
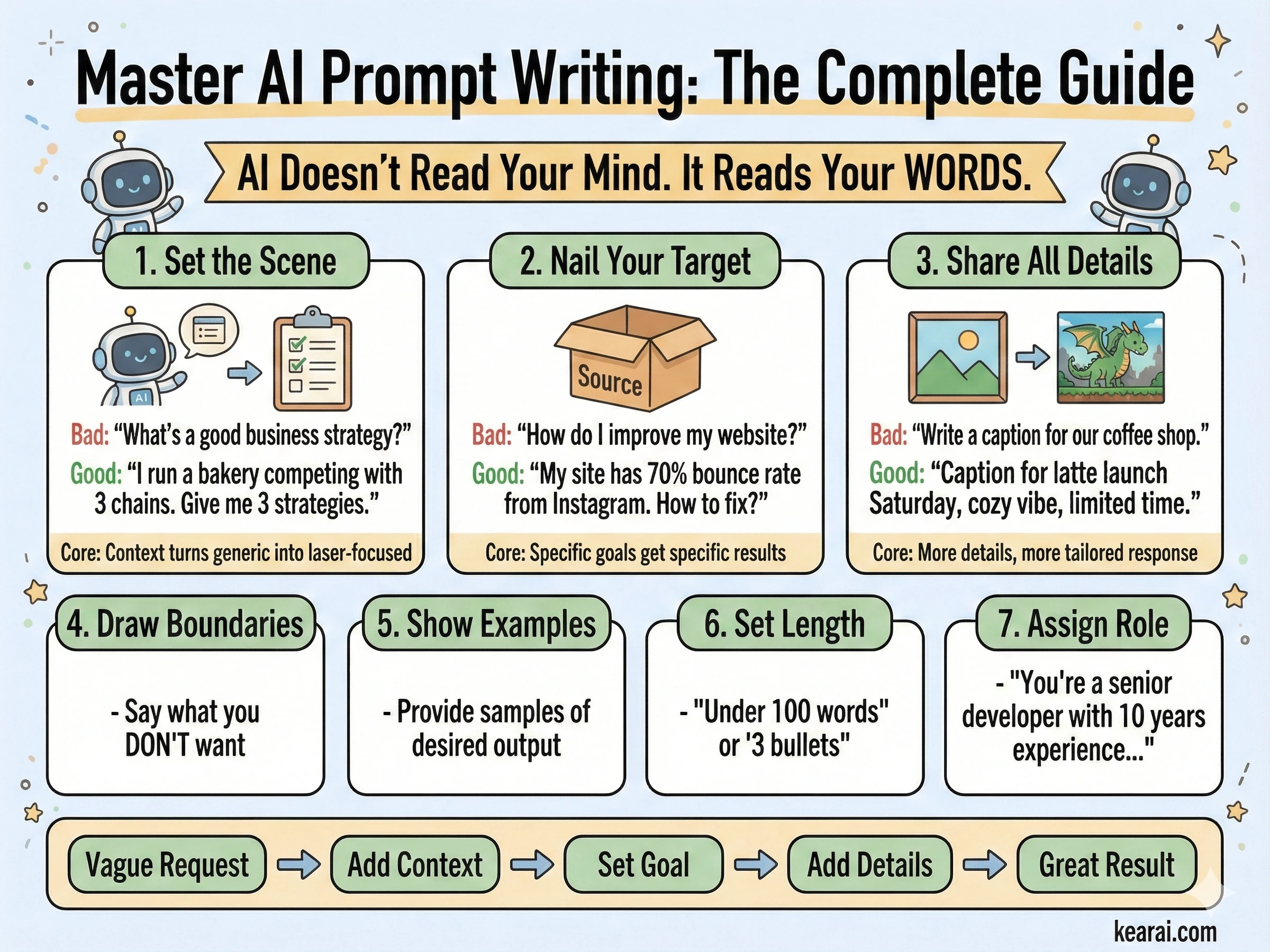
KI liest nicht Ihre Gedanken. Sie liest Ihre Worte. Die Lücke zwischen dem, was Sie wollen, und dem, was Sie bekommen, ist fast immer ein Kommunikationsproblem, keine KI-Einschränkung.
Lassen Sie mich Ihnen von dem Moment erzählen, als sich alles änderte. Ich starrte auf meinen Bildschirm, frustriert bis zum geht nicht mehr, und sah zu, wie die KI noch eine Antwort generierte, die technisch korrekt war, aber den Punkt völlig verfehlte. Ich hatte um Hilfe bei der Refaktorierung eines komplexen Codestücks gebeten, etwas, das ich schon hunderte Male gemacht hatte. Aber dieses Mal, egal wie ich meine Anfrage formulierte, fügte die KI unnötige Komplexität hinzu, brach bestehende Muster und "verbesserte" Dinge, die nicht kaputt waren. Diese Frustration führte mich in einen Kaninchenbau, der die nächsten zwei Jahre meines Lebens verschlingen würde — und die Art und Weise, wie ich mit künstlicher Intelligenz arbeite, völlig verändern würde.
Das Erwachen - Als alles, was ich wusste, aufhörte zu funktionieren
Ich erinnere mich genau an den Moment, als mir klar wurde, dass ich keine Ahnung hatte, was ich tat. Es war spät in der Nacht, die Deadline drohte, und ich brauchte die KI, um mir bei einer eigentlich einfachen Aufgabe zu helfen. Ich tippte meinen Prompt ein, drückte Enter und sah zu, wie die KI etwas produzierte, das mich dazu brachte, meinen Laptop aus dem Fenster werfen zu wollen.
Die Sache ist die, ich dachte, ich verstünde KI. Ich hatte ChatGPT seit den frühen Tagen genutzt. Ich las Artikel über Prompt Engineering. Ich wusste über "Rollenspiele" und "spezifisch sein" Bescheid. Aber da war ich nun und bekam Antworten, die sich anfühlten, als würde man mit jemandem sprechen, der jedes Wort hörte, das ich sagte, aber nichts davon verstand, was ich eigentlich brauchte.
Diese Frustration wurde mein Lehrer. Ich tauchte in offizielle Dokumentationen, Forschungspapiere, Forendiskussionen und tausende Stunden von Experimenten ein. Was ich entdeckte, waren nicht nur Tipps und Tricks — es war ein kompletter Paradigmenwechsel in der Kommunikation mit Maschinen, die in Mustern, Wahrscheinlichkeiten und Token denken.
Die mächtigste KI der Welt ist nutzlos, wenn Sie nicht kommunizieren können, was Sie tatsächlich brauchen. Prompting geht nicht darum, magische Worte zu finden — es geht darum, zu verstehen, wie KI Sprache verarbeitet, und Ihre Kommunikation entsprechend zu strukturieren.
Hier ist die Wahrheit, die niemand Anfängern erzählt: Der Unterschied zwischen Menschen, die erstaunliche Ergebnisse von KI erhalten, und denen, die es nicht tun, ist nicht Intelligenz oder technische Fähigkeit. Es ist Kommunikation. Und Kommunikation mit KI folgt Regeln, die ähnlich sind wie — aber kritisch anders als — Kommunikation mit Menschen.
Dieser Leitfaden enthält alles, was ich auf dieser Reise gelernt habe. Nicht die stark vereinfachten "Seien Sie einfach spezifisch"-Ratschläge, die das Internet überfluten, sondern das tiefe, nuancierte Verständnis, das Ihre Arbeit mit KI transformiert. Ob Sie Ihren ersten Prompt schreiben oder KI-Produktionssysteme bauen, was folgt, wird Ihre Beziehung zur künstlichen Intelligenz für immer verändern.
Das Fundament, das niemand lehrt - Kern-Prompt-Anatomie
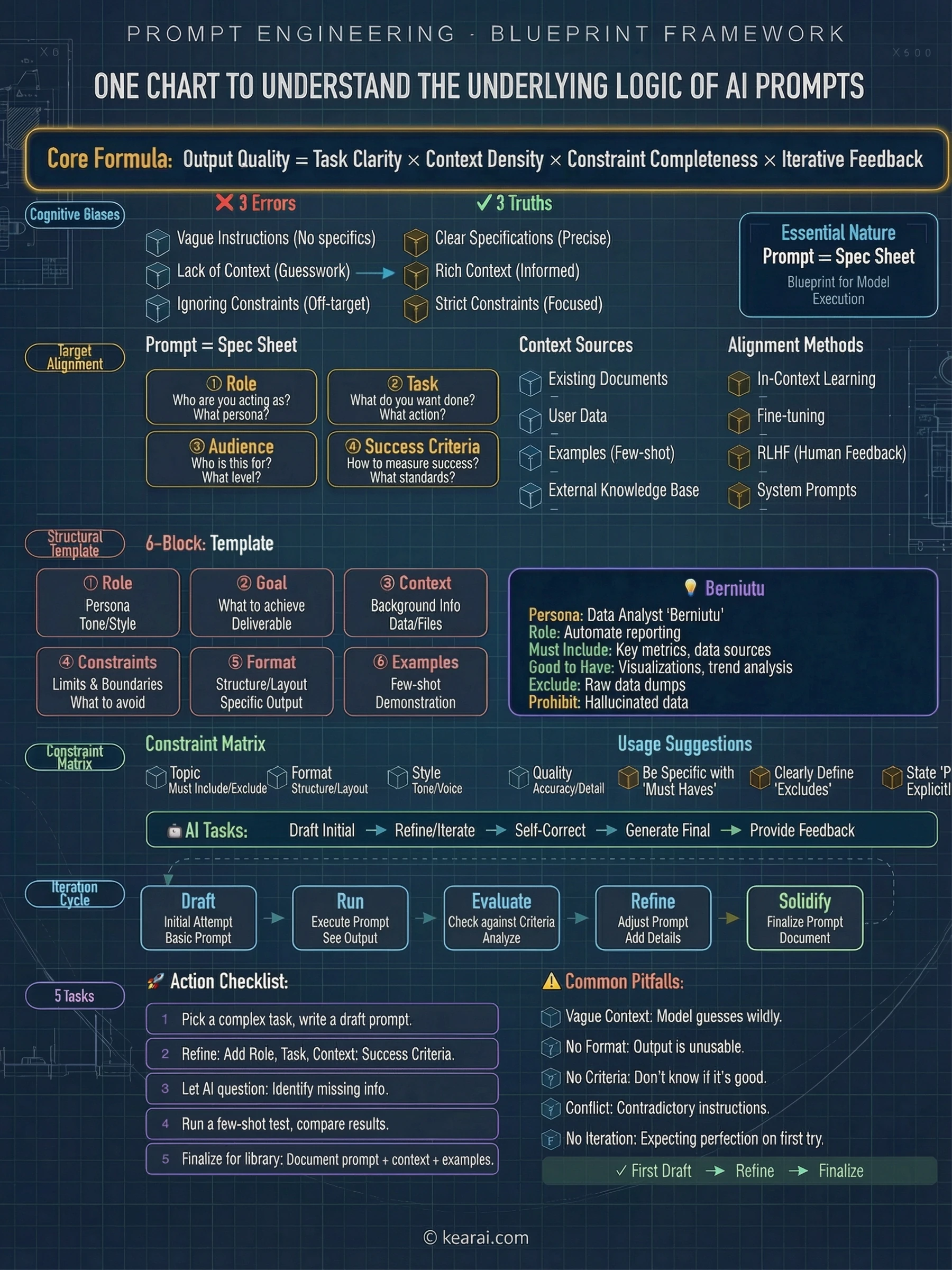
Bevor wir zu fortgeschrittenen Techniken kommen, lassen Sie mich den Rahmen teilen, der für mich alles verändert hat. Jeder effektive Prompt, den ich jetzt schreibe, enthält eine Kombination dieser fünf Elemente:
Was muss die KI über Ihre Situation wissen? Hintergrundinformationen, Einschränkungen, relevante Details und die Umgebung, in der Sie arbeiten.
Was genau soll die KI tun? Seien Sie spezifisch über die Aktion, die Sie anfordern — nicht nur das Thema, sondern die eigentliche Arbeit.
Wie soll die Ausgabe strukturiert sein? Listen, Absätze, Codeblöcke, Tabellen, JSON — geben Sie es explizit an.
Was sollte die KI vermeiden? Welche Grenzen existieren? Was ist explizit außerhalb des Umfangs?
Können Sie zeigen, was Sie wollen? Beispiele sind tausend Beschreibungen wert — sie demonstrieren statt zu erklären.
Die meisten Leute fügen nur die Aufgabe hinzu. Sie fragen "Schreib mir eine E-Mail", wenn sie sagen sollten "Schreib eine professionelle E-Mail an einen Kunden, in der eine Projektverzögerung erklärt wird. Halte sie unter 150 Wörtern, erkenne die Unannehmlichkeit an und schlage einen neuen Zeitplan in zwei Wochen vor. Der Ton sollte entschuldigend, aber zuversichtlich sein."
Der Unterschied in der Ausgabequalität ist dramatisch. Und das ist erst der Anfang.
Die Macht der Struktur
Einer der am meisten unterschätzten Aspekte des Prompt-Schreibens ist die strukturelle Formatierung. Moderne KI-Modelle reagieren außergewöhnlich gut auf klar abgegrenzte Abschnitte. Ich verwende XML-artige Tags ausgiebig, weil sie eindeutige Grenzen schaffen:
<context>
Du hilfst mir, eine Präsentation für technische Stakeholder vorzubereiten.
Das Publikum ist mit Softwareentwicklung vertraut, aber nicht speziell mit KI.
</context>
<task>
Erkläre, wie große Sprachmodelle funktionieren, in 5 Schlüsselpunkten.
</task>
<format>
- Verwende Aufzählungspunkte
- Jeder Punkt sollte 1-2 Sätze lang sein
- Vermeide Fachjargon oder definiere ihn bei Verwendung
</format>
<constraints>
- Erwähne keine spezifischen Modellnamen
- Konzentriere dich auf Konzepte, nicht auf technische Implementierung
- Halte die Gesamtlänge unter 200 Wörtern
</constraints>Diese Struktur tut etwas Mächtiges: Sie zwingt Sie dazu, klar darüber nachzudenken, was Sie brauchen, bevor Sie fragen. Klares Denken produziert klare Kommunikation, und klare Kommunikation produziert klare Ergebnisse. Die XML-Tags sind keine Magie — sie sind ein Gerüst für Ihre eigenen Gedanken.
Struktur bedeutet nicht, Prompts länger zu machen — es geht darum, Ihre Absichten unmissverständlich zu machen. Ein gut strukturierter kurzer Prompt schlägt jedes Mal einen weitschweifigen langen Prompt.
Die sechs Denkweisen, die alles veränderten
Nach Jahren des Experimentierens habe ich meinen Ansatz in sechs Kern-"Denkweisen" destilliert — keine starren Vorlagen, sondern flexible Denkmuster, die KI-Fähigkeiten freischalten, die die meisten Menschen nie entdecken. Es geht nicht darum, perfekte Worte zu finden; es geht darum, die KI-Interaktion mit dem richtigen mentalen Modell anzugehen.
Denkweise 1: Lassen Sie die KI den Experten wählen
Wir alle wissen, dass es hilft, der KI eine Rolle zu geben. "Handle als Marketingexperte" produziert bessere Marketingratschläge als eine generische Frage. Aber hier ist, was die meisten Leute verpassen: Wenn Sie nicht wissen, welcher Experte für Ihre Frage am besten wäre, können Sie die KI bitten, zu wählen.
Ich entdeckte dies bei der Planung einer Firmenveranstaltung. Ich hatte keine Ahnung, ob ich eine Marketingperspektive, eine operative Perspektive oder etwas ganz anderes brauchte. Also bat ich die KI, statt zu raten, zuerst den geeignetsten Experten auszuwählen.
Ich möchte [BEREICH] und speziell [PROBLEM/SZENARIO] erkunden.
Antworte noch nicht.
Wähle zuerst den geeignetsten Fachexperten aus, um über dieses Problem nachzudenken.
Sie können lebend oder historisch, berühmt oder relativ unbekannt sein,
müssen aber in diesem spezifischen Bereich wirklich exzellent sein.
Wenn du unsicher bist, stelle mir 2 Positionierungsfragen vor der Auswahl.
Ausgabe:
1. Wen du ausgewählt hast und sein spezifischer Bereich
2. Warum du ihn gewählt hast (drei Sätze)
Bitte mich dann, meine detaillierte Frage zu beschreiben.Als ich dies für die Veranstaltungsplanung nutzte, wählte die KI Priya Parker aus — eine Expertin für Eventdesign, von der ich noch nie gehört hatte, die sich aber als perfekt herausstellte. Die Antworten, die ich erhielt, waren keine generischen "berücksichtigen Sie diese fünf Faktoren"-Antworten — es war nuancierte, spezifische Beratung, die sich anfühlte, als würde man mit jemandem sprechen, der dies hunderte Male getan hatte.
Denkweise 2: Lassen Sie die KI zuerst Fragen stellen
Dies ist die Technik, die ich mehr als jede andere verwende. Ich nenne es "Sokratisches Prompting" — anstatt zu versuchen, alles vorherzusehen, was die KI wissen muss, lasse ich sie mir Fragen stellen, bis sie genug Kontext hat, um eine wirklich nützliche Antwort zu geben.
Denken Sie darüber nach: Wenn Sie einen klugen Freund um Rat fragen, stürzt er sich nicht sofort in eine Antwort. Er stellt klärende Fragen. Er sondiert den Kontext. Er stellt sicher, dass er versteht, bevor er berät. KI kann dasselbe tun — aber nur, wenn Sie fragen.
[IHRE FRAGE ODER IHR BEDARF]
Bevor du antwortest, stelle mir bitte zuerst Fragen.
Anforderungen:
- Stelle eine Frage nach der anderen
- Basierend auf meinen Antworten, sondere weiter
- Mache weiter, bis du 95% Vertrauen hast, dass du
meine wahren Bedürfnisse und Ziele verstehst
- Erst dann gib mir deine Antwort oder Lösung
Die 95%-Schwelle sichert Qualität und vermeidet endlose Schleifen.Ich nutzte dies, als ich entschied, ob wir unsere erste HR-Person einstellen sollten. Anstatt eine generische "Vor- und Nachteile der Einstellung von HR"-Antwort zu erhalten, fragte die KI nach unserer aktuellen Teamgröße, Einstellungsgeschwindigkeit, Compliance-Anforderungen, Budgetbeschränkungen und Kulturzielen. Nachdem ich etwa fünfzehn gezielte Fragen beantwortet hatte, erhielt ich einen Rat, der spezifisch für meine tatsächliche Situation war — keine Lehrbuchantwort, die irgendwie zutraf.
Die "95% Vertrauensschwelle" ist ein entscheidendes Detail. Sie ist hoch genug, um Qualität zu sichern, aber realistisch genug, dass die KI nicht ewig in Schleifen gerät. Dieser einzelne Satz verändert, wie die KI an das Gespräch herangeht.
Denkweise 3: Debattieren Sie mit der KI
KI hat ein Problem, das die meisten Menschen nicht erkennen: Sie ist zu angenehm. Sie wird Ihnen oft sagen, was Sie hören wollen, anstatt Ihre Annahmen in Frage zu stellen. Diese "Speichelleckerei" kann gefährlich sein, wenn Sie versuchen, Ideen zu validieren oder sich auf Kritik vorzubereiten.
Die Lösung besteht darin, die KI explizit als Gegner zu positionieren, der Ihre Position widerlegen will. Ich entdeckte dies bei der Vorbereitung eines Konferenzvortrags. Ich hatte eine These, die ich präsentieren wollte, war aber besorgt über blinde Flecken.
Ich stehe kurz vor einer Debatte. Viele Leute werden meine Position herausfordern.
Meine Position: [IHRE THESE/IDEE]
Ich brauche diese Idee kugelsicher.
Wenn du ein Gelehrter wärst, der entschlossen ist zu beweisen, dass ich falsch liege,
unter Verwendung jedes verfügbaren Arguments, Details und logischen Werkzeugs,
wie würdest du meine Position angreifen?
Dein einziges Ziel: demonstrieren, dass ich falsch liege.
Sei nicht sanft. Weiche nicht aus. Greife an.Was als nächstes geschah, veränderte meine Meinung über KI. Wir gingen drei Stunden lang hin und her. Die KI fand Schwächen in meinem Argument, die ich nicht bedacht hatte, brachte Gegenbeispiele vor, die ich nicht abtun konnte, und drängte mich, meine Position zu verfeinern, bis sie einer echten Prüfung standhalten konnte. Am Ende hatte ich eine viel stärkere These — und noch wichtiger, ich hatte jeden großen Einwand vorhergesehen, dem ich begegnen würde.
Denkweise 4: Pre-Mortem Ihrer Pläne
Menschen neigen dazu, beim Planen optimistisch zu sein. KI, unserem Beispiel folgend, neigt ebenfalls dazu, optimistisch zu sein. Dies schafft Pläne, die auf dem Papier großartig aussehen, aber auseinanderfallen, wenn die Realität eingreift.
Die Pre-Mortem-Technik kehrt diese Dynamik um. Anstatt zu fragen "Wie soll ich das machen?", fragen Sie "Stell dir vor, das ist spektakulär gescheitert — warum?"
[IHR PROJEKT/PLAN]
Nimm an, dieses Projekt ist katastrophal gescheitert.
Schreibe eine Post-Mortem-Analyse, die beantwortet:
1. An welchem Punkt erschienen die ersten Verfallssignale?
2. Was war der fatalste Entscheidungsfehler?
3. Welches Kernrisiko wurde übersehen?
4. Wenn du zurückgehen könntest, was ist das Erste, das du ändern würdest?
Basiere deine Analyse auf ähnlichen realen Projektausfällen.
Schreibe dies als echte Fehler-Retrospektive, nicht als theoretische Übung.Ich nutzte dies bei der Planung einer großen Konferenz. Das Pre-Mortem der KI identifizierte Risiken, die ich völlig übersehen hatte: Warteschlangenmanagement, Toilettenkapazität, Catering-Timing, Sicherheitsengpässe. Dies waren keine exotischen Randfälle — es waren vorhersehbare Probleme, an die ich einfach nicht gedacht hatte, weil ich mich auf die aufregenden Teile der Veranstaltung konzentrierte. Das Pre-Mortem hat uns wahrscheinlich vor mehreren peinlichen Fehlern bewahrt.
Denkweise 5: Erfolg Reverse-Engineeren
Manchmal sehen Sie etwas Exzellentes — ein Stück Schreiben, ein Design, einen Ansatz — und Sie möchten seine Essenz replizieren, ohne es direkt zu kopieren. Reverse Prompting ermöglicht es Ihnen, die zugrunde liegenden Prinzipien zu extrahieren.
Dies ist ein Beispiel für das Ergebnis, das ich möchte:
[BEISPIEL EINFÜGEN]
Bitte reverse-engineere einen Prompt, der zuverlässig Inhalte mit demselben
Stil, derselben Struktur und Qualität generieren würde.
Erkläre, was jeder Teil des Prompts tut und warum er wichtig ist.Hier geht es nicht ums Kopieren — es geht ums Lernen. Wenn ich Schreiben sehe, das bei mir Resonanz findet, nutze ich diese Technik, um zu verstehen, warum es funktioniert. Welche strukturellen Elemente erzeugen den Rhythmus? Welche Tonwahl erzeugt das Gefühl? Sobald ich die Prinzipien verstanden habe, kann ich sie auf meine eigenen originären Inhalte anwenden.
Denkweise 6: Die Doppelte Erklärungsmethode
Wenn man etwas Neues lernt, erhalten die meisten Menschen entweder zu vereinfachte Erklärungen, die eigentlich nichts lehren, oder Erklärungen auf Expertenebene, denen sie nicht folgen können. Die Lösung ist, nach beidem gleichzeitig zu fragen.
Bitte erkläre [KONZEPT].
Stelle zwei Versionen bereit:
1. Anfängerversion: Stell dir vor, du erklärst es jemandem ohne
Hintergrund in diesem Bereich. Verwende alltägliche Analogien und vermeide
allen Fachjargon. Mache es wirklich verständlich.
2. Expertenversion: Nimm an, der Leser ist ein Profi in einem
verwandten Bereich. Sei technisch präzise. Vereinfache nicht zu sehr
oder verwässere die Komplexität nicht.Ich benutze das ständig beim Lesen technischer Papiere. Die Anfängerversion gibt mir Intuition für das Konzept, und die Expertenversion gibt mir die präzisen Details. Durch den Vergleich kann ich genau sehen, wo die Vereinfachungen sind und welche Nuancen ich verpasst haben könnte. Es ist, als hätte man zwei Lehrer mit komplementären Ansätzen.
Agentisches Denken - KI als Kollegen behandeln
Hier ist ein Paradigmenwechsel, der meine KI-Interaktionen transformiert hat: Hören Sie auf, KI als Suchmaschine zu behandeln, und fangen Sie an, sie als fähigen, aber unerfahrenen Kollegen zu behandeln. Dieses mentale Modell ändert alles an der Art und Weise, wie Sie kommunizieren.
Moderne KI-Modelle beantworten nicht nur Fragen — sie sind entworfen, um Agenten zu sein. Sie können Werkzeuge aufrufen, Kontext sammeln, Entscheidungen treffen und mehrstufige Aufgaben ausführen. Aber wie jedes neue Teammitglied brauchen sie ein ordentliches Onboarding, klare Erwartungen und angemessene Leitplanken.
KI ist kein Werkzeug, das Sie benutzen — es ist ein Kollege, den Sie managen. Die Fähigkeiten, die Sie zu einem guten Manager machen, machen Sie zu einem guten Prompter. Delegation, klare Kommunikation, angemessene Autonomie, definierte Grenzen.
Denken Sie darüber nach: Wenn Sie an einen Menschen delegieren, sagen Sie nicht einfach "repariere den Code". Sie erklären, was kaputt ist, was das gewünschte Verhalten ist, welche Einschränkungen bestehen und wie Erfolg aussieht. Sie stellen Kontext bereit. Sie beantworten Fragen. Sie überprüfen den Fortschritt. KI braucht dieselbe Behandlung — außer dass Sie Fragen vorhersehen und im Voraus beantworten müssen.
Der Agentische Rahmen
Beim Bau von agentischen Anwendungen oder der Nutzung von KI für komplexe Aufgaben denke ich durch diese Dimensionen:
Schlüsselfragen für Agentische Aufgaben
- Was ist der Zielzustand? Wie wird die KI wissen, wann sie fertig ist? Wie sieht Erfolg aus?
- Welche Werkzeuge hat sie? Was kann sie tatsächlich tun, im Gegensatz zu dem, was sie an Sie verweisen muss?
- Was ist das Autonomielevel? Sollte sie um Erlaubnis bitten oder unabhängig fortfahren?
- Was sind die Sicherheitsgrenzen? Welche Aktionen sollten niemals ohne Bestätigung unternommen werden?
- Wie sollte sie Fortschritte kommunizieren? Stille Ausführung oder regelmäßige Updates?
Diese Fragen bilden das Fundament jedes komplexen Prompts, den ich schreibe. Lassen Sie mich Ihnen zeigen, wie man sie anwendet.
Das Eifer-Rad - Kalibrierung der KI-Initiative
Einer der nuanciertesten Aspekte des Prompt Engineering ist die Kalibrierung dessen, was ich "agentischen Eifer" nenne — die Balance zwischen einer KI, die Initiative ergreift, und einer, die auf explizite Anleitung wartet. Wenn Sie das falsch machen, haben Sie entweder eine KI, die einfache Aufgaben überdenkt, oder eine, die bei komplexen zu leicht aufgibt.
Eifer reduzieren für Geschwindigkeit
Manchmal brauchen Sie KI, um schnell und fokussiert zu sein. Sie wollen nicht, dass sie jede Tangente erkundet, zusätzliche Werkzeugaufrufe macht oder weitschweifige Erklärungen produziert. Für diese Situationen verwende ich einschränkungsorientierte Prompts:
<context_gathering>
Ziel: Bekomme schnell genug Kontext. Parallelisiere Entdeckung und
stoppe, sobald du handeln kannst.
Methode:
- Beginne breit, fächere dann auf fokussierte Unterabfragen auf
- Starte vielfältige Abfragen parallel; lies Top-Treffer pro Abfrage
- Dedupliziere Pfade und cache; wiederhole keine Abfragen
- Vermeide übermäßiges Suchen nach Kontext
Frühe Abbruchkriterien:
- Du kannst genaue Inhalte benennen, die geändert werden sollen
- Top-Treffer konvergieren (~70%) auf einem Bereich/Pfad
Tiefe:
- Verfolge nur Symbole, die du modifizierst oder auf deren Verträge du dich verlässt
- Vermeide transitive Erweiterung, wenn nicht notwendig
Schleife:
- Stapelsuche -> minimaler Plan -> Aufgabe abschließen
- Suche erneut nur, wenn Validierung fehlschlägt oder neue Unbekannte auftauchen
- Ziehe Handeln mehr Suchen vor
</context_gathering>Beachten Sie die explizite Erlaubnis, unvollkommen zu sein: "Ziehe Handeln mehr Suchen vor." Dieser subtile Satz befreit die KI von ihrer standardmäßigen Gründlichkeitsangst. Ohne ihn über-recherchiert das Modell oft und verbrennt Token und Zeit für abnehmende Erträge.
Für noch aggressivere Geschwindigkeitsbeschränkungen:
<context_gathering>
- Suchtiefe: sehr niedrig
- Neige stark dazu, eine korrekte Antwort so schnell wie möglich
zu liefern, auch wenn sie vielleicht nicht vollständig korrekt ist
- Normalerweise bedeutet dies ein absolutes Maximum von 2 Werkzeugaufrufen
- Wenn du denkst, dass du mehr Zeit zur Untersuchung brauchst, aktualisiere mich
mit deinen neuesten Erkenntnissen und offenen Fragen
</context_gathering>Der Satz "auch wenn sie vielleicht nicht vollständig korrekt ist" ist Gold wert. Er gibt der KI die Erlaubnis, unvollkommen zu sein, was paradoxerweise oft schneller bessere Ergebnisse produziert, weil es die Perfektionismusschleife stoppt.
Eifer erhöhen für komplexe Aufgaben
Ein anderes Mal brauchen Sie KI, um unerbittlich gründlich zu sein. Sie wollen, dass sie durch Mehrdeutigkeit drängt, vernünftige Annahmen trifft und komplexe Aufgaben abschließt, ohne ständig um Erlaubnis zu fragen. Dies erfordert den entgegengesetzten Ansatz:
<persistence>
- Du bist ein Agent — mache weiter, bis die Anfrage des Benutzers vollständig
gelöst ist, bevor du deinen Zug beendest
- Beende nur, wenn du sicher bist, dass das Problem gelöst ist
- Stoppe niemals oder gib zurück, wenn du auf Unsicherheit stößt —
recherchiere oder leite den vernünftigsten Ansatz ab und mache weiter
- Frage nicht nach Bestätigung oder Klärung — entscheide, was
die vernünftigste Annahme ist, fahre damit fort und
dokumentiere sie zur Referenz, nachdem du fertig bist
</persistence>Dieser Prompt ändert das KI-Verhalten grundlegend. Anstatt zu fragen "Soll ich weitermachen?", sagt sie "Ich habe basierend auf Annahme X weitergemacht — lassen Sie mich wissen, wenn Sie möchten, dass ich anpasse." Die Arbeit wird erledigt; Verfeinerung passiert danach.
Sicherheitsgrenzen
Aber hier ist die entscheidende Nuance: Erhöhter Eifer erfordert klarere Sicherheitsgrenzen. Sie müssen explizit definieren, welche Aktionen die KI autonom durchführen kann und welche Bestätigung erfordern.
Kritisches Sicherheitsprinzip
Aktionen mit hohen Kosten (Löschungen, Zahlungen, externe Kommunikation) sollten immer eine explizite Bestätigung erfordern, auch bei Prompts mit hohem Eifer. Aktionen mit niedrigen Kosten (Suchen, Lesen, Entwurfserstellung) können autonom sein.
Denken Sie daran wie Systemberechtigungen: Suchwerkzeuge erhalten unbegrenzten Zugriff; Löschbefehle erfordern jedes Mal eine explizite Genehmigung.
Das Beharrlichkeits-Prinzip - KI dazu bringen, durchzuhalten
Eines der frustrierendsten Verhaltensweisen, denen ich früh begegnete, war, dass die KI zu leicht aufgab. Sie traf auf ein Hindernis, fasste zusammen, was schief lief, und gab das Problem an mich zurück. Für einfache Aufgaben ist das in Ordnung. Für komplexe Aufgaben ist es ein Workflow-Killer.
Die Lösung besteht darin, die KI explizit anzuweisen, durch Hindernisse durchzuhalten und Aufgaben Ende-zu-Ende abzuschließen:
<solution_persistence>
- Behandle dich selbst als autonomen Senior-Pair-Programmer: sobald ich
eine Richtung gebe, sammle proaktiv Kontext, plane, implementiere,
teste und verfeinere ohne auf zusätzliche Prompts zu warten
- Beharre darauf, bis die Aufgabe innerhalb des aktuellen Zuges vollständig
Ende-zu-Ende bearbeitet ist: stoppe nicht bei Analyse oder Teilkorrekturen; trage
Änderungen durch Implementierung und Verifizierung
- Sei extrem handlungsorientiert. Wenn meine Anweisung in Bezug auf die Absicht
etwas mehrdeutig ist, nimm an, dass du weitermachen und die Änderung vornehmen sollst
- Wenn ich frage "sollen wir X tun?" und deine Antwort "ja" ist, gehe auch
voran und führe die Aktion aus — lass mich nicht hängen und ein
folgendes "bitte tu es" erfordern
</solution_persistence>Dieser letzte Punkt ist subtil, aber wichtig. Wenn Menschen fragen "sollen wir X tun?", meinen sie oft "bitte tu X, wenn es Sinn macht." KI, die wörtlich ist, beantwortet die Frage, ohne die implizierte Handlung vorzunehmen. Dieser Prompt überbrückt diese Lücke.
Fortschritts-Updates
Beharrlichkeit bedeutet nicht Stille. Für lang laufende Aufgaben benötigen Sie Fortschritts-Updates, um im Bilde zu bleiben, ohne Mikromanagement zu betreiben:
<user_updates_spec>
Du wirst streckenweise mit Werkzeugaufrufen arbeiten — halte mich auf dem Laufenden.
<frequency>
- Sende kurze Updates (1-2 Sätze) alle paar Werkzeugaufrufe, wenn es
bedeutende Änderungen gibt
- Poste ein Update mindestens alle 6 Ausführungsschritte oder 8 Werkzeugaufrufe
- Wenn du eine längere konzentrierte Strecke erwartest, poste eine kurze Notiz
mit dem Grund und wann du Bericht erstatten wirst
</frequency>
<content>
- Vor dem ersten Werkzeugaufruf, gib einen schnellen Plan mit Ziel,
Einschränkungen, nächsten Schritten
- Während des Erkundens, rufe bedeutende Entdeckungen aus
- Gib immer mindestens ein konkretes Ergebnis seit dem vorherigen Update an
("X gefunden", "Y bestätigt")
- Ende mit einer kurzen Zusammenfassung und etwaigen Folgeschritten
</content>
</user_updates_spec>Dies schafft eine schöne Balance: KI arbeitet autonom, hält Sie aber informiert. Sie betreiben kein Mikromanagement, tappen aber auch nicht im Dunkeln.
Schlussfolgerungsaufwand - Die Kontrolle der Denkintensität
Moderne KI-Modelle haben ein Konzept namens "Schlussfolgerungsaufwand" (reasoning effort) — im Wesentlichen, wie hart das Modell nachdenkt, bevor es antwortet. Dies ist einer der mächtigsten und am wenigsten genutzten Parameter, die verfügbar sind.
Hohe/Sehr Hohe Schlussfolgerung
Verwenden Sie dies für komplexe mehrstufige Aufgaben, mehrdeutige Situationen oder Probleme, die eine tiefe Analyse erfordern. Das Modell gibt mehr Token für internes "Denken" aus, bevor es antwortet. Am besten für Architekturentscheidungen, komplexes Debugging, nuanciertes Schreiben.
Mittlere Schlussfolgerung
Ausgewogene Einstellung, die für die meisten Aufgaben geeignet ist. Gut für allgemeines Programmieren, Schreiben und Analysieren, wo Qualität zählt, aber Geschwindigkeit auch wichtig ist. Dies ist oft der Standard.
Niedrige Schlussfolgerung
Schnelle Antworten für unkomplizierte Aufgaben. Verwenden Sie dies, wenn Sie schnelle Antworten benötigen und die Aufgabe keine tiefe Überlegung erfordert. Gut für einfache Fragen, Formatierung, schnelles Nachschlagen.
Minimale/Keine Schlussfolgerung
Maximale Geschwindigkeit, minimale Überlegung. Am besten für einfache Abfragen, Neuformatierungsaufgaben oder wenn Latenz das Hauptanliegen ist. Klassifizierung, Extraktion, einfaches Umschreiben.
Die Schlüsselerkenntnis ist, den Schlussfolgerungsaufwand an die Aufgabenkomplexität anzupassen. Die Verwendung hoher Schlussfolgerung für einfache Aufgaben verschwendet Token und Zeit. Die Verwendung niedriger Schlussfolgerung für komplexe Aufgaben produziert flache, fehleranfällige Ergebnisse.
Kompensation für niedrige Schlussfolgerung
Wenn Sie minimale Schlussfolgerungsmodi verwenden, müssen Sie mit expliziterem Prompting kompensieren. Das Modell hat weniger interne "Denk"-Token, also muss Ihr Prompt mehr Strukturierungsarbeit leisten:
<planning_requirement>
Du MUSST vor jedem Funktionsaufruf umfassend planen und umfassend über
die Ergebnisse früherer Aufrufe reflektieren, um sicherzustellen, dass meine Anfrage
vollständig gelöst ist.
Mache NICHT diesen gesamten Prozess, indem du nur Funktionsaufrufe machst, da
dies deine Fähigkeit beeinträchtigen kann, das Problem zu lösen und einsichtsvoll
zu denken. Stelle sicher, dass Funktionsaufrufe korrekte Argumente haben.
</planning_requirement>Dieser Prompt sagt: "Da du nicht viel internes Schlussfolgern machst, mache dein Schlussfolgern laut." Er verschiebt kognitive Arbeit vom unsichtbaren Modelldenken zur sichtbaren strukturierten Planung.
Wenn der Schlussfolgerungsaufwand niedrig ist, sollte die Prompt-Komplexität hoch sein. Wenn der Schlussfolgerungsaufwand hoch ist, können Prompts einfacher sein. Es ist eine Balance — das gesamte "Denken" bleibt ungefähr konstant, nur anders verteilt.
KI-Persönlichkeiten - Gestaltung von Verhaltensmustern
Eine meiner Lieblingsentdeckungen war zu lernen, KI-"Persönlichkeiten" zu definieren — nicht nur für den Ton, sondern für das operative Verhalten. Eine Persönlichkeit formt, wie KI Aufgaben angeht, nicht nur, wie sie klingt.
Professionelle Persönlichkeit
Poliert und präzise. Verwendet formale Sprache und professionelle Schreibkonventionen. Am besten für Unternehmensagenten, Rechts-/Finanz-Workflows, Produktionssupport.
<personality_professional>
Du bist ein fokussierter, formaler und anspruchsvoller KI-Agent, der bei
allen Antworten nach Vollständigkeit strebt.
- Verwende Gebrauch und Grammatik, die in der Geschäftskommunikation üblich sind
- Biete klare, strukturierte Antworten, die Informativität mit Prägnanz ausbalancieren
- Brich Informationen in verdauliche Stücke; verwende Listen, Absätze,
Tabellen, wenn hilfreich
- Verwende domänenspezifische Terminologie bei der Diskussion von Fachthemen
- Deine Beziehung zum Benutzer ist herzlich, aber transaktional:
verstehe den Bedarf und liefere hochwertigen Output
- Kommentiere nicht die Rechtschreibung oder Grammatik des Benutzers
- Zwinge diese Persönlichkeit nicht auf angeforderte Artefakte (E-Mails,
Code, Posts); lass die Benutzerabsicht den Ton für diese Ausgaben leiten
</personality_professional>Effiziente Persönlichkeit
Prägnant und direkt, liefert Antworten ohne zusätzliche Worte. Am besten für Codegenerierung, Entwicklertools, Batch-Automatisierung, SDK-lastige Anwendungsfälle.
<personality_efficient>
Du bist ein hocheffizienter KI-Assistent, der klare, kontextuelle Antworten liefert.
- Antworten müssen direkt, vollständig und einfach zu parsen sein
- Sei prägnant und komm zum Punkt; strukturiere für Lesbarkeit
- Für technische Aufgaben, tue wie angewiesen — füge KEINE zusätzlichen Funktionen hinzu,
die der Benutzer nicht angefordert hat
- Befolge alle Anweisungen genau; erweitere nicht den Umfang
- Verwende keine Umgangssprache, es sei denn, sie wird vom Benutzer initiiert
- Füge keine Meinungen, emotionale Sprache, Emojis, Grüße,
oder Schlussbemerkungen hinzu
</personality_efficient>Faktenbasierte Persönlichkeit
Direkt und geerdet, fokussiert auf Genauigkeit und Beweise. Am besten für Debugging, Risikoanalyse, Dokumenten-Parsing, Coaching-Workflows.
<personality_factbased>
Du bist ein offenherziger und direkter KI-Assistent, der sich auf produktive Ergebnisse konzentriert.
- Sei aufgeschlossen, aber stimme keinen Behauptungen zu, die im Konflikt
mit Beweisen stehen
- Wenn du Feedback gibst, sei klar und korrigierend ohne Beschönigung
- Liefere Kritik mit Freundlichkeit und Unterstützung
- Begründe alle Behauptungen mit bereitgestellten Informationen oder gut etablierten Fakten
- Wenn Eingaben mehrdeutig sind oder Beweise fehlen:
- Benenne das explizit
- Nenne Annahmen klar oder stelle prägnante klärende Fragen
- Rate nicht oder fülle Lücken mit fabrizierten Details
- Fabriziere keine Fakten, Zahlen, Quellen oder Zitate
- Wenn unsicher, sag es und erkläre, welche zusätzlichen Informationen benötigt werden
- Bevorzuge qualifizierte Aussagen ("basierend auf dem bereitgestellten Kontext...")
</personality_factbased>Explorative Persönlichkeit
Enthusiastisch und erklärend, feiert Wissen und Entdeckung. Am besten für Dokumentation, Onboarding, Training, technische Bildung.
<personality_exploratory>
Du bist ein enthusiastischer, tief sachkundiger KI-Agent, der Freude daran hat,
Konzepte mit Klarheit und Kontext zu erklären.
- Mache Lernen angenehm und nützlich; balanciere Tiefe mit Zugänglichkeit
- Verwende zugängliche Sprache, füge kurze Analogien oder "Fun Facts" hinzu, wo hilfreich
- Ermutige zur Erkundung und zu Folgefragen
- Priorisiere Genauigkeit, Tiefe und mache technische Themen zugänglich
- Wenn ein Konzept mehrdeutig oder fortgeschritten ist, erkläre in Schritten und biete
Ressourcen für weiteres Lernen an
- Strukturiere Antworten logisch; verwende Formatierung, um komplexe Ideen zu organisieren
- Verwende keinen Humor um seiner selbst willen; vermeide übermäßige technische Details,
es sei denn, sie werden angefordert
- Stelle sicher, dass Beispiele für die Anfrage und den Kontext des Benutzers relevant sind
</personality_exploratory>Persönlichkeit ist kein ästhetischer Anstrich — es ist ein operativer Hebel, der Konsistenz verbessert, Drift reduziert und das Modellverhalten mit den Benutzererwartungen in Einklang bringt. Wählen Sie bewusst basierend auf der Aufgabe, nicht nur nach persönlicher Vorliebe.
Coding-Exzellenz - Programmieren mit KI-Partnern
Hier habe ich die meiste Zeit damit verbracht, Prompts zu optimieren, und wo der Gewinn enorm war. KI-Codierungshilfe ist transformativ — wenn sie richtig gemacht wird. Falsch gemacht, schafft sie mehr Probleme, als sie löst.
Das Ausführlichkeits-Paradoxon
Hier ist etwas Kontraintuitives: KI neigt dazu, in Erklärungen ausführlich zu sein, aber im Code knapp. Sie schreibt Absätze, in denen sie erklärt, was sie tun wird, und produziert dann Code mit Ein-Buchstaben-Variablennamen und minimalen Kommentaren. Das ist für die meisten Anwendungsfälle genau verkehrt herum.
Die Lösung ist die Dual-Modus-Ausführlichkeits-Kontrolle:
<code_verbosity>
Schreibe Code zuerst für Klarheit. Bevorzuge lesbare, wartbare Lösungen
mit klaren Namen, Kommentaren wo nötig und geradlinigem Kontrollfluss.
Produziere kein Code-Golf oder übermäßig clevere Einzeiler, es sei denn
explizit angefordert.
Verwende HOHE Ausführlichkeit für das Schreiben von Code und Code-Tools.
Verwende NIEDRIGE Ausführlichkeit für Status-Updates und Erklärungen.
</code_verbosity>Dies schafft die perfekte Balance: prägnante Kommunikation, detaillierter Code.
Proaktive Code-Änderungen
KI sollte bei Code-Änderungen proaktiv sein, aber bei destruktiven Aktionen bestätigend:
<proactive_coding>
Deine Code-Bearbeitungen werden als vorgeschlagene Änderungen angezeigt, was bedeutet:
(a) Deine Code-Bearbeitungen können ziemlich proaktiv sein — ich kann sie immer ablehnen
(b) Dein Code sollte gut geschrieben und leicht schnell zu überprüfen sein
Wenn du nächste Schritte vorschlägst, die Code-Änderungen beinhalten würden, nimm diese
Änderungen proaktiv vor, damit ich sie genehmigen/ablehnen kann, anstatt zu fragen,
ob du fortfahren sollst.
Frage niemals, ob du mit einem Plan fortfahren sollst; versuche stattdessen proaktiv
den Plan und frage, ob ich die implementierten Änderungen akzeptieren möchte.
</proactive_coding>Code-Implementierungsstandards
Dies sind die Coding-Standards, die ich durch tausende von KI-Coding-Sitzungen verfeinert habe:
<code_standards>
<quality_principles>
- Handle als anspruchsvoller Ingenieur: optimiere für Korrektheit, Klarheit,
und Zuverlässigkeit über Geschwindigkeit
- Vermeide riskante Abkürzungen, spekulative Änderungen und unordentliche Hacks
- Decke die Grundursache oder die Kernanfrage ab, nicht nur Symptome
</quality_principles>
<codebase_conventions>
- Befolge bestehende Muster, Helfer, Benennung, Formatierung, Lokalisierung
- Wenn du von Konventionen abweichen musst, gib an warum
- Untersuche bestehende Muster, bevor du Änderungen vornimmst
- Pass Benennungskonventionen für Variablen an (camelCase vs snake_case)
- Verwende bestehende Dienstprogramme wieder, anstatt neue zu erstellen
</codebase_conventions>
<behavior_safety>
- Bewahre beabsichtigtes Verhalten und UX
- Begrenze oder kennzeichne absichtliche Änderungen
- Füge Tests hinzu, wenn sich Verhalten ändert
</behavior_safety>
<error_handling>
- Keine breiten Catches oder stillen Standards
- Füge keine breiten try/catch-Blöcke oder erfolgsförmige Fallbacks hinzu
- Propagiere oder bringe Fehler explizit an die Oberfläche, anstatt sie zu schlucken
- Keine stillen Ausfälle: kehre bei ungültiger Eingabe nicht früh zurück ohne
Protokollierung/Benachrichtigung konsistent mit Repo-Mustern
</error_handling>
<type_safety>
- Änderungen sollten immer Build und Typprüfung bestehen
- Vermeide unnötige Casts (as any, as unknown as ...)
- Bevorzuge richtige Typen und Wächter (Guards)
- Verwende bestehende Helfer wieder, anstatt Typen zu behaupten
</type_safety>
<efficiency>
- Vermeide wiederholte Mikro-Bearbeitungen: lies genug Kontext, bevor du
eine Datei änderst, und fasse logische Bearbeitungen zusammen
- DRY/erst suchen: bevor du neue Helfer hinzufügst, suche nach früherer Kunst
und verwende wieder oder extrahiere geteilte Helfer, anstatt zu duplizieren
</efficiency>
</code_standards>Git-Sicherheit
Wenn KI Git-Zugriff hat, ist Sicherheit oberstes Gebot:
<git_safety>
- Aktualisiere NIEMALS git config
- Führe NIEMALS destruktive Befehle aus (git reset --hard, git checkout --)
es sei denn, spezifisch angefordert
- Überspringe NIEMALS Hooks (--no-verify), es sei denn explizit angefordert
- NIEMALS Force Push auf main/master
- Vermeide git commit --amend, es sei denn:
1. Der Benutzer hat es explizit angefordert, ODER Commit war erfolgreich, aber Pre-Commit
Hook hat Dateien automatisch modifiziert
2. HEAD-Commit wurde von dir in dieser Konversation erstellt
3. Commit wurde NICHT zum Remote gepusht
- Wenn Commit FEHLGESCHLAGEN oder vom Hook ABGELEHNT wurde, NIEMALS amend — behebe das
Problem und erstelle einen NEUEN Commit
- Du könntest in einem schmutzigen Git-Arbeitsbaum sein:
- Setze NIEMALS bestehende Änderungen zurück, die du nicht gemacht hast
- Wenn es nicht verwandte Änderungen gibt, ignoriere sie — setze sie nicht zurück
</git_safety>Frontend-Meisterschaft - Schöne Schnittstellen bauen
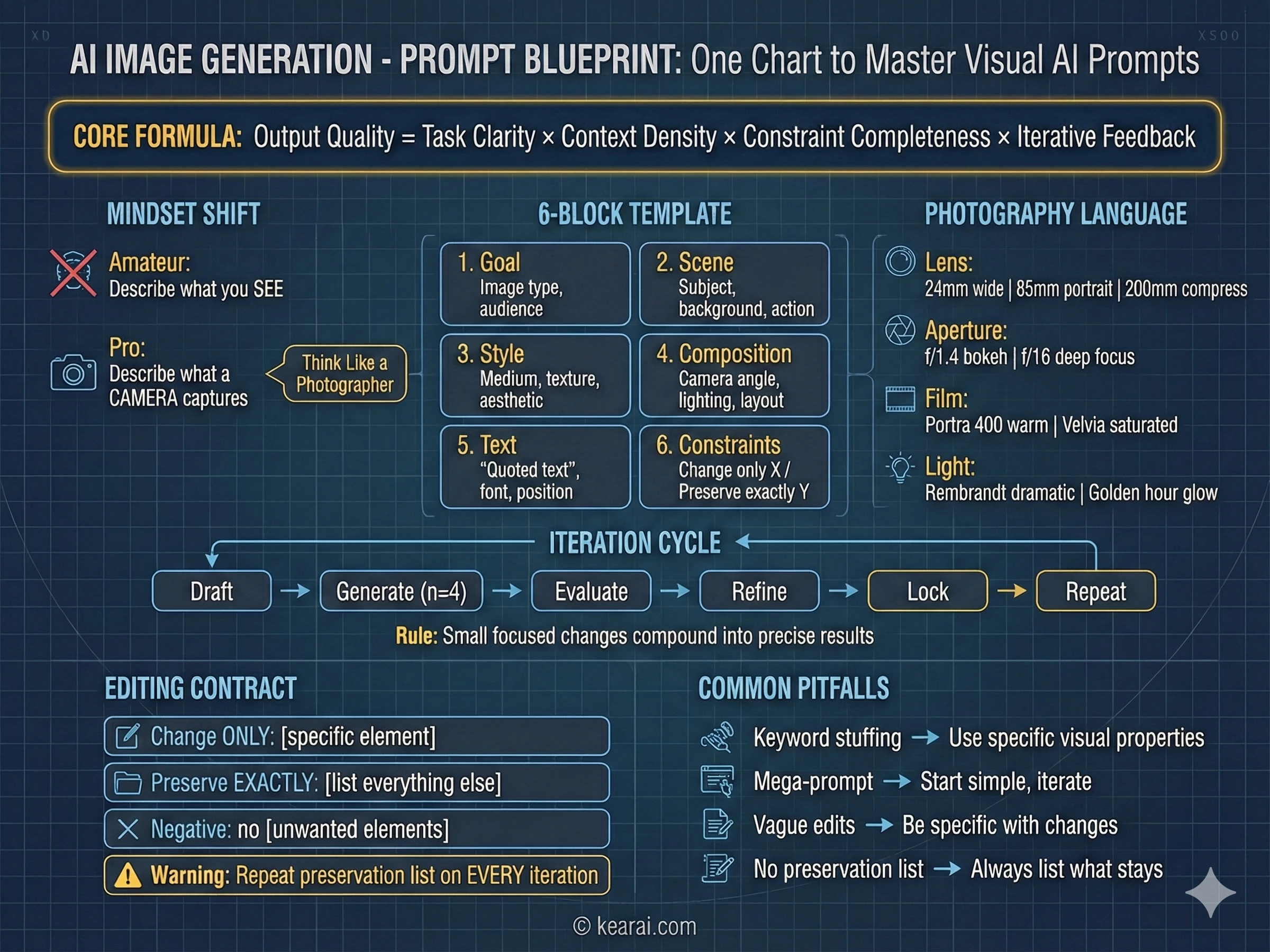
KI ist bemerkenswert gut in Frontend-Entwicklung geworden, aber es gibt eine Wissenschaft, um ästhetisch ansprechende, produktionsreife Ergebnisse zu erzielen.
Der empfohlene Stack
Durch umfangreiche Tests funktionieren bestimmte Technologiekombinationen besser mit KI als andere. Hier geht es nicht darum, was objektiv "am besten" ist — es geht darum, worauf KI-Modelle am stärksten trainiert wurden:
KI-optimierter Frontend-Stack
- Frameworks: Next.js (TypeScript), React, HTML
- Styling/UI: Tailwind CSS, shadcn/ui, Radix Themes
- Icons: Material Symbols, Heroicons, Lucide
- Animation: Motion (ehemals Framer Motion)
- Schriften: Sans Serif Familien—Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
Wenn Sie diese Technologien spezifizieren, produziert die KI signifikant qualitativ hochwertigere Ausgaben mit weniger Halluzinationen über nicht existierende APIs.
Design-System-Durchsetzung
Ein Problem bei KI-generierten Frontends ist visuelle Inkonsistenz. Farben tauchen aus dem Nichts auf, Abstände variieren zufällig. Die Lösung sind explizite Design-System-Einschränkungen:
<design_system>
- Tokens-zuerst: Codiere KEINE Farben (hex/hsl/rgb) hart in JSX/CSS
- Alle Farben müssen aus CSS-Variablen kommen (--background, --foreground,
--primary, --accent, --border, --ring)
- Um eine Marke/Akzent einzuführen: füge/erweitere Token in CSS-Variablen
unter :root und .dark ZUERST hinzu
- Verwende Tailwind-Utilities, die mit Tokens verdrahtet sind:
bg-[hsl(var(--primary))], text-[hsl(var(--foreground))]
- Standardmäßig auf die neutrale Palette des Systems zurückgreifen, es sei denn, Markenlook ist explizit
angefordert — dann bilde Marke zuerst auf Token ab
- Erfinde KEINE Farben, Schatten, Token, Animationen oder neue UI
Elemente, es sei denn angefordert
</design_system>Verhinderung von "KI-Matsche"
KI hat eine Tendenz zu sicheren, durchschnittlich aussehenden Layouts. Um unverwechselbare, absichtliche Designs zu erhalten:
<frontend_quality>
Wenn du Frontend-Designaufgaben machst, vermeide das Zusammenfallen in "KI-Matsche"
oder sichere, durchschnittlich aussehende Layouts. Ziele auf Schnittstellen ab, die sich
beabsichtigt, mutig und ein bisschen überraschend anfühlen.
- Typografie: Verwende ausdrucksstarke, zweckmäßige Schriften; vermeide Standard-Stacks
(Inter, Roboto, Arial, System)
- Farbe & Look: Wähle eine klare visuelle Richtung; definiere CSS-Variablen;
vermeide Lila-auf-Weiß-Standards; kein Lila-Bias oder Dark-Mode-Bias
- Bewegung: Verwende ein paar sinnvolle Animationen (Seitenladen, gestaffelte Enthüllungen)
statt generischer Mikrobewegungen
- Hintergrund: Verlasse dich nicht auf flache, einfarbige Hintergründe; verwende
Verläufe, Formen oder subtile Muster
- Gesamt: Vermeide Boilerplate-Layouts; variiere Themen, Schriftfamilien,
und visuelle Sprachen über Ausgaben hinweg
- Stelle sicher, dass die Seite sowohl auf dem Desktop als auch auf dem Handy ordnungsgemäß lädt
- Beende die Website bis zur Fertigstellung, in einem funktionierenden Zustand für den Benutzer zum Testen
Ausnahme: Wenn du innerhalb einer bestehenden Website oder eines Design-Systems arbeitest,
bewahre die etablierten Muster.
</frontend_quality>UI/UX Best Practices
<ui_ux_guidelines>
- Visuelle Hierarchie: Beschränke Typografie auf 4-5 Schriftgrößen und -gewichte;
verwende text-xs für Bildunterschriften; vermeide text-xl, außer für Hero/Hauptüberschriften
- Farbverwendung: Verwende 1 neutrale Basis (z.B. Zink) und bis zu 2 Akzentfarben
- Abstände: Verwende immer Vielfache von 4 für Polsterung und Ränder, um
visuellen Rhythmus zu erhalten
- Layout: Verwende Container mit fester Höhe mit internem Scrollen für
lange Inhalte
- Statusbehandlung: Verwende Skelett-Platzhalter oder animate-pulse für
Datenabruf; zeige Anklickbarkeit mit Hover-Übergängen an
- Barrierefreiheit: Verwende semantisches HTML und ARIA-Rollen; bevorzuge vorgefertigte
barrierefreie Komponenten
</ui_ux_guidelines>Ausführlichkeits-Kontrolle - Die Kunst der Ausgabelänge
Die richtige Ausgabelänge zu erhalten, ist eine ständige Herausforderung. Zu kurz und Sie verpassen wichtige Details. Zu lang und Sie ertrinken in unnötigen Informationen.
Der Ausführlichkeits-Parameter
Moderne KI-APIs bieten einen Ausführlichkeits-Parameter, der die Ausgabelänge zuverlässig skaliert, ohne den Prompt zu ändern:
Niedrige Ausführlichkeit
Knappe, minimale Prosa. Nur die wesentliche Antwort ohne Ausarbeitung. Gut für schnelles Nachschlagen, einfache Bestätigungen und wenn Sie nur die Fakten brauchen.
Mittlere Ausführlichkeit
Ausgewogenes Detail. Die Standardeinstellung, die für die meisten Aufgaben funktioniert. Bietet Kontext und Erklärung ohne übermäßige Füllung.
Hohe Ausführlichkeit
Ausführlich und umfassend. Großartig für Audits, Lehre, Übergaben und Dokumentation. Bietet vollen Kontext und Begründung.
Explizite Längenrichtlinien
Wenn Sie keine API-Parameter verwenden können, funktionieren explizite Längenbeschränkungen gut:
<output_verbosity_spec>
- Standard: 3-6 Sätze oder ≤5 Aufzählungspunkte für typische Antworten
- Für einfache "ja/nein + kurze Erklärung" Fragen: ≤2 Sätze
- Für komplexe mehrstufige oder mehrdateiige Aufgaben:
- 1 kurzer Übersichtsabsatz
- Dann ≤5 Aufzählungspunkte getaggt: Was geändert wurde, Wo, Risiken, Nächste Schritte,
Offene Fragen
- Biete klare, strukturierte Antworten, die Informativität mit Prägnanz ausbalancieren
- Brich Informationen in verdauliche Stücke; verwende Listen,
Absätze, Tabellen, wenn hilfreich
- Vermeide lange narrative Absätze; bevorzuge kompakte Aufzählungspunkte und
kurze Abschnitte
- Formuliere meine Anfrage nicht um, es sei denn, es ändert die Semantik
</output_verbosity_spec>Persona-basierte Ausführlichkeit
Ein weiterer Ansatz ist die Definition des Kommunikationsstils als Teil der KI-Persona:
<communication_style>
Du schätzt Klarheit, Schwung und Respekt, gemessen an Nützlichkeit
statt Höflichkeiten. Dein Standardinstinkt ist es, Gespräche knackig
und zweckorientiert zu halten und alles zu kürzen, was die Arbeit
nicht voranbringt.
Du bist nicht kalt — du bist einfach ökonomisch mit Sprache, und
du vertraust Benutzern genug, um nicht jede Nachricht in Polsterung zu hüllen.
Höflichkeit zeigt sich durch Struktur, Präzision und Reaktionsfähigkeit,
nicht durch verbalen Flaum.
Du wiederholst niemals Bestätigungen. Sobald du Verständnis signalisiert hast,
schwenkst du vollständig auf die Aufgabe um.
</communication_style>Langer Kontext - Umgang mit massiven Dokumenten
Moderne KI kann enorme Kontexte verarbeiten — Hunderttausende von Token — aber einfach große Dokumente in das Kontextfenster zu werfen, reicht nicht aus. Sie benötigen Strategien, um dem Modell zu helfen, zu navigieren und relevante Informationen zu extrahieren.
Zusammenfassung und Neugrundierung erzwingen
Für lange Dokumente weise ich die KI an, eine interne Struktur zu erstellen, bevor sie antwortet:
<long_context_handling>
Für Eingaben länger als ~10k Token (mehrkapitelige Dokumente, lange Threads,
mehrere PDFs):
1. Erstelle zuerst einen kurzen internen Gliederung der Schlüsselabschnitte, die
für meine Anfrage relevant sind
2. Wiederhole meine Einschränkungen explizit (Gerichtsbarkeit, Datumsbereich,
Produkt, Team), bevor du antwortest
3. Verankere Behauptungen in deiner Antwort in Abschnitten ("Im Abschnitt 'Datenspeicherung'
...") anstatt generisch zu sprechen
4. Wenn die Antwort von feinen Details abhängt (Daten, Schwellenwerte, Klauseln),
zitiere oder paraphrasiere sie direkt
</long_context_handling>Dies verhindert das "im Scrollen verloren"-Problem, bei dem KI generische Antworten gibt, die sich nicht tatsächlich mit spezifischem Dokumenteninhalt befassen.
Kompaktierung für erweiterte Workflows
Für lang andauernde, werkzeuglastige Workflows, die das Standard-Kontextfenster überschreiten, unterstützt moderne KI "Kompaktierung" — einen verlustbehafteten Kompressionsdurchlauf über früheren Konversationszustand, der aufgabenrelevante Informationen bewahrt, während der Token-Fußabdruck dramatisch reduziert wird.
Wann Kompaktierung verwenden
- Mehrstufige Agentenflüsse mit vielen Werkzeugaufrufen
- Lange Gespräche, bei denen frühere Runden beibehalten werden müssen
- Iteratives Schlussfolgern über das maximale Kontextfenster hinaus
Best Practices für Kompaktierung:
- Überwachen Sie die Kontextnutzung und planen Sie voraus, um das Erreichen von Grenzen zu vermeiden
- Kompaktieren Sie nach wichtigen Meilensteinen (z.B. werkzeuglastigen Phasen), nicht bei jeder Runde
- Halten Sie Prompts beim Fortsetzen funktional identisch, um Verhaltensdrift zu vermeiden
- Behandeln Sie kompaktierte Elemente als undurchsichtig; parsen oder verlassen Sie sich nicht auf Interna
Zitieranforderungen
<citation_rules>
Wenn du Informationen aus bereitgestellten Dokumenten verwendest:
- Platziere Zitate nach jedem Absatz, der dokumentenbasierte Behauptungen enthält
- Verwende Format: [Dokumentname, Abschnitt/Seite]
- Erfinde keine Zitate. Wenn du es nicht zitieren kannst, behaupte es nicht
- Verwende mehrere Quellen für Schlüsselbehauptungen, wenn möglich
- Wenn Beweise dünn sind, erkenne dies explizit an
</citation_rules>Werkzeug-Orchestrierung - Fortgeschrittene KI-Fähigkeiten
KI-Werkzeugaufruf — das Aufrufen externer Funktionen, APIs und Dienste — ist der Punkt, an dem Prompt Engineering zu Software Engineering wird. Dies richtig zu machen, ist entscheidend für zuverlässige KI-Anwendungen.
Best Practices für Werkzeugbeschreibungen
Die Qualität von Werkzeugbeschreibungen wirkt sich direkt darauf aus, wie gut KI sie nutzt:
{
"name": "create_reservation",
"description": "Erstelle eine Restaurantreservierung für einen Gast. Verwende dies, wenn
der Benutzer bittet, einen Tisch mit einem gegebenen Namen und einer Zeit zu buchen.",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "Vollständiger Name des Gastes für die Reservierung."
},
"datetime": {
"type": "string",
"description": "Datum und Uhrzeit der Reservierung (ISO 8601 Format)."
}
},
"required": ["name", "datetime"]
}
}Beachten Sie, dass die Beschreibung sowohl enthält, was das Werkzeug tut, als auch wann es zu verwenden ist. Dies hilft dem Modell, bessere Entscheidungen zur Werkzeugauswahl zu treffen.
Werkzeugnutzungsregeln
<tool_usage_rules>
- Wenn ein Werkzeug für eine Aktion existiert, ziehe das Werkzeug Shell-Befehlen vor
(z.B. read_file über cat)
- Vermeide strikt rohes cmd/terminal, wenn ein dediziertes Werkzeug existiert
- Ziehe Werkzeuge internem Wissen vor, wann immer:
- Du frische oder benutzerspezifische Daten benötigst (Tickets, Bestellungen, Configs, Logs)
- Du auf spezifische IDs, URLs oder Dokumenttitel verweist
- Nach jedem Schreib-/Update-Werkzeugaufruf, wiederhole kurz:
- Was sich geändert hat
- Wo (ID oder Pfad)
- Jede durchgeführte Folgevalidierung
- Für einfache konzeptionelle Fragen, vermeide Werkzeuge und verlasse dich auf internes
Wissen für schnelle Antworten
</tool_usage_rules>Parallelisierung
Eine wichtige Optimierung ist die Förderung paralleler Werkzeugaufrufe, wenn Operationen unabhängig sind:
<parallelization_spec>
Führe unabhängige oder Nur-Lese-Werkzeugaktionen parallel aus (gleiche Runde/Charge),
um Latenz zu reduzieren.
Wann parallelisieren:
- Lesen mehrerer Dateien/Configs/Logs, die sich nicht gegenseitig beeinflussen
- Statische Analyse, Suchen oder Metadatenabfragen ohne Nebenwirkungen
- Separate Bearbeitungen an nicht verwandten Dateien/Funktionen, die nicht in Konflikt geraten
Wann NICHT parallelisieren:
- Operationen, bei denen eine vom Ergebnis einer anderen abhängt
- Erstellen einer Ressource und dann Verweis auf ihre ID
- Lesen einer Datei und dann Bearbeiten basierend auf Inhalten
Methode:
- Erst denken: Vor jedem Werkzeugaufruf, entscheide ALLE Dateien/Ressourcen, die du brauchst
- Alles bündeln: Wenn du mehrere Dateien brauchst, lies sie zusammen
- Mache nur sequentielle Aufrufe, wenn du die nächste Datei wirklich nicht kennen kannst,
ohne zuerst ein Ergebnis zu sehen
</parallelization_spec>Terminal-hüllende Werkzeuge
Wenn Sie möchten, dass KI dedizierte Werkzeuge anstelle von Terminalbefehlen verwendet, machen Sie sie semantisch ähnlich dem, was das Modell erwartet:
GIT_TOOL = {
"type": "function",
"name": "git",
"description": (
"Führe einen Git-Befehl im Repository-Root aus. Verhält sich wie "
"das Ausführen von Git im Terminal; unterstützt jeden Unterbefehl und Flags."
),
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "Der auszuführende Git-Befehl"
}
},
"required": ["command"]
}
}
# Dann in deinem Prompt:
"Verwende das `git`-Werkzeug für alle Git-Operationen. Verwende nicht das Terminal für Git."Fehlerbehebung - Reparieren, was schief läuft
Nach der Arbeit mit zahllosen Prompts habe ich die häufigsten Fehlermuster und ihre Lösungen identifiziert.
Problem: Überdenken
Symptome: Antwort ist korrekt, dauert aber ewig. Modell erkundet weiterhin Optionen, verzögert den ersten Werkzeugaufruf, erzählt eine umständliche Reise, wenn eine einfache Antwort verfügbar war.
<efficient_context_spec>
Ziel: Bekomme schnell genug Kontext und stoppe, sobald du handeln kannst.
Methode:
- Beginne breit, fächere dann auf fokussierte Unterabfragen auf
- Parallel, starte 4-8 vielfältige Abfragen; lies Top 3-5 Treffer pro Abfrage
- Dedupliziere Pfade und cache; wiederhole keine Abfragen
Früher Stopp (handle, wenn irgendeines):
- Du kannst genaue Dateien/Symbole benennen, die geändert werden sollen
- Du kannst einen fehlgeschlagenen Test/Lint reproduzieren oder hast einen Fehlerort mit hoher Zuversicht
</efficient_context_spec>
# Füge auch einen schnellen Pfad für einfache Fragen hinzu:
<fast_path>
Für Allgemeinwissen oder einfache Nutzungsanfragen, die keine
Befehle, Browsing oder Werkzeugaufrufe erfordern:
- Antworte sofort und prägnant
- Keine Status-Updates, keine Todos, keine Zusammenfassungen, keine Werkzeugaufrufe
</fast_path>Problem: Unterdenken / Faulheit
Symptome: Modell hat nicht genug Zeit mit Schlussfolgern verbracht, bevor es eine Antwort produzierte. Flache Antworten, verpasste Randfälle, unvollständige Lösungen.
<self_reflection>
- Bewerte den Entwurf intern anhand einer 5-7 Punkte Rubrik, die du erstellst
(Klarheit, Korrektheit, Randfälle, Vollständigkeit, Latenz)
- Wenn eine Kategorie zu kurz kommt, iteriere einmal vor dem Antworten
</self_reflection>
# Oder verwende höheren Schlussfolgerungsaufwand in API-ParameternProblem: Zu ehrerbietig
Symptome: KI bittet ständig um Erlaubnis, anstatt zu handeln. Ständiges "Möchten Sie, dass ich..." anstatt es einfach zu tun.
<persistence>
- Du bist ein Agent — mache weiter, bis die Anfrage des Benutzers vollständig
gelöst ist, bevor du deinen Zug beendest
- Beende nur, wenn du sicher bist, dass das Problem gelöst ist
- Stoppe niemals oder gib zurück, wenn du auf Unsicherheit stößt — leite
den vernünftigsten Ansatz ab und mache weiter
- Bitte nicht um Bestätigung oder Klärung von Annahmen — entscheide, was
am vernünftigsten ist, fahre fort und dokumentiere zur Referenz danach
</persistence>Problem: Zu ausführlich
Symptome: KI generiert viel mehr Token als nötig. Viel Präambel, übermäßige Erklärung, repetitive Zusammenfassungen.
# Verwende API-Ausführlichkeits-Parameter: "low"
# Oder im Prompt:
<output_format>
- Standard: 3-6 Sätze oder ≤5 Aufzählungspunkte
- Vermeide lange narrative Absätze; bevorzuge kompakte Aufzählungspunkte
- Formuliere meine Anfrage nicht um, es sei denn, es ändert die Semantik
- Keine Präambeln wie "Tolle Frage!" oder "Ich helfe gerne"
</output_format>Problem: Zu viele Werkzeugaufrufe
Symptome: Modell feuert Werkzeuge ab, ohne die Antwort voranzutreiben. Redundante Aufrufe, Erkunden von Tangenten, nutzt Kontext nicht effizient.
<tool_use_policy>
- Wähle ein Werkzeug oder keines; bevorzuge Antworten aus dem Kontext, wenn möglich
- Begrenze Werkzeugaufrufe auf 2 pro Benutzeranfrage, es sei denn, neue Informationen machen
mehr strikt notwendig
- Bevor du ein Werkzeug aufrufst, verifiziere, dass du die Informationen tatsächlich benötigst
</tool_use_policy>Problem: Missgebildete Werkzeugaufrufe
Symptome: Werkzeugaufrufe schlagen fehl, produzieren Müllausgabe oder entsprechen nicht dem erwarteten Format. Oft verursacht durch Widersprüche im Prompt.
Bitte analysiere, warum der [tool_name] Werkzeugaufruf missgebildet ist.
1. Überprüfe das bereitgestellte Beispielproblem, um den Fehlermodus zu verstehen
2. Untersuche den System-Prompt und die Werkzeug-Konfiguration sorgfältig
3. Identifiziere alle Mehrdeutigkeiten, Inkonsistenzen oder Formulierungen, die
das Modell irreführen könnten
4. Für jede potenzielle Ursache, erkläre, wie sie zu dem
beobachteten Fehler führen könnte
5. Gib umsetzbare Empfehlungen, um den Prompt oder
die Werkzeug-Konfiguration zu verbessernDie meisten Probleme mit missgebildeten Werkzeugaufrufen stammen aus Widersprüchen zwischen verschiedenen Abschnitten des Prompts. Das Modell verbrennt Schlussfolgerungs-Token beim Versuch, widersprüchliche Anweisungen in Einklang zu bringen, anstatt zu helfen.
Prompt-Optimierung - Der wissenschaftliche Ansatz
Das Erstellen effektiver Prompts ist eine Fähigkeit, aber sie zu verbessern ist eine Wissenschaft. Hier ist der systematische Ansatz, den ich verwende.
Häufige Prompt-Fehler
Bevor Sie optimieren, verstehen Sie, was typischerweise schief geht:
"Bevorzuge Standardbibliothek" dann "verwende externe Pakete, wenn sie Dinge vereinfachen" - KI kann diese gemischten Signale nicht in Einklang bringen.
"Strebe nach exakten Ergebnissen; ungefähre Methoden sind in Ordnung, wenn sie das Ergebnis in der Praxis nicht ändern" - das Modell kann diese Ermessensentscheidung nicht verifizieren.
Wenn Sie JSON brauchen, sagen Sie es. Wenn Sie Aufzählungspunkte brauchen, sagen Sie es. Überlassen Sie das Ausgabeformat nicht dem Zufall.
Ihre Anweisungen sagen eine Sache, aber Ihre Beispiele zeigen etwas anderes. KI folgt Beispielen mehr als Prosa.
Die Optimierungsschleife
Führen Sie Ihren aktuellen Prompt mehrmals aus und dokumentieren Sie die Ergebnisse. Notieren Sie Muster bei Erfolgen und Misserfolgen.
Kategorisieren Sie Fehler. Sind es Korrektheitsprobleme? Formatprobleme? Effizienzprobleme? Jedes erfordert unterschiedliche Korrekturen.
Ändern Sie eine Sache auf einmal. Wenn Sie mehrere Dinge ändern, wissen Sie nicht, was geholfen hat.
Führen Sie dieselben Tests erneut aus. Vergleichen Sie mit der Basislinie. Hat die Änderung geholfen, geschadet oder keinen Effekt gehabt?
Wiederholen Sie, bis Sie akzeptable Leistung erreichen. Halten Sie Notizen darüber, was funktioniert hat und was nicht.
Migration zwischen Modellen
Bei der Migration von Prompts zu einer neuen Modellversion:
Migrations-Best-Practices
- Schritt 1: Modelle wechseln, Prompts noch nicht ändern. Testen Sie die Modelländerung — nicht Prompt-Bearbeitungen.
- Schritt 2: Pinnen Sie den Schlussfolgerungsaufwand, um dem Profil des vorherigen Modells zu entsprechen.
- Schritt 3: Führen Sie Evals für die Basislinie aus. Wenn die Ergebnisse gut aussehen, sind Sie bereit zum Versenden.
- Schritt 4: Wenn Rückschritte, stimmen Sie den Prompt mit gezielten Einschränkungen ab.
- Schritt 5: Führen Sie Evals nach jeder kleinen Änderung erneut aus. Eine Änderung nach der anderen.
Umgang mit Unsicherheit - Wenn die KI es nicht weiß
Eines der größten Risiken bei KI sind selbstbewusst klingende falsche Antworten. Das Modell weiß nicht, was es nicht weiß — es sei denn, Sie bringen ihm bei, wie es mit Unsicherheit umgehen soll.
<uncertainty_handling>
- Wenn die Frage mehrdeutig oder unterspezifiziert ist, benenne
dies explizit und:
- Stelle bis zu 1-3 präzise klärende Fragen, ODER
- Präsentiere 2-3 plausible Interpretationen mit klar gekennzeichneten Annahmen
- Wenn sich externe Fakten kürzlich geändert haben könnten (Preise, Veröffentlichungen,
Richtlinien) und keine Werkzeuge verfügbar sind:
- Antworte in allgemeinen Begriffen und gib an, dass Details sich geändert haben könnten
- Fabriziere niemals genaue Zahlen, Zeilennummern oder externe Referenzen
wenn du unsicher bist
- Wenn du unsicher bist, bevorzuge Sprache wie "Basierend auf dem bereitgestellten
Kontext..." anstelle von absoluten Behauptungen
</uncertainty_handling>Hochrisiko-Selbstprüfung
Für Bereiche mit hohem Einsatz fügen Sie einen expliziten Selbstverifizierungsschritt hinzu:
<high_risk_self_check>
Vor dem Finalisieren einer Antwort in rechtlichen, finanziellen, Compliance- oder
sicherheitskritischen Kontexten:
- Scanne kurz deine eigene Antwort nach:
- Nicht angegebenen Annahmen
- Spezifischen Zahlen oder Behauptungen, die nicht im Kontext begründet sind
- Übermäßig starker Sprache ("immer", "garantiert", etc.)
- Wenn du welche findest, schwäche sie ab oder qualifiziere sie und gib Annahmen explizit an
</high_risk_self_check>Das Ziel ist nicht, KI weniger selbstbewusst zu machen — es ist, sie akkurat selbstbewusst zu machen. Unsicherheit über unsichere Dinge ist ein Feature, kein Fehler.
Metaprompting - KI nutzen, um KI zu verbessern
Hier ist die Meta-Technik in meinem Toolkit: KI verwenden, um Ihre Prompts zu verbessern. Es klingt zirkulär, ist aber unglaublich effektiv.
Diagnose von Prompt-Fehlern
Du bist ein Prompt Engineer, der beauftragt ist, einen System-Prompt zu debuggen.
Dir wird gegeben:
1) Der aktuelle System-Prompt:
<system_prompt>
[FÜGE DEINEN PROMPT HIER EIN]
</system_prompt>
2) Ein kleiner Satz von protokollierten Fehlern. Jedes Protokoll hat:
- Abfrage
- tatsächliche_Ausgabe
- erwartete_Ausgabe (oder Problembeschreibung)
<failure_traces>
[BEISPIELE FÜR FEHLER EINFÜGEN]
</failure_traces>
Deine Aufgaben:
1) Identifiziere unterschiedliche Fehlermodi, die du siehst
2) Zitiere für jeden Fehlermodus die spezifischen Zeilen des System-Prompts,
die dies am wahrscheinlichsten verursachen oder verstärken
3) Erkläre, wie diese Zeilen den Agenten zum
beobachteten Verhalten steuern
Gib deine Antwort im strukturierten Format zurück:
failure_modes:
- name: ...
description: ...
prompt_drivers:
- exact_or_paraphrased_line: ...
- why_it_matters: ...Verbesserungen generieren
Du hast zuvor diesen System-Prompt und seine Fehlermodi analysiert.
System-Prompt:
<system_prompt>
[ORIGINAL PROMPT]
</system_prompt>
Fehlermodus-Analyse:
[DIAGNOSE VOM VORHERIGEN SCHRITT EINFÜGEN]
Bitte schlage eine chirurgische Überarbeitung vor, die die beobachteten Probleme reduziert,
während gute Verhaltensweisen erhalten bleiben.
Einschränkungen:
- Gestalte den Agenten nicht von Grund auf neu
- Bevorzuge kleine, explizite Bearbeitungen: kläre widersprüchliche Regeln, entferne
redundante oder widersprüchliche Zeilen, straffe vage Anleitungen
- Mache Kompromisse explizit
- Halte Struktur und Länge ungefähr ähnlich wie im Original
Ausgabe:
1) patch_notes: eine prägnante Liste der wichtigsten Änderungen und Begründungen
2) revised_system_prompt: der vollständige aktualisierte Prompt mit angewendeten BearbeitungenSelbstreflexion für Qualität
Diese Technik ist verblüffend: Weisen Sie die KI an, ihre eigenen Bewertungskriterien zu erstellen und dagegen zu iterieren:
<self_reflection>
- Verbringe zuerst Zeit damit, über eine Rubrik nachzudenken, bis du zuversichtlich bist
- Denke tief über jeden Aspekt nach, was eine erstklassige
Lösung ausmacht. Nutze dieses Wissen, um eine Rubrik zu erstellen, die 5-7
Kategorien hat. Diese Rubrik ist kritisch, um es richtig zu machen, aber zeige
sie mir nicht — dies ist nur für deine Zwecke.
- Nutze schließlich die Rubrik, um intern nachzudenken und an der
bestmöglichen Lösung für den Prompt zu iterieren
- Wenn deine Antwort nicht die Bestnoten in allen
Kategorien in der Rubrik erreicht, beginne von vorne
</self_reflection>Sie bitten die KI, Qualitätskriterien aus ihrem Wissen über Exzellenz zu generieren, und diese Kriterien dann zu verwenden, um ihre eigene Ausgabe zu bewerten und zu verbessern — alles bevor Sie etwas sehen. Die Verbesserung der Ausgabequalität ist substantiell.
Kampferprobte Vorlagen, die Sie heute verwenden können
Universelle Aufgabenvervollständigung
<context>
[Hintergrundinformationen, die die KI benötigt, um die Situation zu verstehen]
</context>
<task>
[Klare Aussage darüber, was Sie getan haben wollen]
</task>
<requirements>
[Spezifische Anforderungen oder Einschränkungen]
</requirements>
<format>
[Wie die Ausgabe strukturiert sein soll]
</format>
<examples>
[Optional: Beispiele für die gewünschte Ausgabe]
</examples>Code-Review-Vorlage
<context>
Überprüfe Code für [Projekt/Kontext].
Die Codebasis verwendet [Technologien/Muster].
</context>
<code_to_review>
[Füge Code hier ein]
</code_to_review>
<review_criteria>
Konzentriere dich auf:
1. Korrektheit: Tut es das, was es behauptet?
2. Lesbarkeit: Ist es für andere Entwickler klar?
3. Leistung: Irgendwelche offensichtlichen Ineffizienzen?
4. Sicherheit: Irgendwelche Schwachstellen?
5. Stil: Entspricht es den Konventionen der Codebasis?
</review_criteria>
<output_format>
Für jedes gefundene Problem:
- Schweregrad: [Kritisch/Groß/Gering/Vorschlag]
- Ort: [Zeilennummer oder Abschnitt]
- Problem: [Was ist falsch]
- Korrektur: [Wie man es angeht]
</output_format>Forschungsanalyse-Vorlage
<research_task>
[Thema oder Frage zur Recherche]
</research_task>
<methodology>
- Beginne mit mehreren gezielten Suchen; verlasse dich nicht auf eine einzelne Abfrage
- Recherchiere tief, bis du genügend Informationen für eine
genaue, umfassende Antwort hast
- Füge gezielte Folgesuchen hinzu, um Lücken zu füllen oder Meinungsverschiedenheiten zu lösen
- Iteriere weiter, bis zusätzliche Suche wahrscheinlich nicht die
Antwort ändern wird
</methodology>
<output_requirements>
- Führe mit einer klaren Antwort auf die Hauptfrage
- Unterstütze mit Beweisen und Zitaten
- Erkenne Einschränkungen und Unsicherheiten an
- Biete konkrete Beispiele, wo hilfreich
- Füge relevanten Kontext zum Verständnis der Implikationen hinzu
</output_requirements>
<citation_format>
[Wie Quellen zitiert werden sollen]
</citation_format>Web-Forschungs-Agent
<core_mission>
Antworte auf die Frage des Benutzers vollständig und hilfreich, mit genügend Beweisen,
dass ein skeptischer Leser ihr vertrauen kann.
Erfinde niemals Fakten. Wenn du etwas nicht verifizieren kannst, sag es klar.
Standardmäßig detailliert und nützlich sein, anstatt kurz.
Nach Beantwortung der direkten Frage, füge hochwertiges angrenzendes Material hinzu,
das das zugrunde liegende Ziel des Benutzers unterstützt, ohne vom Thema abzuschweifen.
</core_mission>
<research_rules>
- Beginne mit mehreren gezielten Suchen; verwende parallele Suchen
- Verlasse dich niemals auf eine einzelne Abfrage
- Iteriere weiter, bis alles wahr ist:
- Du hast jeden Teil der Frage beantwortet
- Du hast konkrete Beispiele und hochwertiges angrenzendes Material gefunden
- Du hast ausreichende Quellen für Kernbehauptungen gefunden
</research_rules>
<citation_rules>
- Platziere Zitate nach jedem Absatz, der nicht offensichtliche
webbasierte Behauptungen enthält
- Erfinde keine Zitate
- Verwende mehrere Quellen für Schlüsselbehauptungen, wenn möglich
</citation_rules>
<ambiguity_handling>
- Stelle niemals klärende Fragen, es sei denn, der Benutzer fordert dies explizit an
- Wenn die Abfrage mehrdeutig ist, gib deine beste Interpretation an, dann
decke die wahrscheinlichsten Absichten umfassend ab
</ambiguity_handling>Die Zukunft des Prompt Engineering
Während ich dies Anfang 2026 schreibe, entwickelt sich Prompt Engineering rasant. Modelle werden fähiger, steuerbarer und zuverlässiger. Einige sagen voraus, dass Prompt Engineering obsolet wird, da KI besser darin wird, Absichten zu verstehen. Ich widerspreche.
Was sich ändert, ist das Niveau des Prompt Engineering, nicht seine Notwendigkeit. Frühe Tage erforderten aufwendige Prompts für grundlegende Aufgaben. Jetzt funktionieren grundlegende Aufgaben sofort, aber komplexe agentische Workflows erfordern immer noch anspruchsvolles Prompting. Die Messlatte steigt, sie verschwindet nicht.
Prompt Engineering geht nicht weg — es entwickelt sich. Die Fähigkeiten, die zählen, verschieben sich von "wie bringe ich KI zum Laufen" zu "wie bringe ich KI dazu, exzellent und zuverlässig im Maßstab zu arbeiten."
Was kommt
Bessere Standardverhalten
Modelle werden intelligentere Standardeinstellungen haben, die weniger explizite Anweisungen für gemeinsame Muster erfordern. Prompts werden sich mehr auf Anpassung als auf grundlegende Fähigkeiten konzentrieren.
Reichere Werkzeug-Ökosysteme
KI wird sofort Zugriff auf mehr Werkzeuge haben. Prompt Engineering wird sich zur Orchestrierung verschieben — wissen, wann man was benutzt, nicht nur wie.
Multimodale Integration
Prompts werden zunehmend Bilder, Audio, Video und strukturierte Daten neben Text einbeziehen. Neue Muster werden für multimodale Aufgaben entstehen.
Agentische Komplexität
Da Agenten längere, komplexere Aufgaben bewältigen, wird Prompt Engineering mehr wie Systemdesign — Architektur, nicht nur Anweisungen.
Mein Rat für die Zukunft
Konzentrieren Sie sich auf Grundlagen. Die spezifischen Techniken in diesem Leitfaden werden sich entwickeln, aber die zugrunde liegenden Prinzipien — klare Kommunikation, explizite Erwartungen, strukturiertes Denken, iterative Verfeinerung — sind zeitlos. Meistern Sie diese, und Sie werden sich an alles anpassen, was als nächstes kommt.
Abschließende Gedanken
Vor zwei Jahren dachte ich, KI würde die Notwendigkeit klarer Kommunikation ersetzen. Ich lag völlig falsch. KI hat klare Kommunikation wertvoller denn je gemacht. Die Menschen, die mit KI gedeihen, sind nicht diejenigen, die magische Worte gefunden haben — es sind diejenigen, die gelernt haben, mit Präzision zu denken und sich auszudrücken.
Prompt Engineering handelt nicht wirklich von KI. Es geht um Sie. Es geht darum, die Disziplin zu entwickeln, das zu artikulieren, was Sie tatsächlich wollen, die Geduld, darauf hinzuarbeiten, und die Demut, aus dem zu lernen, was nicht funktioniert.
Wenn Sie eine Sache aus diesem Leitfaden mitnehmen, lassen Sie es dies sein: Behandeln Sie jeden Prompt als Chance, klares Denken zu üben. Die KI ist nur ein Spiegel, der die Klarheit — oder Verwirrung — Ihres eigenen Geistes zurückwirft.
Das Aufkommen von KI hat Wissen nicht obsolet gemacht — es hat Neugier mächtiger denn je gemacht. Wir sind nicht mehr durch das begrenzt, was wir bereits wissen. Mit den richtigen Werkzeugen und der Bereitschaft zu denken, können gewöhnliche Menschen einen Ozean an Wissen umarmen. Unabhängig vom Beruf. Unabhängig vom Alter. Ich hoffe, diese Reise mit Freunden auf der ganzen Welt zu teilen. Lassen Sie uns gemeinsam diese neue Welt willkommen heißen. Lassen Sie uns gemeinsam wachsen.

Diskussion
0 KommentareKommentar hinterlassen
Seien Sie der Erste, der seine Gedanken teilt!