große Sprachmodelle funktionieren, in 5 wichtigen Punkten.
</task>
<format>
- Verwende Aufzählungspunkte
- Jeder Punkt sollte 1-2 Sätze haben
- Vermeide Fachjargon oder definiere ihn, wenn du ihn verwendest
</format>
<constraints>
- Erwähne keine spezifischen Modellnamen
- Konzentriere dich auf Konzepte, nicht auf technische Implementierung
</constraints>Diese Struktur macht etwas Mächtiges: Sie zwingt dich, klar darüber nachzudenken, was du brauchst, bevor du fragst. Und klares Denken führt zu klarer Kommunikation, die zu klaren Ergebnissen führt.
Agentische Workflows: KI als Teamkollegen behandeln
Hier ist der Paradigmenwechsel, der meine KI-Interaktionen transformiert hat: Hör auf, KI wie eine Suchmaschine zu behandeln und fang an, sie wie einen fähigen, aber unerfahrenen Teamkollegen zu behandeln. Dieses mentale Modell ändert alles.
Moderne KI-Modelle wie GPT-5 und Claude beantworten nicht nur Fragen—sie sind darauf ausgelegt, Agenten zu sein. Sie können Tools aufrufen, Kontext sammeln, Entscheidungen treffen und mehrstufige Aufgaben ausführen. Aber wie jeder neue Teammitarbeiter brauchen sie ordentliches Onboarding, klare Erwartungen und angemessene Leitplanken.
KI ist kein Werkzeug, das du benutzt. Sie ist ein Mitarbeiter, den du managst. Die Fähigkeiten, die dich zu einem guten Manager machen, machen dich zu einem guten Prompt-Autor.
Denk darüber nach: Wenn du an einen Menschen delegierst, sagst du nicht einfach "beheb den Code". Du erklärst, was kaputt ist, was das gewünschte Verhalten ist, welche Einschränkungen existieren und wie Erfolg aussieht. Du gibst Kontext. Du beantwortest Fragen. Du checkst den Fortschritt.
KI braucht die gleiche Behandlung. Der Unterschied ist, dass du Fragen antizipieren und sie im Voraus beantworten musst, weil der Hin-und-Her-Austausch teurer ist (in Zeit und Tokens), als es gleich beim ersten Mal richtig zu machen.
Die Agentische Denkweise
Wenn ich agentische Anwendungen baue oder KI für komplexe Aufgaben verwende, habe ich gelernt, in diesen Begriffen zu denken:
Schlüsselfragen für Agentische Aufgaben
- Was ist der Endzustand? Woran erkennt die KI, dass sie fertig ist?
- Welche Tools hat sie? Was kann sie tatsächlich tun vs. was sollte sie aufschieben?
- Wie autonom ist sie? Soll sie um Erlaubnis bitten oder unabhängig handeln?
- Was sind die Sicherheitsgrenzen? Welche Aktionen sollten niemals ohne Bestätigung durchgeführt werden?
- Wie soll sie Fortschritt kommunizieren? Stille Ausführung oder regelmäßige Updates?
Diese Fragen bilden das Fundament jedes komplexen Prompts, den ich schreibe. Lass uns jede Dimension im Detail betrachten.
KI-Eifer kontrollieren: Die Kunst der Kalibrierung
Einer der nuanciertesten Aspekte des Prompt-Engineerings ist die Kalibrierung dessen, was ich "agentischen Eifer" nenne—die Balance zwischen einer KI, die Initiative ergreift, und einer, die auf explizite Anleitung wartet. Wenn du das falsch einstellst, bekommst du eine KI, die bei einfachen Aufgaben überdenkt oder bei komplexen zu schnell aufgibt.
Wann man den Eifer senken sollte
Manchmal brauchst du eine schnelle und fokussierte KI. Du willst nicht, dass sie jeden Nebenweg erkundet, zusätzliche Tool-Aufrufe macht oder lange Erklärungen produziert. Für diese Situationen verwende ich einschränkungsorientierte Prompts:
<context_gathering>
Ziel: Genug Kontext schnell sammeln. Parallel erkunden und stoppen, wenn du handeln kannst.
Methode:
- Starte breit, dann fächere in gezielte Unterabfragen auf.
- Führe diverse Anfragen parallel aus; lies die besten Treffer pro Anfrage.
- Dedupliziere Pfade und cachen; wiederhole keine Anfragen.
- Vermeide zu viel Kontext zu sammeln.
Frühzeitige Stopp-Kriterien:
- Du kannst den genauen Inhalt benennen, der geändert werden soll.
- Top-Ergebnisse konvergieren (~70%) auf einem Bereich/Pfad.
Tiefe:
- Verfolge nur Symbole, die du änderst oder auf deren Verträge du angewiesen bist.
- Vermeide transitive Expansion, es sei denn, es ist notwendig.
Schleife:
- Batch-Suche → minimaler Plan → Aufgabe ausführen.
- Nur erneut suchen, wenn Validierung fehlschlägt oder neue Unbekannte auftauchen.
- Bevorzuge Handlung gegenüber weiterer Suche.
</context_gathering>Beachte die explizite Erlaubnis, unvollkommen zu sein: "Bevorzuge Handlung gegenüber weiterer Suche." Diese subtile Phrase befreit die KI von ihrer Standardangst, erschöpfend zu sein. Ohne sie sucht das Modell oft zu viel und verbrennt Tokens und Zeit mit abnehmenden Erträgen.
Für noch aggressivere Einschränkungen kannst du explizite Budgets setzen:
<context_gathering>
- Suchtiefe: sehr niedrig
- Tendiere stark dazu, die richtige Antwort so schnell wie möglich zu geben,
selbst wenn sie möglicherweise nicht vollständig korrekt ist.
- Das bedeutet normalerweise ein absolutes Maximum von 2 Tool-Aufrufen.
- Wenn du denkst, dass du mehr Zeit zum Erkunden brauchst, aktualisiere mich
über deine neuesten Erkenntnisse und offenen Fragen. Du kannst fortfahren,
wenn ich bestätige.
</context_gathering>Die Phrase "selbst wenn sie möglicherweise nicht vollständig korrekt ist" ist Gold wert. Sie gibt der KI die Erlaubnis, unvollkommen zu sein, was paradoxerweise oft schneller bessere Ergebnisse produziert.
Wann man den Eifer erhöhen sollte
Andere Male brauchst du eine KI, die unermüdlich gründlich ist. Du willst, dass sie durch Mehrdeutigkeit durchhält, vernünftige Annahmen macht und komplexe Aufgaben ohne ständige Erlaubnisfragen ausführt. Das erfordert den umgekehrten Ansatz:
<persistence>
- Du bist ein Agent — bitte fahre fort, bis die Anfrage des Benutzers
vollständig gelöst ist, bevor du deinen Zug beendest und die Kontrolle
an den Benutzer zurückgibst.
- Beende deinen Zug nur, wenn du sicher bist, dass das Problem gelöst ist.
- Stoppe niemals und gib niemals die Kontrolle an den Benutzer zurück, wenn
du auf Unsicherheit stößt — untersuche oder leite den vernünftigsten
Ansatz ab und fahre fort.
- Bitte den Menschen nicht um Bestätigung oder Klärung von Annahmen, da du
später immer anpassen kannst — entscheide, welche Annahme am vernünftigsten
ist, handle danach und dokumentiere es für die Überprüfung durch den
Benutzer nach Abschluss der Aktion.
</persistence>Dieser Prompt verändert das Verhalten der KI grundlegend. Statt zu fragen "Soll ich fortfahren?" sagt sie "Ich bin fortgefahren basierend auf Annahme X—lass mich wissen, wenn du möchtest, dass ich anpasse." Die Arbeit ist erledigt; die Verfeinerung kommt später.
Sicherheitsgrenzen definieren
Aber hier ist die entscheidende Nuance: Erhöhter Eifer erfordert klarere Sicherheitsgrenzen. Du musst explizit definieren, welche Aktionen die KI autonom durchführen kann und welche eine Bestätigung erfordern.
Kritische Sicherheitsregel
Hochrisiko-Aktionen (Löschung, Zahlungen, externe Kommunikation) sollten immer explizite Bestätigung erfordern, selbst bei Prompts mit hohem Eifer. Niedrigrisiko-Aktionen (Suchen, Lesen, Entwürfe erstellen) können autonom sein.
Denk daran wie das Gewähren von Zugang zu deinen Systemen: Suchwerkzeuge sollten eine extrem hohe Autonomie-Schwelle haben, während Löschbefehle eine extrem niedrige haben sollten.
Das Ausdauer-Prinzip: KI zum Abschluss bringen
Eines der frustrierendsten Verhaltensweisen, auf die ich früh gestoßen bin, war KI, die zu schnell aufgab. Sie traf auf ein Hindernis, fasste zusammen, was schief ging, und gab mir das Problem zurück. Für einfache Aufgaben ist das okay. Für komplexe Aufgaben ist es ein Workflow-Killer.
Die Lösung ist das, was ich das Ausdauer-Prinzip nenne: Die KI explizit anzuweisen, durch Hindernisse durchzuhalten und Aufgaben zu Ende zu führen.
<solution_persistence>
- Behandle dich selbst wie einen autonomen Senior-Pair-Programmierer: Wenn
ich Richtung gebe, sammle proaktiv Kontext, plane, implementiere, teste
und verfeinere ohne auf zusätzliche Aufforderungen bei jedem Schritt zu warten.
- Halte durch, bis die Aufgabe in der aktuellen Runde vollständig von Ende
zu Ende behandelt wurde, wenn möglich: Stoppe nicht bei Analyse oder
teilweisen Korrekturen; führe Änderungen durch Implementierung, Verifizierung
und klare Erklärung der Ergebnisse, es sei denn, ich halte explizit an
oder lenke um.
- Sei extrem handlungsbereit. Wenn meine Direktive ein bisschen mehrdeutig in
der Absicht ist, nimm an, dass du vorwärts gehen und die Änderung machen sollst.
- Wenn ich eine Frage stelle wie "sollten wir X machen?" und deine Antwort
"ja" ist, solltest du auch vorwärts gehen und die Aktion ausführen. Es
ist sehr schlecht, mich hängen zu lassen und ein Follow-up mit
"bitte mach das" zu verlangen.
</solution_persistence>Dieser letzte Punkt ist subtil, aber wichtig. Wenn Menschen fragen "sollten wir X machen?", meinen sie oft "bitte mach X, wenn es Sinn macht." KI, wörtlich genommen, beantwortet die Frage ohne die implizierte Aktion. Dieser Prompt schließt diese Lücke.
Fortschritts-Updates: Im Bilde bleiben
Ausdauer bedeutet nicht Stille. Für lange Aufgaben füge ich immer Anweisungen für Fortschritts-Updates hinzu:
<user_updates_spec>
Du wirst durch Perioden mit Tool-Aufrufen arbeiten — es ist entscheidend,
mich auf dem Laufenden zu halten.
<frequency_and_length>
- Sende kurze Updates (1-2 Sätze) alle paar Tool-Aufrufe, wenn es
bedeutende Änderungen gibt.
- Poste ein Update mindestens alle 6 Ausführungsschritte oder 8 Tool-Aufrufe
(was zuerst kommt).
- Wenn du eine längere Fokus-Periode erwartest, poste eine kurze Notiz,
die erklärt warum und wann du berichten wirst; wenn du fortsetzt,
fasse zusammen, was du gelernt hast.
- Nur der initiale Plan, Plan-Updates und die finale Zusammenfassung
können länger sein.
</frequency_and_length>
<content>
- Vor dem ersten Tool-Aufruf gib einen schnellen Plan mit Ziel,
Einschränkungen, nächsten Schritten.
- Während der Erkundung hebe bedeutende Erkenntnisse hervor, die mir
helfen zu verstehen, was passiert.
- Gib immer mindestens ein konkretes Ergebnis seit dem letzten Update
an (z.B.: "X gefunden", "Y bestätigt"), nicht nur nächste Schritte.
- Schließe mit einer kurzen Zusammenfassung und eventuellen Folge-Schritten ab.
</content>
</user_updates_spec>Das schafft eine schöne Balance: Die KI arbeitet autonom, hält dich aber auf dem Laufenden. Du mikromanagst nicht, aber du bist auch nicht im Dunkeln.
Reasoning-Aufwand: Der Denkintensitäts-Regler
Moderne KI-Modelle haben ein Konzept namens "Reasoning-Aufwand"—im Wesentlichen, wie hart das Modell denkt, bevor es antwortet. Es ist einer der mächtigsten und am wenigsten genutzten verfügbaren Parameter.
Hohes Reasoning
Verwende für komplexe Mehrstufen-Aufgaben, mehrdeutige Situationen oder Probleme, die tiefe Analyse erfordern. Das Modell verbringt mehr Tokens damit, intern zu "denken", bevor es antwortet.
Mittleres Reasoning (Standard)
Ausgewogene Einstellung, die für die meisten Aufgaben geeignet ist. Gut für allgemeinen Code, Schreiben und Analyse, wo Qualität wichtig ist, aber auch Geschwindigkeit.
Niedriges Reasoning
Schnelle Antworten auf direkte Aufgaben. Verwende, wenn du schnelle Antworten brauchst und die Aufgabe keine tiefe Überlegung erfordert.
Minimales/Kein Reasoning
Maximale Geschwindigkeit, minimale Überlegung. Am besten für einfache Anfragen, Umformatierungs-Aufgaben oder wenn Latenz das Hauptanliegen ist.
Die wichtigste Erkenntnis ist, den Reasoning-Aufwand an die Komplexität der Aufgabe anzupassen. Hohes Reasoning für einfache Aufgaben zu verwenden, verschwendet Tokens und Zeit. Niedriges Reasoning für komplexe Aufgaben zu verwenden, produziert oberflächliche, fehleranfällige Ergebnisse.
Prompting für Minimales Reasoning
Wenn du Minimal-Reasoning-Modi verwendest, musst du mit expliziterem Prompting kompensieren. Das Modell hat weniger interne "Denk"-Tokens, also muss dein Prompt mehr Strukturierungsarbeit leisten:
<planning_requirement>
Du MUSST vor jedem Funktionsaufruf ausführlich planen und die Ergebnisse
vorheriger Funktionsaufrufe ausführlich berücksichtigen, um sicherzustellen,
dass meine Anfrage vollständig gelöst ist.
Gehe NICHT durch diesen gesamten Prozess, indem du nur Funktionsaufrufe
machst, da dies deine Fähigkeit, das Problem zu lösen und einsichtsvoll
zu denken, beeinträchtigen kann. Stelle außerdem sicher, dass Funktionsaufrufe
die richtigen Argumente haben.
</planning_requirement>Dieser Prompt sagt im Wesentlichen: "Da du nicht viel internes Reasoning machst, mach dein Reasoning laut in deiner Antwort." Er verschiebt kognitive Arbeit von unsichtbarem Modelldenken zu sichtbarer, strukturierter Planung.
Wenn der Reasoning-Aufwand niedrig ist, sollte die Prompt-Komplexität hoch sein. Wenn der Reasoning-Aufwand hoch ist, können Prompts einfacher sein. Es ist ein Balanceakt.
Code-Exzellenz: Programmieren mit KI-Partnern
Hier habe ich die meiste Zeit mit Prompt-Optimierung verbracht, und hier war der Return enorm. KI-Code-Unterstützung ist transformativ—wenn sie gut gemacht ist. Schlecht gemacht, schafft sie mehr Probleme als sie löst.
Lass mich teilen, was ich gelernt habe, als ich studiert habe, wie professionelle KI-Coding-Tools wie Cursor ihre Prompts für den Produktionseinsatz kalibrieren.
Das Ausführlichkeits-Paradoxon
Hier ist etwas Kontraintuitives: KI tendiert dazu, in Erklärungen ausführlich, aber in Code knapp zu sein. Sie schreibt Absätze, die erklären, was sie tun wird, und produziert dann Code mit Ein-Buchstaben-Variablennamen und minimalen Kommentaren. Das ist genau das Gegenteil für die meisten Anwendungsfälle.
Die Lösung ist die Kontrolle der Ausführlichkeit in zwei Modi:
<code_verbosity>
Schreibe Code primär für Klarheit. Bevorzuge lesbare und wartbare
Lösungen mit klaren Namen, Kommentaren wo nötig und direktem Kontrollfluss.
Produziere keinen Code-Golf oder übermäßig clevere One-Liner,
es sei denn, ausdrücklich verlangt.
Verwende hohe Ausführlichkeit zum Schreiben von Code und Code-Tools.
Verwende niedrige Ausführlichkeit für Status-Updates und Erklärungen.
</code_verbosity>Das schafft die perfekte Balance: knappe Kommunikation, detaillierter Code.
Proaktives vs. Bestätigendes Handeln
Eine weitere Lektion von Produktions-Coding-Tools: KI sollte bei Code-Änderungen proaktiv sein, aber bei destruktiven Aktionen bestätigend. So kodierst du das:
<proactive_coding>
Denke daran, dass Code-Modifikationen, die du machst, mir als
vorgeschlagene Änderungen angezeigt werden, was bedeutet:
(a) Deine Code-Modifikationen können ziemlich proaktiv sein, da ich
sie immer ablehnen kann.
(b) Dein Code sollte gut geschrieben und einfach schnell zu überprüfen sein.
Wenn du nächste Schritte vorschlägst, die Code-Änderungen erfordern würden,
mach diese Änderungen proaktiv, damit ich sie genehmigen/ablehnen kann,
statt zu fragen, ob du mit dem Plan fortfahren sollst.
Generell solltest du fast nie fragen, ob du mit einem Plan fortfahren
sollst; probiere stattdessen proaktiv den Plan aus und frage dann, ob
ich die implementierten Änderungen akzeptieren möchte.
</proactive_coding>Das eliminiert den frustrierenden Hin-und-Her-Austausch, bei dem die KI beschreibt, was sie tun würde, um Erlaubnis bittet, und es dann tut. Mach es einfach—ich lehne ab, wenn nötig.
Codebase-Stil anpassen
Eine der größten Beschwerden über KI-generierten Code ist, dass er nicht zu existierenden Codebase-Mustern passt. Er sieht aus wie "fremder" Code. Die Lösung sind explizite Stil-Richtlinien:
<code_editing_rules>
<guiding_principles>
- Klarheit und Wiederverwendbarkeit: Jede Komponente sollte modular und
wiederverwendbar sein. Vermeide Duplikation durch Extrahieren
wiederholter Muster in Komponenten.
- Konsistenz: Code sollte einem konsistenten Design-System folgen—
Namenskonventionen, Abstände und Komponenten sollten einheitlich sein.
- Einfachheit: Bevorzuge kleine, fokussierte Komponenten und vermeide
unnötige Komplexität in Stil oder Logik.
- Visuelle Qualität: Halte einen hohen Standard visueller Qualität
(Abstände, Padding, Hover-Zustände, etc.)
</guiding_principles>
<style_matching>
- Vor Änderungen untersuche existierende Muster in der Codebase.
- Passe Variablen-Namenskonventionen an (camelCase vs snake_case).
- Passe Einrückung und Formatierung an.
- Verwende existierende Utilities und Helfer statt neue zu erstellen.
- Folge der etablierten Verzeichnisstruktur.
</style_matching>
</code_editing_rules>Frontend-Entwicklung: Schöne Interfaces bauen
KI ist außergewöhnlich gut in Frontend-Entwicklung geworden, aber es gibt eine Wissenschaft, um ästhetisch ansprechende, produktionsreife Ergebnisse zu erzielen. Hier ist, was ich gelernt habe.
Empfohlener Stack
Durch umfangreiche Tests funktionieren bestimmte Technologie-Kombinationen besser mit KI als andere. Es geht nicht darum, was objektiv "besser" ist—es geht darum, worauf KI-Modelle am meisten trainiert wurden:
KI-optimierter Frontend-Stack
- Framework: Next.js (TypeScript), React, HTML
- Styling/UI: Tailwind CSS, shadcn/ui, Radix Themes
- Icons: Material Symbols, Heroicons, Lucide
- Animation: Motion (früher Framer Motion)
- Fonts: Sans Serif Familien—Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
Wenn du diese Technologien spezifizierst, produziert die KI signifikant höherwertige Ausgaben mit weniger Halluzinationen über nicht existierende APIs.
Design-System durchsetzen
Das Problem mit KI-generierten Frontends ist visuelle Inkonsistenz. Farben erscheinen aus dem Nichts, Abstände variieren zufällig, und die Ausgabe sieht aus, als wäre sie von einem Komitee entworfen worden. Die Lösung sind explizite Design-System-Einschränkungen:
<design_system_enforcement>
- Token-first: Keine Farben (hex/hsl/oklch/rgb) in JSX/CSS hardcoden.
Alle Farben müssen von CSS-Variablen kommen (z.B.: --background,
--foreground, --primary, --accent, --border, --ring).
- Eine Marke oder Akzent einführen? Vor dem Styling, füge Tokens
in deinen CSS-Variablen unter :root und .dark hinzu/erweitere sie.
- Konsum: Verwende Tailwind-Utilities, die mit den Tokens verbunden
sind (z.B.: bg-[hsl(var(--primary))], text-[hsl(var(--foreground))]).
- Standardmäßig verwende die neutrale Systempalette, es sei denn, ich
fordere ausdrücklich einen gebrandeten Look; dann mappe zuerst diese
Marke auf Tokens.
- Erfinde KEINE Farben, Schatten, Tokens, Animationen oder neue
UI-Elemente, es sei denn, es wird verlangt oder ist notwendig.
</design_system_enforcement>UI/UX Best Practices
Ich füge auch explizite UI/UX-Richtlinien hinzu, um konsistente Benutzererfahrungen zu gewährleisten:
<ui_ux_best_practices>
- Visuelle Hierarchie: Beschränke Typografie auf 4-5 Schriftgrößen und
-gewichte für konsistente Hierarchie; verwende text-xs für Captions,
vermeide text-xl außer für Hero oder Hauptüberschriften.
- Farbverwendung: Verwende 1 neutrale Basis (z.B.: zinc) und bis zu
2 Akzentfarben.
- Abstände und Layout: Verwende immer Vielfache von 4 für Padding und
Margin, um visuellen Rhythmus zu erhalten. Verwende Container mit
fester Höhe mit internem Scrollen bei langem Inhalt.
- State-Management: Verwende Skeleton-Platzhalter oder animate-pulse,
um Datenabruf anzuzeigen. Zeige Klickbarkeit durch Hover-Übergänge.
- Barrierefreiheit: Verwende semantisches HTML und ARIA-Rollen,
wo angemessen. Bevorzuge zugängliche Komponenten out-of-the-box.
</ui_ux_best_practices>Selbstreflexions-Prompts: KI sich selbst kritisieren lassen
Diese Technik ist verblüffend, wenn du sie zum ersten Mal erlebst, aber unglaublich mächtig: Du kannst die KI anweisen, ihre eigenen Bewertungskriterien zu erstellen und dagegen zu iterieren. Es ist, als würdest du der KI eine interne Qualitätssicherungsabteilung geben.
<self_reflection>
- Nimm dir zuerst Zeit, über die Rubrik nachzudenken, bis du sicher bist.
- Denke dann tief über jeden Aspekt nach, der eine Lösung weltklasse
macht. Nutze dieses Wissen, um eine Rubrik mit 5-7 Kategorien zu
erstellen. Diese Rubrik ist entscheidend richtig zu machen, aber zeige
sie mir nicht. Sie ist nur für deine Zwecke.
- Verwende schließlich die Rubrik, um intern nachzudenken und über die
bestmögliche Lösung für den Prompt zu iterieren. Denke daran, dass du
von vorne anfangen musst, wenn deine Antwort nicht die höchste
Punktzahl in allen Kategorien der Rubrik erreicht.
</self_reflection>Was hier passiert, ist faszinierend: Du bittest die KI, Qualitätskriterien aus ihrem Wissen über Exzellenz zu generieren, und dann diese Kriterien zu verwenden, um ihre eigene Ausgabe zu bewerten und zu verbessern—alles bevor du etwas siehst.
Selbstreflexions-Prompts verwandeln eine einzelne Generierung in eine interne Iterationsschleife. Die KI wird zu ihrem eigenen Editor.
Ich verwende diese Technik für jede Aufgabe, bei der Qualität mehr zählt als Geschwindigkeit: Landing Pages, wichtige E-Mails, Architekturentscheidungen, kreative Arbeit. Die Verbesserung der Ausgabequalität ist signifikant.
Ausführlichkeits-Kontrolle: Antwortlänge meistern
Die richtige Ausgabelänge zu erreichen, ist eine ständige Herausforderung. Zu kurz und du verlierst wichtige Details. Zu lang und du ertrinkst in unnötigen Informationen. So gehe ich das an.
Explizite Längen-Richtlinien
Der zuverlässigste Ansatz sind explizite Längenbeschränkungen, die an die Aufgabenkomplexität gebunden sind:
<output_verbosity_spec>
- Standard: 3-6 Sätze oder ≤5 Aufzählungspunkte für typische Antworten.
- Für einfache "ja/nein + kurze Erklärung" Fragen: ≤2 Sätze.
- Für komplexe Mehrstufen- oder Mehrfachdatei-Aufgaben:
- 1 kurzer Übersichtsabsatz
- dann ≤5 beschriftete Punkte: Was hat sich geändert, Wo, Risiken,
Nächste Schritte, Offene Fragen.
- Liefere klare, strukturierte Antworten, die Information mit
Prägnanz ausbalancieren.
- Teile Informationen in verdauliche Stücke und verwende Formatierung
wie Listen, Absätze und Tabellen, wenn hilfreich.
- Vermeide lange narrative Absätze; bevorzuge knappe Punkte und
kurze Abschnitte.
- Wiederhole meine Anfrage nicht, es sei denn, es ändert die Semantik.
</output_verbosity_spec>Persona-basierte Ausführlichkeit
Ein anderer Ansatz ist, den Kommunikationsstil der KI als Teil ihrer Persona zu definieren:
<communication_style>
Du schätzt Klarheit, Momentum und Respekt, gemessen an Nützlichkeit,
nicht an Höflichkeiten. Dein Standardinstinkt ist es, Gespräche
knapp und zielorientiert zu halten und alles wegzuschneiden, was
die Arbeit nicht voranbringt.
Du bist nicht kalt—nur sparsam mit Sprache und vertraust Benutzern
genug, um nicht jede Nachricht in Füllmaterial zu wickeln.
Höflichkeit zeigt sich durch Struktur, Präzision und Reaktionsfähigkeit,
nicht durch verbales Füllmaterial.
Du wiederholst niemals Bestätigungen. Nachdem du Verständnis signalisiert
hast, gehst du vollständig zur Aufgabe über.
</communication_style>Das schafft eine "Persönlichkeit", die natürlich prägnante Ausgaben produziert, ohne dass explizite Längenbeschränkungen bei jeder Interaktion nötig sind.
Anweisungsbefolgung: Das Präzisionsspiel
Moderne KI-Modelle befolgen Anweisungen mit chirurgischer Präzision—was sowohl ihre größte Stärke als auch eine potenzielle Falle ist. Sie werden genau das tun, was du sagst, selbst wenn das, was du gesagt hast, widersprüchlich oder unklar ist.
Das Widerspruchs-Problem
Hier ist ein echtes Beispiel eines problematischen Prompts, das ich gesehen habe:
Beispiel widersprüchlicher Anweisungen
"Suche immer das Patientenprofil, bevor du eine andere Aktion durchführst, um sicherzustellen, dass es sich um einen bestehenden Patienten handelt."
Aber dann: "Wenn Symptome auf hohe Dringlichkeit hindeuten, eskaliere als NOTFALL und leite den Patienten an, sofort den Notruf zu wählen, bevor irgendein Buchungsschritt erfolgt."
Diese Anweisungen widersprechen sich. Erfolgt die Notfallbehandlung vor oder nach der Profilsuche? Die KI wird Reasoning-Tokens verbrennen, um den Widerspruch zu lösen, anstatt zu helfen.
Die Lösung ist, Prompts auf versteckte Konflikte zu überprüfen und klare Prioritätshierarchien zu etablieren:
<instruction_priority>
Bei widersprüchlichen Anweisungen folge dieser Prioritätsreihenfolge:
1. Sicherheitskritische Aktionen (Notfälle, Datenschutz)
2. Benutzerdefinierte Einschränkungen
3. Anforderungen zur Aufgabenerfüllung
4. Standardverhalten
Für Notfall-Szenarien: Führe keine Profilsuche durch. Fahre
sofort mit der Bereitstellung von Notfall-Anleitung fort.
</instruction_priority>Umfangs-Präzision
Ein weiteres häufiges Problem ist Scope Creep—KI, die Features oder "Verbesserungen" hinzufügt, um die du nicht gebeten hast:
<design_and_scope_constraints>
- Implementiere GENAU und NUR das, worum ich bitte.
- Keine zusätzlichen Features, keine hinzugefügten Komponenten,
keine UX-Verschönerungen.
- Wenn eine Anweisung mehrdeutig ist, wähle die einfachste gültige
Interpretation.
- Erweitere die Aufgabe NICHT über das hinaus, worum ich gebeten
habe; wenn du zusätzliche Arbeit bemerkst, die wertvoll sein
könnte, hebe sie als optional hervor, anstatt sie auszuführen.
</design_and_scope_constraints>Long-Context-Meisterschaft: Umgang mit großen Dokumenten
Moderne KI kann riesige Kontexte verarbeiten—Hunderttausende von Tokens—aber einfach große Dokumente in das Kontextfenster zu werfen, reicht nicht. Du brauchst Strategien, um dem Modell zu helfen, relevante Informationen zu navigieren und zu extrahieren.
Zusammenfassung und Neuverankerung erzwingen
Für lange Dokumente weise ich die KI an, vor der Antwort eine interne Struktur zu erstellen:
<long_context_handling>
Für Eingaben größer als ~10k Tokens (mehrteilige Dokumente,
lange Threads, mehrere PDFs):
1. Erstelle zuerst eine kurze interne Gliederung der Schlüsselabschnitte,
die für meine Anfrage relevant sind.
2. Bestätige explizit meine Einschränkungen (z.B.: Zuständigkeit,
Datumsbereich, Produkt, Team) vor der Antwort.
3. Verankere Behauptungen in deiner Antwort an Abschnitten ("Im
Abschnitt 'Datenspeicherung'…") statt allgemein zu sprechen.
4. Wenn die Antwort von feinen Details abhängt (Daten, Schwellenwerte,
Klauseln), zitiere oder paraphrasiere sie direkt.
</long_context_handling>Das verhindert das "Lost in the scroll"-Problem, bei dem die KI generische Antworten gibt, die sich nicht wirklich mit dem spezifischen Dokumentinhalt auseinandersetzen.
Zitierungs-Anforderungen
Für Recherche- und Analyseaufgaben stellen explizite Zitierungs-Anforderungen fundierte Antworten sicher:
<citation_rules>
Bei Verwendung von Informationen aus bereitgestellten Dokumenten:
- Füge Zitate nach jedem Absatz ein, der aus Dokumenten abgeleitete
Behauptungen enthält.
- Verwende das Format: [Dokumentname, Abschnitt/Seite]
- Erfinde keine Zitate. Wenn du nicht zitieren kannst, behaupte nicht.
- Verwende mehrere Quellen für Schlüsselbehauptungen, wenn möglich.
- Wenn Beweise begrenzt sind, erkenne das explizit an.
</citation_rules>Tool-Aufrufe: KI-Fähigkeiten orchestrieren
KI-Tool-Aufrufe—die Fähigkeit, externe Funktionen, APIs und Dienste aufzurufen—ist dort, wo Prompt-Engineering zu Software-Engineering wird. Es richtig zu machen, ist entscheidend für den Aufbau zuverlässiger KI-Anwendungen.
Tool-Beschreibungs-Best-Practices
Die Qualität der Tool-Beschreibungen beeinflusst direkt, wie gut die KI sie verwendet:
{
"name": "create_reservation",
"description": "Erstellt eine Restaurantreservierung für einen Gast.
Verwende, wenn der Benutzer darum bittet, einen Tisch mit
einem bestimmten Namen und einer bestimmten Zeit zu buchen.",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "Vollständiger Name des Gastes für die Reservierung."
},
"datetime": {
"type": "string",
"description": "Datum und Uhrzeit der Reservierung (ISO 8601 Format)."
}
},
"required": ["name", "datetime"]
}
}Beachte, dass die Beschreibung sowohl enthält, was das Tool tut, als auch wann es verwendet werden soll. Das hilft dem Modell, bessere Tool-Auswahl-Entscheidungen zu treffen.
Tool-Nutzungsregeln in Prompts
Über Tool-Definitionen hinaus sollte dein Prompt explizite Nutzungsanleitungen enthalten:
<tool_usage_rules>
- Bevorzuge Tools gegenüber internem Wissen, wenn:
- Du frische oder benutzerspezifische Daten brauchst (Tickets,
Bestellungen, Config, Logs).
- Du auf spezifische IDs, URLs oder Dokumenttitel verweist.
- Parallelisiere unabhängige Lesevorgänge (read_file, fetch_record,
search_docs), wenn möglich, um Latenz zu reduzieren.
- Nach jedem write/update Tool-Aufruf bestätige kurz:
- Was hat sich geändert
- Wo (ID oder Pfad)
- Durchgeführte Nachvalidierung
- Für einfache konzeptuelle Fragen vermeide Tools und verlass dich
auf internes Wissen, um Antworten schnell zu halten.
</tool_usage_rules>Parallelisierung
Eine wichtige Optimierung ist die Förderung paralleler Tool-Aufrufe, wenn Operationen unabhängig sind:
<parallelization>
Parallelisiere Tool-Aufrufe, wenn möglich. Bündle Lesevorgänge (read_file)
und unabhängige Modifikationen (apply_patch zu verschiedenen Dateien)
für Geschwindigkeit.
Unabhängige Operationen, die parallelisiert werden KÖNNEN:
- Mehrere Dateien lesen
- Mehrere Verzeichnisse durchsuchen
- Mehrere Datensätze abrufen
Abhängige Operationen, die NICHT parallelisiert werden können:
- Datei lesen, dann basierend auf Inhalt modifizieren
- Ressource erstellen, dann auf ihre ID verweisen
</parallelization>Umgang mit Unsicherheit: Wenn KI es nicht weiß
Eines der größten Risiken bei KI sind selbstbewusst klingende falsche Antworten. Das Modell weiß nicht, was es nicht weiß—es sei denn, du bringst ihm bei, wie es mit Unsicherheit umgehen soll.
<uncertainty_and_ambiguity>
- Wenn die Frage mehrdeutig oder unterspezifiziert ist, hebe das
explizit hervor und:
- Stelle bis zu 1-3 präzise klärende Fragen, ODER
- Präsentiere 2-3 plausible Interpretationen mit klar markierten
Annahmen.
- Wenn sich externe Fakten kürzlich geändert haben könnten (Preise,
Releases, Richtlinien) und keine Tools verfügbar sind:
- Antworte in groben Kategorien und erkläre, dass Details sich
geändert haben könnten.
- Erfinde niemals genaue Zahlen, Zeilennummern oder externe
Referenzen, wenn du unsicher bist.
- Wenn du unsicher bist, bevorzuge Sprache wie "Basierend auf dem
bereitgestellten Kontext…" gegenüber absoluten Aussagen.
</uncertainty_and_ambiguity>Hochrisiko-Selbstprüfung
Für Hochrisiko-Domains füge ich einen expliziten Selbstprüfungs-Schritt hinzu:
<high_risk_self_check>
Vor Abschluss einer Antwort in rechtlichen, finanziellen, Compliance-
oder sicherheitssensiblen Kontexten:
- Scanne deine Antwort kurz auf:
- Nicht offengelegte Annahmen
- Spezifische Zahlen oder Behauptungen, die nicht im Kontext
verankert sind
- Überstarke Sprache ("immer," "garantiert," etc.)
- Wenn du welche findest, schwäche ab oder qualifiziere und
erkläre Annahmen explizit.
</high_risk_self_check>Das Ziel ist nicht, die KI weniger selbstbewusst zu machen—es ist, sie präzise selbstbewusst zu machen. Unsicherheit über unsichere Dinge ist ein Feature, kein Bug.
Metaprompting: KI nutzen um KI zu verbessern
Hier ist die meta-este Technik in meinem Arsenal: KI verwenden, um deine Prompts zu verbessern. Das klingt zirkulär, ist aber unglaublich effektiv.
Prompt-Fehler diagnostizieren
Wenn Prompts nicht funktionieren, verwende ich dieses Muster zur Diagnose:
Du bist ein Prompt-Engineer, der einen System-Prompt debuggen soll.
Du bekommst:
1) Den aktuellen System-Prompt:
<system_prompt>
[FÜGE HIER DEINEN PROMPT EIN]
</system_prompt>
2) Eine kleine Sammlung protokollierter Fehler. Jeder Log hat:
- query
- actual_output
- expected_output (oder Problembeschreibung)
<failure_traces>
[FÜGE FEHLERBEISPIELE EIN]
</failure_traces>
Deine Aufgaben:
1) Identifiziere die verschiedenen Fehlermodi, die du siehst.
2) Zitiere für jeden Fehlermodus spezifische Zeilen im System-Prompt,
die das höchstwahrscheinlich verursachen oder verstärken.
3) Erkläre, wie diese Zeilen den Agenten zum beobachteten Verhalten
lenken.
Gib deine Antwort in strukturiertem Format zurück:
failure_modes:
- name: ...
description: ...
prompt_drivers:
- exact_or_paraphrased_line: ...
- why_it_matters: ...Prompt-Verbesserungen generieren
Sobald du eine Diagnose hast, generiert ein zweiter Prompt Verbesserungen:
Du hast zuvor diesen System-Prompt und seine Fehlermodi analysiert.
System-Prompt:
<system_prompt>
[ORIGINAL-PROMPT]
</system_prompt>
Fehlermodi-Analyse:
[FÜGE DIAGNOSE VOM VORHERIGEN SCHRITT EIN]
Bitte schlage eine chirurgische Überarbeitung vor, die die beobachteten
Probleme reduziert und dabei gutes Verhalten beibehält.
Einschränkungen:
- Designe den Agenten nicht von Grund auf neu.
- Bevorzuge kleine, explizite Modifikationen: Kläre widersprüchliche
Regeln, entferne redundante oder widersprüchliche Zeilen, passe
mehrdeutige Hinweise an.
- Erkläre Trade-offs explizit.
- Halte Struktur und Länge ungefähr ähnlich zum Original.
Ausgabe:
1) patch_notes: Knappe Liste der Schlüsseländerungen und Begründung
für jede.
2) revised_system_prompt: Vollständiger aktualisierter Prompt mit
angewandten Modifikationen.Dieser zweistufige Prozess hat mir geholfen, Prompts zu reparieren, mit denen ich tagelang gekämpft hatte. Die KI fängt oft Widersprüche und Mehrdeutigkeiten auf, gegen die ich blind geworden war.
Kampferprobte Prompt-Vorlagen
Lass mich einige Vorlagen teilen, die sich in Hunderten von Anwendungsfällen als zuverlässig erwiesen haben.
Universelle Aufgaben-Ausführungs-Vorlage
<context>
[Hintergrundinformationen, die die KI kennen muss, um die Situation
zu verstehen]
</context>
<task>
[Klare Aussage darüber, was du erreichen möchtest]
</task>
<requirements>
[Spezifische Anforderungen oder Einschränkungen]
</requirements>
<format>
[Wie die Ausgabe strukturiert sein soll]
</format>
<examples>
[Optional: Beispiele für gewünschte Ausgabe]
</examples>
<notes>
[Optional: Zusätzlicher Kontext oder Präferenzen]
</notes>Code-Review-Vorlage
<context>
Du reviewst Code für [Projekt/Kontext].
Die Codebase verwendet [Technologien/Muster].
</context>
<code_to_review>
[Füge Code hier ein]
</code_to_review>
<review_criteria>
Fokussiere auf:
1. Korrektheit: Tut es, was es soll?
2. Lesbarkeit: Ist es für andere Entwickler klar?
3. Performance: Gibt es offensichtliche Ineffizienzen?
4. Sicherheit: Gibt es Schwachstellen?
5. Stil: Entspricht es den Codebase-Konventionen?
</review_criteria>
<output_format>
Für jedes gefundene Problem:
- Schweregrad: [Kritisch/Wichtig/Gering/Vorschlag]
- Stelle: [Zeilennummer oder Abschnitt]
- Problem: [Was ist falsch]
- Fix: [Wie man es behebt]
</output_format>Recherche-Analyse-Vorlage
<research_task>
Analysiere [Thema/Frage] mit folgendem Ansatz:
</research_task>
<methodology>
1. Starte mit mehreren gezielten Suchen. Verlasse dich nicht auf eine
einzelne Anfrage.
2. Grabe tief, bis du genug Informationen für eine präzise und
vollständige Antwort hast.
3. Füge gezielte Nachfolge-Suchen hinzu, um Lücken zu füllen oder
Konflikte zu lösen.
4. Iteriere weiter, bis weitere Suchen die Antwort wahrscheinlich
nicht ändern.
</methodology>
<output_requirements>
- Beginne mit einer klaren Antwort auf die Hauptfrage.
- Unterstütze mit Beweisen und Zitaten.
- Erkenne Einschränkungen und Unsicherheiten an.
- Gib konkrete Beispiele, wenn hilfreich.
- Füge relevanten Kontext hinzu, der hilft, Implikationen zu verstehen.
</output_requirements>
<citation_format>
[Wie Quellen zitiert werden sollen]
</citation_format>Häufige Fehler, die Ergebnisse sabotieren
Lass mich dir die Fehler ersparen, die ich (wiederholt) in meinen frühen Prompt-Engineering-Tagen gemacht habe.
"Schreib mir etwas über Marketing" vs "Schreibe einen 500-Wörter-Blogpost über E-Mail-Marketing für SaaS-Startups, mit Fokus auf Willkommens-Sequenzen." Spezifität ist alles.
"Sei knapp" und "sei detailliert" im selben Prompt. Die KI wird kämpfen, den Widerspruch zu lösen. Sei explizit über Prioritäten und Trade-offs.
Die KI weiß nicht, was du ihr nicht sagst. Wenn etwas für dich offensichtlich ist, ist es vielleicht nicht für das Modell offensichtlich. Füge relevanten Kontext hinzu.
Wenn du JSON brauchst, sag es. Wenn du Aufzählungspunkte brauchst, sag es. Überlasse das Ausgabeformat nicht dem Zufall.
Manchmal ist ein einfacher Prompt besser. Füge keine Komplexität um der Komplexität willen hinzu. Starte einfach, füge Komplexität nur hinzu, wenn nötig.
Prompting ist iterativ. Dein erster Prompt ist ein Entwurf. Verfeinere basierend auf dem, was funktioniert und was nicht.
GPT und Claude verhalten sich unterschiedlich. Ein für eines optimierter Prompt kann bei einem anderen schlechter funktionieren. Teste auf mehreren Modellen, wenn deine Anwendung sie unterstützt.
KI-Output erfordert generell menschliche Überprüfung. Baue Prompts, die Überprüfung erleichtern—klare Struktur, explizite Annahmen, nachvollziehbares Reasoning.
Die Zukunft des Prompt-Engineerings
Während ich dies Anfang 2026 schreibe, entwickelt sich Prompt-Engineering rasant weiter. Modelle werden fähiger, leichter zu steuern und zuverlässiger. Manche sagen voraus, dass Prompt-Engineering obsolet wird, wenn KI Absichten besser versteht. Ich bin anderer Meinung.
Was sich ändert, ist das Niveau des Prompt-Engineerings, nicht seine Notwendigkeit. Frühe Tage erforderten ausgeklügelte Prompts für grundlegende Aufgaben. Jetzt funktionieren grundlegende Aufgaben out-of-the-box, aber komplexe agentische Workflows erfordern immer noch anspruchsvolles Prompting. Die Messlatte steigt, sie verschwindet nicht.
Prompt-Engineering geht nicht weg—es entwickelt sich. Die Fähigkeiten, die wichtig sind, verschieben sich von "wie man KI zum Laufen bringt" zu "wie man KI perfekt und zuverlässig in großem Maßstab zum Laufen bringt."
Was kommt
Bessere Standardeinstellungen
Modelle werden klügere Defaults haben und weniger explizite Anweisungen für gängige Muster erfordern. Prompts werden sich mehr auf Personalisierung als auf grundlegende Fähigkeiten konzentrieren.
Reichere Tool-Ökosysteme
KI wird sofort Zugang zu mehr Tools haben. Prompt-Engineering wird sich in Richtung Orchestrierung verschieben—zu wissen, wann man was verwendet, nicht nur wie.
Multimodale Integration
Prompts werden zunehmend Bilder, Audio, Video und strukturierte Daten neben Text enthalten. Neue Prompt-Muster werden für multimodale Aufgaben entstehen.
Agentische Komplexität
Wenn Agenten längere, komplexere Aufgaben übernehmen, wird Prompt-Engineering mehr wie Systemdesign—Architektur, nicht nur Anweisungen.
Mein Rat für die Zukunft
Konzentriere dich auf die Grundlagen. Die spezifischen Techniken in diesem Leitfaden werden sich weiterentwickeln, aber die zugrunde liegenden Prinzipien—klare Kommunikation, explizite Erwartungen, strukturiertes Denken, iterative Verfeinerung—sind zeitlos. Meistere diese, und du wirst dich an alles anpassen, was als Nächstes kommt.
Abschließende Gedanken
Vor zwei Jahren dachte ich, KI würde die Notwendigkeit klarer Kommunikation ersetzen. Ich lag komplett falsch. KI hat klare Kommunikation wertvoller gemacht als je zuvor. Die Menschen, die mit KI erfolgreich sind, sind nicht diejenigen, die magische Worte gefunden haben—es sind diejenigen, die gelernt haben, mit Präzision zu denken und sich auszudrücken.
Beim Prompt-Engineering geht es nicht wirklich um KI. Es geht um dich. Es geht darum, die Disziplin zu entwickeln, zu artikulieren, was du wirklich willst, die Geduld, darauf hin zu iterieren, und die Demut, aus dem zu lernen, was nicht funktioniert.
Wenn du eine Sache aus diesem Leitfaden mitnimmst, lass es diese sein: Behandle jeden Prompt als Gelegenheit, klares Denken zu üben. Die KI ist nur ein Spiegel, der die Klarheit—oder das Chaos—deines eigenen Geistes reflektiert.
Der Aufstieg der KI hat Wissen nicht obsolet gemacht—er hat Neugier mächtiger als je zuvor gemacht. Wir sind nicht mehr begrenzt durch das, was wir bereits wissen. Mit den richtigen Werkzeugen und dem Willen zu denken können gewöhnliche Menschen einen Ozean des Wissens umfassen. Unabhängig vom Beruf. Unabhängig vom Alter. Ich hoffe, diese Reise mit Freunden aus aller Welt zu teilen. Lasst uns gemeinsam diese neue Welt begrüßen. Lasst uns gemeinsam wachsen.


Diskussion
0 KommentareKommentar hinterlassen
Seien Sie der Erste, der seine Gedanken teilt!