ความแตกต่างระหว่างภาพ AI ที่น่าหงุดหงิดกับภาพที่น่าทึ่งไม่ใช่พรสวรรค์หรือโชค — มันคือการเรียนรู้ที่จะพูดภาษาภาพที่เครื่องจักรเข้าใจ
ผมยังจำช่วงเวลาที่ทุกอย่างเปลี่ยนไปได้แม่นยำ มันเป็นเวลาตี 2 ของคืนวันอังคาร ผมจ้องมองหน้าจอมาหลายชั่วโมง วนเวียนอยู่กับคำสั่ง (prompt) แล้วคำสั่งเล่า เฝ้าดู ChatGPT พ่นภาพที่ดูไม่เหมือนสิ่งที่ผมจินตนาการไว้ออกมา นิ้วมือที่มีกายวิภาคที่เป็นไปไม่ได้ ข้อความที่ละลายกลายเป็นภาษาต่างดาว ตัวละครที่ดูเหมือนจะต่อต้านความตั้งใจของผมอย่างแข็งขัน ผมพร้อมที่จะยอมแพ้กับการสร้างภาพด้วย AI โดยสิ้นเชิง — ที่จะปัดตกมันว่าเป็นเทคโนโลยีที่ถูกโฆษณาเกินจริงซึ่งใช้ได้ผลกับคนอื่นเท่านั้น
จากนั้นผมก็ลองทำสิ่งที่แตกต่างออกไป แทนที่จะบรรยายสิ่งที่ผมอยากเห็น ผมบรรยายสิ่งที่กล้องจะถ่าย แทนที่จะขอ "พระอาทิตย์ตกที่สวยงาม" ผมเขียนว่า "แสงสีทองส่องผ่านยอดเขา ถ่ายด้วย Canon 5D Mark IV, เลนส์ 24-70mm ที่ f/2.8, การเกรดสีแบบธรรมชาติ" ภาพที่ปรากฏขึ้นไม่ได้แค่ยอมรับได้ — มันน่าทึ่ง สมจริงเหมือนภาพถ่าย ตรงกับสิ่งที่เคยมีอยู่แค่ในจินตนาการของผมเมื่อครู่ก่อนหน้านี้
การเปลี่ยนมุมมองเพียงครั้งเดียวนั้นปลดล็อกทุกอย่าง ในช่วงหลายเดือนต่อมา ผมเจาะลึก ผมสร้างภาพหลายพันภาพ ผมทดสอบทุกเทคนิคที่หาได้ ผมอ่านเอกสารของ OpenAI ตั้งแต่หน้าแรกจนหน้าสุดท้าย ผมทดลองกับ GPT Image 1.5 ในวันที่เปิดตัว และตอนนี้ผมจะแบ่งปันทุกสิ่งที่ผมได้เรียนรู้ — ไม่ใช่เคล็ดลับผิวเผินที่คุณจะหาได้จากที่อื่น แต่เป็นความรู้เชิงลึกที่แยกมืออาชีพออกจากมือสมัครเล่น นี่คือคู่มือที่ผมหวังว่าจะมีตอนที่ผมเริ่มต้น นี่คือวิธีที่คุณจะเปลี่ยนจากมือใหม่ที่สับสนเป็นนักสร้างสรรค์ที่มั่นใจ
การเดินทางของผมสู่การสร้างภาพด้วย AI
ขอผมพาคุณย้อนกลับไปที่จุดเริ่มต้น เช่นเดียวกับหลายๆ คนที่อ่านบทความนี้ ตอนแรกผมสงสัยเกี่ยวกับการสร้างภาพด้วย AI "มันก็แค่ของเล่นสำหรับคนบ้าเทคโนโลยี" ผมคิด "งานสร้างสรรค์จริงๆ ยังคงต้องใช้ทักษะจริงๆ" ผมคิดผิดถนัด
ความต้องการภาพ AI จริงๆ ครั้งแรกของผมมาจากปัญหาในทางปฏิบัติ ผมกำลังสร้างคอนเทนต์สำหรับโปรเจกต์หนึ่งและต้องการภาพหน้าปก — จำนวนมาก ผมต้องจ่ายเงินค่าภาพสต็อก ควักเงินจ่ายภาพทั่วไปที่นักสร้างสรรค์คนอื่นๆ ก็ใช้เหมือนกัน ภาพพวกนั้นก็โอเค แต่มันขาดจิตวิญญาณ มันรู้สึกเหมือนยืมมา ไม่ใช่ของตัวเอง
เพื่อนคนหนึ่งบอกว่า ChatGPT สามารถสร้างภาพได้แล้ว "แค่บรรยายสิ่งที่คุณต้องการ" เธอบอก "มันเหมือนเวทมนตร์" ดังนั้นผมจึงลองดู Prompt แรกของผมไร้เดียงสาจนน่าอาย: "พระอาทิตย์ตกสวยงามเหนือภูเขา" ผลลัพธ์? เละเทะเหมือนสีน้ำที่ถูกทิ้งไว้กลางฝน ผมรู้สึกผิดหวังอย่างน้อยที่สุด
แต่มีบางอย่างดึงผมกลับมา ผมลองอีกครั้ง และอีกครั้ง ความล้มเหลวแต่ละครั้งสอนผมสิ่งใหม่เกี่ยวกับวิธีที่ AI ตีความภาษา ผมเริ่มสังเกตเห็นรูปแบบ — วลีบางอย่างที่ให้ผลลัพธ์ที่ดีกว่าอย่างสม่ำเสมอ วิธีการเชิงโครงสร้างที่นำทางโมเดลไปสู่วิสัยทัศน์ของผมแทนที่จะห่างออกไป
จุดเปลี่ยนมาถึงเมื่อผมตระหนักว่า: การสร้างภาพด้วย AI ไม่ใช่การบรรยายสิ่งที่คุณเห็นในใจ — แต่เป็นการบรรยายสิ่งที่กล้องจะจับภาพในความเป็นจริง การเปลี่ยนมุมมองเพียงครั้งเดียวนั้นเปลี่ยนทุกอย่าง
ผมเลิกคิดแบบคนช่างฝันและเริ่มคิดแบบช่างภาพ แทนที่จะใช้คำว่า "พระอาทิตย์ตกที่สวยงาม" ผมเขียนเกี่ยวกับแสงสีทอง (golden hour), รุ่นกล้องเฉพาะ, ระยะโฟกัสของเลนส์, การตั้งค่ารูรับแสง, ฟิล์ม AI เข้าใจภาษานี้เพราะมันถูกฝึกฝนด้วยภาพล้านๆ ภาพที่มาพร้อมกับข้อมูลเมตาทางเทคนิคแบบนี้
ในช่วงหลายเดือนต่อมา ผมกลายเป็นคนหมกมุ่น ผมสร้างภาพหลายพันภาพในทุกสไตล์และกรณีการใช้งานที่ผมนึกออก ผมอ่านเอกสารทุกชิ้นที่ OpenAI เผยแพร่ ผมเข้าร่วมชุมชนของนักสร้างสรรค์ที่ผลักดันขอบเขตของสิ่งที่เป็นไปได้ และเมื่อ GPT Image 1.5 เปิดตัวในเดือนมกราคม 2026 ผมก็พร้อม ผมเข้าใจไม่เพียงแต่วิธีใช้มัน แต่ยังเข้าใจว่าทำไมมันถึงทำงานแบบนั้น
ตอนนี้ผมจะแบ่งปันทุกสิ่งที่ผมได้เรียนรู้ ไม่ใช่เคล็ดลับผิวเผินที่คุณจะพบในคู่มืออีกร้อยเล่ม ความรู้เชิงลึกที่มาจากการทดลองอย่างกว้างขวาง การทดสอบอย่างเป็นระบบ และการสนทนานับไม่ถ้วนกับนักสร้างสรรค์คนอื่นๆ ที่กำลังผลักดันเครื่องมือเหล่านี้ให้ถึงขีดสุด นี่คือคู่มือฉบับสมบูรณ์ — เล่มที่จะพาคุณจากมือใหม่ที่สับสนไปสู่นักสร้างสรรค์ที่มั่นใจ
ChatGPT Image Generator คืออะไร
ก่อนที่เราจะดำดิ่งลงสู่เทคนิค ขอผมชี้แจงให้ชัดเจนว่าเรากำลังทำงานกับอะไร ChatGPT image generator เป็นระบบสร้างและแก้ไขภาพแบบบูรณาการของ OpenAI ปัจจุบันขับเคลื่อนโดยโมเดล GPT Image 1.5 ของพวกเขา ต่างจากเครื่องมือแยกต่างหากอย่าง Midjourney หรือ Stable Diffusion มันถูกรวมเข้ากับอินเทอร์เฟซการสนทนาของ ChatGPT อย่างลึกซึ้ง
การบูรณาการนี้มีความสำคัญมากกว่าที่คุณคิด เพราะ ChatGPT เข้าใจบริบท มันจึงสามารถรักษาความสม่ำเสมอในการสร้างหลายครั้ง จดจำความชอบของคุณภายในเซสชัน และแม้แต่ใช้เหตุผลเกี่ยวกับสิ่งที่คุณพยายามสร้าง บอกมันว่าคุณกำลังทำหนังสือเด็ก และมันจะปรับสไตล์ให้เหมาะสม พูดถึงว่าคุณต้องการภาพสำหรับการนำเสนอของบริษัท และมันจะเปลี่ยนไปสู่สุนทรียศาสตร์ที่สะอาดและเป็นมืออาชีพ การตระหนักรู้บริบทนี้เป็นสิ่งที่เครื่องมือสร้างภาพแบบแยกต่างหากไม่สามารถเทียบได้
🎨 การสร้างภาพจากข้อความ (Text-to-Image)
บรรยายอะไรก็ได้ด้วยภาษาธรรมชาติและดูมันปรากฏขึ้น ตั้งแต่ภาพพอร์ตเทรตที่สมจริงเหมือนภาพถ่ายไปจนถึงศิลปะนามธรรม จากแบบจำลองผลิตภัณฑ์ไปจนถึงทิวทัศน์แฟนตาซี — ถ้าคุณบรรยายได้ AI ก็สร้างได้
✏️ การแก้ไขภาพที่แม่นยำ
อัปโหลดภาพที่มีอยู่และแก้ไขด้วยคำสั่งข้อความ เปลี่ยนสี สลับวัตถุ ปรับแสง เปลี่ยนฤดูกาล หรือจินตนาการฉากใหม่ทั้งหมดในขณะที่ยังคงองค์ประกอบที่คุณต้องการเก็บไว้
🔄 การถ่ายโอนสไตล์ (Style Transfer)
นำภาษาภาพจากภาพหนึ่ง — จานสี พื้นผิว ฝีแปรง หรือสุนทรียศาสตร์ — และนำไปใช้กับเนื้อหาใหม่ทั้งหมด เหมาะสำหรับการรักษาความสม่ำเสมอของแบรนด์หรือสร้างซีรีส์ที่เชื่อมโยงกัน
📝 การเรนเดอร์ข้อความที่เชื่อถือได้
ในที่สุด AI ที่สะกดคำได้จริงๆ GPT Image 1.5 จัดการข้อความในภาพด้วยความแม่นยำอย่างที่ไม่เคยมีมาก่อน — เหมาะสำหรับโลโก้ โปสเตอร์ อินโฟกราฟิก และวัสดุทางการตลาดที่คำพูดมีความสำคัญ
มันทำงานอย่างไรจริงๆ
เมื่อคุณส่งคำสั่ง (prompt) ไปยังตัวสร้างภาพของ ChatGPT หลายสิ่งเกิดขึ้นเบื้องหลัง ก่อนอื่น ChatGPT จะประมวลผลคำขอของคุณ อาจขยายหรือชี้แจงคำสั่งของคุณตามบริบท มันอาจเพิ่มรายละเอียดที่คุณบอกเป็นนัยแต่ไม่ได้ระบุ หรือจัดโครงสร้างคำขอของคุณในแบบที่โมเดลภาพเข้าใจได้ดีขึ้น
จากนั้นคำขอจะไปที่โมเดลสร้างภาพ — ปัจจุบันคือ GPT Image 1.5 — ซึ่งจะแปลงคำบรรยายของคุณเป็นผลลัพธ์ภาพ โมเดลนี้ถูกฝึกฝนด้วยชุดข้อมูลภาพขนาดมหึมาที่จับคู่กับคำบรรยายโดยละเอียด เรียนรู้ความสัมพันธ์ที่ซับซ้อนระหว่างภาษากับองค์ประกอบภาพ
ผลลัพธ์คือระบบที่เข้าใจสิ่งที่คุณขอจริงๆ ไม่ใช่แค่จับคู่คำหลัก ขอ "ช่วงเวลาเผลอที่สมจริง" และคุณจะได้สิ่งที่ให้ความรู้สึกว่าไม่ได้จัดฉากจริงๆ ขอ "แสงเช้าผ่านมู่ลี่" และคุณจะได้รูปแบบแถบเฉพาะที่มันสร้างขึ้น
GPT Image 1.5 ได้อันดับหนึ่งใน Artificial Analysis Image Arena สำหรับทั้งการสร้างภาพจากข้อความและการแก้ไขภาพ ด้วยอัตราการปฏิบัติตามคำสั่ง 90% — สูงกว่าคู่แข่งที่ใกล้ที่สุดถึง 13 เปอร์เซ็นต์ นี่ไม่ใช่คำพูดทางการตลาด แต่มันสะท้อนถึงก้าวกระโดดที่แท้จริงในด้านความสามารถ
การปฏิวัติ GPT Image 1.5
เมื่อ OpenAI ปล่อย GPT Image 1.5 ในเดือนมกราคม 2026 พวกเขาไม่ได้แค่ปรับปรุงโมเดลก่อนหน้า — พวกเขาสร้างรากฐานใหม่ ผมใช้งานเวอร์ชันก่อนหน้ามาอย่างกว้างขวาง ดังนั้นผมจึงสังเกตเห็นความแตกต่างได้ทันที นี่ไม่ใช่การปรับปรุงทีละน้อย แต่เป็นการเปลี่ยนกระบวนทัศน์
ขอผมระบุให้ชัดเจนว่ามีอะไรเปลี่ยนแปลงบ้าง เพราะการเข้าใจการปรับปรุงเหล่านี้จะช่วยให้คุณใช้ประโยชน์จากมันได้อย่างมีประสิทธิภาพ
สามความก้าวหน้าที่สำคัญ
โมเดลก่อนหน้านี้มีแนวโน้มที่จะเพี้ยนจนน่าหงุดหงิด คุณขอให้เปลี่ยนสิ่งหนึ่ง และอีกสามอย่างก็จะเปลี่ยนไปโดยไม่คาดคิด แก้ไขแสง แล้วจู่ๆ หน้าตัวละครก็เปลี่ยนไป GPT Image 1.5 เข้าใจจริงๆ ว่า "เปลี่ยนเฉพาะองค์ประกอบนี้" — มันสามารถแก้ไขส่วนที่เฉพาะเจาะจงในขณะที่ยังคงแสง องค์ประกอบ ลักษณะใบหน้า หรือแม้แต่พื้นผิวที่ละเอียดอ่อนไว้ได้ นี่ทำให้การปรับแต่งซ้ำๆ เป็นไปได้จริง
ความเร็วในการสร้างเพิ่มขึ้นถึง 400% เมื่อเทียบกับเวอร์ชันก่อนหน้า สิ่งที่เคยใช้เวลา 30 วินาที ตอนนี้ใช้เวลา 7-8 วินาที แต่ที่สำคัญกว่านั้น คุณสามารถต่อคิวการสร้างใหม่ในขณะที่อันปัจจุบันยังประมวลผลอยู่ สิ่งนี้เปลี่ยนกระบวนการสร้างสรรค์จาก "ส่งแล้วรอ" เป็น "สำรวจและทำซ้ำ" ความแตกต่างทางจิตวิทยานั้นสำคัญมาก — ลูปข้อเสนอแนะที่เร็วขึ้นหมายถึงการทดลองที่มากขึ้น
การเรนเดอร์ข้อความในภาพ AI เคยเป็นหายนะ — สะกดผิด ซ้ำซ้อน ตัวอักษรที่ละลายเป็นรูปร่างนามธรรม GPT Image 1.5 จัดการข้อความที่หนาแน่นและมีขนาดเล็กได้ในขณะที่ยังคงรักษารูปแบบตัวอักษร การจัดวาง และความชัดเจนที่เหมาะสม สิ่งนี้เปิดโอกาสให้แก่อินโฟกราฟิก วัสดุทางการตลาด แบบจำลอง UI และกรณีการใช้งานใดๆ ที่คำปรากฏในภาพ เป็นครั้งแรกที่ผมสามารถสร้างสไลด์นำเสนอ กราฟิกโซเชียลมีเดียพร้อมคำบรรยาย และฉลากผลิตภัณฑ์ที่ผมจะใช้งานจริงๆ
เข้าใจการตั้งค่าคุณภาพ
GPT Image 1.5 เสนอระดับคุณภาพที่แตกต่างกัน และการเข้าใจว่าเมื่อใดควรใช้อันไหนจะช่วยประหยัดเวลาและปรับปรุงผลลัพธ์ของคุณ นี่ไม่ใช่แค่เรื่องคุณภาพผลลัพธ์ — แต่เป็นการจับคู่เครื่องมือที่เหมาะสมกับงานที่เหมาะสม
⚡ โหมดคุณภาพต่ำ (Low Quality Mode)
อย่าให้ชื่อหลอกคุณ — "คุณภาพต่ำ" ที่นี่หมายถึง "เร็วและมีประสิทธิภาพ" ผลลัพธ์ยังคงดีอย่างน่าทึ่งสำหรับกรณีการใช้งานส่วนใหญ่ ใช้สิ่งนี้สำหรับ:
- การสำรวจแนวคิดเบื้องต้นและการระดมสมอง
- การทำซ้ำอย่างรวดเร็วเมื่อปรับแต่งไอเดีย
- องค์ประกอบที่เรียบง่ายไม่มีรายละเอียดละเอียดอ่อน
- การสร้างปริมาณมากที่ความเร็วสำคัญ
- ฉบับร่างก่อนที่จะตกลงทำเวอร์ชันสุดท้าย
✨ โหมดคุณภาพสูง (High Quality Mode)
เมื่อทุกพิกเซลมีความสำคัญและคุณต้องการผลลัพธ์ที่พร้อมสำหรับการเผยแพร่ เก็บสิ่งนี้ไว้สำหรับ:
- ภาพการผลิตขั้นสุดท้ายสำหรับการส่งมอบ
- งานข้อความหนาแน่นและงานตัวอักษร
- อินโฟกราฟิกที่ซับซ้อนพร้อมรายละเอียดเล็กๆ
- พอร์ตเทรตที่สมจริงเหมือนภาพถ่ายที่พื้นผิวมีความสำคัญ
- ภาพใดๆ ที่คุณต้องการความเที่ยงตรงสูงสุด
การตั้งค่าความเที่ยงตรงของอินพุตที่ซ่อนอยู่ (Input Fidelity)
นี่คือสิ่งที่คู่มือส่วนใหญ่จะไม่บอกคุณ: เมื่อแก้ไขภาพ มีพารามิเตอร์ที่เรียกว่า input_fidelity ซึ่งมีผลต่อผลลัพธ์อย่างมาก ตั้งค่าเป็น "high" เมื่อคุณต้องการรักษาลักษณะใบหน้า รักษาเอกลักษณ์ในการแก้ไข หรือเปลี่ยนแปลงฉากที่สำคัญ โมเดลจะทำงานหนักขึ้นเพื่อรักษาลักษณะสำคัญของภาพต้นฉบับไว้
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # เคล็ดลับสำหรับการรักษาเอกลักษณ์
quality="high",
image=[open("portrait.png", "rb")],
prompt="Change the background to a sunset beach while preserving the person's exact appearance"
)การผสมผสานนี้ช่วยให้มั่นใจได้ว่าจะรักษาตัวแบบดั้งเดิมไว้ได้สูงสุดในขณะที่ใช้การเปลี่ยนแปลงที่คุณร้องขอ
การเปลี่ยนแปลงที่ใหญ่ที่สุดกับ GPT Image 1.5 ไม่ใช่ทางเทคนิค — แต่เป็นทางปรัชญา การสร้างภาพย้ายจาก "สั่งและภาวนา" เป็น "สั่งและทำซ้ำ" สิ่งนี้ต้องการโมเดลทางความคิดที่แตกต่างไปจากเดิมอย่างสิ้นเชิงสำหรับวิธีที่คุณเข้าถึงการสร้างภาพ
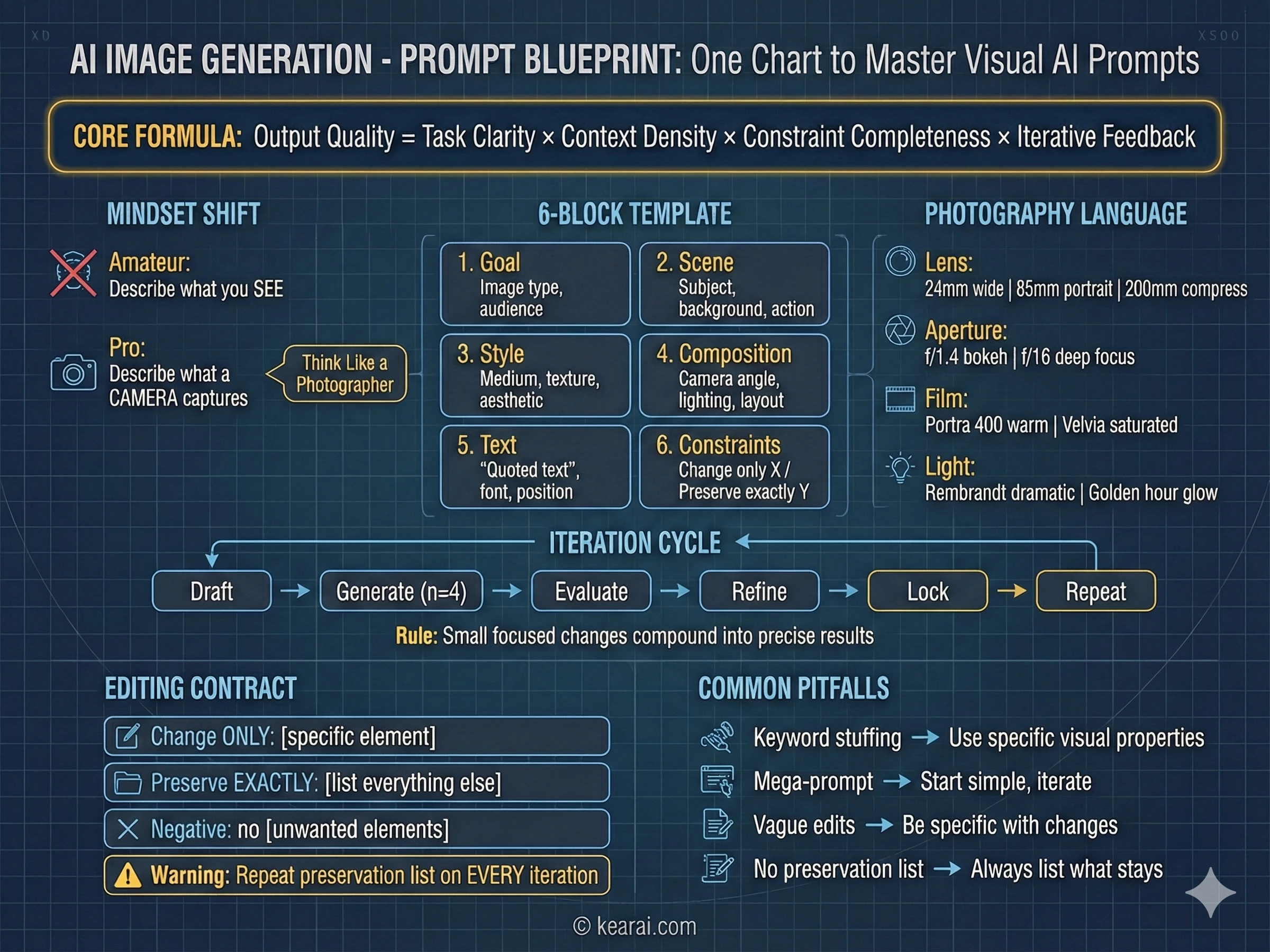
กรอบการเขียน Prompt ที่เปลี่ยนทุกอย่าง
หลังจากสร้างภาพหลายพันภาพ ผมได้พัฒนากรอบงานที่สร้างผลลัพธ์ที่ยอดเยี่ยมอย่างสม่ำเสมอ ลืมทุกสิ่งที่คุณเคยอ่านเกี่ยวกับการเพิ่ม "masterpiece, trending on ArtStation, ultra-detailed, 8K resolution" ลงใน Prompt ของคุณ คำหลักเหล่านั้นใช้ได้ผลกับโมเดลรุ่นเก่าที่ต้องการคำใบ้คุณภาพ แต่ GPT Image 1.5 ตอบสนองต่อโครงสร้างและความเฉพาะเจาะจง ไม่ใช่การยัดเยียดคำหลัก
ผมเรียกมันว่าสถาปัตยกรรม Prompt แบบมีโครงสร้าง และทุก Prompt ที่มีประสิทธิภาพที่ผมเขียนตอนนี้จะทำตามรูปแบบนี้
Goal/Output:
- [Type of image: ad, UI mockup, infographic, photo, illustration]
- [Intended use and audience]
Scene:
- [Background/environment description]
- [Main subject with specific details]
- [Action or relationship between elements]
Style:
- [Medium: photograph, watercolor, 3D render, vector illustration]
- [Key textures: matte, glossy, grainy, smooth, organic]
- [Quality descriptors: realistic imperfections, stylized, minimalist]
Composition/Layout:
- [Camera position: close-up, wide shot, aerial view, eye-level]
- [Lighting: golden hour, studio strobes, overcast, dramatic shadows]
- [Element placement: centered, rule of thirds, negative space, margins]
Text (if any):
- "Exact text in quotes"
- [Font style, size, color, position]
- [Specify: render only once, no duplicates]
Constraints:
- Change ONLY: [specific element if editing]
- Preserve exactly: [elements that must stay unchanged]
- Negative: no watermark, no extra text, no logos, no [unwanted elements]กรอบงานนี้ให้บริบทที่ชัดเจนแก่โมเดลสำหรับการตัดสินใจทางสายตาทุกอย่างที่ต้องทำ
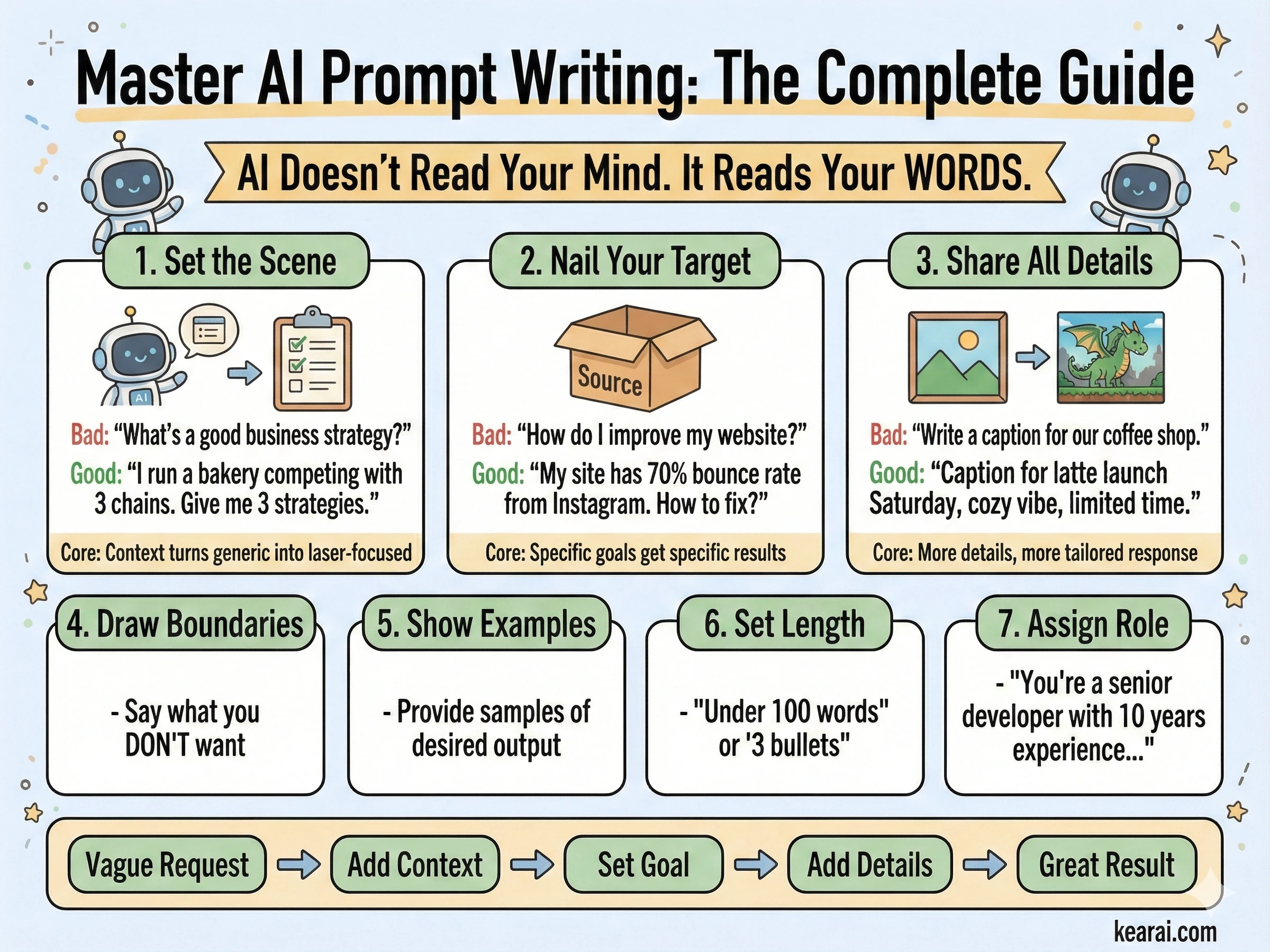
หลักการ 7 ประการของการ Prompt ที่มีประสิทธิภาพ
นอกจากโครงสร้างแล้ว หลักการเหล่านี้ยังควบคุมวิธีที่ผมเขียนทุก Prompt พวกมันคือความแตกต่างระหว่างภาพที่เกือบจะใช้ได้กับภาพที่ตรงกับวิสัยทัศน์ของคุณเป๊ะๆ
โครงสร้างสำคัญกว่าคำหลัก
ใช้ลำดับที่สม่ำเสมอ: พื้นหลัง → ตัวแบบ → รายละเอียด → ข้อจำกัด สำหรับคำขอที่ซับซ้อน ให้ใช้ส่วนที่มีป้ายกำกับหรือการขึ้นบรรทัดใหม่ ย่อหน้าที่ยาวเหยียดทำให้โมเดลสับสน โครงสร้างที่เป็นระเบียบจะนำทางโมเดลไปสู่ความตั้งใจของคุณ
ความเฉพาะเจาะจงสำคัญกว่าคำคุณศัพท์
แทนที่จะใช้ "high quality" หรือ "ultra-detailed" ให้บรรยายคุณสมบัติทางสายตาจริงๆ วัสดุ พื้นผิว รูปทรง สื่อ "Visible skin pores and subtle freckles" (รูขุมขนที่มองเห็นได้และกระที่ละเอียดอ่อน) ชนะ "highly detailed face" (ใบหน้าที่ละเอียดมาก) ทุกครั้ง
การควบคุมองค์ประกอบที่ชัดเจน
ระบุการจัดเฟรมของคุณ (close-up, wide shot, bird's eye), มุมมอง (eye-level, low-angle, Dutch angle), และอารมณ์แสง (soft diffuse, golden hour, high-contrast rim light) อย่าปล่อยให้สิ่งเหล่านี้เป็นเรื่องของโชคชะตา
สัญญาการเปลี่ยนแปลง vs การรักษาไว้
สำหรับการแก้ไข ให้ระบุอย่างชัดเจนว่าอะไรควรเปลี่ยน และอะไรควรคงเดิม ใช้ "change only X" และ "preserve exactly Y" ทำซ้ำรายการรักษาไว้นี้ในการทำซ้ำทุกครั้งเพื่อป้องกันความคลาดเคลื่อน
ข้อความต้องการความแม่นยำ
ใส่ข้อความที่ต้องการใน "เครื่องหมายคำพูด" หรือตัวพิมพ์ใหญ่ทั้งหมด ระบุสไตล์ตัวอักษร ขนาด สี และตำแหน่ง สำหรับคำยากๆ หรือชื่อแบรนด์ ให้สะกดทีละตัวอักษร เติม "render exactly once, no duplicates" เสมอ
ความชัดเจนของการอ้างอิงหลายภาพ
เมื่อทำงานกับภาพอินพุตหลายภาพ ให้อ้างอิงแต่ละภาพด้วยดัชนีและคำอธิบาย: "Image 1: the product shot, Image 2: the style reference" ระบุอย่างชัดเจนว่าพวกมันควรโต้ตอบกันอย่างไร
ทำซ้ำ (Iterate) แทนที่จะใส่ข้อมูลมากเกินไป
เริ่มด้วย Prompt พื้นฐานที่สะอาด แล้วปรับแต่งด้วยการเปลี่ยนแปลงเล็กๆ ทีละอย่าง "Make the lighting warmer." "Remove the background tree." ขั้นตอนเล็กๆ รวมกันเป็นผลลัพธ์ที่แม่นยำ
ความผิดพลาดที่พบบ่อยที่สุด
ข้อผิดพลาดที่ใหญ่ที่สุดที่ผมเห็นผู้คนทำ: พยายามระบุทุกอย่างใน Prompt ใหญ่ยักษ์เดียว โดยหวังว่าโมเดลจะเข้าใจได้เอง แทบไม่เคยได้ผลดีเลย เริ่มด้วย Prompt ที่ง่ายกว่าเพื่อสร้างฐาน จากนั้นทำซ้ำด้วยการปรับแต่งที่ตรงจุด คุณจะได้ผลลัพธ์ที่ดีกว่าในเวลาที่น้อยกว่าพร้อมความล้มเหลวที่น่าหงุดหงิดน้อยกว่ามาก
กรอบความคิดแบบช่างภาพ
การปรับปรุงผลลัพธ์ครั้งใหญ่ที่สุดเพียงครั้งเดียวของผมมาจากการเปลี่ยนความคิด: ผมเลิกคิดเหมือนศิลปินที่บรรยายวิสัยทัศน์ และเริ่มคิดเหมือนช่างภาพที่บรรยายการถ่ายภาพ นี่ไม่ใช่แค่การเปรียบเทียบ — เป็นเทคนิคที่ใช้งานได้จริงซึ่งใช้ประโยชน์จากวิธีการฝึกฝนโมเดล
โมเดลภาพ AI เรียนรู้จากภาพถ่ายหลายล้านภาพที่มาพร้อมกับข้อมูลเมตา: รุ่นกล้อง, สเปกเลนส์, การตั้งค่ารูรับแสง, สภาพแสง เมื่อคุณใช้ภาษานี้ คุณกำลังกระตุ้นความเข้าใจเชิงลึกของโมเดลเกี่ยวกับวิธีการที่กล้องจริงจับภาพฉากจริง
ภาษาการถ่ายภาพที่ได้ผล
- การเลือกเลนส์: "24mm wide angle" สร้างฉากที่กว้างใหญ่พร้อมการบิดเบือนที่ขอบ; "200mm telephoto" บีบอัดความลึกและแยกวัตถุ
- ความรู้สึกของรูรับแสง: "f/1.4 bokeh" ให้พื้นหลังเบลอแบบครีมมี่สำหรับพอร์ตเทรต; "f/16 deep focus" เก็บทุกอย่างให้คมชัดสำหรับทิวทัศน์
- สต็อกฟิล์ม: "Kodak Portra 400" สำหรับโทนสีผิวที่อบอุ่นและดูดี; "Fuji Velvia" สำหรับทิวทัศน์ที่สดใสและอิ่มตัว; "Ilford HP5" สำหรับขาวดำที่มีคอนทราสต์
- การจัดแสง: "Rembrandt lighting" สำหรับพอร์ตเทรตที่น่าทึ่ง; "butterfly lighting" สำหรับภาพความงาม; "golden hour backlight" สำหรับขอบที่เรืองแสงอย่างน่าอัศจรรย์
- การเคลื่อนไหวของกล้อง: "long exposure motion blur" สำหรับพลังงานไดนามิก; "high-speed freeze frame" สำหรับจับภาพแอ็คชั่น
แทนที่จะพูดว่า "ทำให้ดูเป็นมืออาชีพ" ให้ลอง "shot on Hasselblad medium format, studio strobe lighting, seamless gray backdrop, color-calibrated for print reproduction" แทนที่จะเป็น "realistic portrait" ให้ลอง "candid photograph, 85mm f/1.4 lens, window light from camera left, subtle fill from reflector, visible skin texture with pores, shot on Sony A7R IV"
❌ ก่อน (คลุมเครือ):
"A beautiful portrait of an old fisherman, very detailed, high quality, realistic"
✅ หลัง (กรอบความคิดแบบช่างภาพ):
"Candid documentary photograph of an elderly fisherman on a weathered wooden boat.
Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind eyes.
Gray stubble. Faded traditional anchor tattoo on forearm. Salt-stained navy wool
sweater, worn cap.
Early morning coastal light, soft fog diffusing the sun. Medium close-up at eye
level, 50mm lens, f/2.8, shallow depth of field. Shot like 35mm film with subtle
grain, natural color balance.
Documentary style — honest, unretouched, capturing a real moment. No glamorization."กรอบความคิดแบบช่างภาพเปลี่ยนความปรารถนาที่คลุมเครือให้เป็นข้อมูลจำเพาะทางภาพที่แม่นยำซึ่งโมเดลเข้าใจอย่างลึกซึ้ง
เมื่อคุณบรรยายภาพโดยใช้ภาษาการถ่ายภาพ คุณไม่ได้แค่เฉพาะเจาะจงมากขึ้น — คุณกำลังพูดภาษาที่โมเดลถูกฝึกให้เข้าใจ สเปกกล้อง การจัดแสง และสต็อกฟิล์มไม่ใช่คำหลักสุ่มๆ; พวกมันเข้ารหัสข้อมูลภาพที่แม่นยำซึ่งโมเดลสามารถถอดรหัสได้อย่างถูกต้อง
ความเชี่ยวชาญด้าน Text-to-Image
การสร้างภาพจากคำบรรยายข้อความล้วนๆ เป็นจุดเริ่มต้นที่คนส่วนใหญ่เริ่มการเดินทางกับภาพ AI มันยังเป็นที่ที่ช่องว่างระหว่างผลลัพธ์ของมือสมัครเล่นและมืออาชีพเห็นได้ชัดเจนที่สุด ให้ผมแนะนำคุณผ่านเทคนิคที่สร้างผลลัพธ์ที่ยอดเยี่ยมอย่างสม่ำเสมอในกรณีการใช้งานต่างๆ
ภาพสมจริงที่ให้ความรู้สึกเป็นธรรมชาติ
กุญแจสู่ความสมจริงนั้นสวนทางกับความรู้สึก: คุณต้อง Prompt เพื่อความไม่สมบูรณ์ ผิวที่สมบูรณ์แบบ แสงที่สมบูรณ์แบบ องค์ประกอบที่สมบูรณ์แบบ — สิ่งเหล่านี้ตะโกนว่า "AI สร้าง" ความเป็นจริงนั้นยุ่งเหยิงกว่า และความยุ่งเหยิงนั้นคือสิ่งที่ทำให้ภาพรู้สึกจริง
Create a photorealistic candid photograph of an elderly sailor standing on a small fishing boat.
Subject: Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind
eyes with crow's feet. Gray stubble, a few days unshaven. Faded traditional anchor
tattoo on forearm. Salt-stained navy wool sweater, worn and pilled. Creased cap
with faded insignia.
Setting: Early morning on the water, soft coastal fog diffusing the light. Aged
wooden boat deck with peeling paint, fishing nets in background, coiled rope.
Technical: Shot like 35mm film photography, medium close-up at eye level, 50mm
lens, shallow depth of field with boat blurred behind him. Subtle film grain,
natural color balance without heavy grading.
The image should feel like a real moment captured by a photojournalist — honest,
unposed, with real skin texture, worn materials, and everyday imperfection. No
glamorization, no heavy retouching, no artificial perfection.สังเกตว่าเราขอความไม่สมบูรณ์อย่างชัดเจน — ผิวที่ผ่านแดดลม วัสดุที่เก่า สีที่หลุดลอก ความจริงมีพื้นผิว
อินโฟกราฟิกและการแสดงข้อมูลเป็นภาพ
การเรนเดอร์ข้อความที่ได้รับการปรับปรุงใน GPT Image 1.5 ทำให้อินโฟกราฟิกเป็นกรณีการใช้งานที่ใช้งานได้จริงอย่างแท้จริง ตอนนี้ผมสร้างกราฟิกข้อมูลคุณภาพระดับมืออาชีพที่ผมใช้ในงานของผมจริงๆ
Create a detailed infographic explaining how a coffee machine works.
Structure:
- Title at top: "The Journey of Your Morning Coffee"
- Vertical flow diagram showing: bean hopper → grinder → portafilter →
grouphead → water heating → extraction → cup
- Each step has an icon and 1-2 sentence explanation
- Warm color palette (browns, creams, copper accents)
- Clean, modern design with plenty of white space
- Subtle coffee stain texture in background corners
Style: Professional print-quality infographic, vector-style icons, clear
hierarchy, readable at A4 size.
Typography: Clean sans-serif headings, readable body text, clear visual
hierarchy between title, section headers, and explanatory text.
No watermarks. No stock photo elements. Original illustration only.สำหรับข้อความที่หนาแน่นและการจัดวางที่ซับซ้อน ให้ใช้ quality="high" เสมอเพื่อให้แน่ใจว่าข้อความยังคงคมชัดและอ่านง่าย
การออกแบบโลโก้และแบรนด์
การสร้างโลโก้ต้องให้ความสำคัญกับความเรียบง่ายและความสามารถในการขยายขนาด โลโก้ที่ดีจะทำงานได้ในทุกขนาด ตั้งแต่ไอคอน Favicon ขนาดเล็กไปจนถึงป้ายโฆษณาขนาดใหญ่ นี่คือวิธีการ Prompt สำหรับการออกแบบที่ทำหน้าที่เป็นโลโก้ได้จริง
Create an original logo for "Field & Flour" — a local artisan bakery.
Brand personality: Warm, authentic, handcrafted, timeless. Not trendy or corporate.
Design requirements:
- Clean vector-style shapes with strong silhouette
- Balanced negative space
- Must read clearly from 16px favicon to large signage
- Flat design, minimal strokes, no gradients unless essential
- Earth-tone palette: warm wheat gold, deep brown, cream
- Could incorporate subtle wheat or grain element
- Text must be perfectly legible and properly kerned
Output: Single centered logo on plain cream background. Generous padding around
the design for flexibility.
No watermarks, no mockups, no 3D effects, no complex imagery. Simple, functional,
timeless design.ใช้ n=4 เพื่อสร้างหลายรูปแบบ การออกแบบโลโก้เป็นเรื่องส่วนบุคคล — ให้ตัวเลือกตัวเองในการเลือก
แบบจำลอง UI และแอป
สำหรับการออกแบบ UI ให้บรรยายอินเทอร์เฟซราวกับว่ามันมีอยู่จริงและกำลังส่งมอบให้กับผู้ใช้จริง ภาษา Concept art จะสร้าง Concept art ภาษา Product จะสร้างแบบจำลองที่ใช้งานได้
Create a realistic mobile app UI mockup for a local farmers market app.
Screen content (from top):
- Simple header with market name "Riverside Market" and search icon
- Today's featured vendor carousel with square photos
- "Fresh Today" section with produce category chips (Vegetables, Fruits, Dairy, Baked)
- Vendor list with small photos, names, specialties, and distance
- Bottom navigation: Home, Map, Favorites, Cart, Profile
Design language:
- White background, subtle natural green accents
- Clear typography hierarchy (system fonts feel)
- Generous padding and touch-friendly targets
- Looks like a real shipped product, not a concept
- Uses realistic vendor names and produce photos
Frame: Place the UI inside an iPhone 15 Pro device frame, slight perspective
tilt, subtle shadow beneath.เน้นที่การจัดวาง ลำดับชั้น ระยะห่าง และองค์ประกอบอินเทอร์เฟซที่สมจริง หลีกเลี่ยงภาษาเชิงแนวคิดหรือศิลปะ
การ์ตูนและศิลปะลำดับภาพ
การสร้างการ์ตูนหลายช่องต้องกำหนดการเล่าเรื่องเป็นลำดับของจังหวะภาพที่ชัดเจน หนึ่งจังหวะต่อช่อง รักษาคำบรรยายให้เป็นรูปธรรมและเน้นการกระทำ
Create a 4-panel vertical comic strip. Equal panel sizes, clear panel borders.
Panel 1: Pet owner walks out the front door, keys in hand. Through the window
behind them, we see their cat watching — paws pressed against glass, eyes wide
with apparent sadness. The house suddenly feels empty.
Panel 2: The door clicks shut. The cat slowly turns away from the window toward
the empty house. Its posture shifts from forlorn to interested. Eyes narrow with
possibility.
Panel 3: Total chaos. Cat sprawled across the forbidden couch like royalty.
Knocked over plant on the floor. Papers scattered. Sunbeam spotlighting the
scene of domestic crime.
Panel 4: Door handle turns. Cat sits perfectly upright by the entrance,
composed and innocent, tail wrapped neatly around paws. Not a hair out of
place. As if nothing happened.
Style: Warm illustrated style with expressive characters, clear visual
storytelling that reads without text. Consistent character design across
all panels.
No speech bubbles or text. Let the visuals tell the story.กำหนดแต่ละช่องเป็นจังหวะภาพที่แตกต่างกันพร้อมการกระทำที่ชัดเจน โมเดลจะจัดการการจัดวางช่องและความต่อเนื่องของภาพ
ภาพประกอบหนังสือเด็ก
การวาดภาพประกอบหนังสือเด็กต้องการวิธีการเฉพาะ: การออกแบบตัวละครที่น่าจดจำ สไตล์ที่อบอุ่นเข้าถึงง่าย และองค์ประกอบที่ทำงานร่วมกับข้อความซ้อนทับได้
Create a children's book illustration introducing the main character.
Character: Young forest hero, around 8 years old.
- Green hooded tunic (think woodland adventurer, not Robin Hood)
- Soft brown boots, well-worn
- Small belt pouch for collecting treasures
- Carries a tiny wooden bow (symbolic, for helping not hurting)
- Kind expression, bright curious eyes, brave but gentle demeanor
- Slightly oversized head for picture book proportions
Theme: This character protects and rescues small forest animals in trouble.
Style: Hand-painted watercolor look with soft outlines, warm earthy palette
with forest greens and autumn oranges. Whimsical, friendly, inviting for
young readers ages 4-8.
Composition: Character standing in simple forest glade, dappled sunlight,
leaving room for title text above. Character clearly showcased.
Original character design only. No text. No watermarks. No copyrighted
character references.บันทึกภาพอ้างอิงตัวละครนี้ — คุณจะใช้มันเพื่อรักษาความสม่ำเสมอในภาพประกอบต่อๆ ไป
การใช้ประโยชน์จากความรู้โลก
หนึ่งในความสามารถที่ถูกมองข้ามมากที่สุดของ GPT Image 1.5 คือความรู้เกี่ยวกับโลกที่มีอยู่ในตัว โมเดลสามารถอนุมานบริบทจากเบาะแสที่ละเอียดอ่อน สร้างภาพที่ถูกต้องตามประวัติศาสตร์และวัฒนธรรมโดยไม่ต้องมีคำสั่งที่ชัดเจน
Create a realistic outdoor crowd scene in Bethel, New York on August 16, 1969.
Photorealistic, period-accurate clothing, staging, and environment.
Documentary photography style, shot on film, natural lighting.โมเดลรู้ว่านี่คือ Woodstock โดยไม่ต้องบอก มันสร้างชาวฮิปปี้ แฟชั่นยุคนั้น บรรยากาศงานเทศกาล — ทั้งหมดนี้จากวันที่และสถานที่เท่านั้น
ความรู้โลกนี้ขยายไปถึงสถาปัตยกรรมข้ามยุคสมัย แฟชั่นผ่านทศวรรษ เหตุการณ์ทางวัฒนธรรม สถานที่สำคัญทางภูมิศาสตร์ การเคลื่อนไหวทางศิลปะ และแม้แต่สุนทรียศาสตร์การถ่ายภาพเฉพาะ เมื่อความแม่นยำเป็นสิ่งสำคัญ การระบุเวลาและสถานที่มักจะให้ผลลัพธ์ที่ดีกว่าคำบรรยายยาวเหยียดเกี่ยวกับสิ่งที่คุณคาดว่าจะเห็น
ศิลปะแห่งการแก้ไขที่แม่นยำ
การสร้างภาพจากข้อความนั้นน่าประทับใจ แต่การแก้ไขภาพคือที่ที่ GPT Image 1.5 โดดเด่นอย่างแท้จริง ความสามารถในการปรับเปลี่ยนภาพที่มีอยู่อย่างแม่นยำในขณะที่รักษาส่วนที่เหลือไว้ เปิดโอกาสให้เกิดขั้นตอนการทำงานแบบมืออาชีพที่ก่อนหน้านี้เป็นไปไม่ได้หากไม่มีทักษะ Photoshop ระดับเชี่ยวชาญ
กฎทองของการแก้ไข
ทุกการแก้ไขที่ประสบความสำเร็จจะเป็นไปตามรูปแบบเดียวกัน: ระบุสิ่งที่เปลี่ยนแปลงอย่างชัดเจน ระบุสิ่งที่ยังคงเหมือนเดิมอย่างชัดเจน สิ่งนี้ฟังดูชัดเจน แต่ระดับความเฉพาะเจาะจงที่จำเป็นนั้นมากกว่าที่คนส่วนใหญ่ตระหนัก
จัดโครงสร้าง Prompt การแก้ไขเสมอเป็น: "Change ONLY [X]. Preserve EXACTLY: [comprehensive list of everything else]." จากนั้นทำซ้ำรายการรักษาไว้ของคุณในการทำซ้ำการแก้ไขทุกครั้งเพื่อป้องกันการค่อยๆ เบี่ยงเบนจากต้นฉบับ
การลองสวมเสื้อผ้าเสมือนจริง
อีคอมเมิร์ซกำลังถูกเปลี่ยนโดยความสามารถในการลองสวมด้วย AI นี่คือโครงสร้าง Prompt ที่ผมใช้สำหรับการเปลี่ยนเสื้อผ้าที่รักษาเอกลักษณ์ได้อย่างสมบูรณ์แบบ
Edit the image to dress this person in the provided clothing items.
MUST PRESERVE (do not change in any way):
- Face, facial features, expression, skin tone
- Body shape, proportions, and pose
- Hairstyle and hair color
- Background and environment
- Camera angle, framing, and composition
- Overall lighting direction and quality
CHANGE ONLY:
- Replace current clothing with provided garment images
- Fit garments naturally to body geometry
- Show realistic fabric draping, folds, and behavior
- Match lighting and shadows on fabric to original photo
REQUIREMENTS:
- Photorealistic integration — outfit should look worn, not pasted
- Maintain color temperature of original image
- No accessories, text, logos, or watermarks added
- Identity must remain clearly recognizableสำหรับการลองสวมเสมือนจริง ให้ใช้ input_fidelity="high" เสมอเพื่อให้แน่ใจว่าความเหมือนของใบหน้าจะถูกรักษาไว้
การถ่ายโอนสไตล์ (Style Transfer)
การถ่ายโอนสไตล์นำภาษาภาพจากภาพหนึ่ง — จานสี พื้นผิว ฝีแปรง สุนทรียศาสตร์ — และนำไปใช้กับเนื้อหาใหม่ นี่เป็นสิ่งล้ำค่าสำหรับการรักษาความสม่ำเสมอของแบรนด์หรือสร้างซีรีส์ที่เชื่อมโยงกัน
Using the EXACT visual style of the reference image (Image 1), create:
A man riding a motorcycle on a winding mountain road.
STYLE ELEMENTS TO MATCH PRECISELY from reference:
- Color palette and saturation levels
- Line quality and weight
- Texture treatment and brushwork
- Lighting style and direction
- Level of detail vs. abstraction
- Overall artistic aesthetic
APPLY TO NEW CONTENT:
- Single subject (man on motorcycle)
- Clear composition with visual interest
- Mountain road environment with curves
- Sense of motion and freedom
The new image should look like it came from the same artist or series as
the reference. Maintain stylistic consistency exactly.การถ่ายโอนสไตล์ทำงานได้ดีที่สุดเมื่อคุณระบุเจาะจงเกี่ยวกับองค์ประกอบสไตล์ใดที่จะรักษาไว้และองค์ประกอบเนื้อหาใดที่จะเปลี่ยน
การแทนที่วัตถุ
การสลับวัตถุในขณะที่รักษาความสมจริงไว้เป็นเรื่องที่ทำได้จริงแล้ว เคล็ดลับคือการบรรยายไม่ใช่แค่สิ่งที่จะเพิ่ม แต่รวมถึงวิธีที่มันควรผสานเข้ากับฉากที่มีอยู่
In this room photo, replace ONLY the white plastic chairs with
mid-century modern wooden chairs (walnut finish, tapered legs,
woven seat).
PRESERVE COMPLETELY:
- Camera angle and perspective
- Room lighting direction and quality
- All other furniture and objects
- Wall colors and decorations
- Floor material and shadows
- Overall image quality and color grading
INTEGRATION REQUIREMENTS:
- Chairs must match room's perspective exactly
- Wood grain should catch existing light realistically
- Contact shadows must be natural and match light source
- Scale must be accurate relative to table height
- New chairs should look like they belong in this room
Photorealistic result — should look like the original photograph.การแสดงภาพการออกแบบภายในเป็นหนึ่งในแอปพลิเคชันการแก้ไขที่มีมูลค่าทางการค้ามากที่สุด
ภาพร่างสู่การเรนเดอร์เสมือนจริง
การเปลี่ยนภาพร่างคร่าวๆ ให้เป็นภาพเรนเดอร์ที่สวยงามมีประโยชน์อย่างยิ่งสำหรับการออกแบบผลิตภัณฑ์ สถาปัตยกรรม และการพัฒนาแนวคิด Prompt จำเป็นต้องปฏิบัติต่อภาพร่างเสมือนเป็นข้อกำหนดที่ต้องปฏิบัติตาม
Transform this hand-drawn sketch into a photorealistic image.
PRESERVE FROM SKETCH:
- Exact layout and proportions
- Perspective and viewing angle
- Element placement and relationships
- Implied depth and layering
ADD FOR REALISM:
- Appropriate real-world materials and textures
- Consistent natural lighting (interpret from sketch shading)
- Environmental context matching the implied setting
- Surface imperfections and wear appropriate to materials
CONSTRAINTS:
- Do not add new elements not present in sketch
- Do not add text or watermarks
- Treat the sketch as an architectural blueprint to follow exactly
- Fill in realistic details while honoring the original compositionโมเดลตีความเจตนาของภาพร่างและเติมรายละเอียดที่สมจริงในขณะที่ยังคงองค์ประกอบดั้งเดิมไว้
การเปลี่ยนแปลงแสงและสภาพอากาศ
การเปลี่ยนสภาพแวดล้อมในขณะที่รักษาเรขาคณิตของฉากไว้เป็นหนึ่งในแอปพลิเคชันการแก้ไขที่ผมชอบที่สุด เหมาะสำหรับการสร้างตัวแปรตามฤดูกาล ทางเลือกช่วงเวลาของวัน หรือการปรับอารมณ์
Transform this daytime summer scene into a winter evening with snowfall.
CHANGE:
- Time of day: from afternoon to dusk (warm interior lights visible)
- Season: summer to deep winter
- Weather: clear to active snowfall
- Ground: grass to fresh snow coverage
- Trees: summer foliage to bare branches with snow
- Atmosphere: add visible breath if people present
- Surfaces: add frost on windows and metal
PRESERVE:
- Camera position and angle exactly
- All objects and their exact positions
- Architecture and structural elements
- People and their poses (update clothing appropriately)
- Overall composition and framing
Style: Photorealistic, natural atmospheric perspective, visible
snowflakes in air, cozy contrast between warm interior lights and
cold exterior. Should feel photographed, not filtered.ใช้ input_fidelity="high" และ quality="high" เพื่อผลลัพธ์ที่ดีที่สุดในการเปลี่ยนแปลงสภาพแวดล้อม
การประกอบภาพหลายภาพ (Multi-Image Compositing)
การรวมองค์ประกอบจากภาพต้นฉบับหลายภาพต้องการคำแนะนำที่ชัดเจนว่าอะไรมาจากไหนและองค์ประกอบควรผสานกันอย่างราบรื่นอย่างไร
I'm providing 2 images:
- Image 1: Beach scene with woman standing on shore at sunset
- Image 2: Golden retriever sitting in a studio setting
Task: Place the dog from Image 2 into the beach scene from Image 1,
positioned next to the woman, looking up at her.
MATCHING REQUIREMENTS:
- Dog's lighting must match beach sunset (warm golden light from left)
- Scale dog appropriately relative to woman's height
- Dog should cast shadow consistent with scene's sun angle
- Sand texture should show around and under dog's paws
- Fur should catch the same golden hour highlights as scene
PRESERVE FROM IMAGE 1:
- Woman's exact appearance, position, and pose
- Beach background completely unchanged
- Original photo's color grading and mood
The composite should look like a single photograph taken on location.
No visible compositing artifacts.อ้างอิงภาพตามหมายเลขและระบุให้ชัดเจนว่าองค์ประกอบใดถ่ายโอนและองค์ประกอบใดยังคงที่
การแปลข้อความในภาพ
การปรับเนื้อหาภาพให้เข้ากับตลาดต่างประเทศทำได้ง่ายขึ้นอย่างมากด้วยความสามารถด้านข้อความของ GPT Image 1.5
Translate all text in this infographic from English to Japanese.
MUST PRESERVE:
- Exact layout, spacing, and positioning of all elements
- All visual elements, icons, illustrations, and graphics
- Typography hierarchy (headlines vs body text relationships)
- Color scheme and overall design aesthetic
- Font weights and relative sizes
TRANSLATION REQUIREMENTS:
- Accurate Japanese translation with natural phrasing
- Match visual weight and style to original fonts
- Adjust character spacing for Japanese typographic norms
- No text truncation or overflow outside original bounds
Do not modify any non-text elements. Only change the language.ขั้นตอนการทำงานนี้จัดการวัสดุทางการตลาด ภาพหน้าจอ UI บรรจุภัณฑ์ และอินโฟกราฟิกโดยไม่ต้องสร้างใหม่ตั้งแต่ต้น
เทคนิคขั้นสูงสำหรับมืออาชีพ
เมื่อคุณเชี่ยวชาญพื้นฐานแล้ว เทคนิคขั้นสูงเหล่านี้จะยกระดับงานของคุณไปสู่ระดับมืออาชีพอย่างแท้จริง นี่คือรูปแบบที่ผมพัฒนาขึ้นผ่านการทดลองอย่างกว้างขวาง — เทคนิคที่ให้ผลลัพธ์ที่เหนือกว่าอย่างสม่ำเสมอ
ความสม่ำเสมอของตัวละครข้ามภาพ
หนึ่งในความท้าทายที่ใหญ่ที่สุดในการสร้างภาพด้วย AI คือการรักษาความสม่ำเสมอของตัวละครข้ามภาพหลายภาพ สำหรับหนังสือเด็ก มาสคอตแบรนด์ หรือโครงการใดๆ ที่ต้องการตัวละครเดียวกันในฉากต่างๆ นี่คือขั้นตอนการทำงานที่พิสูจน์แล้วของผม
สร้างภาพอ้างอิงที่มีรายละเอียดซึ่งกำหนดลักษณะที่แน่นอนของตัวละคร รวมรายละเอียดหลักทั้งหมด: ชุด, สัดส่วน, การแสดงออก, จานสี บันทึกภาพนี้ — มันจะกลายเป็นแหล่งความจริงของคุณ
เขียนคำบรรยายตัวละครโดยละเอียดที่คุณจะอ้างอิงใน Prompt ในอนาคตทั้งหมด ระบุเจาะจงเกี่ยวกับองค์ประกอบภาพทุกอย่าง สมอข้อความนี้เสริมสมอภาพ
เมื่อสร้างฉากใหม่ ให้รวมภาพสมอเป็นอินพุตและสั่งการอย่างชัดเจนว่า "maintain exact character appearance from reference image."
โมเดลจะรักษาบริบทภายในเซสชันการสนทนา สร้างต่อยอดจากภาพที่ประสบความสำเร็จแทนที่จะเริ่มใหม่สำหรับแต่ละฉาก อ้างอิงรุ่นก่อนหน้าโดยตรง
Continue the children's book story using the character from the reference image.
New Scene:
The same young forest hero is gently helping a frightened squirrel out
of a fallen hollow tree after a winter storm. Snow on the ground, bare
branches above, warm light filtering through clouds.
CHARACTER CONSISTENCY (from reference):
- Same green hooded tunic, exact shade and style
- Same soft brown boots
- Same belt pouch
- Same facial features, proportions, and color palette
- Same gentle, heroic personality in expression
- Same children's book proportions
STYLE CONSISTENCY (from reference):
- Same watercolor illustration style
- Same soft outlines
- Same warm earthy color treatment
- Same whimsical, friendly aesthetic
New elements: winter forest environment, frightened squirrel, fallen
tree with hollow.
Do not redesign the character. Do not change the artistic style.
No text. No watermarks.อ้างอิงภาพสมอและทำซ้ำรายละเอียดตัวละครหลักเพื่อรักษาความสม่ำเสมอตลอดทั้งเล่ม
เทคนิคพอร์ตเทรต 3D แบบมีสไตล์
การสร้างพอร์ตเทรต 3D แบบมีสไตล์ขั้นสูงจากภาพถ่ายอ้างอิงได้กลายเป็นหนึ่งในผลงานที่เป็นเอกลักษณ์ของผม กุญแจสำคัญคือความเฉพาะเจาะจงอย่างยิ่งเกี่ยวกับสุนทรียศาสตร์ที่ต้องการ
Create a hyper-stylized 3D floating head portrait based on this person.
STYLE CHARACTERISTICS:
- Smooth skin with glossy vinyl-finish surface
- Strong highlighter on cheekbones and nose tip catching soft light
- Holographic, iridescent eyeshadow (purple to teal color shift)
- Thick hair sculpted in slick, glossy waves like polished acrylic
- Small metallic chrome nose piercing with brushed reflections
EXPRESSION:
Confident, slightly unimpressed look — half-lidded eyes, subtly
arched brow, the sophisticated "too cool" attitude.
TECHNICAL SPECIFICATIONS:
- Head floats isolated against plain white background
- Slight 15-degree tilt (premium product render feeling)
- Bright, diffuse studio lighting with no harsh shadows
- Emphasis on glossy, plastic, subsurface scattering effects
- Ultra-smooth textures throughout
- Close-up portrait angle, straight-on, 85mm lens feel
The result should look like a high-end 3D character render or
collectible figure — plastic perfection with personality.ระดับรายละเอียดด้านสุนทรียศาสตร์นี้สร้างผลลัพธ์ที่สม่ำเสมออย่างน่าทึ่งกับตัวแบบที่แตกต่างกัน
การแปลงร่างตัวละครจิบิ (Chibi)
การแปลงภาพถ่ายให้เป็นตัวละครสไตล์จิบิที่น่ารักทำงานได้ดีอย่างน่าประหลาดใจสำหรับมาสคอตแบรนด์ อวตารโซเชียลมีเดีย และสินค้า
Transform this person into an adorable chibi-style character.
CHIBI PROPORTIONS:
- Tiny body (about 1 head-height tall)
- Oversized head (3x body proportions)
- Large, sparkling eyes with cute highlights
- Soft, rounded facial features
- Cheerful, expressive pose with personality
PRESERVE FROM ORIGINAL:
- Recognizable facial features (simplified but identifiable)
- Hairstyle, length, and hair color
- Distinctive clothing style or accessories
- Any notable characteristics (glasses, jewelry, etc.)
- Overall personality and vibe
STYLE:
- Smooth pastel shading
- Clean lines and simplified details
- Bright, expressive colors
- Collectible figure aesthetic
Background: Simple gradient or plain color to showcase character.
The result should feel like an irresistible chibi mascot that
clearly represents the original person.การแปลงร่างจิบิทำงานได้ดีสำหรับการสร้างแบรนด์ส่วนบุคคล อวตารทีม และการออกแบบสินค้า
สื่อสร้างสรรค์ทางการตลาดพร้อมข้อความที่สมบูรณ์แบบ
การสร้างสื่อการตลาดที่มีข้อความถูกต้องต้องการการควบคุมตัวอักษรที่เข้มงวดและข้อกำหนดข้อความที่ชัดเจน
Create a realistic highway billboard mockup featuring this product.
BILLBOARD CONTENT:
- Product bottle prominently displayed on left third
- Main headline on right (EXACT TEXT, render verbatim):
"Fresh & Clean — Every Day"
- Tagline below headline: "Nature's Best Ingredients"
- Small logo placeholder area in bottom right corner
TYPOGRAPHY SPECIFICATIONS:
- Headline: Bold sans-serif, white text, high contrast
- Tagline: Light sans-serif, slightly smaller, same white
- Clean kerning, centered alignment within text area
- Text appears EXACTLY ONCE — no duplicates anywhere
SCENE:
- Billboard on highway overpass or roadside structure
- Sunset lighting creating warm, appealing atmosphere
- Photorealistic environment with motion-blurred vehicles below
- Professional advertising photography feel
No watermarks. No additional marketing copy. No logos unless
specified. Text must be perfectly legible and correctly spelled.ใช้ quality="high" เสมอสำหรับสื่อการตลาดที่มีข้อความ ตรวจสอบการสะกดคำก่อนใช้งานจริง
การสกัดภาพถ่ายสินค้า
การสร้างภาพสินค้าที่สะอาดพร้อมตัวแบบแยกเป็นสิ่งจำเป็นสำหรับอีคอมเมิร์ซ นี่คือ Prompt ที่ได้ผล
Extract the product from this image for e-commerce use.
OUTPUT SPECIFICATIONS:
- Transparent background (RGBA PNG format)
- Crisp silhouette with clean edges
- No halos or color fringing around product
- All product labels and text perfectly preserved
- Exact product geometry and proportions maintained
OPTIONAL ENHANCEMENT:
- Add subtle, realistic contact shadow
- Shadow should be soft and natural, no hard edges
- Shadow works with the transparent background
CRITICAL CONSTRAINTS:
- Do NOT restyle or recolor the product
- Do NOT modify product appearance in any way
- Only remove background and add optional shadow
- Preserve every detail of the original product exactlyหมายเหตุ: โมเดลปัจจุบันแสดงรูปแบบตารางหมากรุกสำหรับความโปร่งใส — อาจต้องมีการประมวลผลภายหลังสำหรับช่องอัลฟาที่แท้จริง
ข้อจำกัดที่ทราบ
การลบพื้นหลังในปัจจุบันจะแสดงรูปแบบตารางหมากรุกแบบภาพเพื่อระบุความโปร่งใสแทนที่จะสร้างความโปร่งใสแบบ RGBA จริงในไฟล์เอาต์พุต สำหรับการใช้งานจริง คุณอาจต้องประมวลผลเอาต์พุตภายหลังเพื่อแปลงตารางหมากรุกเป็นความโปร่งใสจริงโดยใช้ซอฟต์แวร์แก้ไขภาพ
วงรอบการปรับแต่งซ้ำ (Iterative Refinement Loop)
อย่าพยายามบรรลุความสมบูรณ์แบบใน Prompt เดียว ผลลัพธ์ระดับมืออาชีพมาจากการทำซ้ำอย่างเป็นระบบ
กระบวนการปรับแต่ง
- สร้าง: สร้างภาพเริ่มต้นที่มีองค์ประกอบหลักและองค์ประกอบโดยรวม
- ประเมิน: ระบุปัญหาที่สำคัญที่สุด 1-2 ข้อเพื่อแก้ไขก่อน
- ปรับแต่ง: แก้ไขเฉพาะปัญหาเฉพาะเหล่านั้น โดยรักษาทุกอย่างที่เหลือไว้อย่างชัดเจน
- ล็อค: บันทึกสถานะปัจจุบันก่อนที่จะพยายามทำซ้ำครั้งต่อไป
- ทำซ้ำ: ดำเนินการต่อจนพอใจ สร้างขึ้นทีละน้อย
การเปลี่ยนแปลงเล็กๆ น้อยๆ ที่มุ่งเน้นแต่ละครั้งรวมกันเป็นผลลัพธ์สุดท้ายที่แม่นยำด้วยความหงุดหงิดน้อยกว่าการพยายามทำทุกอย่างพร้อมกันมาก
ขั้นตอนการทำงานระดับมืออาชีพในโลกจริง
ทฤษฎีมีค่า แต่การเห็นว่าเทคนิคต่างๆ รวมกันเป็นขั้นตอนการทำงานที่สมบูรณ์อย่างไรคือจุดที่ความเข้าใจตกผลึก นี่คือขั้นตอนการทำงานที่ผมใช้บ่อยที่สุดในการปฏิบัติงานจริง
ไปป์ไลน์การถ่ายภาพสินค้าอีคอมเมิร์ซ
ระบบภาพสินค้าที่สมบูรณ์
- การสกัดสินค้า: ลบพื้นหลังออกจากภาพถ่ายสินค้าดิบ สร้างภาพแยกที่สะอาด
- บริบทไลฟ์สไตล์: สร้างฉากสภาพแวดล้อม (ห้องครัว, สำนักงาน, กลางแจ้ง) และประกอบสินค้าเข้าไป
- ตัวแปรสี: สร้างความหลากหลายของสีสินค้าผ่านการแก้ไขที่ตรงจุดโดยไม่ต้องถ่ายใหม่
- สื่อสร้างสรรค์ทางการตลาด: สร้างแบบจำลองป้ายโฆษณา, กราฟิกโซเชียลมีเดีย, โฆษณาแบนเนอร์ที่มีการรวมสินค้า
- การปรับให้เข้ากับท้องถิ่น: แปลข้อความในวัสดุการตลาดสำหรับตลาดต่างๆ ในขณะที่ยังคงการออกแบบไว้
ไปป์ไลน์การถ่ายภาพสินค้าที่สมบูรณ์ซึ่งก่อนหน้านี้ต้องใช้เวลาสตูดิโอ ความเชี่ยวชาญ Photoshop และผู้เชี่ยวชาญหลายคน ตอนนี้ทำงานผ่านชุดของ AI prompt
ห้องสมุดภาพของผู้สร้างเนื้อหา
การสร้างสินทรัพย์แบรนด์ที่สม่ำเสมอ
- การพัฒนาตัวละคร: สร้างมาสคอตแบรนด์หรืออวตารส่วนตัวด้วยภาพสมอที่มีรายละเอียด
- การสร้างคู่มือสไตล์: ผลิตอ้างอิงจานสี มูดบอร์ด และตัวอย่างสุนทรียศาสตร์
- โรงงานภาพปกคลิป: สร้างภาพปกคลิป YouTube/โซเชียลที่สม่ำเสมอโดยใช้ตัวละครและสไตล์ที่กำหนดไว้
- ห้องสมุดพื้นหลัง: สร้างพื้นหลังฉากที่ตรงกับสุนทรียศาสตร์ของแบรนด์สำหรับเนื้อหาประเภทต่างๆ
- การขยายตัวแปร: ใช้การถ่ายโอนสไตล์เพื่อรักษาความสม่ำเสมอทางภาพในเนื้อหาใหม่ทั้งหมด
สร้างรากฐานภาพของคุณเพียงครั้งเดียว แล้วทำซ้ำอย่างมีประสิทธิภาพ สร้างความสม่ำเสมอของแบรนด์แบบที่เคยต้องใช้ทีมออกแบบเฉพาะ
การสร้างต้นแบบการออกแบบอย่างรวดเร็ว
จากแนวคิดสู่ภาพในไม่กี่นาที
- ภาพร่างคร่าวๆ: วาดแนวคิดพื้นฐานด้วยมือ (คุณภาพบนกระดาษเช็ดปากก็ใช้ได้ — รูปร่างและการจัดวางคร่าวๆ)
- การเรนเดอร์เบื้องต้น: แปลงภาพร่างเป็นภาพเสมือนจริงหรือมีสไตล์โดยรักษาองค์ประกอบของคุณไว้
- วงจรการทำซ้ำ: ปรับแต่งผ่านการแก้ไขที่ตรงจุด ("แสงอุ่นขึ้น," "วัสดุต่างกัน," "คอนทราสต์มากขึ้น")
- การสำรวจตัวแปร: สร้างหลายรูปแบบ (n=4) สำหรับการนำเสนอต่อลูกค้าหรือการตัดสินใจ
- การขัดเกลาขั้นสุดท้าย: ส่งออกคุณภาพสูงของทิศทางที่เลือกพร้อมรายละเอียดที่ประณีต
นักออกแบบรายงานการทำซ้ำแนวคิดที่เร็วขึ้นอย่างมากเมื่อเทียบกับขั้นตอนการทำงานสร้างสรรค์ดิจิทัลแบบดั้งเดิม
ไปป์ไลน์ภาพประกอบหนังสือเด็ก
การสร้างหนังสือภาพที่สม่ำเสมอ
- การออกแบบตัวละคร: สร้างแผ่นอ้างอิงตัวละครโดยละเอียดที่กำหนดลักษณะที่แน่นอน
- การกำหนดสไตล์: สร้างหน้าตัวอย่าง 2-3 หน้าเพื่อล็อคสไตล์ภาพประกอบ เลือกสิ่งที่ดีที่สุด
- การสร้างทีละฉาก: ทำงานผ่านเรื่องราวทีละหน้า โดยอ้างอิงทั้งสมอตัวละครและสไตล์เสมอ
- การตรวจสอบความสม่ำเสมอ: ดูทุกหน้าด้วยกัน ใช้การแก้ไขเพื่อแก้ไขการเบี่ยงเบนของตัวละครหรือความไม่สม่ำเสมอของสไตล์
- การปรับแต่งขั้นสุดท้าย: ขัดเกลาแต่ละหน้าตามต้องการในขณะที่ยังคงลุคที่กำหนดไว้
วิธีการใช้ภาพสมอทำให้การวาดภาพประกอบตัวละครที่สม่ำเสมอตลอดทั้งเล่มเป็นไปได้จริง
ความผิดพลาดที่ฆ่าผลลัพธ์ของผม
หลังจากเฝ้าดูตัวเองและคนอื่นนับไม่ถ้วนดิ้นรนกับการสร้างภาพด้วย AI ผมได้ระบุรูปแบบที่แยกความสำเร็จออกจากความหงุดหงิด นี่คือความผิดพลาดที่ผมเคยทำ — และวิธีที่ผมแก้ไขมัน
❌ การยัดเยียดคำหลัก (Keyword Stuffing)
ข้อผิดพลาด: การเพิ่ม "highly detailed, 8K, photorealistic, trending on ArtStation, masterpiece" ลงในทุก Prompt
วิธีแก้: บรรยายคุณสมบัติทางภาพที่เฉพาะเจาะจงแทน "Visible skin pores, morning window light, 50mm lens depth of field" สื่อสารได้มากกว่าคำหลักคุณภาพทั่วไป
❌ Mega-Prompt
ข้อผิดพลาด: พยายามระบุทุกรายละเอียดที่เป็นไปได้ใน Prompt เดียวขนาดใหญ่ โดยหวังว่าโมเดลจะเข้าใจวิสัยทัศน์ที่สมบูรณ์ของผม
วิธีแก้: เริ่มต้นง่ายๆ ได้ภาพพื้นฐานที่มั่นคงก่อน แล้วปรับแต่งด้วย Prompt ติดตามผลที่ตรงจุด การสร้างทีละน้อยให้ผลลัพธ์ที่ดีกว่ามาก
❌ คำสั่งแก้ไขที่คลุมเครือ
ข้อผิดพลาด: พูดว่า "ทำให้มันดีขึ้น" หรือ "แก้แสง" โดยไม่ระบุว่า "ดีกว่า" หมายถึงอะไร หรือแสงควรเปลี่ยนไปอย่างไร
วิธีแก้: เจาะจงเกี่ยวกับการเปลี่ยนแปลง "เปลี่ยนแสงจากแสงเหนือศีรษะที่รุนแรงเป็นแสงหน้าต่างนุ่มนวลจากด้านซ้าย พร้อมอุณหภูมิสีที่อุ่นขึ้น"
❌ ลืมรายการรักษาไว้
ข้อผิดพลาด: ขอเปลี่ยนแปลงโดยไม่ระบุอย่างชัดเจนว่าอะไรควรคงเดิม แล้วประหลาดใจเมื่อองค์ประกอบอื่นๆ เปลี่ยนไป
วิธีแก้: ทุก Prompt แก้ไขต้องรวมถึงข้อกำหนดการรักษาไว้อย่างชัดเจน ทำซ้ำในแต่ละรอบเพราะโมเดลไม่จำข้อจำกัดก่อนหน้านี้
❌ การลืมบริบท (Context Amnesia)
ข้อผิดพลาด: เริ่มการสนทนาใหม่สำหรับภาพที่เกี่ยวข้องกัน สูญเสียบริบทและความสม่ำเสมอทั้งหมดที่สร้างขึ้น
วิธีแก้: สร้างภายในเซสชันสำหรับงานที่เกี่ยวข้อง อ้างอิงรุ่นก่อนหน้าโดยตรง ใช้วลีเช่น "สไตล์เดียวกับภาพก่อนหน้า" เพื่อใช้ประโยชน์จากบริบท
❌ การตั้งค่าคุณภาพผิด
ข้อผิดพลาด: ใช้คุณภาพสูงตลอดเวลา (ช้าและแพงสำหรับการทำซ้ำ) หรือใช้คุณภาพต่ำตลอดเวลา (พลาดรายละเอียดสำคัญเมื่อจำเป็น)
วิธีแก้: จับคู่การตั้งค่ากับงาน คุณภาพต่ำสำหรับการสำรวจและการทำซ้ำ; คุณภาพสูงสำหรับผลลัพธ์สุดท้ายและอะไรก็ตามที่มีข้อความ
❌ การต่อสู้กับโมเดล
ข้อผิดพลาด: รัน Prompt เดิมซ้ำๆ โดยคาดหวังผลลัพธ์ที่แตกต่าง หรือบังคับทิศทางที่โมเดลต่อต้านอย่างสม่ำเสมอ
วิธีแก้: หาก Prompt ไม่ได้ผล ให้เปลี่ยนถ้อยคำแทนที่จะทำซ้ำ คำที่แตกต่างกันจะกระตุ้นรูปแบบที่แตกต่างกัน บางครั้งวิธีการของคุณต้องเปลี่ยน ไม่ใช่แค่ผลลัพธ์ของโมเดล
❌ การเพิกเฉยต่อความไม่แน่นอน (Stochasticity)
ข้อผิดพลาด: คาดหวังผลลัพธ์ที่เหมือนกันทุกประการจาก Prompt ที่เหมือนกัน หงุดหงิดเมื่อผลลัพธ์แตกต่างกัน
วิธีแก้: สร้างหลายรูปแบบ (n=4) และเลือกสิ่งที่ดีที่สุด ยอมรับความแปรปรวนว่าเป็นแหล่งของตัวเลือกที่สร้างสรรค์แทนที่จะเป็นข้อบกพร่องที่ต้องเอาชนะ
การเปลี่ยนแปลงที่มีผลกระทบมากที่สุดเพียงอย่างเดียวที่คนส่วนใหญ่ทำได้: หยุดปฏิบัติต่อ Prompt เหมือนคำอธิษฐานและเริ่มปฏิบัติต่อเหมือนข้อกำหนดทางเทคนิค จงแม่นยำเหมือนที่คุณจะทำในบรีฟการออกแบบสำหรับเพื่อนร่วมงานที่เป็นมนุษย์ โมเดลมีความสามารถอย่างน่าทึ่ง — แต่มันต้องการทิศทางที่ชัดเจนเพื่อแสดงความสามารถนั้น
การรวม API สำหรับนักพัฒนา
หากคุณกำลังรวม GPT Image 1.5 เข้ากับแอปพลิเคชันโดยใช้โปรแกรม นี่คือรายละเอียดทางเทคนิคและแนวทางปฏิบัติที่ดีที่สุดที่คุณต้องการ
การตั้งค่า API พื้นฐาน
import os
import base64
from openai import OpenAI
client = OpenAI()
# Create output directory
os.makedirs("output_images", exist_ok=True)
def save_image(result, filename: str) -> None:
"""Save base64 image response to file."""
image_base64 = result.data[0].b64_json
with open(f"output_images/{filename}", "wb") as f:
f.write(base64.b64decode(image_base64))
# Basic text-to-image generation
result = client.images.generate(
model="gpt-image-1.5",
prompt="Your detailed prompt here",
quality="high", # or "low" for faster iteration
n=1 # number of variations
)
save_image(result, "output.png")การแก้ไขภาพด้วยอินพุตหลายภาพ
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # Essential for identity preservation
quality="high",
image=[
open("input_images/source.png", "rb"),
open("input_images/style_reference.png", "rb"),
],
prompt="""
Apply the artistic style from Image 2 to the subject in Image 1.
PRESERVE: subject's identity, pose, and composition
CHANGE: artistic style, color palette, texture treatment
Do not add new elements. Maintain subject likeness exactly.
"""
)
save_image(result, "styled_output.png")พารามิเตอร์ API ที่สำคัญ
พารามิเตอร์การสร้าง
model
"gpt-image-1.5" — โมเดลเรือธงล่าสุดที่มีความสามารถดีที่สุด
prompt
คำบรรยายข้อความของคุณ — โครงสร้างสำคัญกว่าความยาว
quality
"high" สำหรับรายละเอียดและงานข้อความ, "low" สำหรับความเร็วและการทำซ้ำ
n
จำนวนรูปแบบที่จะสร้าง (ปกติ 1-4, สูงกว่าสำหรับการสำรวจ)
พารามิเตอร์การแก้ไข
image
วัตถุไฟล์หรือรายการวัตถุไฟล์สำหรับอินพุตหลายภาพ
input_fidelity
"high" สำหรับการรักษาเอกลักษณ์ สำคัญสำหรับงานพอร์ตเทรต
ข้อควรพิจารณาเรื่องราคา
โครงสร้างต้นทุน API
- ราคาตามโทเค็น: ต้นทุนขยายตามความละเอียดและการตั้งค่าคุณภาพ
- 1MP คุณภาพสูง: ประมาณ $133 ต่อ 1,000 ภาพ
- 1MP คุณภาพต่ำ: ประมาณ $9 ต่อ 1,000 ภาพ
- การประหยัดต้นทุน: ต้นทุนอินพุต/เอาต์พุตภาพต่ำกว่า GPT Image 1 ถึง 20%
สำหรับแอปพลิเคชันที่มีปริมาณมาก ให้เริ่มด้วยคุณภาพต่ำเสมอและอัปเกรดเฉพาะสำหรับผลลัพธ์สุดท้ายหรือภาพที่มีข้อความหนาแน่น
เปรียบเทียบกับเครื่องมืออื่นอย่างไร
ผมใช้เวลาอย่างมากกับเครื่องมือสร้างภาพ AI หลักๆ ทุกตัว นี่คือการประเมินอย่างตรงไปตรงมาของผมว่าตัวสร้างภาพของ ChatGPT (GPT Image 1.5) เทียบกับคู่แข่งได้อย่างไร
GPT Image 1.5 vs Gemini 3.0 Pro Image
GPT Image 1.5 ชนะ: การปฏิบัติตามคำสั่ง (90% vs 77%), ความแม่นยำในการเรนเดอร์ข้อความ, การแก้ไขที่แม่นยำ, คุณภาพการรวม API
Gemini 3.0 Pro ชนะ: คุณภาพของภาพโดยรวมในการทดสอบบางอย่าง, การตีความอย่างสร้างสรรค์, ฉากหลายตัวละครที่ซับซ้อน
มุมมองของผม: GPT Image 1.5 สำหรับงานมืออาชีพที่ต้องการความแม่นยำและความสม่ำเสมอ; Gemini สำหรับการสำรวจเชิงสร้างสรรค์ที่คุณต้องการการตีความมากขึ้น
GPT Image 1.5 vs Midjourney
GPT Image 1.5 ชนะ: การทำตามคำสั่ง, ความสามารถในการแก้ไขภาพ, การเข้าถึง API, การเรนเดอร์ข้อความ, ผลลัพธ์ที่คาดเดาได้
Midjourney ชนะ: สุนทรียศาสตร์ทางศิลปะและ "ปัจจัยว้าว," ชุมชนและคุณสมบัติการแบ่งปัน, สไตล์แบบภาพวาด
มุมมองของผม: GPT Image 1.5 สำหรับงานมืออาชีพ/เชิงพาณิชย์ที่คุณต้องการผลลัพธ์เฉพาะ; Midjourney สำหรับการสำรวจทางศิลปะและคอนเซ็ปต์อาร์ต
GPT Image 1.5 vs DALL-E 3
GPT Image 1.5 ชนะ: ความสามารถในการแก้ไข, ความเร็ว (เร็วกว่า 4 เท่า), ความสม่ำเสมอในการทำซ้ำ, การปฏิบัติตามคำสั่ง
DALL-E 3 ชนะ: ไม่มีอะไรสำคัญ — GPT Image 1.5 เป็นรุ่นต่อมาและปรับปรุงในทุกมิติ
มุมมองของผม: ถ้าคุณยังใช้ DALL-E 3 อยู่ ให้อัปเกรดทันที GPT Image 1.5 ดีกว่าอย่างสิ้นเชิง
GPT Image 1.5 vs Stable Diffusion
GPT Image 1.5 ชนะ: ใช้งานง่าย, ไม่ต้องติดตั้ง, การทำตามคำสั่ง, การเรนเดอร์ข้อความ, คุณภาพที่สม่ำเสมอ
Stable Diffusion ชนะ: การปรับแต่งเต็มรูปแบบ, การควบคุมในเครื่อง, การสร้างฟรีไม่จำกัด, การปรับแต่งละเอียด (fine-tuning), โมเดลเฉพาะทาง
มุมมองของผม: GPT Image 1.5 สำหรับความเร็วและความสะดวก; Stable Diffusion สำหรับการควบคุม การปรับแต่ง และงานปริมาณมากที่คำนึงถึงต้นทุน
ในการทดสอบเกณฑ์มาตรฐาน GPT Image 1.5 ได้อันดับ #1 ทั้งในหมวดหมู่ text-to-image และ image editing บน Artificial Analysis Image Arena สำหรับงานการผลิตที่ต้องการผลลัพธ์ที่เชื่อถือได้ คาดเดาได้ พร้อมการควบคุมที่แม่นยำ นี่คือตัวเลือกที่ดีที่สุดในขณะนี้
คำตอบที่แท้จริง? เครื่องมือที่ดีที่สุดขึ้นอยู่กับความต้องการเฉพาะของคุณ ผมรักษาการเข้าถึงเครื่องมือหลายอย่างเพราะแต่ละตัวมีความเป็นเลิศในสิ่งที่แตกต่างกัน แต่ถ้าผมมีได้เพียงตัวเดียวสำหรับงานมืออาชีพ ผมจะเลือก GPT Image 1.5 เพราะความน่าเชื่อถือ ความแม่นยำ และความสามารถในการแก้ไข
ความลับของผู้ใช้ระดับสูง (Power User)
นี่คือเคล็ดลับที่พาผมจากผลลัพธ์ "ดีพอใช้" ไปสู่ "คุณภาพระดับมืออาชีพ" แต่ละข้อเรียนรู้ผ่านการทดลองอย่างกว้างขวางและความล้มเหลวที่เจ็บปวดในบางครั้ง
เริ่มต้นใหม่สำหรับโปรเจกต์ใหม่
เริ่มแต่ละโปรเจกต์ใหม่ในการสนทนาใหม่ บริบทจากโปรเจกต์เก่าสามารถรั่วไหลเข้าไปในรุ่นใหม่และทำให้เกิดผลลัพธ์ที่ไม่คาดคิด กระดานชนวนที่สะอาด ผลลัพธ์ที่สะอาด
กฎ 80/20
ทำให้ได้ 80% ในการสร้างครั้งแรก ใช้การแก้ไขสำหรับอีก 20% ที่เหลือ การพยายามทำให้สมบูรณ์แบบใน Prompt เดียวจะนำไปสู่ความหงุดหงิดและเสียเวลา
ความเฉพาะเจาะจงชนะความเว่อร์วัง
"Shot on medium format film with natural grain" ชนะ "ultra-high-quality amazing detailed" ทุกครั้ง ข้อมูลจำเพาะนำทางโมเดล; คำคุณศัพท์ที่เกินจริงเพียงแค่เพิ่มสัญญาณรบกวน
ใส่เครื่องหมายคำพูดให้ข้อความของคุณ
ใส่ข้อความที่ต้องการใน "เครื่องหมายคำพูด" เสมอและระบุว่าควรปรากฏ "exactly once, no duplicates." สิ่งนี้ป้องกันการทำซ้ำและข้อผิดพลาดในการสะกดที่รบกวนการเรนเดอร์ข้อความ
จบด้วยเชิงลบ
จบทุก Prompt ด้วยสิ่งที่คุณไม่ต้องการ: "No watermarks, no text unless specified, no logos, no excessive saturation, no artificial bokeh." การป้องกันดีกว่าการแก้ไข
บันทึกผู้ชนะของคุณ
เมื่อคุณได้ผลลัพธ์ที่ยอดเยี่ยม ให้บันทึกทั้งภาพและ Prompt ที่สมบูรณ์ สร้างห้องสมุดส่วนตัวของ Prompt ที่พิสูจน์แล้วว่าใช้งานได้จริงซึ่งคุณสามารถปรับเปลี่ยนสำหรับโปรเจกต์ในอนาคต
เปลี่ยนถ้อยคำ อย่าทำซ้ำ
หาก Prompt ไม่ได้ผล อย่ารันซ้ำโดยหวังว่าจะโชคดี เปลี่ยนถ้อยคำ คำที่แตกต่างกันจะกระตุ้นรูปแบบที่แตกต่างกันในโมเดล เปลี่ยนวิธีการของคุณ
คุณภาพสูงสำหรับข้อความเสมอ
เมื่อใดก็ตามที่ภาพของคุณมีข้อความ — ข้อความใดๆ ก็ตาม — ให้ใช้โหมดคุณภาพสูง ข้อความคุณภาพต่ำมักอ่านไม่ออก ทำให้การประหยัดความเร็วไร้ค่า
ทำความเข้าใจความน่าจะเป็น (Stochasticity)
นี่คือสิ่งที่สำคัญ: การสร้างภาพด้วย AI โดยพื้นฐานแล้วเป็นการสุ่ม (stochastic) Prompt เดียวกันสามารถให้ผลลัพธ์ที่แตกต่างกันในแต่ละครั้ง นี่ไม่ใช่ข้อบกพร่อง — มันเป็นธรรมชาติของเทคโนโลยี
โอบรับความแปรปรวน
แทนที่จะต่อสู้กับการสุ่ม ให้ใช้มัน สร้าง 4 รูปแบบแล้วเลือกสิ่งที่ดีที่สุด บางครั้งการตีความที่ "คาดไม่ถึง" จะนำไปสู่ที่ที่ดีกว่าที่คุณจินตนาการไว้ในตอนแรก ศิลปิน AI ที่ดีที่สุดที่ผมรู้จักพึ่งพาอุบัติเหตุที่มีความสุขในขณะที่ยังคงควบคุมได้เพียงพอที่จะบรรลุเป้าหมาย ความแปรปรวนเป็นคุณสมบัติ ไม่ใช่ข้อบกพร่อง
การแก้ไขปัญหาทั่วไป
หลังจากสร้างภาพหลายพันครั้ง ผมเจอปัญหาทุกอย่างที่จินตนาการได้ นี่คือวิธีแก้ไขปัญหาที่พบบ่อยที่สุดที่ทำให้นักสร้างสรรค์หงุดหงิด
ปัญหา: ข้อความสะกดผิดหรือซ้ำซ้อน
วิธีแก้
ใส่ข้อความที่แน่นอนในเครื่องหมายคำพูด: "RESTAURANT" ไม่ใช่ restaurant เพิ่มคำสั่งที่ชัดเจน: "render exactly once, no duplicates." สำหรับคำยาก ให้สะกดทีละตัวอักษร: "R-E-S-T-A-U-R-A-N-T" ใช้ quality="high" เสมอสำหรับภาพที่มีข้อความ ตรวจสอบผลลัพธ์ก่อนใช้
ปัญหา: ตัวละครดูแตกต่างกันในแต่ละภาพ
วิธีแก้
สร้างภาพสมอตัวละครที่มีรายละเอียดก่อนแล้วบันทึกไว้ รวมสมอนี้เป็นอินพุตสำหรับทุกการสร้างในภายหลัง เขียนคัมภีร์ตัวละครที่ระบุทุกรายละเอียดทางภาพ สั่งการอย่างชัดเจนว่า "maintain exact character appearance from reference image." ใช้ input_fidelity="high" ในการเรียก API ทำงานภายในเซสชันเดียวเมื่อเป็นไปได้
ปัญหา: การแก้ไขเปลี่ยนมากกว่าที่ขอ
วิธีแก้
ชัดเจนขึ้นเกี่ยวกับการรักษาไว้ จัดโครงสร้าง Prompt เป็น "Change ONLY: [X]. Preserve EXACTLY: [list everything else in detail]." ทำซ้ำรายการรักษาไว้ทั้งหมดในทุกการวนซ้ำการแก้ไข — โมเดลไม่จดจำข้อจำกัดก่อนหน้านี้ ใช้ input_fidelity="high" สำหรับองค์ประกอบที่สำคัญ
ปัญหา: ภาพดูเป็น "AI สร้าง" อย่างชัดเจน
วิธีแก้
เพิ่มความไม่สมบูรณ์ที่สมจริง: "subtle film grain," "slight lens vignette," "natural skin texture with pores and subtle blemishes," "dust particles visible in sunbeam," "minor wear on materials." ความสมบูรณ์แบบดูปลอม ความจริงยุ่งเหยิง บรรยายสิ่งที่กล้องจับภาพได้จริง ไม่ใช่เวอร์ชันในอุดมคติ
ปัญหา: สีดูอิ่มตัวเกินไปหรือดูไม่เป็นธรรมชาติ
วิธีแก้
ระบุการรักษาเฉดสีอย่างชัดเจน: "natural color grading," "true-to-life colors," "muted earth tones," "not oversaturated," "color-accurate." อ้างอิงสต็อกฟิล์มเฉพาะสำหรับคำแนะนำเรื่องสี: "Kodak Portra color science" หรือ "documentary color grading." เพิ่ม "realistic color balance, no HDR look."
ปัญหา: การลบพื้นหลังสร้างรัศมีหรือสิ่งแปลกปลอม
วิธีแก้
ขออย่างชัดเจน: "transparent background (RGBA PNG format), crisp silhouette, no halos, no color fringing, clean edges, no artifacts." โปรดทราบว่าโมเดลปัจจุบันแสดงรูปแบบตารางหมากรุกสำหรับความโปร่งใส — อาจต้องมีการประมวลผลภายหลังสำหรับช่องอัลฟาที่แท้จริงในการผลิต
ปัญหา: องค์ประกอบรู้สึกไม่สมดุลหรือน่าอึดอัด
วิธีแก้
ระบุองค์ประกอบอย่างชัดเจน: "subject positioned using rule of thirds," "centered with symmetrical framing," "generous negative space on left for text overlay," "eye-level camera angle," "subject fills 60% of frame." อย่าปล่อยให้องค์ประกอบเป็นเรื่องของโชคชะตา — บรรยายสิ่งที่คุณต้องการให้ชัดเจน
อนาคตของการสร้างภาพด้วย AI
เรากำลังมีชีวิตอยู่ท่ามกลางการปฏิวัติ สิ่งที่เป็นนิยายวิทยาศาสตร์เมื่อสองปีก่อน ตอนนี้เป็นสินค้าที่ใครๆ ก็เข้าถึงได้ แต่เรายังอยู่ในบทแรกๆ ของเรื่องราวนี้ นี่คือสิ่งที่ผมเห็นกำลังจะมา
สิ่งที่มีอยู่บนขอบฟ้า
🎬 การรวมวิดีโออย่างราบรื่น
เส้นแบ่งระหว่างภาพนิ่งและวิดีโอกำลังจางลงอย่างรวดเร็ว คาดหวังการเปลี่ยนผ่านที่ราบรื่นจากการสร้างภาพไปสู่ลำดับภาพเคลื่อนไหวภายในอินเทอร์เฟซเดียวกัน เวอร์ชันแรกๆ อยู่ที่นี่แล้ว (Sora, Runway) และกำลังปรับปรุงอย่างรวดเร็ว คำสั่งภาพของคุณจะกลายเป็นคำสั่งวิดีโอด้วยการดัดแปลงเพียงเล็กน้อย
🎯 ความสม่ำเสมอที่สมบูรณ์แบบ
ความสม่ำเสมอของตัวละครและสไตล์ในภาพจำนวนไม่จำกัดโดยไม่ต้องใช้ความพยายามด้วยตนเอง ขั้นตอนการทำงานแบบสมอและอ้างอิงจะกลายเป็นอัตโนมัติ ฝึกฝนโมเดลด้วยตัวอย่างตัวละครของคุณเพียงไม่กี่ตัวอย่าง และมันจะรักษาความสม่ำเสมอที่สมบูรณ์แบบตลอดไป ปัญหา "การเบี่ยงเบน" จะได้รับการแก้ไขอย่างสมบูรณ์
✏️ การแก้ไขร่วมกันแบบเรียลไทม์
การแก้ไขแบบโต้ตอบที่คุณวาด ลาก และจัดการองค์ประกอบผ่านการสนทนาแบบเรียลไทม์ ลองนึกภาพ Photoshop ที่ทุกฝีแปรงกระตุ้นการตอบสนองของ AI และการแก้ไขที่ซับซ้อนเกิดขึ้นผ่านการสนทนาแทนที่จะเป็นเครื่องมือทางเทคนิค
🎨 การเรียนรู้สไตล์ส่วนตัว
ฝึกฝนโมเดลด้วยสุนทรียศาสตร์ของคุณด้วยตัวอย่างเพียงไม่กี่ตัวอย่าง ศิลปิน AI ส่วนตัวของคุณที่เข้าใจรสนิยม แบรนด์ ภาษาภาพของคุณ — และนำไปใช้อย่างสม่ำเสมอกับทุกสิ่งที่คุณสร้าง
การทำให้การสร้างสรรค์ภาพเป็นประชาธิปไตย
สิ่งที่เรากำลังเป็นพยานอยู่คือการทำให้การสร้างสรรค์ภาพเป็นประชาธิปไตย ทักษะที่เคยต้องใช้เวลาฝึกฝนนานหลายปี — การถ่ายภาพสินค้า การออกแบบกราฟิก ภาพประกอบ คอนเซ็ปต์อาร์ต — กำลังเข้าถึงได้สำหรับทุกคนที่สามารถบรรยายสิ่งที่พวกเขาต้องการเห็น
สิ่งนี้ไม่ได้กำจัดคุณค่าของความคิดสร้างสรรค์ของมนุษย์ ถ้าจะมีอะไร ก็เป็นการยกระดับมัน เมื่อการปฏิบัติกลายเป็นเรื่องง่าย วิสัยทัศน์จะกลายเป็นทุกสิ่ง คนที่จะเติบโตในภูมิทัศน์ใหม่นี้ไม่ใช่คนที่จะเรนเดอร์มือที่สมจริงที่สุดได้ — AI จัดการเรื่องนั้นแล้ว พวกเขาจะเป็นคนที่มีอะไรจะพูด มีอะไรจะแสดง มีสิ่งที่ขับเคลื่อนผู้คน
ช่างภาพที่เติบโตในช่วงการเปลี่ยนผ่านจากฟิล์มสู่ดิจิทัลไม่ใช่คนที่ต่อต้านการเปลี่ยนแปลง พวกเขาคือคนที่ยอมรับเครื่องมือใหม่ในขณะที่ยังคงรักษาวิสัยทัศน์ทางศิลปะของตนไว้ การสร้างภาพด้วย AI คือการเปลี่ยนผ่านแบบเดียวกัน เพียงแต่รุนแรงและรวดเร็วกว่า
ภาพที่สร้างโดย AI ที่ดีที่สุดจะถูกสร้างโดยคนที่เข้าใจทั้งเทคโนโลยีและศิลปะ เชี่ยวชาญเครื่องมือ แต่อย่าลืมว่าเครื่องมือรับใช้วิสัยทัศน์ เทคโนโลยีขยายความคิดสร้างสรรค์ของมนุษย์ — มันไม่ได้มาแทนที่
บทสรุป
ภาพขนาดย่อ กราฟิก และเนื้อหาโซเชียลในไม่กี่นาทีแทนที่จะเป็นชั่วโมง
การถ่ายภาพสินค้า ตัวแปร และการตลาดในระดับที่ไม่เคยมีมาก่อน
การสร้างแนวคิดและการนำเสนอต่อลูกค้าอย่างรวดเร็วที่เคยใช้เวลาหลายวัน
การเข้าถึงโปรแกรมที่แข็งแกร่งสำหรับการสร้างแอปพลิเคชันที่ใช้ภาพ
ภาษาธรรมชาติทำให้การเริ่มต้นง่ายกว่าเครื่องมือออกแบบแบบดั้งเดิม
คุณภาพและความสม่ำเสมอเพียงพอสำหรับงานเชิงพาณิชย์
ผมเริ่มต้นการเดินทางนี้ด้วยความหงุดหงิดและสงสัย ผมเคยได้ยินโฆษณาเกี่ยวกับการสร้างภาพด้วย AI แต่ก็ชนกำแพงระหว่างคำสัญญาทางการตลาดกับความเป็นจริงในทางปฏิบัติซ้ำแล้วซ้ำเล่า นิ้วมือที่มีกายวิภาคที่เป็นไปไม่ได้ ข้อความที่ละลายเป็นรูปร่างนามธรรม องค์ประกอบที่ต่อสู้กับความตั้งใจของผมอย่างแข็งขัน ผมพร้อมที่จะปัดตกทั้งหมดว่าเป็นเทคโนโลยีที่ถูกโฆษณาเกินจริง
จากนั้นผมก็ได้เรียนรู้ที่จะพูดภาษาของเครื่องจักร ผมเลิกบรรยายสิ่งที่ผมอยากเห็นและเริ่มบรรยายสิ่งที่กล้องจะจับภาพ ผมเลิกหวังพึ่งโชคและเริ่มสร้างอย่างเป็นระบบ ผมเลิกต่อสู้กับโมเดลและเริ่มร่วมมือกับมัน
GPT Image 1.5 ไม่ได้แค่ปรับปรุงปัญหาที่มีมาก่อนหน้านี้ — มันเปลี่ยนความสัมพันธ์ของผมกับการสร้างสรรค์ภาพไปโดยสิ้นเชิง ตอนนี้ผมคิดในแง่ของ Prompt และการทำซ้ำแทนที่จะเป็นแปรงและเลเยอร์ ผมเข้าหาความท้าทายทางภาพด้วยความมั่นใจว่ามีโครงสร้าง Prompt ที่จะผลิตสิ่งที่ผมต้องการ ภาพที่ผมสร้างในวันนี้อาจใช้เวลาหลายวันในการผลิตเมื่อสองปีก่อน ไอเดียที่ผมสามารถสำรวจได้ถูกจำกัดด้วยจินตนาการเท่านั้น ไม่ใช่ทักษะทางเทคนิค
เส้นโค้งการเรียนรู้นั้นมีอยู่จริง คุณจะไม่เชี่ยวชาญสิ่งนี้ในชั่วข้ามคืน แต่หลักการในคู่มือนี้ — โครงสร้างสำคัญกว่าคำหลัก, ความเฉพาะเจาะจงสำคัญกว่าคำคุณศัพท์, การทำซ้ำสำคัญกว่าความสมบูรณ์แบบ, กรอบความคิดแบบช่างภาพ — จะย่อเวลาหลายสัปดาห์ของการทดลองที่น่าหงุดหงิดให้เหลือเพียงการเรียนรู้ที่มุ่งเน้นและมีประสิทธิผล
เหนือสิ่งอื่นใด ผมหวังว่าคู่มือนี้จะมอบสิ่งผมหวังว่าจะมีตอนที่ผมเริ่มต้นให้กับคุณ: ไม่ใช่แค่เทคนิค แต่เป็นแบบจำลองทางความคิด ความเข้าใจว่าเทคโนโลยีนี้ตีความภาษาอย่างไร มันตอบสนองต่ออะไร และวิธีพูดภาษาภาพของมันอย่างคล่องแคล่ว
ช่องว่างระหว่างภาพในใจของคุณกับภาพบนหน้าจอของคุณไม่เคยเล็กเท่านี้มาก่อน และด้วยแนวทางที่ถูกต้อง ช่องว่างนั้นจะเล็กลงเรื่อยๆ ในทุก Prompt ที่คุณเขียน
ตอนนี้ไปสร้างสิ่งที่สวยงามกันเถอะ
ผมจำช่วงเวลาตอนตี 2 นั้นได้เมื่อทุกอย่างลงตัว — เมื่อภาพที่ปรากฏขึ้นไม่ได้แค่ยอมรับได้ แต่เป็นสิ่งที่ผมจินตนาการไว้เป๊ะๆ ความรู้สึกนั้นมีให้คุณแล้วตอนนี้ เทคโนโลยีมาถึงแล้ว เทคนิคได้รับการบันทึกไว้แล้ว สิ่งเดียวที่เหลือคือจินตนาการของคุณและความเต็มใจที่จะเรียนรู้ภาษาใหม่ เครื่องมือสร้างภาพ ChatGPT ไม่ใช่แค่เครื่องมือ — มันเป็นพันธมิตรที่สร้างสรรค์ที่ขยายวิสัยทัศน์ของมนุษย์ในรูปแบบที่เราเพิ่งเริ่มเข้าใจ ยินดีต้อนรับสู่อนาคตของการสร้างสรรค์ภาพ ภาพที่คุณเคยเห็นในใจของคุณ? พวกมันใกล้เคียงกับความจริงมากกว่าที่เคยเป็นมา
การสนทนา
0 ความคิดเห็นแสดงความคิดเห็น
เป็นคนแรกที่แบ่งปันความคิดของคุณ!