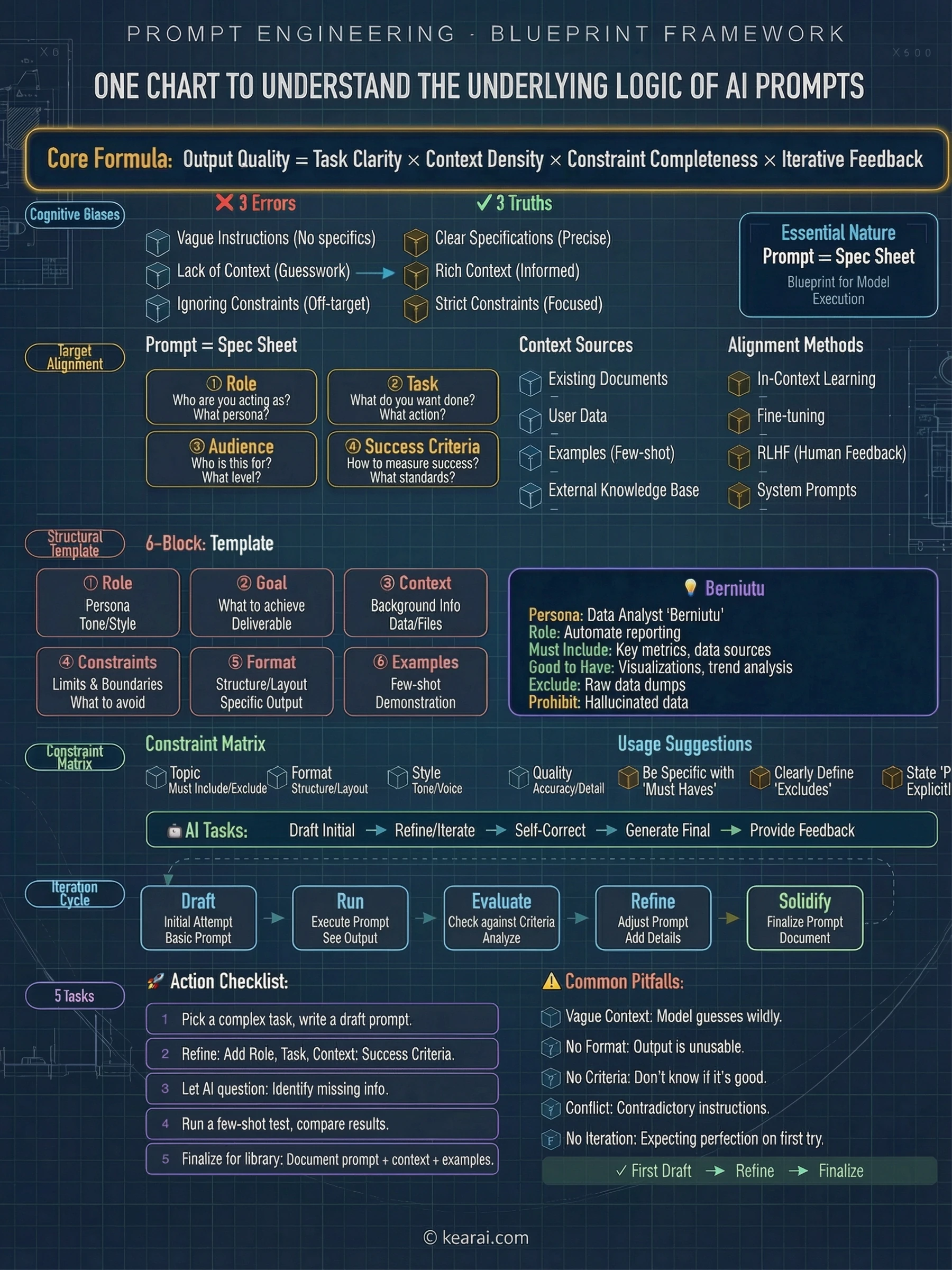
AI ไม่ได้อ่านใจคุณ มันอ่านคำพูดของคุณ คุณภาพของ prompt กำหนดคุณภาพของผลลัพธ์
สองปีก่อน ผมพิมพ์ prompt แรกเข้า ChatGPT และคิดว่าตัวเองเข้าใจปัญญาประดิษฐ์แล้ว ผมคิดผิด สิ่งที่ผมเข้าใจคือวิธีถามคำถาม—ไม่ใช่วิธีสื่อสารกับเครื่องจักรที่คิดด้วย patterns, probabilities และ tokens ความแตกต่างระหว่างสองสิ่งนี้? มันคือความแตกต่างระหว่างการได้คำตอบทั่วไป กับการปลดล็อกความสามารถที่คุณไม่รู้ว่ามีอยู่ นี่คือเรื่องราวของการที่ผมเรียนรู้การพูดคุยกับ AI ได้อย่างคล่องแคล่ว และทุกสิ่งที่ค้นพบตลอดทาง
การตื่นรู้: เมื่อ Prompt ง่ายๆ ใช้ไม่ได้ผล
มันเกิดขึ้นระหว่างใกล้ deadline ของโปรเจกต์ ผมต้องการให้ AI ช่วย refactor โค้ดที่ซับซ้อน—สิ่งที่ผมเคยทำมาเป็นร้อยครั้ง แต่ครั้งนี้ ไม่ว่าผมจะพูดอย่างไร AI ก็ให้คำตอบที่ถูกต้องทางเทคนิคแต่พลาดประเด็นโดยสิ้นเชิง มันเพิ่มความซับซ้อนที่ไม่จำเป็น ทำลาย patterns ที่มีอยู่ "ปรับปรุง" สิ่งที่ไม่ได้เสีย
ผมหงุดหงิด แล้วก็อยากรู้ ผมทำอะไรผิด?
ความหงุดหงิดนั้นนำผมลงไปในโพรงกระต่ายที่เปลี่ยนทุกอย่าง: เอกสารอย่างเป็นทางการ, research papers, prompt engineering guides, และการทดลองหลายพันชั่วโมง สิ่งที่ผมค้นพบไม่ใช่แค่เทคนิคเล็กๆ น้อยๆ—มันคือการเปลี่ยนกระบวนทัศน์ทั้งหมดในการสื่อสารกับระบบ AI
AI ที่ทรงพลังที่สุดในโลกก็ไร้ประโยชน์ถ้าคุณสื่อสารไม่ได้ว่าต้องการอะไรจริงๆ
นี่คือความจริงที่ไม่มีใครบอกมือใหม่: การเขียน prompt ไม่ใช่การหาคำวิเศษ มันคือการเข้าใจว่า AI models ประมวลผลภาษาอย่างไร ต้องการข้อมูลอะไร และจะจัดโครงสร้างข้อมูลอย่างไรเพื่อให้ model ช่วยคุณได้จริง มันเป็นทักษะ—และเหมือนทักษะอื่นๆ มันสามารถเรียนรู้ ฝึกฝน และเชี่ยวชาญได้
คู่มือนี้มีทุกอย่างที่ผมอยากให้ใครสักคนบอกตั้งแต่แรก ไม่ใช่คำแนะนำแบบง่ายเกินไปอย่าง "แค่ให้ละเอียด" ที่เต็มอินเทอร์เน็ต แต่เป็นความเข้าใจลึกซึ้งและละเอียดอ่อนที่แยกคนที่ใช้ AI ออกจากคนที่ใช้ประโยชน์จาก AI
พื้นฐาน Prompt: รากฐานที่ไม่มีใครสอน
ก่อนที่จะลงลึกเทคนิคขั้นสูง มาสร้างพื้นฐานกันก่อน ทุก prompt ที่มีประสิทธิภาพจะมีองค์ประกอบเหล่านี้รวมกัน:
AI ต้องรู้อะไรเกี่ยวกับสถานการณ์? ข้อมูลพื้นหลัง, ข้อจำกัด, และรายละเอียดที่เกี่ยวข้อง
คุณต้องการให้ AI ทำอะไรกันแน่? ระบุ action ที่คุณขอให้ชัดเจน
Output ควรจัดโครงสร้างอย่างไร? Lists, paragraphs, code blocks, tables—ระบุให้ชัด
AI ควรหลีกเลี่ยงอะไร? มีขอบเขตอะไร? อะไรอยู่นอกขอบเขต?
คุณแสดงสิ่งที่ต้องการได้ไหม? ตัวอย่างหนึ่งมีค่าเท่าคำอธิบายพันคำ
คนส่วนใหญ่ใส่แค่ task พวกเขาถามว่า "เขียนอีเมลให้หน่อย" ทั้งที่ควรพูดว่า "เขียนอีเมลมืออาชีพถึงลูกค้าอธิบายการเลื่อนโปรเจกต์ ความยาวไม่เกิน 150 คำ ยอมรับความไม่สะดวก และเสนอ timeline ใหม่ที่เลื่อนออกไปสองสัปดาห์ โทนควรขอโทษแต่มั่นใจ"
ความแตกต่างของคุณภาพ output นั้นมหาศาล และนี่แค่จุดเริ่มต้น
บทบาทของโครงสร้าง
หนึ่งในแง่มุมที่ถูกมองข้ามมากที่สุดของการเขียน prompt คือการจัดรูปแบบเชิงโครงสร้าง AI models สมัยใหม่ตอบสนองได้ดีเป็นพิเศษกับส่วนที่แบ่งชัดเจน ผมใช้ XML-style tags อย่างกว้างขวาง:
<context>
คุณกำลังช่วยผมเตรียม presentation สำหรับ technical stakeholders
ผู้ชมคุ้นเคยกับ software development แต่ไม่ใช่ AI โดยเฉพาะ
</context>
<task>
อธิบายว่า large language models ทำงานอย่างไรใน 5 ประเด็นหลัก
</task>
<format>
- ใช้ bullet points
- แต่ละประเด็น 1-2 ประโยค
- หลีกเลี่ยงศัพท์เทคนิค หรือนิยามเมื่อใช้
</format>
<constraints>
- อย่าพูดถึงชื่อ model เฉพาะ
- เน้นแนวคิด ไม่ใช่ technical implementation
</constraints>โครงสร้างนี้ทำสิ่งที่ทรงพลัง: มันบังคับให้คุณคิดชัดเจนว่าต้องการอะไรก่อนที่จะถาม และความคิดที่ชัดเจนสร้างการสื่อสารที่ชัดเจนสร้างผลลัพธ์ที่ชัดเจน
Agentic Workflows: ปฏิบัติต่อ AI เหมือนเพื่อนร่วมงาน
นี่คือการเปลี่ยนกระบวนทัศน์ที่เปลี่ยนวิธีที่ผมโต้ตอบกับ AI: หยุดปฏิบัติต่อ AI เหมือน search engine และเริ่มปฏิบัติต่อมันเหมือนเพื่อนร่วมงานที่มีความสามารถแต่ยังขาดประสบการณ์ mental model นี้เปลี่ยนทุกอย่าง
AI models สมัยใหม่อย่าง GPT-5 และ Claude ไม่ได้แค่ตอบคำถาม—พวกมันถูกออกแบบมาเป็นagents พวกมันสามารถเรียกใช้ tools, รวบรวม context, ตัดสินใจ, และทำงานหลายขั้นตอนได้ แต่เหมือนสมาชิกทีมใหม่ทุกคน พวกมันต้องการ onboarding ที่เหมาะสม, ความคาดหวังที่ชัดเจน, และ guardrails ที่เหมาะสม
AI ไม่ใช่เครื่องมือที่คุณใช้ มันคือเพื่อนร่วมงานที่คุณบริหาร ทักษะที่ทำให้คุณเป็นผู้จัดการที่ดีก็ทำให้คุณเป็น prompter ที่ดี
ลองคิดดู: เมื่อคุณมอบหมายงานให้คน คุณไม่ได้แค่พูดว่า "แก้โค้ด" คุณอธิบายว่าอะไรเสีย, behavior ที่ต้องการคืออะไร, มีข้อจำกัดอะไร, และความสำเร็จหน้าตาเป็นอย่างไร คุณให้ context คุณตอบคำถาม คุณติดตามความคืบหน้า
AI ต้องการการปฏิบัติแบบเดียวกัน ความแตกต่างคือคุณต้องคาดการณ์คำถามและตอบล่วงหน้า เพราะการโต้ตอบไปมามีค่าใช้จ่ายสูงกว่า (ทั้งเวลาและ tokens) การทำถูกตั้งแต่แรก
Agentic Mindset
เมื่อสร้าง agentic applications หรือใช้ AI สำหรับงานซับซ้อน ผมเรียนรู้ที่จะคิดในแง่ของ:
คำถามสำคัญสำหรับ Agentic Tasks
- Goal state คืออะไร? AI จะรู้ได้อย่างไรว่าทำเสร็จแล้ว?
- มี tools อะไร? มันทำอะไรได้จริง vs อะไรที่ต้องรอ?
- Autonomy level คืออะไร? ควรขออนุญาตหรือดำเนินการเอง?
- Safety boundaries คืออะไร? actions ไหนที่ห้ามทำโดยไม่ได้รับการยืนยัน?
- ควรสื่อสารความคืบหน้าอย่างไร? ทำเงียบๆ หรืออัปเดตเป็นระยะ?
คำถามเหล่านี้เป็นรากฐานของทุก prompt ที่ซับซ้อนที่ผมเขียน มาสำรวจแต่ละมิติอย่างละเอียด
ควบคุมความกระตือรือร้นของ AI: ศิลปะแห่งการปรับจูน
หนึ่งในแง่มุมที่ละเอียดอ่อนที่สุดของ prompt engineering คือการปรับสิ่งที่ผมเรียกว่า "agentic eagerness"—ความสมดุลระหว่าง AI ที่ริเริ่มเองกับ AI ที่รอคำแนะนำ ทำผิดแล้วคุณจะได้ AI ที่คิดมากเกินไปสำหรับงานง่ายๆ หรือ AI ที่ยอมแพ้ง่ายเกินไปกับงานซับซ้อน
เมื่อไหร่ควรลดความกระตือรือร้น
บางครั้งคุณต้องการ AI ที่เร็วและโฟกัส คุณไม่อยากให้มันสำรวจทุกทาง, เรียก tools เพิ่ม, หรือให้คำอธิบายยาว สำหรับสถานการณ์เหล่านี้ ผมใช้ constraint-focused prompts:
<context_gathering>
เป้าหมาย: รับ context เพียงพอให้เร็ว ค้นหาแบบ parallel และหยุดทันทีที่ลงมือได้
วิธีการ:
- เริ่มกว้าง แล้วแตกเป็น subqueries ที่เจาะจง
- ปล่อย queries หลากหลายพร้อมกัน; อ่านผลลัพธ์ top hits ต่อ query
- ไม่ทำซ้ำ paths และ cache; ไม่ query ซ้ำ
- หลีกเลี่ยงการค้นหา context มากเกินไป
เกณฑ์หยุดก่อน:
- คุณระบุ content ที่จะเปลี่ยนได้ชัดเจน
- Top hits ลู่เข้า (~70%) ที่พื้นที่/path เดียว
ความลึก:
- ติดตามเฉพาะ symbols ที่จะแก้ไขหรือที่พึ่งพา contracts
- หลีกเลี่ยง transitive expansion ยกเว้นจำเป็น
Loop:
- Batch search → minimal plan → complete task
- ค้นหาอีกเมื่อ validation fail หรือมี unknowns ใหม่
- เน้นลงมือมากกว่าค้นหาเพิ่ม
</context_gathering>สังเกตการอนุญาตชัดเจนให้ไม่สมบูรณ์แบบ: "เน้นลงมือมากกว่าค้นหาเพิ่ม" ประโยคละเอียดอ่อนนี้ปลดปล่อย AI จากความวิตกกังวลเรื่องความละเอียดถี่ถ้วนโดยธรรมชาติ ไม่มีมัน model มักจะค้นหามากเกินไป เผา tokens และเวลาบน diminishing returns
สำหรับ constraints ที่เข้มกว่า คุณสามารถตั้ง budgets ที่ชัดเจน:
<context_gathering>
- Search depth: ต่ำมาก
- เน้นอย่างมากที่ให้คำตอบถูกต้องเร็วที่สุด
แม้อาจไม่ถูกต้องสมบูรณ์
- ปกติหมายถึงสูงสุด 2 tool calls
- ถ้าคิดว่าต้องการเวลาสืบสวนมากกว่านี้ อัปเดตผมด้วย
findings ล่าสุดและ open questions ได้รับการยืนยันแล้วดำเนินการต่อได้
</context_gathering>ประโยค "แม้อาจไม่ถูกต้องสมบูรณ์" นั้นทรงพลัง มันให้ AI อนุญาตที่จะไม่สมบูรณ์แบบ ซึ่งขัดแย้งกันแต่มักให้ผลลัพธ์ที่ดีกว่าเร็วกว่า
เมื่อไหร่ควรเพิ่มความกระตือรือร้น
ในบางครั้ง คุณต้องการ AI ที่ละเอียดถี่ถ้วนอย่างไม่หยุดยั้ง คุณอยากให้มันฝ่าฟันความคลุมเครือ, ทำ assumptions ที่สมเหตุสมผล, และทำงานซับซ้อนให้เสร็จโดยไม่ต้องขออนุญาตตลอด นี่ต้องการแนวทางตรงข้าม:
<persistence>
- คุณเป็น agent — โปรดดำเนินการต่อจนกว่า query ของผู้ใช้จะแก้ไขเสร็จสมบูรณ์
ก่อนจบ turn และคืนให้ผู้ใช้
- ยุติ turn เมื่อแน่ใจว่าปัญหาแก้ไขแล้วเท่านั้น
- อย่าหยุดหรือคืนให้ผู้ใช้เมื่อพบความไม่แน่นอน —
ค้นคว้าหรือหา approach ที่สมเหตุสมผลที่สุดและดำเนินการต่อ
- อย่าขอให้มนุษย์ยืนยันหรือชี้แจง assumptions เพราะคุณสามารถ
ปรับทีหลังได้ — ตัดสินใจว่า assumption ที่สมเหตุสมผลที่สุดคืออะไร,
ดำเนินการตามนั้น, และบันทึกไว้ให้ผู้ใช้อ้างอิงหลังจากลงมือเสร็จ
</persistence>Prompt นี้เปลี่ยน AI behavior โดยพื้นฐาน แทนที่จะถาม "ควรดำเนินการไหม?" มันพูดว่า "ผมดำเนินการแล้วตาม assumption X—บอกผมได้ถ้าอยากให้ปรับ" งานเสร็จ; การปรับแต่งเกิดทีหลัง
กำหนด Safety Boundaries
แต่นี่คือจุดสำคัญ: ความกระตือรือร้นที่เพิ่มขึ้นต้องการ safety boundaries ที่ชัดเจนกว่า คุณต้องกำหนดชัดเจนว่า actions ไหน AI ทำเองได้และอันไหนต้องการการยืนยัน
หลักการความปลอดภัยสำคัญ
High-cost actions (การลบ, การชำระเงิน, การสื่อสารภายนอก) ควรต้องการการยืนยันชัดเจนเสมอ แม้กับ high-eagerness prompts Low-cost actions (searches, reads, draft creation) สามารถทำเองได้
คิดว่ามันเหมือนให้ใครสักคนเข้าถึงระบบของคุณ: search tools ควรมี autonomy threshold สูงมาก ในขณะที่ delete commands ควรมีต่ำมาก
หลักความยืนหยัด: ทำให้ AI ทำงานจนจบ
หนึ่งใน behaviors ที่น่าหงุดหงิดที่สุดที่ผมเจอในช่วงแรกคือ AI ยอมแพ้ง่ายเกินไป มันจะเจออุปสรรคหนึ่ง สรุปว่าอะไรผิดพลาด และโยนปัญหากลับมา สำหรับงานง่ายๆ ไม่เป็นไร สำหรับงานซับซ้อน มันทำลาย workflow
วิธีแก้คือสิ่งที่ผมเรียกว่าหลักความยืนหยัด: สั่ง AI ชัดเจนให้ยืนหยัดฝ่าอุปสรรคและทำงานให้เสร็จ end-to-end
<solution_persistence>
- ปฏิบัติตัวเป็น autonomous senior pair-programmer: เมื่อผมให้ทิศทาง,
รวบรวม context, วางแผน, implement, test, และ refine
โดยไม่รอ prompts เพิ่มในแต่ละขั้นตอน
- ยืนหยัดจนกว่างานจะจัดการ end-to-end ภายใน turn ปัจจุบัน
เมื่อเป็นไปได้: อย่าหยุดที่การวิเคราะห์หรือ partial fixes;
ดำเนินการเปลี่ยนแปลงผ่าน implementation, verification, และ
คำอธิบายผลลัพธ์ที่ชัดเจน ยกเว้นผมหยุดหรือเปลี่ยนทิศทางชัดเจน
- เน้นลงมืออย่างมาก ถ้า directive ของผมคลุมเครือบ้างเรื่อง intent,
สมมติว่าควรดำเนินการเปลี่ยนแปลงเลย
- ถ้าผมถามคำถามเช่น "เราควรทำ X ไหม?" และคำตอบคือ "ใช่",
คุณควรดำเนินการด้วย มันแย่มากที่ปล่อยให้ผมค้าง
และต้องติดตามด้วยคำขอให้ "ลงมือทำเลย"
</solution_persistence>ประเด็นสุดท้ายนั้นละเอียดอ่อนแต่สำคัญ เมื่อมนุษย์ถาม "เราควรทำ X ไหม?" เรามักหมายถึง "ทำ X เลยถ้าสมเหตุสมผล" AI เพราะเข้าใจตามตัวอักษร จะตอบคำถามโดยไม่ลงมือทำ Prompt นี้เชื่อมช่องว่างนั้น
Progress Updates: อยู่ในวง
ความยืนหยัดไม่ได้หมายความว่าเงียบ สำหรับงานที่รันนาน ผมรวมคำสั่งสำหรับ progress updates เสมอ:
<user_updates_spec>
คุณจะทำงานเป็นช่วงๆ กับ tool calls — การอัปเดตให้ผมทราบสำคัญมาก
<frequency_and_length>
- ส่งอัปเดตสั้น (1-2 ประโยค) ทุกสองสาม tool calls เมื่อมีความเปลี่ยนแปลงสำคัญ
- โพสต์อัปเดตอย่างน้อยทุก 6 execution steps หรือ 8 tool calls
(อันไหนมาถึงก่อน)
- ถ้าคาดว่าจะทำงานยาวแบบ heads-down โพสต์บันทึกสั้นว่าทำไม
และจะรายงานเมื่อไหร่; เมื่อกลับมา สรุปสิ่งที่เรียนรู้
- เฉพาะแผนเริ่มต้น, อัปเดตแผน, และ recap สุดท้ายที่ยาวได้
</frequency_and_length>
<content>
- ก่อน tool call แรก ให้แผนด่วนพร้อมเป้าหมาย, constraints, next steps
- ระหว่างสำรวจ ชี้ให้เห็น discoveries สำคัญที่ช่วยให้ผมเข้าใจว่าเกิดอะไรขึ้น
- ระบุอย่างน้อยหนึ่ง concrete outcome ตั้งแต่อัปเดตก่อนเสมอ
(เช่น "พบ X", "ยืนยัน Y") ไม่ใช่แค่ next steps
- จบด้วย recap สั้นและ follow-up steps ใดๆ
</content>
</user_updates_spec>นี่สร้างความสมดุลที่สวยงาม: AI ทำงานอัตโนมัติแต่ให้คุณทราบ คุณไม่ได้ micromanage แต่คุณก็ไม่ได้อยู่ในความมืด
Reasoning Effort: ปุ่มปรับความเข้มของการคิด
AI models สมัยใหม่มีแนวคิดที่เรียกว่า "reasoning effort"—โดยพื้นฐานคือ model คิดหนักแค่ไหนก่อนตอบ นี่เป็นหนึ่งในพารามิเตอร์ที่ทรงพลังและถูกใช้ประโยชน์น้อยที่สุด
High Reasoning
ใช้สำหรับงานหลายขั้นตอนที่ซับซ้อน, สถานการณ์คลุมเครือ, หรือปัญหาที่ต้องวิเคราะห์ลึก Model ใช้ tokens "คิด" ภายในมากขึ้นก่อนตอบ
Medium Reasoning (Default)
การตั้งค่าสมดุลที่เหมาะกับงานส่วนใหญ่ ดีสำหรับ coding ทั่วไป, การเขียน, และการวิเคราะห์ที่คุณภาพสำคัญแต่ความเร็วก็สำคัญ
Low Reasoning
การตอบเร็วสำหรับงานตรงไปตรงมา ใช้เมื่อต้องการคำตอบเร็วและงานไม่ต้องการการคิดลึก
Minimal/None Reasoning
ความเร็วสูงสุด การคิดน้อยสุด ดีที่สุดสำหรับ queries ง่าย, งาน reformatting, หรือเมื่อ latency เป็นความกังวลหลัก
ความเข้าใจสำคัญคือการจับคู่ reasoning effort กับความซับซ้อนของงาน ใช้ high reasoning กับงานง่ายเสีย tokens และเวลา ใช้ low reasoning กับงานซับซ้อนได้ผลลัพธ์ตื้นและผิดพลาดง่าย
Prompting สำหรับ Minimal Reasoning
เมื่อใช้ minimal reasoning modes คุณต้องชดเชยด้วย prompting ที่ชัดเจนกว่า Model มี "thinking" tokens ภายในน้อยกว่า ดังนั้น prompt ของคุณต้องทำงานโครงสร้างมากขึ้น:
<planning_requirement>
คุณต้องวางแผนอย่างละเอียดก่อน function call แต่ละครั้ง, และ reflect
อย่างละเอียดกับผลลัพธ์ของ function calls ก่อนหน้า, ให้แน่ใจว่า
query ของผมแก้ไขเสร็จสมบูรณ์
อย่าทำกระบวนการทั้งหมดด้วย function calls อย่างเดียว เพราะอาจ
ทำลายความสามารถในการแก้ปัญหาและคิดอย่างลึกซึ้ง นอกจากนี้
ให้แน่ใจว่า function calls มี arguments ที่ถูกต้อง
</planning_requirement>Prompt นี้พูดว่า: "เนื่องจากคุณไม่ได้ทำ reasoning ภายในมาก ให้ทำ reasoning ออกเสียงใน response ของคุณ" มันย้ายงานทางความคิดจากการคิดของ model ที่มองไม่เห็นมาเป็นการวางแผนที่มีโครงสร้างที่มองเห็นได้
เมื่อ reasoning effort ต่ำ, prompt complexity ควรสูง เมื่อ reasoning effort สูง, prompts สามารถง่ายกว่า มันคือความสมดุล
ความเป็นเลิศด้าน Coding: เขียนโปรแกรมร่วมกับ AI
นี่คือที่ผมใช้เวลามากที่สุดในการ optimize prompts และที่ผลตอบแทนมหาศาล AI coding assistance เปลี่ยนเกม—เมื่อทำถูกต้อง ทำผิดแล้ว มันสร้างปัญหามากกว่าแก้
ให้ผมแชร์สิ่งที่เรียนรู้จากการศึกษาว่า AI coding tools มืออาชีพอย่าง Cursor ปรับ prompts อย่างไรสำหรับการใช้งานจริง
Verbosity Paradox
นี่คือสิ่งที่ขัดสามัญสำนึก: AI มักจะ verbose ในคำอธิบายแต่ terse ในโค้ด มันจะเขียนหลายย่อหน้าอธิบายว่าจะทำอะไร แล้วผลิตโค้ดที่มีชื่อตัวแปรตัวอักษรเดียวและ comments น้อยมาก นี่ตรงข้ามกับที่ต้องการในกรณีส่วนใหญ่
วิธีแก้คือ dual-mode verbosity control:
<code_verbosity>
เขียนโค้ดเพื่อความชัดเจนก่อน เลือก solutions ที่อ่านง่าย, maintain ง่าย
ด้วยชื่อที่ชัดเจน, comments เมื่อจำเป็น, และ control flow ตรงไปตรงมา
อย่าผลิต code-golf หรือ one-liners ที่ฉลาดเกินไปยกเว้นถูกขอชัดเจน
ใช้ high verbosity สำหรับเขียนโค้ดและ code tools
ใช้ low verbosity สำหรับ status updates และคำอธิบาย
</code_verbosity>นี่สร้างความสมดุลที่สมบูรณ์แบบ: การสื่อสารกระชับ, โค้ดละเอียด
Proactive vs Confirmative Actions
อีกบทเรียนจาก production coding tools: AI ควร proactive กับการเปลี่ยนโค้ดแต่ confirmative กับ destructive actions นี่คือวิธี encode:
<proactive_coding>
ทราบว่า code edits ที่คุณทำจะแสดงให้ผมเห็นเป็น proposed changes
ซึ่งหมายความว่า:
(a) Code edits ของคุณสามารถค่อนข้าง proactive ได้ เพราะผม reject ได้เสมอ
(b) โค้ดควรเขียนดีและ review เร็วได้ง่าย
ถ้าเสนอ next steps ที่เกี่ยวข้องกับการเปลี่ยนโค้ด ทำการเปลี่ยนแปลงเหล่านั้น
proactively ให้ผม approve/reject แทนที่จะถามว่าควรดำเนินการตามแผนไหม
โดยทั่วไป คุณแทบไม่ควรถามผมว่าควรดำเนินการตามแผนไหม;
แทนที่ proactively พยายามทำแผนแล้วถามว่าผมอยาก accept
การเปลี่ยนแปลงที่ implemented แล้วไหม
</proactive_coding>นี่กำจัดการโต้ตอบไปมาที่น่าหงุดหงิดที่ AI อธิบายว่าจะทำอะไร, ขออนุญาต, แล้วทำ แค่ทำเลย—ผมจะ reject ถ้าจำเป็น
Matching Codebase Style
หนึ่งในข้อร้องเรียนใหญ่ที่สุดเกี่ยวกับโค้ดที่ AI สร้างคือมันไม่ match patterns ของ codebase ที่มีอยู่ มันรู้สึกเหมือนโค้ด "ต่างด้าว" วิธีแก้คือ style guidance ที่ชัดเจน:
<code_editing_rules>
<guiding_principles>
- Clarity and Reuse: ทุก component ควร modular และ reusable
หลีกเลี่ยงการทำซ้ำโดย factor repeated patterns เป็น components
- Consistency: โค้ดต้องยึดตาม design system ที่สอดคล้องกัน—naming
conventions, spacing, และ components ต้องเป็นหนึ่งเดียว
- Simplicity: เลือก components เล็ก, focused และหลีกเลี่ยงความซับซ้อน
ที่ไม่จำเป็นใน styling หรือ logic
- Visual Quality: ทำตามมาตรฐานคุณภาพภาพสูง (spacing, padding,
hover states, etc.)
</guiding_principles>
<style_matching>
- ก่อนทำการเปลี่ยนแปลง ตรวจสอบ patterns ที่มีอยู่ใน codebase
- Match variable naming conventions (camelCase vs snake_case)
- Match indentation และ formatting
- Reuse utilities และ helpers ที่มีอยู่แทนที่จะสร้างใหม่
- ทำตาม directory structure ที่กำหนดไว้
</style_matching>
</code_editing_rules>Frontend Development: สร้าง Interface ที่สวยงาม
AI กลายเป็นเก่งมากใน frontend development แต่มีศาสตร์ในการได้ผลลัพธ์ที่สวยงามและพร้อมใช้งานจริง นี่คือสิ่งที่ผมเรียนรู้
Stack ที่แนะนำ
ผ่านการทดสอบอย่างกว้างขวาง การรวมเทคโนโลยีบางอย่างทำงานกับ AI ได้ดีกว่า นี่ไม่ใช่เรื่องว่าอะไร "ดีที่สุด" อย่างเป็นกลาง—แต่เกี่ยวกับว่า AI models ถูก train กับอะไรมากที่สุด:
AI-Optimized Frontend Stack
- Frameworks: Next.js (TypeScript), React, HTML
- Styling/UI: Tailwind CSS, shadcn/ui, Radix Themes
- Icons: Material Symbols, Heroicons, Lucide
- Animation: Motion (เดิมชื่อ Framer Motion)
- Fonts: Sans Serif families—Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
เมื่อคุณระบุเทคโนโลยีเหล่านี้ AI ผลิต output คุณภาพสูงขึ้นอย่างมากพร้อม hallucinations เกี่ยวกับ APIs ที่ไม่มีอยู่น้อยลง
Design System Enforcement
ปัญหาหนึ่งกับ frontends ที่ AI สร้างคือความไม่สอดคล้องทางภาพ สีโผล่มาจากไหนไม่รู้, spacing แตกต่างกันแบบสุ่ม, และผลลัพธ์ดูเหมือนถูกออกแบบโดยคณะกรรมการ วิธีแก้คือ design system constraints ที่ชัดเจน:
<design_system_enforcement>
- Tokens-first: อย่า hard-code colors (hex/hsl/oklch/rgb) ใน JSX/CSS
ทุกสีต้องมาจาก CSS variables (เช่น --background, --foreground,
--primary, --accent, --border, --ring)
- แนะนำ brand หรือ accent? ก่อน styling, เพิ่ม/ขยาย tokens ใน
CSS variables ภายใต้ :root และ .dark
- Consumption: ใช้ Tailwind utilities ที่เชื่อมกับ tokens
(เช่น bg-[hsl(var(--primary))], text-[hsl(var(--foreground))])
- Default เป็น neutral palette ของระบบยกเว้นผมขอ brand look ชัดเจน;
แล้ว map brand นั้นกับ tokens ก่อน
- อย่าประดิษฐ์ colors, shadows, tokens, animations, หรือ UI elements ใหม่
ยกเว้นถูกขอหรือจำเป็น
</design_system_enforcement>UI/UX Best Practices
ผมยังรวม UI/UX guidelines ที่ชัดเจนเพื่อให้แน่ใจว่า visual hierarchy สอดคล้องกัน:
<ui_ux_best_practices>
- Visual Hierarchy: จำกัด typography เป็น 4-5 font sizes และ weights
สำหรับ hierarchy ที่สอดคล้อง; ใช้ text-xs สำหรับ captions,
หลีกเลี่ยง text-xl ยกเว้นสำหรับ hero หรือ major headings
- Color Usage: ใช้ 1 neutral base (เช่น zinc) และสูงสุด 2 accent colors
- Spacing and Layout: ใช้ตัวคูณของ 4 เสมอสำหรับ padding และ margins
เพื่อรักษา visual rhythm ใช้ fixed height containers
พร้อม internal scrolling เมื่อจัดการ long content
- State Handling: ใช้ skeleton placeholders หรือ animate-pulse
เพื่อบ่งบอก data fetching บ่งบอก clickability ด้วย hover transitions
- Accessibility: ใช้ semantic HTML และ ARIA roles ตามเหมาะสม
เลือก pre-built accessible components
</ui_ux_best_practices>Self-Reflection Prompts: ให้ AI วิจารณ์ตัวเอง
เทคนิคนี้ทำให้งงเมื่อเจอครั้งแรก แต่ทรงพลังมาก: คุณสามารถสั่งให้ AI สร้างเกณฑ์ประเมินของตัวเองและ iterate ตามเกณฑ์นั้น เหมือนให้ AI มีแผนก QA ภายใน
<self_reflection>
- ก่อนอื่น ใช้เวลาคิด rubric จนกว่าจะมั่นใจ
- แล้ว คิดลึกเกี่ยวกับทุกแง่มุมของสิ่งที่ทำให้เป็น world-class solution
ใช้ความรู้นั้นสร้าง rubric ที่มี 5-7 categories
Rubric นี้สำคัญมากที่ต้องทำถูก แต่ไม่ต้องแสดงให้ผมเห็น
นี่สำหรับจุดประสงค์ของคุณเท่านั้น
- สุดท้าย ใช้ rubric เพื่อคิดภายในและ iterate หา solution ที่ดีที่สุด
สำหรับ prompt จำไว้ว่าถ้า response ของคุณไม่ได้คะแนนสูงสุด
ในทุก categories ใน rubric คุณต้องเริ่มใหม่
</self_reflection>สิ่งที่เกิดขึ้นที่นี่น่าสนใจ: คุณขอให้ AI สร้างเกณฑ์คุณภาพจากความรู้เรื่องความเป็นเลิศ แล้วใช้เกณฑ์เหล่านั้นประเมินและปรับปรุง output ของตัวเอง—ทั้งหมดก่อนที่คุณจะเห็นอะไร
Self-reflection prompts เปลี่ยน single generation เป็น internal iteration loop AI กลายเป็น editor ของตัวเอง
ผมใช้เทคนิคนี้สำหรับทุกงานที่คุณภาพสำคัญกว่าความเร็ว: landing pages, อีเมลสำคัญ, architectural decisions, งานสร้างสรรค์ การปรับปรุงคุณภาพ output นั้นมีนัยสำคัญ
ควบคุมความยาว: เชี่ยวชาญความยาวของ Output
การได้ความยาว output ที่ถูกต้องเป็นความท้าทายต่อเนื่อง สั้นเกินไปคุณพลาดรายละเอียดสำคัญ ยาวเกินไปคุณจมในข้อมูลที่ไม่จำเป็น นี่คือวิธีของผม
Explicit Length Guidelines
วิธีที่เชื่อถือได้ที่สุดคือ length constraints ที่ชัดเจนผูกกับความซับซ้อนของงาน:
<output_verbosity_spec>
- Default: 3-6 ประโยคหรือ ≤5 bullets สำหรับคำตอบทั่วไป
- สำหรับคำถาม "ใช่/ไม่ใช่ + คำอธิบายสั้น" ง่ายๆ: ≤2 ประโยค
- สำหรับงานหลายขั้นตอนหรือหลายไฟล์ที่ซับซ้อน:
- 1 overview paragraph สั้น
- แล้ว ≤5 bullets ติด tag: อะไรเปลี่ยน, ที่ไหน, Risks, Next steps,
Open questions
- ให้ responses ที่ชัดเจนและมีโครงสร้างที่สมดุลระหว่างข้อมูล
กับความกระชับ
- แยกข้อมูลเป็นชิ้นย่อยที่ย่อยง่ายและใช้ formatting เช่น
lists, paragraphs และ tables เมื่อช่วยได้
- หลีกเลี่ยง narrative paragraphs ยาว; เลือก compact bullets และ short sections
- อย่า rephrase request ของผมยกเว้นเปลี่ยน semantics
</output_verbosity_spec>Persona-Based Verbosity
อีกวิธีคือกำหนด communication style ของ AI เป็นส่วนหนึ่งของ persona:
<communication_style>
คุณให้คุณค่ากับความชัดเจน, momentum, และความเคารพที่วัดจากประโยชน์
ไม่ใช่คำสุภาพ สัญชาตญาณ default ของคุณคือรักษาบทสนทนาให้กระชับ
และมุ่งเป้าหมาย ตัดทุกอย่างที่ไม่ขับเคลื่อนงานไปข้างหน้า
คุณไม่เย็นชา—คุณแค่ประหยัดกับภาษา และคุณไว้ใจ
ผู้ใช้พอที่จะไม่ห่อทุกข้อความด้วย padding
ความสุภาพแสดงผ่านโครงสร้าง, ความแม่นยำ, และ responsiveness
ไม่ใช่ผ่านคำที่ไม่จำเป็น
คุณไม่เคยพูดซ้ำ acknowledgments เมื่อคุณแสดงความเข้าใจแล้ว
คุณหันไปโฟกัสที่งานเต็มที่
</communication_style>นี่สร้าง "personality" ที่ผลิต output กระชับตามธรรมชาติโดยไม่ต้องมี length constraints ชัดเจนสำหรับทุกปฏิสัมพันธ์
การทำตามคำสั่ง: เกมแห่งความแม่นยำ
AI models สมัยใหม่ทำตามคำสั่งด้วยความแม่นยำระดับศัลยแพทย์—ซึ่งเป็นทั้งจุดแข็งที่สุดและข้อผิดพลาดที่อาจเกิดได้ พวกมันจะทำตรงตามที่คุณพูด แม้ว่าสิ่งที่คุณพูดจะขัดแย้งหรือคลุมเครือ
ปัญหาความขัดแย้ง
นี่คือตัวอย่างจริงของ prompt ที่มีปัญหาที่ผมเคยเห็น:
ตัวอย่างคำสั่งที่ขัดแย้ง
"ค้นหาประวัติผู้ป่วยก่อนทำ actions อื่นเสมอเพื่อให้แน่ใจว่าเป็นผู้ป่วยที่มีอยู่"
แต่ทีหลัง: "เมื่ออาการบ่งบอกความเร่งด่วนสูง ยกระดับเป็น EMERGENCY และแนะนำให้ผู้ป่วยโทร 1669 ทันทีก่อนขั้นตอนนัดหมายใดๆ"
คำสั่งเหล่านี้ขัดแย้งกัน การจัดการ emergency เกิดก่อนหรือหลังการค้นหาประวัติ? AI จะเผา reasoning tokens พยายามประสานความขัดแย้งแทนที่จะช่วยเหลือ
วิธีแก้คือทบทวน prompts สำหรับความขัดแย้งที่ซ่อนอยู่และสร้าง priority hierarchies ที่ชัดเจน:
<instruction_priority>
เมื่อคำสั่งขัดแย้ง ทำตาม priority order นี้:
1. Safety-critical actions (emergencies, data protection)
2. User-specified constraints
3. Task completion requirements
4. Default behaviors
สำหรับสถานการณ์ฉุกเฉิน: อย่าทำ profile lookup ดำเนินการให้
emergency guidance ทันที
</instruction_priority>Precision in Scope
อีกปัญหาที่พบบ่อยคือ scope creep—AI เพิ่ม features หรือ "improvements" ที่คุณไม่ได้ขอ:
<design_and_scope_constraints>
- Implement ตรงและเฉพาะสิ่งที่ผมขอ
- ไม่มี features เพิ่ม, ไม่มี components ที่เพิ่มมา, ไม่มี UX embellishments
- ถ้าคำสั่งใดคลุมเครือ เลือก interpretation ที่ง่ายที่สุดที่ valid
- อย่าขยายงานเกินกว่าที่ผมขอ; ถ้าสังเกตเห็นงานเพิ่มเติมที่อาจ
มีคุณค่า ชี้ให้เห็นเป็น optional แทนที่จะทำเลย
</design_and_scope_constraints>Long Context Mastery: จัดการเอกสารขนาดใหญ่
AI สมัยใหม่สามารถประมวลผล contexts ขนาดใหญ่—หลายแสน tokens—แต่แค่โยนเอกสารใหญ่ๆ เข้า context window ไม่พอ คุณต้องมีกลยุทธ์ช่วยให้ model navigate และดึงข้อมูลที่เกี่ยวข้อง
Force Summarization และ Re-grounding
สำหรับเอกสารยาว ผมสั่งให้ AI สร้างโครงสร้างภายในก่อนตอบ:
<long_context_handling>
สำหรับ inputs ที่ยาวกว่า ~10k tokens (เอกสารหลายบท, threads ยาว,
หลาย PDFs):
1. ก่อนอื่น ผลิต internal outline สั้นๆ ของ key sections ที่เกี่ยวข้อง
กับ request ของผม
2. พูดซ้ำ constraints ของผมชัดเจน (เช่น jurisdiction, date range,
product, team) ก่อนตอบ
3. ในคำตอบของคุณ anchor claims กับ sections ("ใน section 'Data Retention'…")
แทนที่จะพูดกว้างๆ
4. ถ้าคำตอบขึ้นอยู่กับรายละเอียด (dates, thresholds, clauses),
quote หรือ paraphrase โดยตรง
</long_context_handling>นี่ป้องกันปัญหา "หลงในการ scroll" ที่ AI ให้คำตอบทั่วไปที่ไม่ได้ engage กับเนื้อหาเอกสารเฉพาะจริงๆ
Citation Requirements
สำหรับงานวิจัยและวิเคราะห์ citation requirements ที่ชัดเจนให้แน่ใจว่าคำตอบมีรากฐาน:
<citation_rules>
เมื่อใช้ข้อมูลจากเอกสารที่ให้มา:
- ใส่ citations หลังแต่ละ paragraph ที่มี claims จากเอกสาร
- ใช้ format: [ชื่อเอกสาร, Section/หน้า]
- อย่าประดิษฐ์ citations ถ้า cite ไม่ได้ อย่า claim
- ใช้หลาย sources สำหรับ key claims เมื่อเป็นไปได้
- ถ้า evidence บาง ยอมรับชัดเจน
</citation_rules>Tool Calling: ประสานความสามารถของ AI
AI tool calling—ความสามารถในการเรียกใช้ external functions, APIs, และ services—คือที่ prompt engineering กลายเป็น software engineering การทำถูกต้องสำคัญสำหรับการสร้าง AI applications ที่เชื่อถือได้
Tool Description Best Practices
คุณภาพของ tool descriptions ส่งผลโดยตรงต่อการที่ AI ใช้มันได้ดีแค่ไหน:
{
"name": "create_reservation",
"description": "สร้างการจองร้านอาหารสำหรับแขก ใช้เมื่อผู้ใช้ขอจองโต๊ะ
ด้วยชื่อและเวลาที่กำหนด",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "ชื่อเต็มของแขกสำหรับการจอง"
},
"datetime": {
"type": "string",
"description": "วันที่และเวลาจอง (ISO 8601 format)"
}
},
"required": ["name", "datetime"]
}
}สังเกตว่า description รวมทั้งอะไรที่ tool ทำและเมื่อไหร่ควรใช้ นี่ช่วยให้ model ตัดสินใจเลือก tool ได้ดีขึ้น
Tool Usage Rules in Prompts
นอกเหนือจาก tool definitions แล้ว prompt ของคุณควรรวม usage guidance ที่ชัดเจน:
<tool_usage_rules>
- เลือก tools มากกว่า internal knowledge เมื่อ:
- ต้องการข้อมูลสดหรือเฉพาะผู้ใช้ (tickets, orders, configs, logs)
- อ้างอิง IDs, URLs, หรือ document titles เฉพาะ
- Parallelize independent reads (read_file, fetch_record, search_docs)
เมื่อเป็นไปได้เพื่อลด latency
- หลังทุก write/update tool call พูดสั้นๆ:
- อะไรเปลี่ยน
- ที่ไหน (ID หรือ path)
- follow-up validation ใดที่ทำ
- สำหรับคำถาม conceptual ง่ายๆ หลีกเลี่ยง tools และพึ่ง internal knowledge
เพื่อให้ responses เร็ว
</tool_usage_rules>Parallelization
Key optimization คือสนับสนุน parallel tool calls เมื่อ operations เป็นอิสระ:
<parallelization>
Parallelize tool calls เมื่อเป็นไปได้ Batch reads (read_file) และ
independent edits (apply_patch ไปยังไฟล์ต่างกัน) เพื่อเร่งกระบวนการ
Independent operations ที่สามารถ parallelize ได้:
- อ่านหลายไฟล์
- ค้นหาหลาย directories
- Fetch หลาย records
Dependent operations ที่ไม่สามารถ parallelize ได้:
- อ่านไฟล์, แล้วแก้ไขตาม contents
- สร้าง resource, แล้วอ้างอิง ID ของมัน
</parallelization>จัดการความไม่แน่นอน: เมื่อ AI ไม่รู้
หนึ่งในความเสี่ยงใหญ่ที่สุดกับ AI คือคำตอบที่ผิดแต่ฟังดูมั่นใจ Model ไม่รู้ว่าตัวเองไม่รู้อะไร—ยกเว้นคุณสอนมันว่าจัดการความไม่แน่นอนอย่างไร
<uncertainty_and_ambiguity>
- ถ้าคำถามคลุมเครือหรือ spec ไม่พอ ชี้ให้เห็นชัดเจนและ:
- ถามคำถามชี้แจงที่แม่นยำสูงสุด 1-3 คำถาม, หรือ
- นำเสนอ 2-3 interpretations ที่เป็นไปได้พร้อม assumptions ที่ติด label ชัด
- เมื่อ external facts อาจเปลี่ยนเมื่อเร็วๆ นี้ (ราคา, releases, policies)
และไม่มี tools:
- ตอบเป็น general terms และบอกว่ารายละเอียดอาจเปลี่ยนแล้ว
- อย่าประดิษฐ์ตัวเลข, line numbers, หรือ external references ที่แม่นยำ
เมื่อไม่แน่ใจ
- เมื่อไม่แน่ใจ เลือกภาษาแบบ "ตาม context ที่ให้มา…"
แทน absolute claims
</uncertainty_and_ambiguity>High-Risk Self-Check
สำหรับ domains ที่มีความเสี่ยงสูง ผมเพิ่ม self-verification step ที่ชัดเจน:
<high_risk_self_check>
ก่อน finalize คำตอบใน legal, financial, compliance, หรือ
safety-sensitive contexts:
- Scan คำตอบของตัวเองสั้นๆ สำหรับ:
- Assumptions ที่ไม่ได้พูด
- ตัวเลขหรือ claims เฉพาะที่ไม่มีรากฐานใน context
- ภาษาที่แรงเกินไป ("เสมอ", "รับประกัน", etc.)
- ถ้าพบอะไร ลดลงหรือ qualify และบอก assumptions ชัดเจน
</high_risk_self_check>เป้าหมายไม่ใช่ทำให้ AI ไม่มั่นใจ—แต่ทำให้มันมั่นใจอย่างแม่นยำ ความไม่แน่นอนเกี่ยวกับสิ่งที่ไม่แน่นอนเป็น feature ไม่ใช่ bug
Metaprompting: ใช้ AI ปรับปรุง AI
นี่คือเทคนิคที่ meta ที่สุดใน toolkit ของผม: ใช้ AI ปรับปรุง prompts ของคุณ ฟังดูวนลูป แต่มีประสิทธิภาพมาก
วินิจฉัย Prompt Failures
เมื่อ prompts ไม่ทำงาน ผมใช้ pattern นี้วินิจฉัยปัญหา:
คุณเป็น prompt engineer ที่ได้รับมอบหมายให้ debug system prompt
คุณได้รับ:
1) System prompt ปัจจุบัน:
<system_prompt>
[วาง PROMPT ของคุณที่นี่]
</system_prompt>
2) ชุดเล็กๆ ของ logged failures แต่ละ log มี:
- query
- actual_output
- expected_output (หรือ description ของปัญหา)
<failure_traces>
[วางตัวอย่าง FAILURES]
</failure_traces>
งานของคุณ:
1) ระบุ distinct failure modes ที่คุณเห็น
2) สำหรับแต่ละ failure mode, quote บรรทัดเฉพาะของ system prompt
ที่น่าจะก่อให้เกิดหรือเสริมมัน
3) อธิบายว่าบรรทัดเหล่านั้น steer agent ไปสู่ behavior ที่สังเกตได้อย่างไร
Return คำตอบใน structured format:
failure_modes:
- name: ...
description: ...
prompt_drivers:
- exact_or_paraphrased_line: ...
- why_it_matters: ...สร้าง Prompt Improvements
เมื่อมี diagnosis แล้ว prompt ที่สองสร้าง improvements:
คุณเพิ่งวิเคราะห์ system prompt นี้และ failure modes ของมัน
System prompt:
<system_prompt>
[PROMPT เดิม]
</system_prompt>
Failure-mode analysis:
[วาง DIAGNOSIS จากขั้นตอนก่อน]
โปรดเสนอ surgical revision ที่ลด issues ที่สังเกตได้ในขณะที่
รักษา behaviors ที่ดี
Constraints:
- อย่า redesign agent จากศูนย์
- เลือก edits เล็ก, ชัดเจน: ชี้แจง rules ที่ขัดแย้ง, ลบบรรทัด
redundant หรือ contradictory, เข้มงวด guidance ที่คลุมเครือ
- ทำ tradeoffs ชัดเจน
- รักษาโครงสร้างและความยาวใกล้เคียงกับ original
Output:
1) patch_notes: รายการกระชับของ key changes และ reasoning เบื้องหลังแต่ละอัน
2) revised_system_prompt: full updated prompt พร้อม edits ที่ apply แล้วกระบวนการสองขั้นตอนนี้ช่วยผมแก้ prompts ที่ผมดิ้นรนมาหลายวัน AI มักจะเห็นความขัดแย้งและความคลุมเครือที่ผมมองไม่เห็นแล้ว
Prompt Templates ที่ผ่านการทดสอบแล้ว
ให้ผมแชร์ templates บางอันที่พิสูจน์แล้วว่าเชื่อถือได้ในหลายร้อยกรณีการใช้งาน
Universal Task Completion Template
<context>
[ข้อมูลพื้นหลังที่ AI ต้องเข้าใจสถานการณ์]
</context>
<task>
[statement ชัดเจนว่าต้องการให้ทำอะไร]
</task>
<requirements>
[ข้อกำหนดหรือข้อจำกัดเฉพาะ]
</requirements>
<format>
[คุณต้องการให้ output มีโครงสร้างอย่างไร]
</format>
<examples>
[ตัวเลือก: ตัวอย่างของ output ที่ต้องการ]
</examples>
<notes>
[ตัวเลือก: context หรือ preferences เพิ่มเติม]
</notes>Code Review Template
<context>
คุณกำลัง review โค้ดสำหรับ [project/context]
Codebase ใช้ [technologies/patterns]
</context>
<code_to_review>
[วางโค้ดที่นี่]
</code_to_review>
<review_criteria>
Focus on:
1. ความถูกต้อง: มันทำในสิ่งที่ claim ไหม?
2. ความอ่านง่าย: ชัดเจนสำหรับ developers คนอื่นไหม?
3. Performance: มี inefficiencies ที่เห็นชัดไหม?
4. Security: มี vulnerabilities ไหม?
5. Style: match conventions ของ codebase ไหม?
</review_criteria>
<output_format>
สำหรับแต่ละ issue ที่พบ:
- Severity: [Critical/Major/Minor/Suggestion]
- Location: [เลข line หรือ section]
- Issue: [อะไรผิด]
- Fix: [แก้อย่างไร]
</output_format>Research Analysis Template
<research_task>
วิเคราะห์ [หัวข้อ/คำถาม] ด้วยแนวทางต่อไปนี้:
</research_task>
<methodology>
1. เริ่มด้วย targeted searches หลายอัน อย่าพึ่ง query เดียว
2. ค้นคว้าลึกจนมีข้อมูลเพียงพอสำหรับคำตอบที่แม่นยำ ครอบคลุม
3. เพิ่ม follow-up searches ที่เจาะจงเพื่อเติมช่องว่างหรือแก้ความไม่ตรงกัน
4. iterate ต่อจนกว่าการค้นหาเพิ่มเติมไม่น่าจะเปลี่ยนคำตอบ
</methodology>
<output_requirements>
- นำด้วยคำตอบชัดเจนสำหรับคำถามหลัก
- สนับสนุนด้วย evidence และ citations
- ยอมรับ limitations และ uncertainties
- ให้ตัวอย่างเฉพาะเมื่อช่วยได้
- รวม context ที่เกี่ยวข้องที่ช่วยเข้าใจ implications
</output_requirements>
<citation_format>
[คุณต้องการให้ cite sources อย่างไร]
</citation_format>ความผิดพลาดที่ทำลายผลลัพธ์
ให้ผมช่วยคุณหลีกเลี่ยงความผิดพลาดที่ผมทำ (ซ้ำแล้วซ้ำเล่า) ในช่วงแรกของ prompt engineering
"เขียนอะไรเกี่ยวกับ marketing ให้หน่อย" vs "เขียนบทความ blog 500 คำเกี่ยวกับ email marketing สำหรับ SaaS startups เน้น welcome sequences" ความเฉพาะเจาะจงคือทุกอย่าง
"กระชับ" และ "ละเอียด" ใน prompt เดียวกัน AI จะดิ้นรนประสานความขัดแย้ง ระบุ priorities และ tradeoffs ให้ชัด
AI ไม่รู้สิ่งที่คุณไม่ได้บอก ถ้าบางอย่างชัดเจนสำหรับคุณ มันอาจไม่ชัดสำหรับ model รวม background ที่เกี่ยวข้อง
ถ้าต้องการ JSON ก็บอก ถ้าต้องการ bullet points ก็บอก อย่าปล่อยให้ output format เป็นไปตามโชค
บางครั้ง prompt ง่ายดีที่สุด อย่าเพิ่มความซับซ้อนเพื่อความซับซ้อน เริ่มง่าย เพิ่มความซับซ้อนเมื่อจำเป็นเท่านั้น
การเขียน prompt เป็น iterative Prompt แรกของคุณคือ draft ปรับปรุงตามสิ่งที่ได้ผลและไม่ได้ผล
GPT และ Claude behave ต่างกัน Prompt ที่ optimize สำหรับอันหนึ่งอาจทำได้ไม่ดีบนอีกอัน ทดสอบข้าม models ถ้า application ของคุณ support หลายอัน
AI output มักต้องการ human review สร้าง prompts ที่ทำให้ review ง่าย—โครงสร้างชัด, assumptions ชัด, reasoning ติดตามได้
อนาคตของ Prompt Engineering
ขณะที่ผมเขียนบทความนี้ในต้นปี 2026 prompt engineering กำลังเปลี่ยนแปลงอย่างรวดเร็ว Models กำลังกลายเป็นมีความสามารถมากขึ้น, controllable มากขึ้น, และเชื่อถือได้มากขึ้น บางคนคาดการณ์ว่า prompt engineering จะล้าสมัยเมื่อ AI เข้าใจ intent ได้ดีขึ้น ผมไม่เห็นด้วย
สิ่งที่เปลี่ยนคือระดับของ prompt engineering ไม่ใช่ความจำเป็นของมัน ในช่วงแรกต้องมี prompts ที่ละเอียดสำหรับงานพื้นฐาน ตอนนี้ งานพื้นฐานใช้งานได้ทันที แต่ agentic workflows ที่ซับซ้อนยังต้องการ prompting ที่ซับซ้อน มาตรฐานกำลังเพิ่มขึ้น ไม่ใช่หายไป
Prompt engineering ไม่ได้หายไป—มัน evolve ทักษะที่สำคัญกำลังเปลี่ยนจาก "วิธีทำให้ AI ทำงาน" เป็น "วิธีทำให้ AI ทำงานได้ยอดเยี่ยมและเชื่อถือได้ในระดับ scale"
สิ่งที่กำลังมา
Default Behaviors ที่ดีขึ้น
Models จะมี defaults ที่ฉลาดกว่า ต้องการ instruction ชัดเจนน้อยลงสำหรับ patterns ทั่วไป Prompts จะเน้น customization มากกว่า basic capability
Tool Ecosystems ที่หลากหลายขึ้น
AI จะเข้าถึง tools มากขึ้นแบบ out of the box Prompt engineering จะเปลี่ยนไปสู่ orchestration—รู้ว่าเมื่อไหร่ใช้อะไร ไม่ใช่แค่ใช้อย่างไร
Multimodal Integration
Prompts จะเกี่ยวข้องกับ images, audio, video, และ structured data มากขึ้นควบคู่กับ text Prompt patterns ใหม่จะเกิดขึ้นสำหรับ multimodal tasks
Agentic Complexity
เมื่อ agents จัดการงานที่ยาวและซับซ้อนกว่า prompt engineering จะกลายเป็นเหมือน system design มากขึ้น—architecture ไม่ใช่แค่ instructions
คำแนะนำสำหรับอนาคต
เน้นพื้นฐาน เทคนิคเฉพาะในคู่มือนี้จะ evolve แต่หลักการพื้นฐาน—การสื่อสารที่ชัดเจน, ความคาดหวังที่ชัด, การคิดที่มีโครงสร้าง, การปรับปรุงแบบ iterative—เป็นสิ่งที่ไม่มีวันเปลี่ยน เชี่ยวชาญสิ่งเหล่านั้น และคุณจะปรับตัวกับอะไรก็ตามที่มาถัดไป
ความคิดสุดท้าย
สองปีก่อน ผมคิดว่า AI จะมาแทนที่ความจำเป็นในการสื่อสารอย่างชัดเจน ผมคิดผิดโดยสิ้นเชิง AI ทำให้การสื่อสารที่ชัดเจนมีค่ากว่าที่เคย คนที่เจริญรุ่งเรืองกับ AI ไม่ใช่คนที่หาคำวิเศษ—พวกเขาคือคนที่เรียนรู้ที่จะคิดและแสดงออกอย่างแม่นยำ
Prompt engineering ไม่ได้เกี่ยวกับ AI จริงๆ มันเกี่ยวกับคุณ มันเกี่ยวกับการพัฒนาวินัยในการอธิบายสิ่งที่คุณต้องการจริงๆ, ความอดทนที่จะ iterate ไปหามัน, และความอ่อนน้อมที่จะเรียนรู้จากสิ่งที่ไม่ได้ผล
ถ้าคุณจะเอาอะไรไปจากคู่มือนี้แค่อย่างเดียว ให้มันเป็นนี่: ปฏิบัติต่อทุก prompt เป็นโอกาสฝึกการคิดอย่างชัดเจน AI เป็นแค่กระจกที่สะท้อนความชัดเจน—หรือความสับสน—ของจิตใจคุณเอง
การเกิดขึ้นของ AI ไม่ได้ทำให้ความรู้ล้าสมัย—มันทำให้ความอยากรู้อยากเห็นทรงพลังกว่าที่เคย เราไม่ถูกจำกัดด้วยสิ่งที่เรารู้แล้วอีกต่อไป ด้วยเครื่องมือที่ถูกต้องและความเต็มใจที่จะคิด คนธรรมดาสามารถโอบกอดมหาสมุทรแห่งความรู้ ไม่ว่าอาชีพอะไร ไม่ว่าอายุเท่าไหร่ ผมหวังจะแบ่งปันการเดินทางนี้กับเพื่อนๆ ทั่วโลก มาต้อนรับโลกใหม่นี้ด้วยกัน มาเติบโตด้วยกัน


การสนทนา
0 ความคิดเห็นแสดงความคิดเห็น
เป็นคนแรกที่แบ่งปันความคิดของคุณ!