Różnica między frustrującymi obrazami AI a zapierającymi dech w piersiach nie leży w talencie czy szczęściu — to nauczenie się mówienia wizualnym językiem, który maszyna rozumie.
Wciąż pamiętam dokładnie ten moment, kiedy wszystko się zmieniło. Była 2 w nocy we wtorek. Wpatrywałem się w ekran od godzin, cyklicznie wpisując prompt za promptem, patrząc, jak ChatGPT wypluwa obrazy, które w niczym nie przypominały tego, co sobie wyobraziłem. Palce o niemożliwej anatomii. Tekst, który topił się w bełkot. Postacie, które wydawały się aktywnie opierać moim intencjom. Byłem gotów całkowicie zrezygnować z generowania obrazów AI — odrzucić to jako przereklamowaną technologię, która działała tylko dla innych ludzi.
Wtedy spróbowałem czegoś innego. Zamiast opisywać to, co chciałem zobaczyć, opisałem to, co uchwyciłby aparat. Zamiast prosić o "piękny zachód słońca", napisałem "światło złotej godziny strumieniujące przez szczyty górskie, zrobione na Canon 5D Mark IV, obiektyw 24-70mm przy f/2.8, naturalna korekcja kolorów". Obraz, który się pojawił, nie był tylko akceptowalny — był oszałamiający. Fotorealistyczny. Dokładnie to, co istniało tylko w mojej wyobraźni chwilę wcześniej.
Ta jedna zmiana perspektywy odblokowała wszystko. Przez następne miesiące zgłębiałem temat. Wygenerowałem tysiące obrazów. Przetestowałem każdą technikę, jaką mogłem znaleźć. Przeczytałem dokumentację OpenAI od deski do deski. Eksperymentowałem z GPT Image 1.5 w dniu premiery. A teraz podzielę się wszystkim, czego się nauczyłem — nie powierzchownymi wskazówkami, które znajdziesz wszędzie indziej, ale głęboką wiedzą, która oddziela profesjonalistów od hobbystów. To jest przewodnik, którego istnienia życzyłem sobie, gdy zaczynałem. Oto jak przejść od sfrustrowanego początkującego do pewnego siebie twórcy.
Moja Podróż do Generowania Obrazów AI
Pozwólcie, że zabiorę was z powrotem do miejsca, gdzie to wszystko się zaczęło. Jak wielu z was czytających to, byłem początkowo sceptyczny wobec generowania obrazów przez AI. "To tylko zabawka dla entuzjastów technologii", myślałem. "Prawdziwa praca twórcza wciąż wymaga prawdziwych umiejętności". Nie mogłem się bardziej mylić.
Moja pierwsza prawdziwa potrzeba obrazów AI wynikła z praktycznego problemu. Tworzyłem treści do projektu i potrzebowałem obrazów okładkowych — wielu. Płaciłem za zdjęcia stockowe, wydając pieniądze na generyczne ujęcia, których używał też każdy inny twórca. Obrazy były w porządku, ale brakowało im duszy. Czuć było, że są pożyczone, a nie własne.
Przyjaciel wspomniał, że ChatGPT może teraz generować obrazy. "Po prostu opisz, co chcesz", powiedziała. "To jak magia". Więc spróbowałem. Mój pierwszy prompt był żenująco naiwny: "Piękny zachód słońca nad górami". Wynik? Rozmazany bałagan, który wyglądał jak akwarela zostawiona na deszczu. Byłem delikatnie mówiąc rozczarowany.
Ale coś ciągnęło mnie z powrotem. Spróbowałem znowu. I znowu. Każda porażka uczyła mnie czegoś nowego o tym, jak AI interpretuje język. Zacząłem zauważać wzorce — pewne frazy, które konsekwentnie dawały lepsze wyniki, podejścia strukturalne, które kierowały model w stronę mojej wizji, zamiast od niej oddalać.
Przełom nastąpił, gdy zdałem sobie sprawę: generowanie obrazów AI nie polega na opisywaniu tego, co widzisz w swoim umyśle — polega na opisywaniu tego, co uchwyciłby aparat w rzeczywistości. Ta jedna zmiana perspektywy zmieniła wszystko.
Przestałem myśleć jak marzyciel i zacząłem myśleć jak fotograf. Zamiast "piękny zachód słońca", pisałem o świetle złotej godziny, konkretnych modelach aparatów, ogniskowych obiektywów, ustawieniach przysłony, taśmach filmowych. AI rozumiała ten język, ponieważ była trenowana na milionach obrazów, które posiadały dokładnie takie metadane techniczne.
W ciągu następnych miesięcy stałem się obsesyjny. Wygenerowałem tysiące obrazów w każdym stylu i przypadku użycia, jaki mogłem sobie wyobrazić. Przeczytałem każdy kawałek dokumentacji opublikowany przez OpenAI. Dołączyłem do społeczności twórców przesuwających granice tego, co możliwe. A kiedy GPT Image 1.5 wystartował w styczniu 2026, byłem gotowy. Rozumiałem nie tylko jak go używać, ale dlaczego działał w ten sposób.
Teraz zamierzam podzielić się wszystkim, czego się nauczyłem. Nie powierzchownymi wskazówkami, które znajdziesz w stu innych przewodnikach. Głęboką wiedzą, która pochodzi z obszernych eksperymentów, systematycznych testów i niezliczonych rozmów z innymi twórcami, którzy popychają te narzędzia do granic ich możliwości. To jest kompletny przewodnik — ten, który zabierze cię od zagubionego początkującego do pewnego siebie twórcy.
Czym jest Generator Obrazów ChatGPT
Zanim zagłębimy się w techniki, wyjaśnijmy dokładnie, z czym pracujemy. Generator obrazów ChatGPT to zintegrowany system tworzenia i edycji obrazów OpenAI, obecnie zasilany przez ich model GPT Image 1.5. W przeciwieństwie do samodzielnych narzędzi, takich jak Midjourney czy Stable Diffusion, jest głęboko zintegrowany z interfejsem konwersacyjnym ChatGPT.
Ta integracja ma większe znaczenie, niż mogłoby się wydawać. Ponieważ ChatGPT rozumie kontekst, może zachować spójność w wielu generacjach, pamiętać twoje preferencje w ramach sesji, a nawet rozumować na temat tego, co próbujesz stworzyć. Powiedz mu, że pracujesz nad książką dla dzieci, a dostosuje swój styl odpowiednio. Wspomnij, że potrzebujesz obrazów do prezentacji korporacyjnej, a przesunie się w stronę czystej, profesjonalnej estetyki. Ta świadomość kontekstowa to coś, czego samodzielne generatory obrazów po prostu nie mogą dorównać.
🎨 Generowanie Tekst-na-Obraz
Opisz cokolwiek w języku naturalnym i patrz, jak się materializuje. Od fotorealistycznych portretów po sztukę abstrakcyjną, od mockupów produktów po fantastyczne krajobrazy — jeśli możesz to opisać, AI może to stworzyć.
✏️ Precyzyjna Edycja Obrazu
Prześlij istniejące obrazy i modyfikuj je za pomocą poleceń tekstowych. Zmieniaj kolory, zamieniaj obiekty, dostosuj oświetlenie, zmieniaj pory roku lub całkowicie przeobraź scenę, zachowując elementy, które chcesz zatrzymać.
🔄 Transfer Stylu
Weź język wizualny z jednego obrazu — jego paletę, fakturę, pociągnięcia pędzla lub estetykę — i zastosuj go do zupełnie nowej treści. Idealne do utrzymania spójności marki lub tworzenia spójnych serii.
📝 Niezawodne Renderowanie Tekstu
Wreszcie, AI, która potrafi poprawnie pisać. GPT Image 1.5 obsługuje tekst na obrazach z niespotykaną dokładnością — idealne dla logotypów, plakatów, infografik i materiałów marketingowych, gdzie słowa mają znaczenie.
Jak To Faktycznie Działa
Kiedy wysyłasz prompt do generatora obrazów ChatGPT, za kulisami dzieje się kilka rzeczy. Po pierwsze, sam ChatGPT przetwarza twoje żądanie, potencjalnie rozszerzając lub wyjaśniając twój prompt w oparciu o kontekst. Może dodać szczegóły, które zasugerowałeś, ale nie wypowiedziałeś, lub ustrukturyzować twoje żądanie w sposób, który model obrazu lepiej rozumie.
Następnie żądanie trafia do modelu generowania obrazów — obecnie GPT Image 1.5 — który przekształca twój opis tekstowy w wynik wizualny. Model ten był trenowany na ogromnym zbiorze danych obrazów sparowanych ze szczegółowymi opisami, ucząc się zawiłych relacji między językiem a elementami wizualnymi.
Wynikiem jest system, który autentycznie rozumie, o co prosisz, a nie tylko dopasowuje słowa kluczowe. Poproś o "fotorealistyczny moment z ukrycia", a otrzymasz coś, co autentycznie sprawia wrażenie niepozowanego. Zażądaj "porannego światła przez żaluzje weneckie", a otrzymasz konkretny wzór w paski, który to tworzy.
GPT Image 1.5 zajął pierwsze miejsce w Artificial Analysis Image Arena zarówno w kategorii tekst-na-obraz, jak i edycji obrazu, ze wskaźnikiem zgodności z instrukcjami na poziomie 90% — o 13 punktów procentowych wyższym niż jego najbliższy konkurent. To nie jest marketingowa gadka; to odzwierciedla prawdziwy skok w możliwościach.
Rewolucja GPT Image 1.5
Kiedy OpenAI wypuściło GPT Image 1.5 w styczniu 2026, nie tylko ulepszyli swój poprzedni model — przebudowali fundamenty. Używałem poprzednich wersji intensywnie, więc natychmiast zauważyłem różnicę. To nie była przyrostowa poprawa; to była zmiana paradygmatu.
Pozwólcie, że będę konkretny co do tego, co się zmieniło, ponieważ zrozumienie tych ulepszeń pomoże wam efektywnie je wykorzystać.
Trzy Przełomy, Które Mają Znaczenie
Poprzednie modele miały frustrującą tendencję do dryfowania. Prosiłeś o zmianę jednej rzeczy, a trzy inne zmieniały się niespodziewanie. Napraw oświetlenie, a nagle twarz postaci wygląda inaczej. GPT Image 1.5 autentycznie rozumie "zmień tylko ten element" — może modyfikować konkretne części, zachowując oświetlenie, kompozycję, cechy twarzy, a nawet subtelne tekstury. To sprawia, że iteracyjne udoskonalanie jest faktycznie praktyczne.
Szybkość generowania wzrosła do 400% w porównaniu z poprzednimi wersjami. Co zajmowało 30 sekund, teraz zajmuje 7-8. Ale co ważniejsze, możesz kolejkować nowe generacje, podczas gdy obecne są wciąż przetwarzane. To przekształca proces twórczy z "wyślij i czekaj" na "eksploruj i iteruj". Psychologiczna różnica jest znacząca — szybsze pętle informacji zwrotnej oznaczają więcej eksperymentowania.
Renderowanie tekstu w obrazach AI historycznie było katastrofą — błędy ortograficzne, duplikacje, litery topiące się w abstrakcyjne kształty. GPT Image 1.5 obsługuje gęsty, mały tekst przy zachowaniu właściwej typografii, układu i czytelności. To otwiera infografiki, materiały marketingowe, mockupy UI i każdy przypadek użycia, w którym słowa pojawiają się na obrazach. Po raz pierwszy mogę generować slajdy prezentacji, grafiki do mediów społecznościowych z napisami i etykiety produktów, których faktycznie bym użył.
Zrozumienie Ustawień Jakości
GPT Image 1.5 oferuje różne poziomy jakości, a zrozumienie, kiedy używać każdego z nich, zaoszczędzi ci czasu i poprawi twoje wyniki. Tu nie chodzi tylko o jakość wyjściową — chodzi o dopasowanie odpowiedniego narzędzia do odpowiedniego zadania.
⚡ Tryb Niskiej Jakości
Nie daj się zwieść nazwie — "niska jakość" tutaj oznacza "szybki i wydajny". Wyniki są wciąż niezwykle dobre dla większości przypadków użycia. Używaj tego do:
- Początkowej eksploracji koncepcji i burzy mózgów
- Szybkich iteracji przy dopracowywaniu pomysłów
- Prostych kompozycji bez drobnych detali
- Generowania o dużej objętości, gdzie liczy się prędkość
- Szkiców przed zatwierdzeniem ostatecznych wersji
✨ Tryb Wysokiej Jakości
Kiedy każdy piksel ma znaczenie i potrzebujesz wyników gotowych do publikacji. Zarezerwuj to dla:
- Ostatecznych obrazów produkcyjnych do dostarczenia
- Gęstego tekstu i pracy typograficznej
- Złożonych infografik z małymi detalami
- Fotorealistycznych portretów, gdzie tekstura ma znaczenie
- Każdego obrazu, gdzie potrzebujesz maksymalnej wierności
Ukryte Ustawienie Wierności Wejścia
Oto coś, o czym większość przewodników ci nie powie: przy edycji obrazów istnieje parametr o nazwie input_fidelity, który dramatycznie wpływa na wyniki. Ustaw go na "high" (wysoki), gdy musisz zachować cechy twarzy, utrzymać tożsamość w trakcie edycji lub dokonać znaczących zmian w scenie. Model pracuje ciężej, aby zachować kluczowe cechy oryginalnego obrazu.
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # Tajny składnik dla zachowania tożsamości
quality="high",
image=[open("portrait.png", "rb")],
prompt="Change the background to a sunset beach while preserving the person's exact appearance"
)Ta kombinacja zapewnia maksymalne zachowanie oryginalnego tematu przy jednoczesnym zastosowaniu żądanych zmian.
Największa zmiana z GPT Image 1.5 nie jest techniczna — jest filozoficzna. Generowanie obrazów przechodzi z "promptuj i módl się" na "instruuj i iteruj". To wymaga zupełnie innego modelu mentalnego dla tego, jak podchodzisz do twórczości wizualnej.
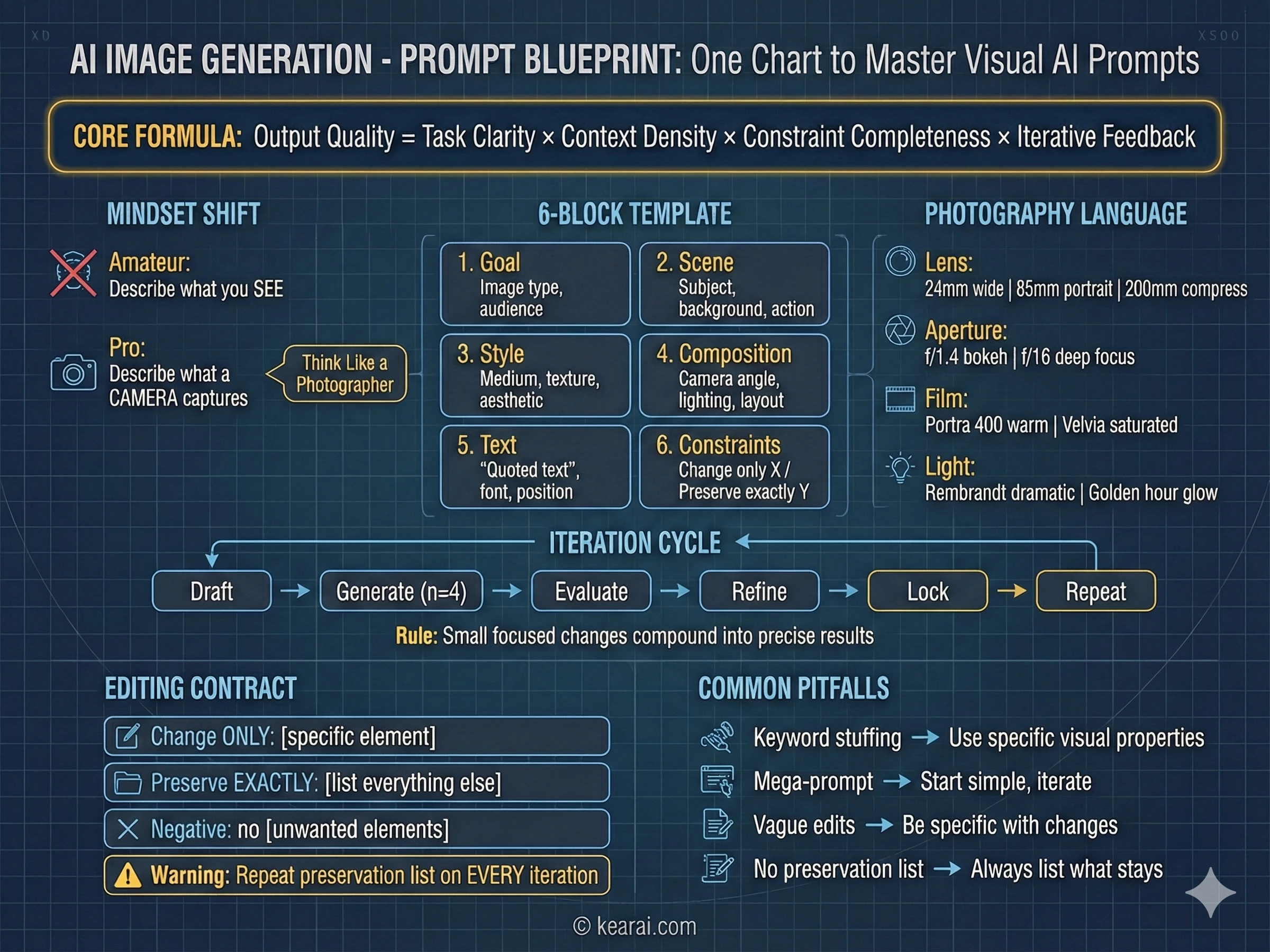
Framework Promptów, Który Zmienił Wszystko
Po wygenerowaniu tysięcy obrazów opracowałem framework, który konsekwentnie produkuje wyjątkowe rezultaty. Zapomnij o wszystkim, co czytałeś o dodawaniu "masterpiece, trending on ArtStation, ultra-detailed, 8K resolution" do swoich promptów. Te słowa kluczowe działały dla starszych modeli, które potrzebowały wskazówek jakościowych, ale GPT Image 1.5 reaguje na strukturę i specyficzność, a nie na upychanie słów kluczowych.
Nazywam to ustrukturyzowaną architekturą promptu, a każdy skuteczny prompt, który teraz piszę, podąża za tym wzorcem.
Goal/Output (Cel/Wyjście):
- [Type of image: ad, UI mockup, infographic, photo, illustration] (Typ obrazu)
- [Intended use and audience] (Zamierzone użycie i odbiorcy)
Scene (Scena):
- [Background/environment description] (Opis tła/środowiska)
- [Main subject with specific details] (Główny temat ze szczegółami)
- [Action or relationship between elements] (Akcja lub relacja między elementami)
Style (Styl):
- [Medium: photograph, watercolor, 3D render, vector illustration] (Medium)
- [Key textures: matte, glossy, grainy, smooth, organic] (Kluczowe tekstury)
- [Quality descriptors: realistic imperfections, stylized, minimalist] (Deskryptory jakości)
Composition/Layout (Kompozycja/Układ):
- [Camera position: close-up, wide shot, aerial view, eye-level] (Pozycja kamery)
- [Lighting: golden hour, studio strobes, overcast, dramatic shadows] (Oświetlenie)
- [Element placement: centered, rule of thirds, negative space, margins] (Umieszczenie elementów)
Text (if any) (Tekst jeśli jest):
- "Exact text in quotes" ("Dokładny tekst w cudzysłowie")
- [Font style, size, color, position] (Styl czcionki, rozmiar, kolor, pozycja)
- [Specify: render only once, no duplicates] (Określ: renderuj tylko raz)
Constraints (Ograniczenia):
- Change ONLY: [specific element if editing] (Zmień TYLKO)
- Preserve exactly: [elements that must stay unchanged] (Zachowaj dokładnie)
- Negative: no watermark, no extra text, no logos, no [unwanted elements] (Negatyw)Ten framework daje modelowi jasny kontekst dla każdej decyzji wizualnej, którą musi podjąć.
Siedem Zasad Skutecznego Promptowania
Poza strukturą, te zasady rządzą tym, jak piszę każdy prompt. Są różnicą między obrazami, które prawie działają, a obrazami, które idealnie trafiają w twoją wizję.
Struktura Ponad Słowami Kluczowymi
Używaj spójnej kolejności: tło → temat → szczegóły → ograniczenia. Dla złożonych żądań używaj oznaczonych sekcji lub przerw w liniach. Długie akapity dezorientują model; zorganizowana struktura prowadzi go w stronę twojej intencji.
Specyficzność Ponad Superlatywami
Zamiast "wysoka jakość" lub "ultra-szczegółowy", opisz rzeczywiste właściwości wizualne. Materiały, tekstury, kształty, media. "Widoczne pory skóry i subtelne piegi" bije "bardzo szczegółową twarz" za każdym razem.
Wyraźna Kontrola Kompozycji
Nazwij swoje kadrowanie (zbliżenie, szeroki plan, widok z lotu ptaka), perspektywę (poziom oczu, niski kąt, kąt holenderski) i nastrój oświetlenia (miękkie rozproszone, złota godzina, światło konturowe o wysokim kontraście). Nie zostawiaj tego przypadkowi.
Kontrakt Zmiany vs. Zachowania
Dla edycji, wyraźnie określ, co powinno się zmienić, A co powinno pozostać nietknięte. Używaj "change only X" i "preserve exactly Y". Powtarzaj tę listę zachowania przy każdej iteracji, aby zapobiec dryfowaniu.
Tekst Wymaga Precyzji
Umieść wymagany tekst w "cudzysłowie" lub WIELKIMI LITERAMI. Określ styl czcionki, rozmiar, kolor i pozycję. Dla trudnych słów lub nazw marek, przeliteruj je litera po literze. Zawsze dodawaj "render exactly once, no duplicates".
Jasność Odniesienia Wieloobrazowego
Podczas pracy z wieloma obrazami wejściowymi, odwołuj się do każdego przez indeks i opis: "Image 1: ujęcie produktu, Image 2: referencja stylu". Wyraźnie określ, jak powinny współdziałać.
Iteruj Zamiast Przeciążać
Zacznij od czystego promptu bazowego, następnie dopracuj za pomocą małych, pojedynczych zmian. "Make the lighting warmer" (Ociepl oświetlenie). "Remove the background tree" (Usuń drzewo w tle). Małe kroki sumują się w precyzyjne wyniki.
Najczęstszy Błąd
Największy błąd, jaki widzę u ludzi: próba określenia wszystkiego w jednym gigantycznym prompcie, z nadzieją, że model jakoś to ogarnie. To prawie nigdy nie działa dobrze. Zacznij od prostszego promptu, aby ustalić bazę, następnie iteruj z ukierunkowanymi udoskonaleniami. Uzyskasz lepsze wyniki w krótszym czasie z dużo mniejszą liczbą frustrujących porażek.
Sposób Myślenia Fotografa
Pojedyncza największa poprawa w moich wynikach pochodziła ze zmiany mentalnej: przestałem myśleć jak artysta opisujący wizję i zacząłem myśleć jak fotograf opisujący ujęcie. To nie jest tylko metafora — to praktyczna technika, która wykorzystuje sposób, w jaki model był trenowany.
Modele obrazów AI uczyły się z milionów fotografii, które posiadały metadane: modele aparatów, specyfikacje obiektywów, ustawienia przysłony, warunki oświetleniowe. Kiedy używasz tego języka, aktywujesz głębokie zrozumienie modelu, jak prawdziwe aparaty chwytają prawdziwe sceny.
Język Fotograficzny, Który Działa
- Wybór obiektywu: "24mm wide angle" (szeroki kąt) tworzy rozległe sceny ze zniekształceniami na krawędziach; "200mm telephoto" (teleobiektyw) kompresuje głębię i izoluje obiekty
- Efekt przysłony: "f/1.4 bokeh" daje kremowe rozmycie tła dla portretów; "f/16 deep focus" (duża głębia ostrości) utrzymuje wszystko ostre dla krajobrazów
- Rodzaje filmu: "Kodak Portra 400" dla ciepłych, pochlebnych odcieni skóry; "Fuji Velvia" dla mocnych, nasyconych krajobrazów; "Ilford HP5" dla kontrastowej czerni i bieli
- Konfiguracje oświetlenia: "Rembrandt lighting" dla dramatycznych portretów; "butterfly lighting" dla ujęć beauty; "golden hour backlight" dla eterycznych, świecących krawędzi
- Ruch kamery: "long exposure motion blur" dla dynamicznej energii; "high-speed freeze frame" dla uchwycenia akcji
Zamiast mówić "make it look professional" (niech wygląda profesjonalnie), spróbuj "shot on Hasselblad medium format, studio strobe lighting, seamless gray backdrop, color-calibrated for print reproduction". Zamiast "realistic portrait" (realistyczny portret), spróbuj "candid photograph, 85mm f/1.4 lens, window light from camera left, subtle fill from reflector, visible skin texture with pores, shot on Sony A7R IV".
❌ PRZED (Niejasne):
"A beautiful portrait of an old fisherman, very detailed, high quality, realistic"
✅ PO (Mentalność Fotografa):
"Candid documentary photograph of an elderly fisherman on a weathered wooden boat.
Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind eyes.
Gray stubble. Faded traditional anchor tattoo on forearm. Salt-stained navy wool
sweater, worn cap.
Early morning coastal light, soft fog diffusing the sun. Medium close-up at eye
level, 50mm lens, f/2.8, shallow depth of field. Shot like 35mm film with subtle
grain, natural color balance.
Documentary style — honest, unretouched, capturing a real moment. No glamorization."Mentalność fotografa przekształca niejasne życzenia w precyzyjne specyfikacje wizualne, które model rozumie głęboko.
Kiedy opisujesz obrazy używając języka fotograficznego, nie jesteś tylko bardziej konkretny — mówisz językiem, którego model został nauczony rozumieć. Specyfikacje aparatu, konfiguracje oświetlenia i rodzaje filmu nie są arbitralnymi słowami kluczowymi; kodują precyzyjne informacje wizualne, które model może dokładnie odkodować.
Mistrzostwo Tekst-na-Obraz
Tworzenie obrazów z czystych opisów tekstowych to miejsce, gdzie większość ludzi zaczyna swoją podróż z obrazami AI. To także miejsce, gdzie przepaść między wynikami amatorskimi a profesjonalnymi jest najbardziej widoczna. Pozwólcie, że przeprowadzę was przez techniki, które konsekwentnie dają wybitne rezultaty w różnych przypadkach użycia.
Fotorealistyczne Obrazy, Które Wydają Się Naturalne
Klucz do fotorealizmu jest kontraintuicyjny: musisz promptować o niedoskonałość. Idealna skóra, idealne oświetlenie, idealna kompozycja — to krzyczy "wygenerowane przez AI". Rzeczywistość jest bardziej bałaganiarska, i ten bałagan sprawia, że obrazy wydają się autentyczne.
Create a photorealistic candid photograph of an elderly sailor standing on a small fishing boat.
Subject: Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind
eyes with crow's feet. Gray stubble, a few days unshaven. Faded traditional anchor
tattoo on forearm. Salt-stained navy wool sweater, worn and pilled. Creased cap
with faded insignia.
Setting: Early morning on the water, soft coastal fog diffusing the light. Aged
wooden boat deck with peeling paint, fishing nets in background, coiled rope.
Technical: Shot like 35mm film photography, medium close-up at eye level, 50mm
lens, shallow depth of field with boat blurred behind him. Subtle film grain,
natural color balance without heavy grading.
The image should feel like a real moment captured by a photojournalist — honest,
unposed, with real skin texture, worn materials, and everyday imperfection. No
glamorization, no heavy retouching, no artificial perfection.Zauważ, jak wyraźnie prosimy o niedoskonałości — zniszczona skóra, zużyte materiały, łuszcząca się farba. Rzeczywistość ma teksturę.
Infografiki i Wizualizacja Danych
Ulepszone renderowanie tekstu w GPT Image 1.5 sprawia, że infografiki są autentycznie praktycznym przypadkiem użycia. Teraz tworzę grafiki informacyjne profesjonalnej jakości, których faktycznie używam w mojej pracy.
Create a detailed infographic explaining how a coffee machine works.
Structure:
- Title at top: "The Journey of Your Morning Coffee"
- Vertical flow diagram showing: bean hopper → grinder → portafilter →
grouphead → water heating → extraction → cup
- Each step has an icon and 1-2 sentence explanation
- Warm color palette (browns, creams, copper accents)
- Clean, modern design with plenty of white space
- Subtle coffee stain texture in background corners
Style: Professional print-quality infographic, vector-style icons, clear
hierarchy, readable at A4 size.
Typography: Clean sans-serif headings, readable body text, clear visual
hierarchy between title, section headers, and explanatory text.
No watermarks. No stock photo elements. Original illustration only.Dla gęstego tekstu i złożonych układów, zawsze używaj quality="high", aby zapewnić, że tekst pozostanie ostry i czytelny.
Projektowanie Logo i Marki
Generowanie logo wymaga priorytetyzowania prostoty i skalowalności. Świetne logo działa w każdym rozmiarze, od malutkiej ikony favicon po ogromny billboard. Oto jak prosić o projekty, które faktycznie funkcjonują jako loga.
Create an original logo for "Field & Flour" — a local artisan bakery.
Brand personality: Warm, authentic, handcrafted, timeless. Not trendy or corporate.
Design requirements:
- Clean vector-style shapes with strong silhouette
- Balanced negative space
- Must read clearly from 16px favicon to large signage
- Flat design, minimal strokes, no gradients unless essential
- Earth-tone palette: warm wheat gold, deep brown, cream
- Could incorporate subtle wheat or grain element
- Text must be perfectly legible and properly kerned
Output: Single centered logo on plain cream background. Generous padding around
the design for flexibility.
No watermarks, no mockups, no 3D effects, no complex imagery. Simple, functional,
timeless design.Użyj n=4, aby wygenerować wiele wariacji. Projektowanie logo jest subiektywne — daj sobie opcje do wyboru.
Makiety UI i Aplikacji
Dla projektowania UI, opisz interfejs tak, jakby już istniał i był dostarczany do prawdziwych użytkowników. Język concept art produkuje concept art. Język produktu produkuje używalne makiety.
Create a realistic mobile app UI mockup for a local farmers market app.
Screen content (from top):
- Simple header with market name "Riverside Market" and search icon
- Today's featured vendor carousel with square photos
- "Fresh Today" section with produce category chips (Vegetables, Fruits, Dairy, Baked)
- Vendor list with small photos, names, specialties, and distance
- Bottom navigation: Home, Map, Favorites, Cart, Profile
Design language:
- White background, subtle natural green accents
- Clear typography hierarchy (system fonts feel)
- Generous padding and touch-friendly targets
- Looks like a real shipped product, not a concept
- Uses realistic vendor names and produce photos
Frame: Place the UI inside an iPhone 15 Pro device frame, slight perspective
tilt, subtle shadow beneath.Skup się na układzie, hierarchii, odstępach i realistycznych elementach interfejsu. Unikaj języka konceptualnego lub artystycznego.
Komiksy i Sztuka Sekwencyjna
Tworzenie wielopanelowych komiksów wymaga zdefiniowania narracji jako sekwencji jasnych bitów wizualnych, po jednym na panel. Utrzymuj opisy konkretne i skoncentrowane na akcji.
Create a 4-panel vertical comic strip. Equal panel sizes, clear panel borders.
Panel 1: Pet owner walks out the front door, keys in hand. Through the window
behind them, we see their cat watching — paws pressed against glass, eyes wide
with apparent sadness. The house suddenly feels empty.
Panel 2: The door clicks shut. The cat slowly turns away from the window toward
the empty house. Its posture shifts from forlorn to interested. Eyes narrow with
possibility.
Panel 3: Total chaos. Cat sprawled across the forbidden couch like royalty.
Knocked over plant on the floor. Papers scattered. Sunbeam spotlighting the
scene of domestic crime.
Panel 4: Door handle turns. Cat sits perfectly upright by the entrance,
composed and innocent, tail wrapped neatly around paws. Not a hair out of
place. As if nothing happened.
Style: Warm illustrated style with expressive characters, clear visual
storytelling that reads without text. Consistent character design across
all panels.
No speech bubbles or text. Let the visuals tell the story.Zdefiniuj każdy panel jako odrębny bit wizualny z jasną akcją. Model zajmuje się układem paneli i ciągłością wizualną.
Ilustracje do Książek dla Dzieci
Ilustracja książki dla dzieci wymaga specyficznego podejścia: zapadającego w pamięć projektu postaci, ciepłego, przystępnego stylu i kompozycji, które współpracują z nakładkami tekstowymi.
Create a children's book illustration introducing the main character.
Character: Young forest hero, around 8 years old.
- Green hooded tunic (think woodland adventurer, not Robin Hood)
- Soft brown boots, well-worn
- Small belt pouch for collecting treasures
- Carries a tiny wooden bow (symbolic, for helping not hurting)
- Kind expression, bright curious eyes, brave but gentle demeanor
- Slightly oversized head for picture book proportions
Theme: This character protects and rescues small forest animals in trouble.
Style: Hand-painted watercolor look with soft outlines, warm earthy palette
with forest greens and autumn oranges. Whimsical, friendly, inviting for
young readers ages 4-8.
Composition: Character standing in simple forest glade, dappled sunlight,
leaving room for title text above. Character clearly showcased.
Original character design only. No text. No watermarks. No copyrighted
character references.Zapisz ten obraz referencyjny postaci — użyjesz go do utrzymania spójności w kolejnych ilustracjach.
Wykorzystanie Wiedzy o Świecie
Jedną z najbardziej niedocenianych możliwości GPT Image 1.5 jest jego wbudowana wiedza o świecie. Model może wnioskować o kontekście z subtelnych wskazówek, generując obrazy historycznie i kulturowo poprawne bez wyraźnych instrukcji.
Create a realistic outdoor crowd scene in Bethel, New York on August 16, 1969.
Photorealistic, period-accurate clothing, staging, and environment.
Documentary photography style, shot on film, natural lighting.Model wie, że to Woodstock bez mówienia mu tego. Generuje hipisów, modę z epoki, atmosferę festiwalu — wszystko tylko na podstawie daty i lokalizacji.
Ta wiedza o świecie rozciąga się na architekturę przez epoki, modę przez dekady, wydarzenia kulturalne, punkty orientacyjne, ruchy artystyczne, a nawet specyficzną estetykę fotograficzną. Gdy dokładność ma znaczenie, podanie czasu i miejsca często daje lepsze wyniki niż długie opisy tego, co spodziewasz się zobaczyć.
Sztuka Precyzyjnej Edycji
Generowanie tekst-na-obraz jest imponujące, ale edycja obrazów to miejsce, gdzie GPT Image 1.5 naprawdę błyszczy. Możliwość precyzyjnego modyfikowania istniejących obrazów przy jednoczesnym zachowaniu wszystkiego innego otwiera profesjonalne przepływy pracy, które wcześniej były niemożliwe bez eksperckich umiejętności w Photoshopie.
Złota Zasada Edycji
Każda udana edycja podąża za tym samym wzorcem: wyraźnie określ co się zmienia, wyraźnie określ co pozostaje takie samo. Brzmi to oczywiście, ale poziom wymaganej specyficzności jest większy niż większość ludzi zdaje sobie sprawę.
Zawsze strukturyzuj prompty edycyjne jako: "Change ONLY [X]. Preserve EXACTLY: [comprehensive list of everything else]." Następnie powtarzaj swoją listę zachowania przy każdej edycji uzupełniającej, aby zapobiec stopniowemu dryfowaniu od oryginału.
Wirtualna Przymierzalnia Odzieży
E-commerce jest transformowany przez możliwości wirtualnych przymierzalni AI. Oto struktura promptu, której używam do zamiany odzieży, która idealnie zachowuje tożsamość.
Edit the image to dress this person in the provided clothing items.
MUST PRESERVE (do not change in any way):
- Face, facial features, expression, skin tone
- Body shape, proportions, and pose
- Hairstyle and hair color
- Background and environment
- Camera angle, framing, and composition
- Overall lighting direction and quality
CHANGE ONLY:
- Replace current clothing with provided garment images
- Fit garments naturally to body geometry
- Show realistic fabric draping, folds, and behavior
- Match lighting and shadows on fabric to original photo
REQUIREMENTS:
- Photorealistic integration — outfit should look worn, not pasted
- Maintain color temperature of original image
- No accessories, text, logos, or watermarks added
- Identity must remain clearly recognizableDla wirtualnej przymierzalni zawsze używaj input_fidelity="high", aby zapewnić zachowanie podobieństwa twarzy.
Transfer Stylu
Transfer stylu bierze język wizualny z jednego obrazu — jego paletę, fakturę, pociągnięcia pędzla, estetykę — i stosuje go do nowej treści. Jest to nieocenione dla utrzymania spójności marki lub tworzenia spójnych serii.
Using the EXACT visual style of the reference image (Image 1), create:
A man riding a motorcycle on a winding mountain road.
STYLE ELEMENTS TO MATCH PRECISELY from reference:
- Color palette and saturation levels
- Line quality and weight
- Texture treatment and brushwork
- Lighting style and direction
- Level of detail vs. abstraction
- Overall artistic aesthetic
APPLY TO NEW CONTENT:
- Single subject (man on motorcycle)
- Clear composition with visual interest
- Mountain road environment with curves
- Sense of motion and freedom
The new image should look like it came from the same artist or series as
the reference. Maintain stylistic consistency exactly.Transfer stylu działa najlepiej, gdy jesteś konkretny co do tego, które elementy stylu zachować, a które elementy treści zmienić.
Zamiana Obiektów
Zamiana obiektów przy zachowaniu fotorealizmu jest teraz praktyczna. Sekret tkwi w opisaniu nie tylko tego, co dodać, ale jak powinno się to integrować z istniejącą sceną.
In this room photo, replace ONLY the white plastic chairs with
mid-century modern wooden chairs (walnut finish, tapered legs,
woven seat).
PRESERVE COMPLETELY:
- Camera angle and perspective
- Room lighting direction and quality
- All other furniture and objects
- Wall colors and decorations
- Floor material and shadows
- Overall image quality and color grading
INTEGRATION REQUIREMENTS:
- Chairs must match room's perspective exactly
- Wood grain should catch existing light realistically
- Contact shadows must be natural and match light source
- Scale must be accurate relative to table height
- New chairs should look like they belong in this room
Photorealistic result — should look like the original photograph.Wizualizacja projektowania wnętrz jest jedną z najbardziej wartościowych komercyjnie aplikacji edycji.
Szkic do Fotorealistycznego Renderu
Przekształcanie szorstkich szkiców w dopracowane rendery jest niezwykle przydatne w projektowaniu produktów, architekturze i rozwoju koncepcji. Prompt musi traktować szkic jako specyfikację do naśladowania.
Transform this hand-drawn sketch into a photorealistic image.
PRESERVE FROM SKETCH:
- Exact layout and proportions
- Perspective and viewing angle
- Element placement and relationships
- Implied depth and layering
ADD FOR REALISM:
- Appropriate real-world materials and textures
- Consistent natural lighting (interpret from sketch shading)
- Environmental context matching the implied setting
- Surface imperfections and wear appropriate to materials
CONSTRAINTS:
- Do not add new elements not present in sketch
- Do not add text or watermarks
- Treat the sketch as an architectural blueprint to follow exactly
- Fill in realistic details while honoring the original compositionModel interpretuje intencję szkicu i wypełnia realistycznymi detalami, zachowując oryginalną kompozycję.
Transformacja Oświetlenia i Pogody
Zmiana warunków środowiskowych przy zachowaniu geometrii sceny to jedna z moich ulubionych aplikacji edycji. Idealne do tworzenia wariantów sezonowych, alternatyw pory dnia lub dostosowań nastroju.
Transform this daytime summer scene into a winter evening with snowfall.
CHANGE:
- Time of day: from afternoon to dusk (warm interior lights visible)
- Season: summer to deep winter
- Weather: clear to active snowfall
- Ground: grass to fresh snow coverage
- Trees: summer foliage to bare branches with snow
- Atmosphere: add visible breath if people present
- Surfaces: add frost on windows and metal
PRESERVE:
- Camera position and angle exactly
- All objects and their exact positions
- Architecture and structural elements
- People and their poses (update clothing appropriately)
- Overall composition and framing
Style: Photorealistic, natural atmospheric perspective, visible
snowflakes in air, cozy contrast between warm interior lights and
cold exterior. Should feel photographed, not filtered.Użyj input_fidelity="high" i quality="high" dla najlepszych rezultatów transformacji środowiskowych.
Kompozycja Wieloobrazowa
Łączenie elementów z wielu obrazów źródłowych wymaga jasnych instrukcji dotyczących tego, co skąd pochodzi i jak elementy powinny się bezproblemowo integrować.
I'm providing 2 images:
- Image 1: Beach scene with woman standing on shore at sunset
- Image 2: Golden retriever sitting in a studio setting
Task: Place the dog from Image 2 into the beach scene from Image 1,
positioned next to the woman, looking up at her.
MATCHING REQUIREMENTS:
- Dog's lighting must match beach sunset (warm golden light from left)
- Scale dog appropriately relative to woman's height
- Dog should cast shadow consistent with scene's sun angle
- Sand texture should show around and under dog's paws
- Fur should catch the same golden hour highlights as scene
PRESERVE FROM IMAGE 1:
- Woman's exact appearance, position, and pose
- Beach background completely unchanged
- Original photo's color grading and mood
The composite should look like a single photograph taken on location.
No visible compositing artifacts.Odwołuj się do obrazów numerami i bądź wyraźny co do tego, które elementy się przenoszą, a które pozostają stałe.
Tłumaczenie Tekstu na Obrazach
Lokalizacja treści wizualnych na rynki międzynarodowe jest dramatycznie uproszczona dzięki możliwościom tekstowym GPT Image 1.5.
Translate all text in this infographic from English to Japanese.
MUST PRESERVE:
- Exact layout, spacing, and positioning of all elements
- All visual elements, icons, illustrations, and graphics
- Typography hierarchy (headlines vs body text relationships)
- Color scheme and overall design aesthetic
- Font weights and relative sizes
TRANSLATION REQUIREMENTS:
- Accurate Japanese translation with natural phrasing
- Match visual weight and style to original fonts
- Adjust character spacing for Japanese typographic norms
- No text truncation or overflow outside original bounds
Do not modify any non-text elements. Only change the language.Ten przepływ pracy obsługuje materiały marketingowe, zrzuty ekranu UI, opakowania i infografiki bez budowania od zera.
Zaawansowane Techniki dla Profesjonalistów
Kiedy już opanujesz podstawy, te zaawansowane techniki podniosą twoją pracę na prawdziwie profesjonalny poziom. To wzorce, które opracowałem poprzez obszerne eksperymenty — techniki, które konsekwentnie dają lepsze rezultaty.
Spójność Postaci w Obrazach
Jednym z największych wyzwań w generowaniu obrazów AI jest utrzymanie spójności postaci na wielu obrazach. Dla książek dla dzieci, maskotek marek lub każdego projektu wymagającego tej samej postaci w różnych scenach, oto mój sprawdzony przepływ pracy.
Wygeneruj szczegółowy obraz referencyjny, który ustala ostateczny wygląd postaci. Uwzględnij wszystkie kluczowe szczegóły: strój, proporcje, wyraz twarzy, paletę kolorów. Zapisz ten obraz — staje się twoim źródłem prawdy.
Napisz szczegółowy opis tekstowy postaci, do którego będziesz się odwoływać we wszystkich przyszłych promptach. Bądź konkretny co do każdego elementu wizualnego. Ta kotwica tekstowa uzupełnia wizualną.
Podczas tworzenia nowych scen, zawsze dołączaj obraz kotwicy jako wejście i wyraźnie instruuj "maintain exact character appearance from reference image".
Model zachowuje kontekst w ramach sesji konwersacji. Buduj na udanych obrazach zamiast zaczynać od nowa dla każdej sceny. Odwołuj się bezpośrednio do poprzednich generacji.
Continue the children's book story using the character from the reference image.
New Scene:
The same young forest hero is gently helping a frightened squirrel out
of a fallen hollow tree after a winter storm. Snow on the ground, bare
branches above, warm light filtering through clouds.
CHARACTER CONSISTENCY (from reference):
- Same green hooded tunic, exact shade and style
- Same soft brown boots
- Same belt pouch
- Same facial features, proportions, and color palette
- Same gentle, heroic personality in expression
- Same children's book proportions
STYLE CONSISTENCY (from reference):
- Same watercolor illustration style
- Same soft outlines
- Same warm earthy color treatment
- Same whimsical, friendly aesthetic
New elements: winter forest environment, frightened squirrel, fallen
tree with hollow.
Do not redesign the character. Do not change the artistic style.
No text. No watermarks.Odwołuj się do obrazu kotwicy i powtarzaj kluczowe szczegóły postaci, aby zachować spójność w całej książce.
Technika Stylizowanego Portretu 3D
Tworzenie hiper-stylizowanych portretów 3D ze zdjęć referencyjnych stało się jednym z moich popisowych wyników. Kluczem jest ekstremalna specyficzność co do pożądanej estetyki.
Create a hyper-stylized 3D floating head portrait based on this person.
STYLE CHARACTERISTICS:
- Smooth skin with glossy vinyl-finish surface
- Strong highlighter on cheekbones and nose tip catching soft light
- Holographic, iridescent eyeshadow (purple to teal color shift)
- Thick hair sculpted in slick, glossy waves like polished acrylic
- Small metallic chrome nose piercing with brushed reflections
EXPRESSION:
- Confident, slightly unimpressed look — half-lidded eyes, subtly
arched brow, the sophisticated "too cool" attitude.
TECHNICAL SPECIFICATIONS:
- Head floats isolated against plain white background
- Slight 15-degree tilt (premium product render feeling)
- Bright, diffuse studio lighting with no harsh shadows
- Emphasis on glossy, plastic, subsurface scattering effects
- Ultra-smooth textures throughout
- Close-up portrait angle, straight-on, 85mm lens feel
The result should look like a high-end 3D character render or
collectible figure — plastic perfection with personality.Ten poziom szczegółowości estetycznej daje niezwykle spójne wyniki dla różnych obiektów.
Transformacja Postaci Chibi
Konwersja zdjęć na urocze postacie w stylu chibi działa zaskakująco dobrze dla maskotek marek, awatarów w mediach społecznościowych i gadżetów.
Transform this person into an adorable chibi-style character.
CHIBI PROPORTIONS:
- Tiny body (about 1 head-height tall)
- Oversized head (3x body proportions)
- Large, sparkling eyes with cute highlights
- Soft, rounded facial features
- Cheerful, expressive pose with personality
PRESERVE FROM ORIGINAL:
- Recognizable facial features (simplified but identifiable)
- Hairstyle, length, and hair color
- Distinctive clothing style or accessories
- Any notable characteristics (glasses, jewelry, etc.)
- Overall personality and vibe
STYLE:
- Smooth pastel shading
- Clean lines and simplified details
- Bright, expressive colors
- Collectible figure aesthetic
Background: Simple gradient or plain color to showcase character.
The result should feel like an irresistible chibi mascot that
clearly represents the original person.Transformacje Chibi sprawdzają się dobrze w brandingu osobistym, awatarach zespołowych i projektach gadżetów.
Kreacje Marketingowe z Idealnym Tekstem
Tworzenie materiałów marketingowych z dokładnym tekstem wymaga ścisłej kontroli typografii i wyraźnych specyfikacji tekstowych.
Create a realistic highway billboard mockup featuring this product.
BILLBOARD CONTENT:
- Product bottle prominently displayed on left third
- Main headline on right (EXACT TEXT, render verbatim):
"Fresh & Clean — Every Day"
- Tagline below headline: "Nature's Best Ingredients"
- Small logo placeholder area in bottom right corner
TYPOGRAPHY SPECIFICATIONS:
- Headline: Bold sans-serif, white text, high contrast
- Tagline: Light sans-serif, slightly smaller, same white
- Clean kerning, centered alignment within text area
- Text appears EXACTLY ONCE — no duplicates anywhere
SCENE:
- Billboard on highway overpass or roadside structure
- Sunset lighting creating warm, appealing atmosphere
- Photorealistic environment with motion-blurred vehicles below
- Professional advertising photography feel
No watermarks. No additional marketing copy. No logos unless
specified. Text must be perfectly legible and correctly spelled.Zawsze używaj quality="high" dla materiałów marketingowych z tekstem. Sprawdź pisownię przed ostatecznym użyciem.
Ekstrakcja Fotografii Produktowej
Tworzenie czystych ujęć produktów z odizolowanymi przedmiotami jest niezbędne dla e-commerce. Oto prompt, który działa.
Extract the product from this image for e-commerce use.
OUTPUT SPECIFICATIONS:
- Transparent background (RGBA PNG format)
- Crisp silhouette with clean edges
- No halos or color fringing around product
- All product labels and text perfectly preserved
- Exact product geometry and proportions maintained
OPTIONAL ENHANCEMENT:
- Add subtle, realistic contact shadow
- Shadow should be soft and natural, no hard edges
- Shadow works with the transparent background
CRITICAL CONSTRAINTS:
- Do NOT restyle or recolor the product
- Do NOT modify product appearance in any way
- Only remove background and add optional shadow
- Preserve every detail of the original product exactlyUwaga: Obecny model renderuje wzór szachownicy dla przezroczystości — może wymagać post-processingu dla prawdziwego kanału alfa.
Znane Ograniczenie
Usuwanie tła obecnie renderuje wizualny wzór szachownicy, aby wskazać przezroczystość, zamiast tworzyć prawdziwą przezroczystość RGBA w pliku wyjściowym. Do użytku produkcyjnego może być konieczne przetworzenie wyjścia w celu konwersji szachownicy na rzeczywistą przezroczystość przy użyciu oprogramowania do edycji obrazu.
Pętla Iteracyjnego Udoskonalania
Nie próbuj osiągnąć perfekcji w jednym prompcie. Profesjonalne wyniki pochodzą z systematycznej iteracji.
Proces Udoskonalania
- Generuj: Stwórz początkowy obraz z głównymi elementami i ogólną kompozycją
- Oceniaj: Zidentyfikuj 1-2 najważniejsze problemy do rozwiązania w pierwszej kolejności
- Dopracuj: Napraw tylko te konkretne problemy, wyraźnie zachowując wszystko inne
- Zablokuj: Zapisz bieżący stan przed próbą kolejnej iteracji
- Powtórz: Kontynuuj aż do zadowolenia, budując stopniowo
Każda mała, skoncentrowana zmiana sumuje się w precyzyjne wyniki końcowe ze znacznie mniejszą frustracją niż próba zrobienia wszystkiego naraz.
Profesjonalne Przepływy Pracy w Rzeczywistym Świecie
Teoria jest cenna, ale zobaczenie, jak techniki łączą się w kompletne przepływy pracy, to moment, w którym zrozumienie krystalizuje się. Oto przepływy pracy, których używam najczęściej w praktyce zawodowej.
Rurociąg Fotografii Produktowej E-Commerce
Kompletny System Wizualny Produktu
- Ekstrakcja produktu: Usuń tła z surowych zdjęć produktów, stwórz czyste, izolowane ujęcia
- Konteksty lifestyle: Generuj sceny środowiskowe (kuchnia, biuro, plener) i komponuj w nich produkty
- Warianty kolorystyczne: Twórz wariacje kolorystyczne produktów poprzez ukierunkowaną edycję bez ponownego fotografowania
- Kreacje marketingowe: Generuj makiety billboardów, grafiki do mediów społecznościowych, reklamy banerowe z integracją produktu
- Lokalizacja: Tłumacz tekst w materiałach marketingowych na różne rynki, zachowując projekt
Kompletny rurociąg fotografii produktowej, który wcześniej wymagał czasu w studiu, ekspertyzy Photoshopa i wielu specjalistów, teraz działa poprzez serię promptów AI.
Biblioteka Wizualna Twórcy Treści
Budowanie Spójnych Zasobów Marki
- Rozwój postaci: Stwórz maskotkę marki lub osobistego awatara ze szczegółowym obrazem kotwicą
- Generowanie przewodnika stylu: Produkuj referencje palety kolorów, tablice nastrojów i przykłady estetyczne
- Fabryka miniatur: Generuj spójne miniatury YouTube/social media używając ustalonej postaci i stylu
- Biblioteka tła: Twórz tła scen pasujące do estetyki marki dla różnych typów treści
- Ekspansja wariacji: Używaj transferu stylu, aby zachować spójność wizualną we wszystkich nowych treściach
Zbuduj swoje fundamenty wizualne raz, a potem iteruj efektywnie. Tworzy rodzaj spójności marki, który wcześniej wymagał dedykowanego zespołu projektowego.
Szybkie Prototypowanie Projektu
Od Koncepcji do Wizualizacji w Minuty
- Szorstki szkic: Narysuj ręcznie podstawową koncepcję (jakość serwetkowa jest w porządku — zgrubne kształty i układ)
- Wstępny render: Konwertuj szkic na fotorealistyczny lub stylizowany obraz zachowując kompozycję
- Cykl iteracji: Dopracuj poprzez ukierunkowane edycje ("cieplejsze oświetlenie", "inny materiał", "większy kontrast")
- Eksploracja wariantów: Wygeneruj wiele wariacji (n=4) do prezentacji klientowi lub podejmowania decyzji
- Ostateczny szlif: Eksport wysokiej jakości wybranego kierunku z dopracowanymi detalami
Projektanci zgłaszają dramatycznie szybszą iterację koncepcji w porównaniu z tradycyjnymi cyfrowymi przepływami pracy twórczej.
Rurociąg Ilustracji Książek dla Dzieci
Tworzenie Spójnych Książek Ilustrowanych
- Projekt postaci: Stwórz szczegółowy arkusz referencyjny postaci ustalający ostateczny wygląd
- Ustalenie stylu: Wygeneruj 2-3 strony próbne, aby zablokować styl ilustracji, wybierz najlepszy
- Generowanie scena po scenie: Pracuj nad historią strona po stronie, zawsze odwołując się zarówno do postaci, jak i kotwic stylu
- Przegląd spójności: Zobacz wszystkie strony razem, użyj edycji, aby naprawić wszelkie odchylenia postaci lub niespójności stylu
- Ostateczne dopracowanie: Wypoleruj poszczególne strony w razie potrzeby, zachowując ustalony wygląd
Podejście oparte na obrazie kotwicy sprawia, że spójna ilustracja postaci w całej książce jest autentycznie osiągalna.
Błędy, Które Zabijały Moje Wyniki
Po obserwowaniu siebie i niezliczonych innych zmagających się z generowaniem obrazów AI, zidentyfikowałem wzorce, które oddzielają sukces od frustracji. Oto błędy, które popełniałem — i jak je naprawiłem.
❌ Upychanie Słów Kluczowych
Błąd: Dodawanie "highly detailed, 8K, photorealistic, trending on ArtStation, masterpiece" do każdego pojedynczego promptu.
Rozwiązanie: Opisz zamiast tego konkretne właściwości wizualne. "Widoczne pory skóry, poranne światło z okna, głębia ostrości obiektywu 50mm" komunikuje znacznie więcej niż ogólne słowa kluczowe jakości.
❌ Mega-Prompt
Błąd: Próba określenia każdego możliwego szczegółu w jednym masywnym prompcie, z nadzieją, że model jakoś domyśli się mojej kompletnej wizji.
Rozwiązanie: Zacznij prosto. Najpierw uzyskaj solidny obraz bazowy, a potem dopracuj go ukierunkowanymi promptami uzupełniającymi. Budowanie przyrostowe daje znacznie lepsze wyniki.
❌ Niejasne Instrukcje Edycji
Błąd: Mówienie "zrób to lepiej" lub "napraw oświetlenie" bez określenia, co oznacza "lepiej" lub jak oświetlenie powinno się zmienić.
Rozwiązanie: Bądź konkretny co do zmiany. "Przesuń oświetlenie z ostrego górnego na miękkie światło z okna z lewej strony, z cieplejszą temperaturą barwową."
❌ Zapominanie o Liście Zachowania
Błąd: Żądanie zmian bez wyraźnego określenia, co powinno pozostać niezmienione, a następnie zdziwienie, gdy inne elementy dryfują.
Rozwiązanie: Każdy prompt edycji zawiera wyraźne wymagania zachowania. Powtarzaj je przy każdej iteracji, ponieważ model nie pamięta poprzednich ograniczeń.
❌ Amnezja Kontekstu
Błąd: Rozpoczynanie nowych konwersacji dla powiązanych obrazów, tracąc cały zbudowany kontekst i spójność.
Rozwiązanie: Buduj w ramach sesji dla powiązanej pracy. Odwołuj się bezpośrednio do poprzednich generacji. Używaj fraz takich jak "ten sam styl co poprzedni obraz", aby wykorzystać kontekst.
❌ Złe Ustawienia Jakości
Błąd: Zawsze używanie wysokiej jakości (wolne i drogie przy iteracji) lub zawsze używanie niskiej jakości (brak kluczowych detali, gdy to ważne).
Rozwiązanie: Dopasuj ustawienia do zadania. Niska jakość do eksploracji i iteracji; wysoka jakość do wyników końcowych i wszystkiego z tekstem.
❌ Walka z Modelem
Błąd: Uruchamianie dokładnie tego samego promptu wielokrotnie, oczekując innych wyników, lub wymuszanie kierunku, któremu model konsekwentnie się opiera.
Rozwiązanie: Jeśli prompt nie działa, sformułuj go inaczej zamiast powtarzać. Inne słowa aktywują inne wzorce. Czasami twoje podejście musi się zmienić, nie tylko wynik modelu.
❌ Ignorowanie Stochastyczności
Błąd: Oczekiwanie identycznych wyników z identycznych promptów, frustracja, gdy wyniki się różnią.
Rozwiązanie: Wygeneruj wiele wariacji (n=4) i wybierz najlepszą. Zaakceptuj zmienność jako źródło kreatywnych opcji, a nie wadę do pokonania.
Pojedyncza najbardziej wpływowa zmiana, jaką większość ludzi może wprowadzić: przestań traktować prompty jak życzenia i zacznij traktować je jak specyfikacje. Bądź tak precyzyjny, jak byłbyś w briefie projektowym dla ludzkiego współpracownika. Model jest niezwykle zdolny — ale potrzebuje jasnego kierunku, aby pokazać te możliwości.
Integracja API dla Programistów
Jeśli integrujesz GPT Image 1.5 w aplikacjach programistycznie, oto szczegóły techniczne i najlepsze praktyki, których potrzebujesz.
Podstawowa Konfiguracja API
import os
import base64
from openai import OpenAI
client = OpenAI()
# Create output directory
os.makedirs("output_images", exist_ok=True)
def save_image(result, filename: str) -> None:
"""Save base64 image response to file."""
image_base64 = result.data[0].b64_json
with open(f"output_images/{filename}", "wb") as f:
f.write(base64.b64decode(image_base64))
# Basic text-to-image generation
result = client.images.generate(
model="gpt-image-1.5",
prompt="Your detailed prompt here",
quality="high", # or "low" for faster iteration
n=1 # number of variations
)
save_image(result, "output.png")Edycja Obrazu z Wieloma Wejściami
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # Essential for identity preservation
quality="high",
image=[
open("input_images/source.png", "rb"),
open("input_images/style_reference.png", "rb"),
],
prompt="""
Apply the artistic style from Image 2 to the subject in Image 1.
PRESERVE: subject's identity, pose, and composition
CHANGE: artistic style, color palette, texture treatment
Do not add new elements. Maintain subject likeness exactly.
"""
)
save_image(result, "styled_output.png")Kluczowe Parametry API
Parametry Generowania
model
"gpt-image-1.5" — najnowszy flagowy model z najlepszymi możliwościami
prompt
Twój opis tekstowy — struktura ma większe znaczenie niż długość
quality
"high" (wysoka) dla szczegółów i pracy z tekstem, "low" (niska) dla szybkości i iteracji
n
Liczba wariacji do wygenerowania (typowo 1-4, więcej dla eksploracji)
Parametry Edycji
image
Obiekt pliku lub lista obiektów plików dla wejść wieloobrazowych
input_fidelity
"high" (wysoka) dla zachowania tożsamości, krytyczne dla pracy portretowej
Rozważania Cenowe
Struktura Kosztów API
- Ceny oparte na tokenach: Koszty skalują się z rozdzielczością i ustawieniami jakości
- 1MP wysoka jakość: Około $133 za 1,000 obrazów
- 1MP niska jakość: Około $9 za 1,000 obrazów
- Oszczędności kosztów: Koszty wejścia/wyjścia obrazu są o 20% niższe niż w GPT Image 1
Dla aplikacji o dużej objętości, zawsze zaczynaj od niskiej jakości i aktualizuj tylko dla ostatecznych wyników lub obrazów z dużą ilością tekstu.
Jak Wypada na Tle Innych Narzędzi
Spędziłem dużo czasu z każdym głównym narzędziem do generowania obrazów AI. Oto moja szczera ocena tego, jak generator obrazów ChatGPT (GPT Image 1.5) wypada na tle konkurencji.
GPT Image 1.5 vs Gemini 3.0 Pro Image
GPT Image 1.5 wygrywa: Zgodność z instrukcjami (90% vs 77%), dokładność renderowania tekstu, precyzyjna edycja, jakość integracji API
Gemini 3.0 Pro wygrywa: Ogólna jakość obrazu w niektórych benchmarkach, kreatywna interpretacja, złożone sceny wielopostaciowe
Moje zdanie: GPT Image 1.5 do pracy profesjonalnej wymagającej precyzji i spójności; Gemini do kreatywnej eksploracji, gdzie chcesz więcej interpretacji
GPT Image 1.5 vs Midjourney
GPT Image 1.5 wygrywa: Podążanie za instrukcjami, możliwości edycji obrazu, dostęp do API, renderowanie tekstu, przewidywalne wyniki
Midjourney wygrywa: Artystyczna estetyka i "efekt wow", funkcje społecznościowe i udostępniania, style malarskie
Moje zdanie: GPT Image 1.5 do pracy profesjonalnej/komercyjnej, gdzie potrzebujesz konkretnych wyników; Midjourney do eksploracji artystycznej i concept artu
GPT Image 1.5 vs DALL-E 3
GPT Image 1.5 wygrywa: Możliwości edycji, szybkość (4x szybciej), spójność w iteracjach, zgodność z instrukcjami
DALL-E 3 wygrywa: Nic znaczącego — GPT Image 1.5 jest następcą i poprawia każdy wymiar
Moje zdanie: Jeśli nadal używasz DALL-E 3, zaktualizuj natychmiast. GPT Image 1.5 jest ściśle lepszy.
GPT Image 1.5 vs Stable Diffusion
GPT Image 1.5 wygrywa: Łatwość użycia, brak wymaganej konfiguracji, podążanie za instrukcjami, renderowanie tekstu, stała jakość
Stable Diffusion wygrywa: Pełna personalizacja, kontrola lokalna, nielimitowane darmowe generowanie, dostrajanie, wyspecjalizowane modele
Moje zdanie: GPT Image 1.5 dla szybkości i łatwości; Stable Diffusion dla kontroli, personalizacji i pracy o dużej objętości wrażliwej na koszty
W testach porównawczych GPT Image 1.5 osiągnął 1. miejsce zarówno w kategoriach tekst-na-obraz, jak i edycji obrazu w Artificial Analysis Image Arena. Do pracy produkcyjnej wymagającej niezawodnych, przewidywalnych wyników z precyzyjną kontrolą, jest to obecnie najlepsza dostępna opcja.
Prawdziwa odpowiedź? Najlepsze narzędzie zależy od twoich konkretnych potrzeb. Utrzymuję dostęp do wielu narzędzi, ponieważ każde z nich przoduje w różnych rzeczach. Ale gdybym mógł mieć tylko jedno do pracy profesjonalnej, wybrałbym GPT Image 1.5 ze względu na jego niezawodność, precyzję i możliwości edycji.
Sekrety Power Userów
To są wskazówki, które przeniosły mnie z "całkiem niezłych" do "profesjonalnej jakości" wyników. Każda z nich została nauczona poprzez obszerne eksperymenty i czasami bolesne porażki.
Zaczynaj Świeżo dla Nowych Projektów
Zaczynaj każdy nowy projekt w nowej rozmowie. Kontekst ze starych projektów może przenikać do nowych generacji i powodować nieoczekiwane wyniki. Czysta karta, czyste wyniki.
Reguła 80/20
Uzyskaj 80% poprawności w pierwszej generacji. Użyj edycji dla końcowych 20%. Próba osiągnięcia perfekcji w jednym prompcie prowadzi do frustracji i straty czasu.
Konkret Wygrywa z Superlatywem
"Zrobione na filmie średniego formatu z naturalnym ziarnem" bije "ultra-wysoka jakość niesamowite szczegółowe" za każdym razem. Szczegóły prowadzą model; superlatywy tylko dodają szumu.
Cytuj Swój Tekst
Zawsze umieszczaj wymagany tekst w "cudzysłowie" i określ, że powinien pojawić się "dokładnie raz, bez duplikatów". Zapobiega to duplikacji i błędom ortograficznym, które nękają renderowanie tekstu.
Kończ Negatywami
Kończ każdy prompt tym, czego nie chcesz: "No watermarks, no text unless specified, no logos, no excessive saturation, no artificial bokeh". Zapobieganie bije poprawianie.
Zapisuj Swoich Zwycięzców
Kiedy uzyskasz świetny wynik, zapisz zarówno obraz ORAZ kompletny prompt. Zbuduj osobistą bibliotekę sprawdzonych promptów, które możesz dostosować do przyszłych projektów.
Przeformułuj, Nie Powtarzaj
Jeśli prompt nie działa, nie uruchamiaj go ponownie, licząc na szczęście. Przeformułuj go. Inne słowa aktywują inne wzorce w modelu. Zmień swoje podejście.
Zawsze Wysoka Jakość dla Tekstu
Kiedykolwiek twój obraz zawiera tekst — jakikolwiek tekst — używaj trybu wysokiej jakości. Tekst niskiej jakości jest często nieczytelny, co sprawia, że oszczędności prędkości są bezwartościowe.
Zrozumienie Stochastyczności
Oto coś kluczowego: generowanie obrazów AI jest fundamentalnie stochastyczne. Ten sam prompt może dawać różne wyniki za każdym razem. To nie jest błąd — to natura technologii.
Zaakceptuj Zmienność
Zamiast walczyć z losowością, użyj jej. Wygeneruj 4 wariacje i wybierz najlepszą. Czasami "nieoczekiwana" interpretacja prowadzi do czegoś lepszego niż to, co pierwotnie sobie wyobrażałeś. Najlepsi artyści AI, których znam, polegają na szczęśliwych wypadkach, zachowując jednocześnie wystarczającą kontrolę, aby osiągnąć swoje cele. Zmienność to cecha, nie wada.
Rozwiązywanie Typowych Problemów
Po tysiącach generacji napotkałem każdy możliwy problem. Oto jak naprawić najczęstsze problemy, które frustrują twórców.
Problem: Tekst Jest Źle Napisany lub Zduplikowany
Rozwiązanie
Umieść dokładny tekst w cudzysłowie: "RESTAURACJA" nie restauracja. Dodaj wyraźną instrukcję: "render exactly once, no duplicates". Dla trudnych słów, przeliteruj litera po literze: "R-E-S-T-A-U-R-A-C-J-A". Zawsze używaj quality="high" dla każdego obrazu zawierającego tekst. Zweryfikuj wyjście przed użyciem.
Problem: Postać Wygląda Inaczej na Obrazach
Rozwiązanie
Najpierw stwórz szczegółowy obraz kotwicy postaci i zapisz go. Dołącz tę kotwicę jako wejście dla każdej kolejnej generacji. Napisz biblię postaci wymieniającą każdy szczegół wizualny. Wyraźnie instruuj "maintain exact character appearance from reference image". Używaj input_fidelity="high" w wywołaniach API. Pracuj w ramach pojedynczych sesji, gdy to możliwe.
Problem: Edycje Zmieniają Więcej Niż Żądano
Rozwiązanie
Bądź bardziej wyraźny w kwestii zachowania. Strukturyzuj prompty jako "Change ONLY: [X]. Preserve EXACTLY: [lista wszystkiego innego w szczegółach]". Powtarzaj pełną listę zachowania przy każdej iteracji edycji — model nie pamięta poprzednich ograniczeń. Używaj input_fidelity="high" dla ważnych elementów.
Problem: Obrazy Wyglądają Oczywiście na "Wygenerowane przez AI"
Rozwiązanie
Dodaj realistyczne niedoskonałości: "subtle film grain", "slight lens vignette", "natural skin texture with pores and subtle blemishes", "dust particles visible in sunbeam", "minor wear on materials". Perfekcja wygląda sztucznie. Rzeczywistość jest bałaganiarska. Opisz to, co aparaty faktycznie chwytają, a nie wyidealizowane wersje.
Problem: Kolory Wyglądają na Zbyt Nasycone lub Nienaturalne
Rozwiązanie
Określ traktowanie kolorów wyraźnie: "natural color grading", "true-to-life colors", "muted earth tones", "not oversaturated", "color-accurate". Odwołuj się do konkretnych taśm filmowych dla wskazówek kolorystycznych: "Kodak Portra color science" lub "documentary color grading". Dodaj "realistic color balance, no HDR look".
Problem: Usuwanie Tła Tworzy Aureole lub Artefakty
Rozwiązanie
Zażądaj wyraźnie: "transparent background (RGBA PNG format), crisp silhouette, no halos, no color fringing, clean edges, no artifacts". Zauważ, że obecny model renderuje wzór szachownicy dla przezroczystości — może być potrzebny post-processing dla prawdziwego kanału alfa w produkcji.
Problem: Kompozycje Wydają Się Niezrównoważone lub Niezręczne
Rozwiązanie
Określ kompozycję wyraźnie: "subject positioned using rule of thirds", "centered with symmetrical framing", "generous negative space on left for text overlay", "eye-level camera angle", "subject fills 60% of frame". Nie zostawiaj kompozycji przypadkowi — opisz dokładnie to, co chcesz.
Przyszłość Generowania Obrazów AI
Żyjemy w trakcie rewolucji. To, co było science fiction dwa lata temu, jest teraz towarem, do którego każdy ma dostęp. Ale wciąż jesteśmy we wczesnych rozdziałach tej historii. Oto co widzę, że nadchodzi.
Co Jest na Horyzoncie
🎬 Płynna Integracja Wideo
Granica między obrazami statycznymi a wideo zaciera się szybko. Spodziewaj się płynnych przejść od generowania obrazów do animowanych sekwencji w tym samym interfejsie. Wczesne wersje już tu są (Sora, Runway) i poprawiają się szybko. Twoje prompty obrazowe staną się promptami wideo przy minimalnej adaptacji.
🎯 Perfekcyjna Spójność
Spójność postaci i stylu w nieograniczonej liczbie obrazów bez ręcznego wysiłku. Przepływ pracy kotwica-i-referencja stanie się automatyczny. Wytrenuj model na kilku przykładach twojej postaci, a on zachowa idealną spójność na zawsze. Problem "dryfowania" zostanie całkowicie rozwiązany.
✏️ Edycja Współpracy w Czasie Rzeczywistym
Interaktywna edycja, gdzie malujesz, przeciągasz i manipulujesz elementami konwersacyjnie w czasie rzeczywistym. Wyobraź sobie Photoshopa, gdzie każde pociągnięcie pędzla wyzwala reakcję AI, a złożone edycje dzieją się poprzez rozmowę zamiast narzędzi technicznych.
🎨 Nauka Osobistego Stylu
Wytrenuj model na swojej estetyce za pomocą garści przykładów. Twój własny osobisty artysta AI, który rozumie twój gust, twoją markę, twój język wizualny — i stosuje go konsekwentnie do wszystkiego, co tworzysz.
Demokratyzacja Twórczości Wizualnej
To, czego jesteśmy świadkami, to nic innego jak demokratyzacja twórczości wizualnej. Umiejętności, które kiedyś wymagały lat szkolenia — fotografia produktowa, projektowanie graficzne, ilustracja, concept art — stają się dostępne dla każdego, kto potrafi opisać to, co chce zobaczyć.
Nie eliminuje to wartości ludzkiej kreatywności. Jeśli już, to ją podnosi. Kiedy wykonanie staje się łatwe, wizja staje się wszystkim. Ludzie, którzy odniosą sukces w tym nowym krajobrazie, nie będą tymi, którzy potrafią wyrenderować najbardziej realistyczne dłonie — AI zajmuje się tym teraz. Będą to ci, którzy mają coś wartego powiedzenia, coś wartego pokazania, coś, co porusza ludzi.
Fotografowie, którzy odnieśli sukces w przejściu z filmu na cyfrę, nie byli tymi, którzy opierali się zmianom. Byli tymi, którzy przyjęli nowe narzędzia, zachowując swoją wizję artystyczną. Generowanie obrazów AI to ten sam rodzaj przejścia, tylko bardziej dramatyczny i szybszy.
Najlepsze obrazy generowane przez AI będą zawsze tworzone przez ludzi, którzy rozumieją zarówno technologię, JAK I sztukę. Opanuj narzędzia, ale nigdy nie zapominaj, że narzędzia służą wizji. Technologia wzmacnia ludzką kreatywność — nie zastępuje jej.
Myśli Końcowe
Miniatury, grafiki i treści społecznościowe w minuty zamiast godzin
Fotografia produktowa, warianty i marketing na niespotykaną skalę
Szybkie koncepcje i prezentacje dla klientów, które zajmowały dni
Solidny dostęp programistyczny do budowania aplikacji obsługujących obrazy
Język naturalny sprawia, że wejście jest łatwiejsze niż w tradycyjnych narzędziach projektowych
Jakość i spójność wystarczająca do pracy komercyjnej
Zacząłem tę podróż sfrustrowany i sceptyczny. Słyszałem szum wokół generowania obrazów AI, ale wielokrotnie uderzałem w ścianę między obietnicami marketingowymi a praktyczną rzeczywistością. Palce o niemożliwej anatomii. Tekst, który topił się w abstrakcyjne kształty. Kompozycje, które aktywnie walczyły z moimi intencjami. Byłem gotów odrzucić to wszystko jako przereklamowaną technologię.
Wtedy nauczyłem się mówić językiem maszyny. Przestałem opisywać to, co chciałem zobaczyć, i zacząłem opisywać to, co uchwyciłby aparat. Przestałem liczyć na szczęście i zacząłem budować systematycznie. Przestałem walczyć z modelem i zacząłem z nim współpracować.
GPT Image 1.5 nie tylko poprawił poprzednie problemy — fundamentalnie zmienił moją relację z twórczością wizualną. Teraz myślę w kategoriach promptów i iteracji, a nie pędzli i warstw. Podchodzę do wyzwań wizualnych z pewnością, że istnieje struktura promptu, która wyprodukuje to, czego potrzebuję. Obrazy, które tworzę dzisiaj, zajęłyby dni zaledwie dwa lata temu. Pomysły, które mogę eksplorować, są ograniczone tylko przez wyobraźnię, nie przez umiejętności techniczne.
Krzywa uczenia się jest prawdziwa. Nie opanujesz tego z dnia na dzień. Ale zasady w tym przewodniku — struktura ponad słowami kluczowymi, specyficzność ponad superlatywami, iteracja ponad perfekcją, mentalność fotografa — skompresują tygodnie frustrujących eksperymentów w ukierunkowaną, produktywną naukę.
Przede wszystkim mam nadzieję, że ten przewodnik da ci to, czego ja bym sobie życzył, gdy zaczynałem: nie tylko techniki, ale model mentalny. Zrozumienie tego, jak ta technologia interpretuje język, na co reaguje i jak płynnie mówić jej wizualnym językiem.
Przepaść między obrazami w twoim umyśle a obrazami na twoim ekranie nigdy nie była mniejsza. A dzięki odpowiedniemu podejściu, ta przepaść zmniejsza się z każdym promptem, który piszesz.
Teraz idź stworzyć coś pięknego.
Pamiętam ten moment o 2 w nocy, kiedy wszystko kliknęło — kiedy obraz, który się pojawił, nie był tylko akceptowalny, ale dokładnie taki, jak sobie wyobraziłem. To uczucie jest dostępne dla ciebie teraz. Technologia nadeszła. Techniki są udokumentowane. Jedyne co zostało, to twoja wyobraźnia i chęć nauczenia się nowego języka. Generator obrazów ChatGPT to nie tylko narzędzie — to kreatywny partner, który wzmacnia ludzką wizję w sposób, który dopiero zaczynamy rozumieć. Witaj w przyszłości twórczości wizualnej. Obrazy, które widziałeś w swoim umyśle? Są bliżej rzeczywistości niż kiedykolwiek były.

Dyskusja
0 komentarzyZostaw komentarz
Bądź pierwszym, który podzieli się swoimi przemyśleniami!