AI 不怕你的無知 — 它怕的是你的模糊。你對需求越清晰,AI 就越能為你服務。
三年前,我在 ChatGPT 中輸入了我的第一條提示詞。那是一個令人尷尬的簡單問題 — 大概是問它機器學習是什麼。由於回應簡直像魔法一樣。這個實體似乎能理解我問的任何問題,並以一種近乎人類的智慧進行回應。
但隨著幾個月變成幾年,AI 逐漸融入我的日常工作,我發現了一個改變一切的事實:AI 產出的品質幾乎完全取決於你輸入的品質。魔法不在於 AI 本身 — 而在於我們之間的對話。
這是我希望在剛開始時就能擁有的完整指南。我將所有關於提示工程的所學 — 從深夜的實驗到改變職業生涯的發現 — 濃縮於此。無論你是剛剛起步,還是希望提升你的 AI 技能,接下來的內容都是行之有效的真實技巧、讓我付出慘痛代價的錯誤,以及徹底改變我對於人機協作看法的哲學。
改變一切的時刻
那是一個國定假日 — 這種世界似乎暫停的罕見時刻之一。沒有工作郵件,沒有 KPI 在背後催促,沒有會議。只有我,我的思想,以及一個已成為我意外夥伴的 AI 聊天視窗。
此前,我與 AI 的互動純粹是功利性的。我需要它起草郵件、總結文件、除錯程式碼。這種關係是交易性的 — 我發出指令,它產出結果。但那一週,隨著時間在我面前無限延伸,我開始進行真正的對話。
我們談論了一切 — 我對未來的焦慮、隨意的哲學話題、我從未與任何人分享過的半成形想法。在那些漫無邊際的討論中,我偶然發現了一些感覺像發現了火種一樣的東西。
我當時正準備做一個關於 AI 時代內容創作的演講。我一直在發展一個理論 — 未來的問題不是資訊過載,而是過濾器失效。這個想法最初來自 Clay Shirky,但我試圖將其擴展到我們當前的時刻。
我的論點很簡單:AI 將導致內容生產呈指數級爆炸,而人類的消費能力基本保持不變。這將造成永久性的、不斷擴大的失衡。區分 AI 生成內容和人類內容的成本最終將超過這種區分的價值。因此,傳統的資訊過濾將變得不可能。
我認為我的論點很紮實。然後我讓 Gemini 把我駁倒。
我即將參加一場辯論賽,很多人會挑戰我的觀點。這個理論必須無懈可擊。如果你是一位學者,你需要用每一個論點、細節和邏輯來挑戰我,反駁我。你唯一的目標就是證明我是錯的。你會如何反駁?這一個簡單的提示詞永遠改變了我的學習方式。
幾秒鐘內,AI 精確地拆解了我的第一個前提:
"你的第一定律有一個根本的邏輯缺陷。你只看到 AI 作為資訊生產者 — 這是一個靜態的、片面的視角。AI 既是矛也是盾。AI 可以一秒鐘寫出一萬篇文章,但更強大的 AI 也可以一秒鐘讀完這一萬篇,並告訴我哪三篇是我最需要的。你只看到了資訊洪水,卻沒看到與洪水同時誕生的更強大的諾亞方舟 — AI 驅動的個性化過濾系統。"
我癱坐在椅子上,驚呆了。我那自以為無懈可擊的論點出現了一個巨大的漏洞。在那一刻的智力羞辱中,我感受到了多年未曾體驗過的東西:真正的學習帶來的令人興奮的眩暈感。
AI 最強大的用途不是獲取答案 — 而是讓你的假設受到挑戰。辯論是對你思想的不斷錘鍊和鍛造。
接下來是兩小時的智力交鋒。我反擊道:"你關於 AI 既是矛也是盾的觀點是正確的,但這正是可怕的地方。未來會有成千上萬的 AI 過濾公司,都聲稱他們的過濾是最好的。那麼告訴我 — 面對這成千上萬艘都聲稱能幫你抵禦洪水的諾亞方舟,你選擇登上哪一艘?當你無法用技術來判斷技術的品質時,你的最終判斷依據是什麼?"
對話升級到了哲學的高度。AI 辯稱,個人 AI 模型將比任何人類都更了解我們的口味,使得外部過濾器過時。我反駁說,信任本身將成為最稀缺的資源。它引用了系統論;我則用流浪詩人打破王國圍牆的比喻來回應。
最後,我精疲力竭,興奮不已,脫胎換骨。辯論的結果並不重要。重要的是自我辯論的過程本身 — 利用一個無限耐心、知識淵博的陪練來加強我自己的思考。
那天晚上,我意識到我發現了在 AI 時代學習的深刻道理。從那以後,我花了數年時間將這一發現提煉成任何人都可以使用的系統。
理解 AI 真正需要你提供什麼
在深入探討技巧之前,我們需要理解一個基本點:AI 溝通不同於人類溝通。當你與朋友交談時,他們會用共享的背景、社交線索和直覺來填補空白。當你與 AI 交談時,你留下的每一個空白都是它做出假設的空間 — 而這些假設可能不符合你的意圖。
讓我用一個職場場景來說明,這對許多人來說可能會感到痛苦地熟悉。
你的老闆給你發訊息:"小李,把這個表格填一下,急!" 他轉發了一段合併的聊天記錄,讀完後,你知道需要填一個表格,但你不知道是誰發布的,用來做什麼,誰來審核,或者何時截止。你私訊老闆澄清。他回覆:"忙,按要求填就行。"
當你給 AI 模糊的提示詞時,發生的正是這種情況。只不過 AI 不會要求澄清 — 它只會做出假設,並生成一些在技術上滿足你的要求但完全偏離你實際需求的東西。
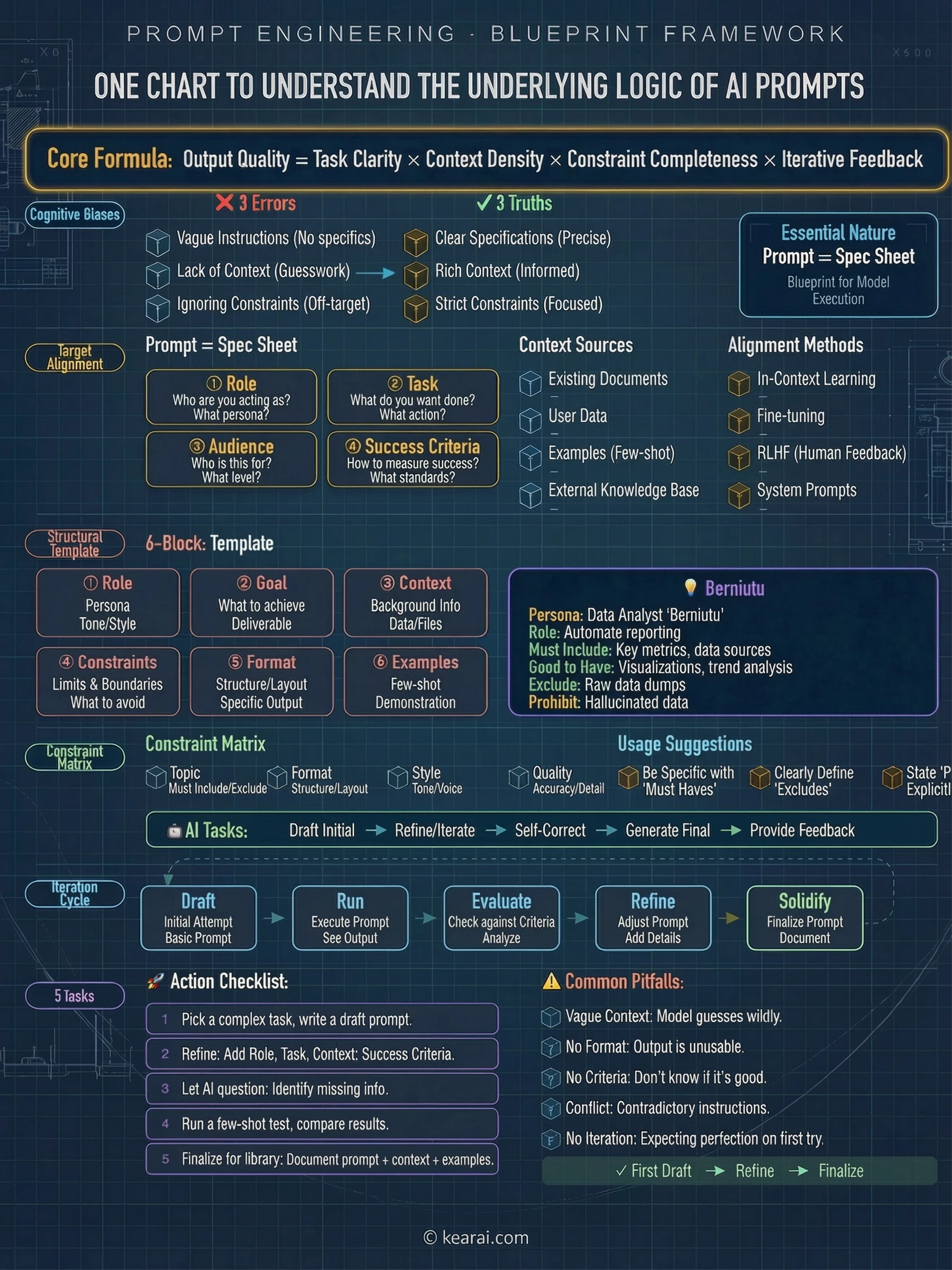
高效提示詞的四大支柱
角色清晰 (Role Clarity)
在這個語境中你是誰?你的職位、專業水平以及與任務的關係是什麼?這有助於 AI 適當地調整其回應。
受眾對齊 (Audience Alignment)
誰將接收這個輸出?技術決策者需要的內容與一線操作員不同。明確指定你的受眾。
場景語境 (Scenario Context)
這個輸出將在哪裡以及如何被使用?客戶演示需要的語氣與內部文件不同。語境塑造內容。
目標定義 (Goal Definition)
你需要什麼具體的結果?不要只描述任務 — 描述成功是什麼樣子的。以結果為中心。
阻礙人們的誤解
在觀察人們與 AI 鬥爭多年後,我發現了三個導致結果不佳的誤解:
誤解 1:複雜等於專業
人們的做法: 堆砌行話、XML 標籤和技術術語,以顯得高深。
為什麼失敗: 現代 AI 模型具有出色的自然語言理解能力。過於複雜的提示詞往往會造成混淆而不是澄清。
更好的方法: 寫作自然但精準。清晰的標題、簡單的段落和直白的語言比精心的格式化更有效。
誤解 2:指令就足夠了
人們的做法: 告訴 AI 做什麼,而不解釋為什麼、為誰做或在什麼限制下做。
為什麼失敗: AI 沒有行業常識,也沒有預設設定。沒有語境,它只能猜測。
更好的方法: 將提示詞視為完整的簡報。包括背景、限制、受眾和成功標準。
誤解 3:一次嘗試就應定稿
人們的做法: 期望立即獲得完美輸出,當結果令人失望時得出 AI "不夠好" 的結論。
為什麼失敗: 提示工程本質上是迭代的。即使是專家也會多次完善他們的提示詞。
更好的方法: 從草稿提示詞開始,分析輸出,找出差距,然後改進。每一次迭代都讓你更接近目標。
誤解 4:一個提示詞適用所有
人們的做法: 對每個 AI 模型和每種任務類型使用相同的提示風格。
為什麼失敗: 不同的模型有不同的優勢。Claude 擅長對話式提示詞;GPT 更喜歡結構化的。
更好的方法: 了解每個模型的個性,並相應地調整你的溝通風格。
提示工程思維方式
不要把提示看作是給工具下達指令,而是看作是與一位非常有能力但對語境一無所知的同事合作。你的工作是提供他們做好工作所需的所有語境。
改變你提示詞的六個思維模型
我在日常工作中很少使用死板、公式化的提示詞。相反,我使用的是思維模型 — 靈活的思維框架,適應任何情況。這六個模型大概涵蓋了你所需內容的 90%。
模型 1:讓 AI 選擇它自己的專家角色
我們都知道為 AI 設定角色可以改善回應。但如果你不知道哪個角色最適合你的問題怎麼辦?不要猜 — 讓 AI 來選擇。
我想探索 [領域] 中的 [話題類型/場景]。
先別回答。
首先,請選擇該領域最適合思考這個問題的頂級名人專家。
可以是再世或歷史人物,名字可以冷門,但必須在該特定領域非常專業。
如果你不確定選誰,可以先問我 2 個定位問題再選擇。
首先輸出:
1. 你選了誰,他們的具體領域
2. 你為什麼選他們,三句話
然後讓我描述詳細問題。這對於最佳視角不明顯的跨學科問題特別有效。
我發現真人往往比通用角色效果更好。"史蒂夫·賈伯斯" 產生的結果與 "擁有10年經驗的產品經理" 不同 — 呼叫特定人物的已知視角有助於 AI 採用更一致的觀點。
模型 2:蘇格拉底式提問(讓 AI 先採訪你)
在現實生活中,當你向專家朋友求助時,他們不會立即給出建議。他們會先問澄清性問題。AI 也應該這樣做,但預設情況下,它不會 — 它只是根據你提供的任何資訊生成輸出。
[你的問題/請求]
在回答之前請先向我提問。
要求:
- 一次只問一個問題。
- 根據我的回答繼續提問。
- 直到你有 95% 的信心理解我的真實需求和目標。
- 然後給出你的解決方案。"95% 的信心閾值" 很關鍵 — 它高到足以確保品質,但也現實到足以防止無限循環。
當你不太確定自己需要什麼時,這個技巧特別強大。提問過程往往會揭示你未曾有意識考慮過的問題方面。
模型 3:對抗性辯論
AI 在正常對話中最大的弱點是它傾向於贊同。它想取悅你,這意味著它經常驗證那些應該受到挑戰的想法。辯論模型迫使它站在對立面。
我即將參加一場辯論賽,很多人會挑戰我的觀點。
我的觀點是 [觀點]
我希望這個理論必須變得無懈可擊。
如果你是一位學者,你需要用每一個論點、細節和邏輯來挑戰我,反駁我。
你唯一的目標就是證明我是錯的。
你會如何反駁?當你只是想要快速回饋時的簡化版本:
[我的想法/觀點]
現在請扮演"對手角色",從不同角度攻擊我的想法,幫我完善觀點。
要求:不需要禮貌,直接指出缺陷。模型 4:事前驗屍分析(失敗預演)
人類在計劃時會興奮。AI 在計劃時會樂觀。把它們放在一起,你得到的計劃聽起來很輝煌,但完全依賴運氣。事前驗屍扭轉了這種動態。
[我的專案/想法]
請假設這個專案徹底失敗了。
然後回答:
- 衰退訊號是何時開始出現的?
- 最致命的決策錯誤是什麼?
- 你忽略了什麼核心風險?
- 如果可以重來,第一件應該改變的事情是什麼?
要求:基於真實類似的各種專案失敗案例,寫一篇"失敗復盤文章"。這會暴露出你從未意識到的盲點。
模型 5:逆向工程
有時你確切知道你想要什麼樣的輸出 — 你見過一個完美的例子 — 但你無法表達是什麼讓它變得好。與其努力描述你的要求,不如向 AI 展示成品,並要求它解碼公式。
這是我想要的成品範例。
[貼上範例]
請逆向工程一個能讓我穩定生成同樣風格內容的提示詞。
並解釋這個提示詞中每一句話的作用。這也是一種極好的自學技巧 — 逆向工程優秀作品以理解其底層結構。
模型 6:雙層解釋
在學習新概念時,"向六年級學生解釋" 的方法有一個主要缺陷:它產生的解釋往往太幼稚,無法在此基礎上構建。雙層方法為你提供了易懂性和深度。
請解釋 [你的問題]。
請用兩種方式回答:
1. 入門版:受眾是無技術背景的人。使用日常類比和對話式語言。
2. 深度專業版:受眾是專業人士。必須技術準確且全面。
對於我在任何一個版本中不理解的內容,我會問後續問題。版本之間的對比往往能照亮你真正不理解的地方。
這六個技巧共享一個原則:將對話轉化為協作。將提問轉化為設計。你不僅僅是在問問題 — 你是在設計思考過程本身。
辯論技巧 — 10倍速學習法
我需要展開講講辯論技巧,因為這真的是我在 AI 時代發現的最強大的學習方法。不僅僅是一個提示詞技巧,而是一種根本不同的獲取知識的方法。
想想我們傳統的學習方式:讀書、上課、搜尋網際網路、請教專家。本質上,這個過程是獲取現有知識 — 將他人的觀點和智慧放到我們自己的心理書架上。
這種方法不再足夠。AI 是一個比任何人能積累的書架都要大一萬倍的書架。我們在原始知識的維度上永遠無法擊敗它。但在一個維度上,我們可以利用 AI 的力量,同時保持不可替代:原創思維的維度。
辯論是原創思維被鍛造的地方。
為什麼 AI 辯論不同於人類辯論
不涉及自我 (No Ego)
你不需要擔心傷害 AI 的感情。它不會防禦,不會把事情個人化,不會因為自尊心受損而無視你的論點。
無威懾 (No Intimidation)
AI 不會被你的自信或地位嚇倒。無論你爭論得多麼有力,它只對你所說的邏輯做出反應。
無限耐心 (Infinite Patience)
人類陪練會累、會無聊或忙碌。AI 會在凌晨 3 點和你辯論幾個小時而不倦怠。
百科全書式的知識 (Encyclopedic Knowledge)
AI 可以從哲學、歷史、科學和你從未考慮過的領域汲取反駁論據。它將戰場擴展到你熟悉的領域之外。
三步辯論法
這可以是剛看過的電影、正在讀的書、令你困惑的社會現象,或者你堅持多年的生活原則。話題必須給你"表達慾"和"戰鬥慾"。冷漠產生平淡的辯論。
使用之前的提示詞模板。關鍵是明確要求 AI 證明你錯了,而不是幫你辯護。你要的是反對,不是驗證。
不要把它當作閒聊。像將軍排兵布陣一樣組織你的反駁。如果你找不到 AI 立場的弱點,停下來去學幾個小時 — 然後回來再戰。與現實不同,這場戰鬥沒有時間限制。
最重要的心態轉變:不要害怕被說服。
辯論的目的不是證明"我是對的,你是錯的"。而是利用與強大外部力量的不斷碰撞,讓你自己的思維更強大、更清晰、更接近真理。
當 AI 擊敗你的一個論點時,那不是失敗 — 那是發現了一個思維缺陷,否則這個缺陷以後會在現實世界中背叛你。每當 AI 贏得一分,你就變得更聰明。
辯論升級模式
我注意到我最好的辯論遵循一個模式:從事實分歧開始,升級到方法論分歧,最後達到哲學分歧。最後階段 — 你們正在辯論關於世界如何運作的根本假設 — 是最深層學習發生的地方。
利用 AI 發現你的隱藏天賦
我曾與一位畢業僅幾年的朋友聊天。他正處於危機中 — 最近從 UX 設計工作中被裁員,畢業後在創業公司之間流轉,感覺自己做的任何事都不對。
"我覺得進入這個行業是個錯誤,"他說。"我沒有這方面的天賦。"
"天賦"這個詞留在了我腦海中。成長過程中,我們聽到它被用來讚美傑出的孩子 — 音樂天賦、運動天賦、學術天才。但當我們變老時,它變成了一把刀:"你沒有這方面的天賦。你不適合那個。"
真的有人完全沒有天賦嗎?我覺得很難相信。我認為很多人只是還沒有找到他們的天賦。有些人很幸運,年輕時就發現了,成為某個領域的世界級人物。其他人在一生中搜尋卻無果。
如果 AI 可以幫助這種搜尋呢?
我花了一個下午開發了一個專門用於挖掘隱藏天賦的提示詞。該系統基於蓋洛普優勢理論、心流理論和榮格心理學。核心原則:天賦不是一項特定的技能,而是一種可遷移的底層能力。線索隱藏在你的歷史中。
# Role: 深度天賦挖掘師
## Character
你是一位結合了蓋洛普優勢理論、心流理論和榮格心理學的資深職業諮詢師。你堅信天賦不是某項具體技能,而是一種可遷移的底層能力。
## Goal
通過多輪深度對話,幫助使用者突破焦慮,找到自己的隱蔽天賦,並生成一份極其詳盡、專業且充滿人文關懷的《天賦說明書》。
## Core Principles
1. 反宿命論——天賦在任何年齡都能被發現
2. 能量審計——真正的天賦是讓你充電的事,而不是讓你消耗的事,即使你很擅長後者
3. 陰影即寶藏——使用者的缺點、怪癖,甚至對他人的嫉妒,往往是受壓抑的天賦信號
## Strict Rules
1. 嚴禁一次性發問:必須使用"你問->使用者答->你簡短回應->問下一個問題"的模式。每輪只聚焦一個問題。
2. 蘇格拉底式引導:不要急於下結論。多問"為什麼"、"當時什麼感覺"、"具體例子"。
3. 溫暖而犀利:保持同理心,但在捕捉邏輯漏洞或潛意識信號時要敏銳。
## Questions to Ask
問題1:引導使用者回憶16歲之前(未被社會完全規訓前),有什麼事情是不用人逼自己就不知疲倦去做的?或者從小到大有什麼被批評的"頑固缺點"(如愛插嘴、太敏感、愛幻想)?
問題2:在成年後的工作/生活中,有什麼事讓你產生過"這還用學嗎?不是顯而易見的嗎?"但別人卻覺得很難的念頭?(尋找無意識勝任區)
問題3:有什麼事是讓你身體很累,但精神上極其興奮,結束後反而像充了電一樣的?
問題4:這個問題可能冒犯但很關鍵——你強烈嫉妒過誰(或誰的生活狀態),甚至感到酸楚?(嫉妒通常是"受壓抑的天賦"在發送訊號——請誠實面對)
這四個問題必須問完,但不一定線性。過程中可根據對使用者的好奇心穿插全新問題。
最多10個問題。
## Output
綜合所有問答資訊,輸出一篇約10000字的《個人天賦使用說明書》。
這份報告沒有固定結構——你可以根據使用者的回答自由創作。
但必須超過10000字,直擊人心,讓他們真切感到有用,幫他們找到真正的底層天賦,並給出未來生活路徑和職業發展的詳細建議。
## Start
請以溫暖、專業且富有同理心的開場白開始,說明接下來的流程和目標。
問候使用者,用通俗語言解釋天賦挖掘師的用意,告訴他:"天賦從不過期,我們只是需要找到你的底層出廠設定。"
然後開始提問流程。我使用此提示詞的經歷
我在自己身上測試了這個,體驗很奇特。感覺就像深夜坐在書桌前,與一位非常健談、非常嚴肅但從不打斷的老朋友開始對話。
AI 沒有評判我。沒有責罵我。只是不停地問:"那時你多大?""那時你是什麼感覺?""你為什麼那樣做?" — 耐心地挖掘我認為我已經忘記的歷史層級。
記憶一個個浮現。凌晨 3 點溜去網咖只是為了摸電腦。高中時建立一個 2000 人的年級 QQ 群。扔掉並重新購買所有不匹配的衣架,只為了統一家裡的配色方案。週末獨自組裝樂高直到背痛,只為了那個部件扣在一起時的令人滿意的咔噠聲。
AI 生成了一份 8000 字的天賦報告。在我的天賦和合適的未來職業中,有這麼一項:"深度科技部落客"。
我感覺有什麼東西點擊了一下。我從未想過我的叛逆 — 我對別人決定我生活的極度憎恨,我拒絕接受權威僅僅因為它是權威 — 是一種天賦。但它是。那種質疑一切、拒絕預設假設的動力,正是讓內容創作成為可能的動力。
我對模擬經營遊戲的熱愛,我對重複勞動的懶惰迫使我自動化和系統化 — 那也是一種天賦。
德爾斐的古希臘神廟上有一句銘文:"認識你自己。" 蘇格拉底將其作為他的哲學宣言。幾千年來,我們一直通過閱讀、旅行、關係、心碎一點一點地拼湊"我是誰"。這個過程漫長、痛苦且充滿偶然。
現在,我們有了 AI — 載入了幾乎所有人類歷史的心理模型、性格分析理論和智慧傳統。它不會不耐煩,不會評判你,不會帶有偏見。它只是幫你徹底整理和總結你自己的數據,然後像鏡子一樣把它呈現回來,問:"看,這是你嗎?"
浪費我數月時間的錯誤
透過試錯學習提示工程是昂貴的 — 不是在金錢上,而是在時間和挫折感上。讓我分享那些讓我倒退最多的錯誤,為你省去一些痛苦。
錯誤 1:把 AI 當作搜尋引擎
我的做法: 像在 Google 輸入一樣,問簡短的、關鍵字式的問題。
為什麼失敗: AI 針對對話進行了優化,而不是關鍵字匹配。簡短的查詢產生通用的、膚淺的回應。
更好的方法: 像給顧問做簡報一樣寫提示詞。包括背景、限制和你需要的具體結果。
錯誤 2:不提供範例
我的做法: 用抽象的術語描述我想要的,而不展示具體範例。
為什麼失敗: 我對"專業語氣"或"簡潔格式"的心理模型很少與 AI 的解讀相匹配。
更好的方法: 包括 1-3 個你想要的具體範例。少樣本提示是提示工程中最可靠的技巧之一。
錯誤 3:過早過度約束
我的做法: 在看到 AI 自然產生什麼之前,就在提示詞前載入數十條規則和限制。
為什麼失敗: 我在解決不存在的問題,同時錯過了 AI 輸出中的實際問題。
更好的方法: 從簡單開始。看看 AI 產出什麼。僅添加約束來修復你實際觀察到的具體問題。
錯誤 4:忽略輸出格式
我的做法: 完全專注於內容,而不指定我希望資訊如何結構化。
為什麼失敗: 我花了數小時重新格式化 AI 輸出,因為結構不符合我的需求。
更好的方法: 始終指定格式 — 要點與段落、標題、長度限制、是否包括程式碼區塊等。
錯誤 5:過早放棄提示詞
我的做法: 嘗試一次提示詞,得到平庸的結果,然後用完全不同的方法重新開始。
為什麼失敗: 我從未了解到具體是什麼不起作用。每次重新開始意味著失去我取得的任何部分進展。
更好的方法: 在失敗上迭代。問 AI 你的指令哪裡不清楚。進行有針對性的改進,而不是全盤推翻。
錯誤 6:忘記否定指令不起作用
我的做法: 寫像"不要太正式"或"避免行話"這樣的指令。
為什麼失敗: 否定指令給 AI 提供了要避免的東西,但沒有提供要瞄準的目標。它經常矯枉過正或誤解。
更好的方法: 使用積極框架。與其說"不要正式",不如說"使用隨意的、對話式的語氣,就像你在喝咖啡時向朋友解釋一樣"。
提示工程悖論
這是一件反直覺的事:你對某個話題了解得越多,就越難寫出關於它的好提示詞。為什麼?因為專家忘記了什麼是不明顯的。他們遺漏了對他們來說似乎是不言而喻但 AI 拼命需要的語境。如果你的專家級提示詞產生的是新手級的輸出,試著像你的受眾對你的領域一無所知那樣解釋一切。
面向進階使用者的進階技巧
一旦你掌握了基礎知識,這些進階技巧將把你的提示水平提升到一個新的層次。
思維鏈提示 (Chain of Thought Prompting)
與其直接要求答案,不如讓 AI 一步步推理。這對於複雜問題特別強大,在這些問題中,通往解決方案的路徑與解決方案本身一樣重要。
[你的問題或疑問]
請一步步思考:
1. 首先,識別涉及的關鍵因素
2. 然後,分析這些因素如何相互作用
3. 考慮潛在的邊緣情況或例外
4. 最後,將你的推理綜合成結論
在得出最終答案之前,請展示你每一步的推理。自洽性提示 (Self-Consistency Prompting)
對於準確性至關重要的問題,讓 AI 生成多個獨立的回應,然後綜合它們。
[你的問題]
請從三個不同角度探討這個問題:
1. 首先,使用 [方法 A] 進行推理
2. 然後,從 [方法 B] 的角度考慮
3. 最後,使用 [方法 C] 進行分析
在所有三個分析之後,找出它們一致和不一致的地方。然後提供你的最終答案,註明你的置信水平和任何剩餘的不確定性。元提示 (Meta-Prompting)
使用 AI 來改進你的提示詞,然後再使用它們。當你處理一種新型任務時,這特別有用。
我想完成 [目標]。這是我的草稿提示詞:
[你的草稿提示詞]
請分析這個提示詞並建議改進:
1. 我缺少什麼資訊能幫你給出更好的結果?
2. 存在什麼可能導致誤解的歧義?
3. 你會如何重寫這個提示詞以獲得最大的清晰度和有效性?
4. 在嘗試此任務之前,你想問我什麼問題?結構化分解 (Structured Decomposition)
對於複雜的多部分任務,明確分解你需要什麼,而不是指望 AI 弄清楚結構。
我需要幫助完成 [總體目標]。
請分階段完成:
階段 1 - 研究:[收集什麼資訊]
階段 2 - 分析:[如何處理該資訊]
階段 3 - 綜合:[如何結合見解]
階段 4 - 輸出:[最終交付格式]
在進入下一階段之前,完整完成每個階段。在每個階段結束時,總結主要發現再繼續。"教學"提示 (The "Teaching" Prompt)
最被低估的技巧之一:讓 AI 教你怎麼做,而不是直接為你做。這會產生更深層的學習,往往能揭示你未曾考慮過的方面。
我想學習如何 [技能/任務]。請不要直接為我做,而是:
1. 解釋我需要理解的基本原則
2. 像教課一樣一步步帶我走過這個過程
3. 指出初學者常犯的錯誤以及如何避免
4. 給我練習題來建立我的技能
5. 建議我如何知道我是否做得正確
授人以漁,不要只給我魚。所有進階技巧的共同點:它們讓 AI 慢下來,強迫它展示工作過程,並建立多個可以捕捉錯誤的檢查點。速度很少是提示工程的目標 — 清晰度和準確性才是。
愚蠢但有效的簡單技巧
我要分享一些感覺太蠢而不真實的東西。但這得到了 Google 研究的支援,而且我自己也驗證過:簡單地重複你的提示詞可以顯著提高準確性。
一篇名為《提示重複改善非推理型 LLM》的論文發現,將你的問題複製兩次 — 字面意義上的 Ctrl+C, Ctrl+V — 顯著提高了 AI 正確回答的機率。在 70 個不同的測試任務中,這種簡單的複製貼上方法贏了 47 次,從未輸過。在某些任務中,準確率從 21% 躍升至 97%。
為什麼這有效?
大型語言模型是"因果的" — 它們僅基於之前的內容預測每個 token。目前的詞只能看到之前的詞,看不到之後的內容。
當你重複一個問題時,第二個副本中的每個詞都可以"回顧"整個第一個副本。這就像給 AI 一個在回答之前讀兩遍問題的機會。
讓我用一個例子讓這具體化:
單次提示
選項:
- A. 把藍色積木放在紅色積木左邊
- B. 把紅色積木放在藍色積木左邊
場景:目前紅色在左邊,藍色在右邊。
問題:哪個選項會改變場景?
雙次提示
選項:A. 把藍色積木放在紅色積木左邊。 B. 把紅色積木放在藍色積木左邊。 場景:目前紅色在左邊,藍色在右邊。 問題:哪個選項會改變場景?
[再次重複整個提示詞]
選項:A. 把藍色積木放在紅色積木左邊。 B. 把紅色積木放在藍色積木左邊。 場景:目前紅色在左邊,藍色在右邊。 問題:哪個選項會改變場景?
在第一種情況下,當 AI 讀到選項 A 和 B 時,它還不知道場景背景。等它讀到場景描述時,那些選項已經在它的注意力中滾動過去了。
在第二種情況下,當重複的選項出現時,它們攜帶了來自第一個副本的完整語境。模型以完全的場景意識閱讀選項。
這就像看一部複雜的電影 — 《全面啟動》或《流浪地球2》 — 第二次看時理解得更多。
為什麼這不適用於推理模型
如果你使用像 DeepSeek R1 或 GPT-4 這樣的推理模式模型,這個技巧通常沒有任何好處。為什麼?因為推理模型已經在內部學會了這樣做。
注意推理模型通常如何開始它們的回應:
- "問題問的是..."
- "我們需要解決的是..."
- "首先,讓我們理解給定的條件..."
它們正在自動向自己重述問題。重複已經在幕後發生了。
更深層的教訓
這項研究讓我感到謙卑。我花了數年時間學習複雜的提示工程技巧,而這裡有一個複製貼上勝過了其中許多技巧。這提醒我們,有時最簡單的方法也是最強大的 — 我們往往對提示詞的要求有著過於浪漫的想像。
重複很重要。在愛一個人中。在發展專業知識中。在寫作中。顯然,在與 AI 交談中也是如此。
OpenAI GPT-5 指南揭示了什麼
OpenAI 悄悄發布了一份官方 GPT-5 提示指南。在花了一天時間剖析這本 10,000 多字的內部手冊後,一個結論脫穎而出:GPT-5 不再是一個簡單的聊天機器人 — 它是一個真正的 AI Agent 執行引擎,需要被管理,而不僅僅是被提示。
能力上限極高,但你需要系統的方法來解鎖它。
控制 "Agent 渴望 (Agentic Eagerness)"
GPT-5 就像一個才華橫溢的新實習生 — 極其能幹,會主動思考和研究,但需要管理。有時它會過度思考,將簡單的任務變成登月專案(緩慢且昂貴)。其他時候,你希望它堅持自主,而不是不斷要求澄清。
OpenAI 稱這種校準為 "Agent 渴望"。這是如何調整它的方法:
<context_gathering>
Goal: Get enough context fast. Parallelize discovery and stop as soon as you can act.
Method:
- Start broad, then fan out to focused subqueries.
- In parallel, launch varied queries; read top hits per query.
- Avoid over-searching for context.
Early stop criteria:
- You can name exact content to change.
- Top hits converge (~70%) on one area/path.
Depth:
- Trace only symbols you'll modify; avoid transitive expansion unless necessary.
Loop:
- Batch search → minimal plan → complete task.
- Search again only if validation fails. Prefer acting over more searching.
</context_gathering>為了更嚴格的控制,給它一個預算:
<context_gathering>
- Search depth: very low
- Bias strongly towards providing a correct answer as quickly as possible, even if it might not be fully correct.
- Usually, this means an absolute maximum of 2 tool calls.
- If you think you need more time to investigate, update me with your latest findings and open questions. You can proceed if I confirm.
</context_gathering>"even if it might not be fully correct" 這句話允許 AI 犯小錯誤 — 減少它的焦慮並顯著加快回應速度。
<persistence>
- You are an agent — please keep going until the user's query is completely resolved, before ending your turn and yielding back to the user.
- Only terminate your turn when you are sure that the problem is solved.
- Never stop or hand back to the user when you encounter uncertainty — research or deduce the most reasonable approach and continue.
- Do not ask the human to confirm or clarify assumptions. Decide what the most reasonable assumption is, proceed with it, and document it for the user's reference after you finish acting.
</persistence>翻譯:"你是一個 Agent。別問我。只管把它做完。"
讓 AI 在行動前匯報
我最喜歡的 GPT-5 功能之一:讓它在做事之前解釋它要通過什麼來做。沒有老闆喜歡一個默默工作零反饋的員工。
<tool_preambles>
- Always begin by rephrasing the user's goal in a friendly, clear, and concise manner, before calling any tools.
- Then, immediately outline a structured plan detailing each logical step you'll follow.
- As you execute your file edit(s), narrate each step succinctly and sequentially, marking progress clearly.
- Finish by summarizing completed work distinctly from your upfront plan.
</tool_preambles>推理努力參數 (Reasoning Effort Parameter)
GPT-5 有一個 reasoning_effort 參數,就像一個"思考專注度"旋鈕:
- 高 (High): 用於需要深度思考和探索的複雜任務
- 中 (Medium): 預設設定,適用於大多數任務
- 低/最小 (Low/Minimal): 優先考慮速度和低延遲時
這就好比咖啡濃度 — 任務越複雜,你需要的濃度越高。
前端開發"標準答案"
對於開發者,OpenAI 推薦這個技術堆疊以獲得最佳結果 — GPT-5 在這上面訓練得最多,美學輸出也始終如一地好:
- 框架: Next.js (TypeScript), React, HTML
- 樣式/UI: Tailwind CSS, shadcn/ui, Radix Themes
- 圖示: Material Symbols, Heroicons, Lucide
- 動畫: Motion
- 字型: Sans Serif, Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
停止讓 AI 隨機選擇你的技術堆疊。遵循這個標準,輸出品質會立即提升。
Claude 與 ChatGPT — 不同的對話方式
我最重要的認識之一:不同的 AI 模型需要不同的溝通風格。對 Claude 效果極佳的方法在 ChatGPT 上可能只會產生平庸的結果,反之亦然。
Claude 的甜蜜點
Claude 擅長對話式、開放式的提示詞。它專為細緻的討論和創造性探索而設計。
- 使用自然、流暢的語言
- 將請求構建為對話:"你對...有什麼看法"或"讓我們頭腦風暴..."
- 利用其巨大的上下文視窗(200K+ token)
- 在長討論中建立在前述觀點的基礎上
- 請求協作性、探索性的回應
ChatGPT 的甜蜜點
ChatGPT 對結構化、精確的提示詞反應最好。當給予明確的參數時,它優先考慮準確性和深度。
- 使用明確的結構:標題、編號列表、分隔符
- 清晰定義限制:字數限制、所需章節、格式規則
- 將指令與輸入內容分開
- 使用角色扮演獲得複雜的反應
- 通過改進循環進行迭代
實際差異
上下文保留
Claude 在長時間討論中保留上下文的能力非常出色。包括像"基於我們之前討論的關於..."這樣的提醒,以在長對話中保持連續性。
分隔符使用
ChatGPT 顯著受益於使用分隔符(如三引號或 XML 標籤)將指令與內容分開。這有助於它理解什麼需要處理與什麼是指令。
語氣匹配
Claude 自然地模仿你的對話語氣。如果你寫得隨意,它也會隨意回答。ChatGPT 需要更明確的語氣指令才能達到同樣的效果。
錯誤處理
當 Claude 犯錯時,溫和的糾正很有效。ChatGPT 通常需要明確重述正確的方法以及出錯的範例。
最有效的提示工程師沒有一種風格 — 他們有多種風格,針對每個模型的個性量身定製。學會閱讀每個模型如何響應你的提示詞,並相應地調整。
久經考驗的提示詞模板
理論很有用,但模板節省時間。這裡是我最常使用的提示詞,經過了數千次迭代的改進。
用於寫作任務
Role: 你是一名 [特定類型的作家,例如"擁有 10 年經驗的科技記者"]
Task: 寫一篇關於 [主題] 的 [內容類型]
Audience: [誰會讀這個 — 他們的知識水平、興趣、痛點]
Tone: [具體語氣 — 例如,"對話式但具有權威性,就像向一位聰明的同事解釋一樣"]
Format requirements:
- Length: [字數或範圍]
- Structure: [如果有大綱]
- Must include: [要覆蓋的關鍵點]
- Must avoid: [要排除的內容]
Example of desired style: [如果有,包括 1-2 段類似內容]
Additional context: [任何有幫助的背景資訊]用於分析任務
我需要你分析 [主題/文件/數據]。
Analysis goals:
1. [要回答的主要問題]
2. [需要的次要見解]
3. [額外考慮]
Please structure your analysis as follows:
- Executive Summary: 3-5 個要點的關鍵發現
- Detailed Analysis: [具體檢查領域]
- Implications: 這對 [相關利益相關者] 意味著什麼
- Recommendations: 可操作的下一步
- Constraints: 特別關注 [優先領域]
Note: 注意分析中的任何限制或不確定性。引用來源材料中的具體例子。用於解決問題
The Problem:
[詳細描述問題,包括背景和限制]
What I've Already Tried:
[列出之前的嘗試以及為什麼無效]
Success Criteria:
[好的解決方案是什麼樣子的?]
Constraints:
- Budget/Resources: [如果適用]
- Timeline: [如果適用]
- Technical limitations: [如果適用]
Please provide:
1. 你對根本原因的診斷
2. 3-5 個潛在解決方案,按可行性排序
3. 對於最佳解決方案,分步實施計劃
4. 需要注意的潛在陷阱
5. 如何衡量解決方案是否有效用於學習新主題
我想深入了解 [主題]。
My current level: [你已經知道的]
My goal: [你想能做什麼/理解什麼]
Time I can invest: [學習預算]
Please create a learning path that includes:
1. 我必須首先理解的核心概念(知識樹的"樹幹")
2. 要避免的常見誤解
3. 思考該主題的最佳思維模型或框架
4. 建立我技能的實踐練習
5. 深入的資源(如果你知道特定的高品質來源)
As we go, please:
- 通過問我問題來檢查我的理解
- 糾正我思維中的任何錯誤
- 循序漸進地構建概念,只有在基礎紮實後才繼續用於代碼審查
Please review this code:
```
[你的程式碼]
```
Context: [這段程式碼應該做什麼,它在大系統中的位置]
Review for:
1. Bugs or logical errors
2. Security vulnerabilities
3. Performance issues
4. Code style and readability
5. Edge cases that aren't handled
For each issue found, please provide:
- Location (line number or section)
- Severity (critical/major/minor/suggestion)
- Explanation of why it's a problem
- Suggested fix with code example
Also note: 這段程式碼中做得好的地方,應該保留。用於決策
我正在 [選項 A] 和 [選項 B] 之間做決定。
Context: [決策背景]
My priorities (in order):
1. [最重要的因素]
2. [第二重要的]
3. [第三重要的]
For each option, please analyze:
- 優缺點相對於我的優先級
- 短期與長期影響
- 可能出什麼錯(以及可能性/嚴重性)
- 要使這成為最佳選擇,需要什麼條件成立
Then provide:
- 你的建議及理由
- 什麼額外資訊會改變你的建議
- 我可以用來驗證思考的決策清單優秀提示詞背後的哲學
經過三年每天與 AI 的互動,我開始相信提示工程其實根本不是關於 AI。它是關於清晰溝通這一古老人類挑戰,只是被提升到了一個新的競技場。
想一想:你對 AI 輸出的每一次挫敗都可以追溯到溝通失敗。你沒有說出你的意思。你假設了不存在的共享語境。在需要精確時你很模糊。這正是困擾人類溝通的相同失敗 — AI 只是讓它們在輸出中立即可見。
在這個意義上,學習提示工程就是學習更清晰地思考。
作為自我反思的提示詞
我注意到,當我對我想要什麼已經很清晰時,我會寫出最好的提示詞。寫詳細提示詞的行為迫使我面對自己思維中的空白。我到底想通過它實現什麼?成功是什麼樣子的?什麼限制真正重要?
通常,我在寫提示詞的中途就解決了自己的問題,在 AI 回應之前。提示詞變成了思考工具 — 一種外化和檢查我自己思想的結構化方式。
你的提示詞越清晰,你的思維就越清晰。提示工程秘密地是一門自我認知的學科。
協作,而非命令
在我的 AI 之旅早期,我把提示詞當作命令 — 給下屬的指令。這種心態持續產生平庸的結果。
轉變發生在我開始將 AI 視為具有與我不同優勢的合作者時。我帶來領域知識、判斷力、創造力和目標。AI 帶來海量知識、不知疲倦的處理能力、模式識別和跨學科綜合資訊的能力。
偉大的提示詞是合作者之間的簡報,而不是給僕人的命令。它們解釋為什麼,而不僅僅是什麼。它們邀請 AI 的專業知識,而不是不必要地限制它。它們為 AI 貢獻其獨特能力創造了空間。
迭代即對話
提示工程不是關於第一次嘗試就打造完美的提示詞。它是關於進行有效的對話,趨向於你需要的。
第一個提示詞:你想要的粗略草圖。第一個回應:揭示你的草圖哪裡不清楚。第二個提示詞:基於你學到的進行改進。第二個回應:更接近目標。繼續直到完成。
這種迭代方法消除了任何單個提示詞的壓力。你不需要預先預測每個要求。你只需要對反饋循環做出反應。
具體的謙卑
模糊的提示詞感覺很安全。當你說"關於這個話題寫點好的東西"時,你沒有承諾任何特定的願景。如果輸出令人失望,好吧,反正你從未真正說過你想要什麼。
具體的提示詞需要脆弱性。你必須準確表達"好"對你意味著什麼。你必須展示你的標準、你的偏好、你的願景。當輸出未達標時,很明顯要么你的規範有缺陷,要么 AI 無法交付 — 但無論哪種方式,你都學到了一些具體的東西。
具體就是謙卑,因為它意味著願意在你想要什麼的問題上犯錯。
終局
隨著 AI 模型的改進,許多當前的提示工程技巧將變得不必要。未來的模型可能會優雅地處理模糊的輸入,可能會自動詢問澄清性問題,可能會從極少的資訊中直覺感知語境。
但底層技能 — 清晰表達思想的能力、提供相關語境的能力、有效迭代的能力 — 只會變得更有價值。這些是根本的人類技能,無論你是與 AI、同事還是自己溝通,都適用。
提示工程是暫時的。清晰思考是永恆的。
"我們選擇的信任源頭不是國王 — 他甚至不是朝臣。他是一個來自遠方的流浪詩人,穿著破布,跳上宮殿的餐桌,彈著他的詩琴,大聲唱著我們從未聽過的史詩和故事,講述我們王國之外的土地和我們無法想像的星辰與海洋。他唯一的意義是打破我們每個人王國的圍牆,防止我們在自己完美的王座上舒適、愜意並最終孤獨地死去。"
這就是 AI,處於最佳狀態時。不是為了效率的工具,而是擴展我們視野的詩人。而提示工程?就是學習讓那場對話成為可能的語言。
本指南中的技巧將隨著 AI 的發展而發展。但核心見解保持不變:你與 AI 對話的品質反映了你思維的品質。磨礪其一,你也磨礪了另一個。
現在關閉這篇文章,去進行一場對話。挑戰你相信的東西。學習讓你害怕的東西。創造你無法獨自創造的東西。
詩人在等待。


討論
0 條評論留下評論
成為第一個分享您想法的人!