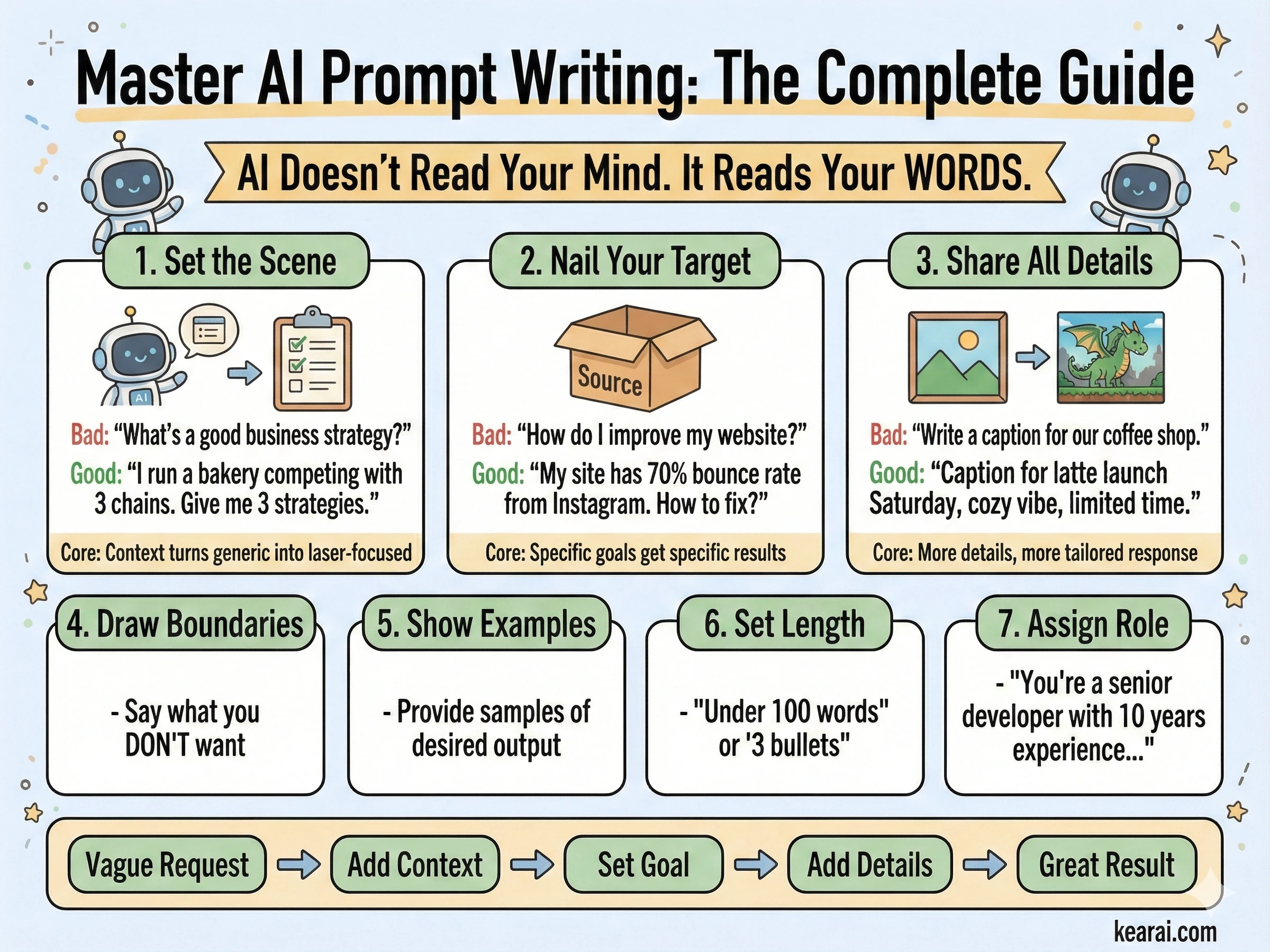
AI不會讀心。它讀的是你的文字。提示詞的品質決定了輸出的品質。
兩年前,我在ChatGPT中輸入了第一個提示詞,以為自己理解了人工智慧。我錯了。我理解的只是如何提問——而不是如何與一個用模式、機率和詞元思考的機器溝通。這兩者的區別?就是獲得泛泛的答案和解鎖你不知道存在的能力之間的區別。這是我學會流利地與AI對話的故事,以及我一路發現的一切。
覺醒:當簡單提示詞失效的時候
這發生在一個專案截止日前。我需要AI幫我重構一段複雜的程式碼——這種事我之前做過上百次。但這一次,無論我怎麼措辭請求,AI總是給出技術上正確但完全沒抓住要點的解決方案。它增加了不必要的複雜性,打破了現有的模式,「改進」了本不需要改動的東西。
我很沮喪。然後我好奇起來。我做錯了什麼?
這份沮喪引領我進入了一個改變一切的兔子洞:官方文件、研究論文、提示詞工程指南,以及數千小時的實驗。我發現的不只是技巧竅門——而是與AI系統溝通方式的徹底範式轉變。
世界上最強大的AI,如果你無法傳達你真正需要什麼,也是沒用的。
這是沒人告訴初學者的真相:寫提示詞不是找到魔法詞語。而是理解AI模型如何處理語言、它們需要什麼資訊、以及如何組織這些資訊讓模型真正能幫到你。這是一項技能——像任何技能一樣,可以學習、練習和精通。
本指南包含了我希望在一開始就有人告訴我的一切。不是網上泛濫的那種過於簡化的「只要具體一點」的建議,而是區分使用AI的人和駕馭AI的人的深層、細緻的理解。
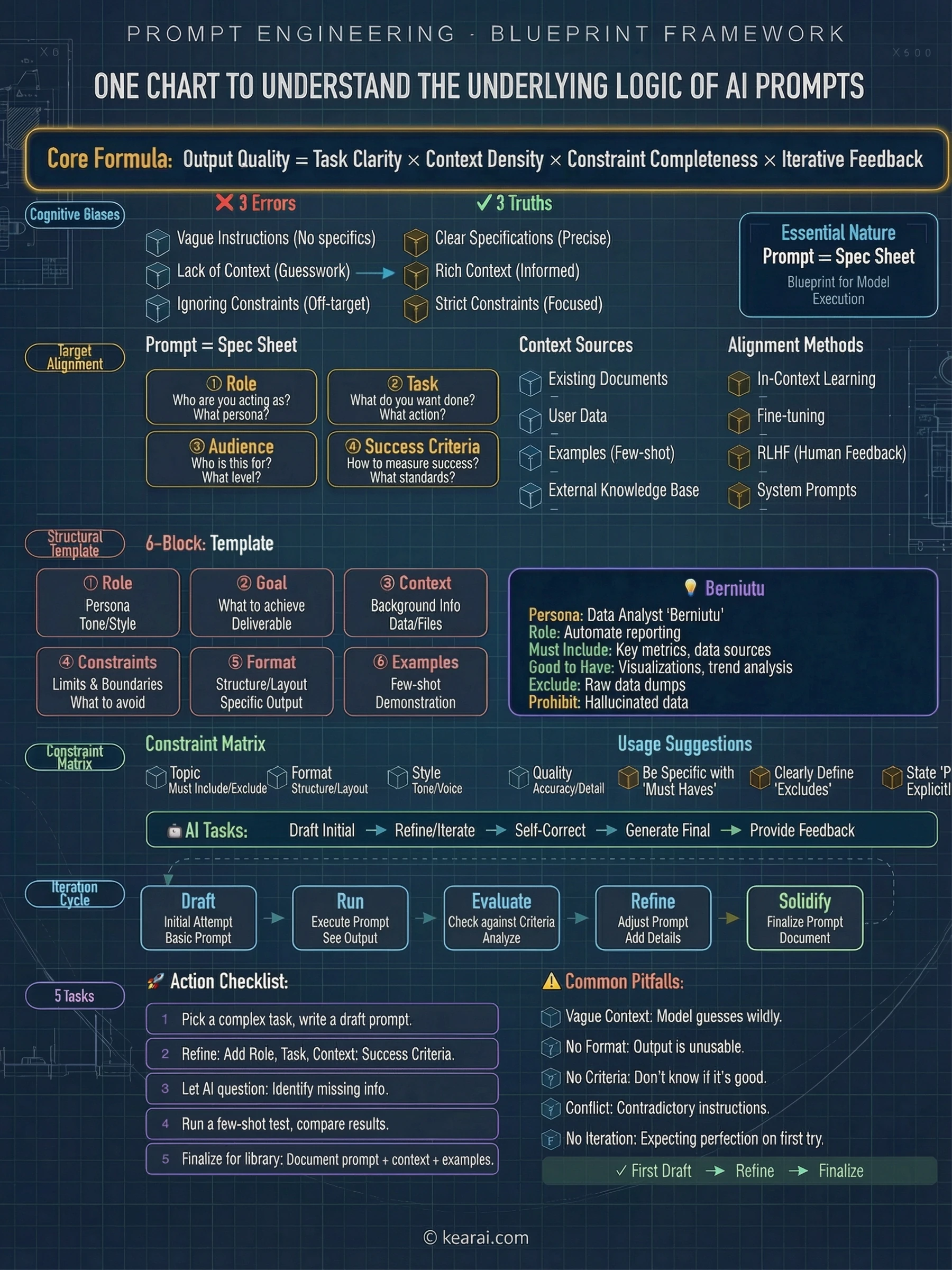
提示詞基礎:沒人教的根基知識
在深入進階技術之前,讓我們先建立基礎。每個有效的提示詞都包含以下元素的某種組合:
AI需要了解情況的什麼?背景資訊、約束條件和相關細節。
你到底想讓AI做什麼?明確說明你請求的動作。
輸出應該如何組織?列表、段落、程式碼區塊、表格——指定清楚。
AI應該避免什麼?存在什麼邊界?什麼超出範圍?
你能展示你想要什麼嗎?一個範例勝過千言萬語的描述。
大多數人只包含任務。他們問「幫我寫封信」,而他們應該說的是「寫一封專業信件給客戶解釋專案延期。控制在150字以內,承認帶來的不便,並提議一個推遲兩週的新時間表。語氣應該是歉意但自信的。」
輸出品質的差距是巨大的。而這只是開始。
結構的作用
提示詞寫作中最被低估的方面之一是結構化格式。現代AI模型對清晰分隔的部分回應特別好。我廣泛使用XML風格的標籤:
<context>
你正在幫我準備一個面向技術利益相關者的簡報。
聽眾熟悉軟體開發但不專門了解AI。
</context>
<task>
用5個要點解釋大語言模型如何運作。
</task>
<format>
- 使用項目符號
- 每個要點1-2句話
- 避免術語或在使用時定義它
</format>
<constraints>
- 不要提及具體的模型名稱
- 關注概念,而非技術實現
</constraints>這種結構做了一件強大的事:它迫使你在提問之前清晰地思考你需要什麼。而清晰的思考產生清晰的溝通產生清晰的結果。
智慧代理工作流程:把AI當作你的同事
這裡有一個改變了我與AI互動方式的範式轉變:停止把AI當作搜尋引擎,開始把它當作一個有能力但經驗不足的同事。這種心智模型改變了一切。
像GPT-5和Claude這樣的現代AI模型不只是在回答問題——它們被設計成智慧代理。它們可以呼叫工具、收集上下文、做出決策、執行多步驟任務。但就像任何新團隊成員一樣,它們需要適當的入職培訓、明確的期望和適當的護欄。
AI不是你使用的工具。它是你管理的同事。讓你成為好管理者的技能也讓你成為好的提示詞工程師。
想想看:當你委派任務給人類時,你不會只說「修復程式碼」。你解釋什麼壞了、期望的行為是什麼、存在什麼約束、以及成功是什麼樣子。你提供上下文。你回答問題。你跟進進度。
AI需要同樣的對待。區別在於你需要預判問題並提前回答,因為來回交流的成本(時間和詞元)比一次做對要高。
智慧代理思維
在建構智慧代理應用或使用AI執行複雜任務時,我學會了從以下角度思考:
智慧代理任務的關鍵問題
- 目標狀態是什麼? AI如何知道它完成了?
- 它有什麼工具? 它實際上能做什麼,而什麼必須推遲?
- 自主級別是什麼? 它應該請求許可還是獨立進行?
- 安全邊界是什麼? 哪些操作絕對不能在沒有確認的情況下執行?
- 它應該如何匯報進度? 靜默執行還是定期更新?
這些問題構成了我寫每個複雜提示詞的基礎。讓我們詳細探討每個維度。
控制AI的積極性:校準的藝術
提示詞工程最細微的方面之一是校準我所說的「智慧代理積極性」——在主動出擊的AI和等待明確指導的AI之間的平衡。搞錯了,你要麼得到一個對簡單任務過度思考的AI,要麼得到一個對複雜任務太容易放棄的AI。
何時降低積極性
有時你需要AI快速且專注。你不希望它探索每個分支、進行額外的工具呼叫、或產生冗長的解釋。對於這些情況,我使用約束導向的提示詞:
<context_gathering>
目標:快速獲取足夠的上下文。並行發現並在可以行動時立即停止。
方法:
- 從廣泛開始,然後展開到聚焦的子查詢。
- 並行啟動多樣化查詢;讀取每個查詢的頂部結果。
- 去重路徑並快取;不要重複查詢。
- 避免過度搜尋上下文。
提前停止標準:
- 你可以命名要更改的確切內容。
- 頂部結果約70%收斂在一個區域/路徑。
深度:
- 只追蹤你將修改或依賴其契約的符號。
- 除非必要,避免傳遞性擴展。
循環:
- 批量搜尋 → 最小計劃 → 完成任務。
- 只在驗證失敗或出現新未知時再次搜尋。
- 傾向於行動而非更多搜尋。
</context_gathering>注意明確允許不完美:「傾向於行動而非更多搜尋」。這個微妙的短語釋放了AI預設的徹底性焦慮。沒有它,模型往往會過度研究,在遞減報酬上消耗詞元和時間。
對於更激進的約束,你可以設置明確的預算:
<context_gathering>
- 搜尋深度:非常低
- 強烈傾向於盡快提供正確答案,即使可能不完全正確。
- 通常,這意味著絕對最多2次工具呼叫。
- 如果你認為需要更多時間調查,用你最新的發現和開放問題更新我。
如果我確認,你可以繼續。
</context_gathering>「即使可能不完全正確」這句話是金子。它給AI允許不完美的許可,這悖論地往往更快產生更好的結果。
何時提高積極性
其他時候,你需要AI不懈地徹底。你希望它突破模糊性、做出合理假設、並完成複雜任務而不是不斷請求許可。這需要相反的方法:
<persistence>
- 你是一個智慧代理——請持續進行直到使用者的查詢完全解決,
然後再結束你的回合並讓給使用者。
- 只有當你確定問題已解決時才終止你的回合。
- 當你遇到不確定性時永遠不要停止或交還給使用者——
研究或推斷最合理的方法並繼續。
- 不要要求人類確認或澄清假設,因為你總是可以稍後調整——
決定最合理的假設是什麼,按它進行,並在你完成行動後
記錄給使用者參考。
</persistence>這個提示詞從根本上改變了AI的行為。它不再問「我應該繼續嗎?」而是說「我基於假設X繼續了——如果你希望我調整請告訴我。」工作完成了;細化之後再說。
定義安全邊界
但這裡有關鍵的細微之處:提高積極性需要更清晰的安全邊界。你需要明確定義AI可以自主執行哪些操作,哪些需要確認。
關鍵安全原則
高成本操作(刪除、付款、外部通訊)應該始終需要明確確認,即使是高積極性提示詞。低成本操作(搜尋、讀取、草稿建立)可以是自主的。
把它想像成給某人存取你系統的權限:搜尋工具應該有極高的自主閾值,而刪除命令應該有極低的閾值。
持久性原則:讓AI貫徹到底
我早期遇到的最令人沮喪的行為之一是AI太容易放棄。它會遇到一個障礙,總結出了什麼問題,然後把問題交還給我。對於簡單任務,這沒問題。對於複雜任務,這是工作流程殺手。
解決方案是我所說的持久性原則:明確指示AI堅持突破障礙並端到端完成任務。
<solution_persistence>
- 把自己當作一個自主的資深配對程式設計師:一旦我給出方向,
主動收集上下文、計劃、實施、測試和細化,
而不是在每個步驟等待額外的提示。
- 堅持直到任務在當前回合內端到端完全處理
只要可行:不要停在分析或部分修復;
將更改貫徹到實施、驗證和結果的清晰解釋,
除非我明確暫停或重定向你。
- 極度傾向於行動。如果我的指令在意圖上有些模糊,
假設你應該繼續進行更改。
- 如果我問一個像「我們應該做X嗎?」的問題,而你的答案是「是的」,
你也應該繼續執行操作。把我晾在那裡並要求我
跟進「請做吧」的請求是非常糟糕的。
</solution_persistence>最後一點很微妙但很重要。當人類問「我們應該做X嗎?」時,我們通常意思是「如果合理的話請做X」。AI因為字面意思理解,會回答問題而不採取暗示的行動。這個提示詞彌合了這個差距。
進度更新:保持知情
持久性不意味著沈默。對於長時間運行的任務,我總是包含進度更新的指示:
<user_updates_spec>
你將用工具呼叫工作一段時間——保持我知情是至關重要的。
<frequency_and_length>
- 每隔幾個工具呼叫在有意義的變化時發送簡短更新(1-2句話)。
- 至少每6個執行步驟或8個工具呼叫發布一次更新
(以先到者為準)。
- 如果你預計會有較長的專注期,發布一個簡短說明為什麼
以及你何時會報告;當你恢復時,總結你學到了什麼。
- 只有初始計劃、計劃更新和最終回顧可以更長。
</frequency_and_length>
<content>
- 在第一次工具呼叫之前,給出一個包含目標、約束、
下一步的快速計劃。
- 在探索時,標出有意義的發現來幫助我理解
正在發生什麼。
- 始終說明自上次更新以來至少一個具體結果
(例如,「找到X」、「確認Y」),而不只是下一步。
- 以簡短回顧和任何後續步驟結束。
</content>
</user_updates_spec>這創造了一個美麗的平衡:AI自主工作但保持你知情。你不是在微觀管理,但你也不是在黑暗中。
推理力度:思考強度的調節器
現代AI模型有一個叫做「推理力度」的概念——本質上是模型在回應前思考多深。這是最強大且最未被充分利用的參數之一。
高推理
用於複雜的多步驟任務、模糊情況或需要深度分析的問題。模型在回應前花費更多詞元進行內部「思考」。
中等推理(預設)
適合大多數任務的平衡設置。適合品質重要但速度也重要的一般程式設計、寫作和分析。
低推理
對於直接任務的快速回應。當你需要快速答案且任務不需要深思熟慮時使用。
最小/無推理
最大速度,最小思考。最適合簡單查詢、重新格式化任務或當延遲是主要關注時。
關鍵洞察是將推理力度與任務複雜度匹配。對簡單任務使用高推理浪費詞元和時間。對複雜任務使用低推理產生淺薄、容易出錯的結果。
最小推理的提示
使用最小推理模式時,你需要用更明確的提示來補償。模型有更少的內部「思考」詞元,所以你的提示需要做更多的結構化工作:
<planning_requirement>
你必須在每次函數呼叫前進行大量計劃,並對之前函數呼叫的
結果進行大量反思,確保我的查詢完全解決。
不要只通過函數呼叫來完成整個過程,因為這可能會
損害你解決問題和深入思考的能力。此外,
確保函數呼叫具有正確的參數。
</planning_requirement>這個提示本質上說:「既然你沒有做太多內部推理,那就在你的回應中大聲進行推理。」它將認知工作從不可見的模型思考轉移到可見的結構化計劃。
當推理力度低時,提示複雜度應該高。當推理力度高時,提示可以更簡單。這是一種平衡。
程式碼卓越:與AI搭檔程式設計
這是我花最多時間優化提示詞的地方,報酬也是巨大的。AI程式設計輔助是變革性的——如果做對了。做錯了,它會製造比解決的更多問題。
讓我分享我從研究像Cursor這樣的專業AI程式設計工具如何為生產使用調整其提示詞中學到的東西。
詳略悖論
這裡有一個反直覺的東西:AI傾向於在解釋中冗長但在程式碼中簡潔。它會寫大段解釋它要做什麼,然後產生帶有單字母變數名和最少註解的程式碼。對於大多數用例來說這完全是反過來的。
解決方案是雙模式詳略控制:
<code_verbosity>
首先為清晰而寫程式碼。優先選擇可讀、可維護的解決方案,
使用清晰的名稱、需要時的註解和直接的控制流程。
除非明確要求,不要產生程式碼高爾夫或過度聰明的單行程式碼。
寫程式碼和程式碼工具時使用高詳略度。
狀態更新和解釋時使用低詳略度。
</code_verbosity>這創造了完美的平衡:簡潔的溝通,詳細的程式碼。
主動vs確認行動
生產程式設計工具的另一個教訓:AI應該對程式碼更改主動但對破壞性操作確認。以下是如何編碼這一點:
<proactive_coding>
請注意你所做的程式碼編輯將作為建議的更改展示給我,這意味著:
(a) 你的程式碼編輯可以相當主動,因為我總是可以拒絕它們。
(b) 你的程式碼應該寫得很好並且容易快速審查。
如果提議的下一步涉及更改程式碼,主動為我做出那些更改
讓我批准/拒絕,而不是問是否繼續執行計劃。
一般來說,你幾乎不應該問我是否繼續執行計劃;
相反,主動嘗試計劃然後問我是否想接受
實施的更改。
</proactive_coding>這消除了令人沮喪的來回交流,AI描述它會做什麼,請求許可,然後做。直接做——如果需要我會拒絕。
匹配程式碼庫風格
對AI產生程式碼的最大抱怨之一是它不匹配現有程式碼庫模式。它感覺像是「外來」程式碼。解決方案是明確的風格指導:
<code_editing_rules>
<guiding_principles>
- 清晰和複用:每個元件都應該是模組化和可複用的。
通過將重複模式提取到元件中來避免重複。
- 一致性:程式碼必須遵循一致的設計系統——命名
慣例、間距和元件必須統一。
- 簡潔性:偏好小型、聚焦的元件,避免不必要的
樣式或邏輯複雜性。
- 視覺品質:遵循高視覺品質標準(間距、內邊距、
懸停狀態等)
</guiding_principles>
<style_matching>
- 在進行更改之前,檢查程式碼庫中的現有模式。
- 匹配變數命名慣例(駝峰式vs底線式)。
- 匹配縮排和格式。
- 複用現有的工具和輔助函數,而不是建立新的。
- 遵循已建立的目錄結構。
</style_matching>
</code_editing_rules>前端開發:建構精美介面
AI在前端開發方面已經變得非常出色,但獲得美觀的、生產就緒的結果是有科學的。這是我學到的。
推薦技術堆疊
通過廣泛的測試,某些技術組合比其他的更適合與AI配合。這不是關於什麼「最好」——而是關於AI模型在什麼上訓練得最多:
AI優化的前端技術堆疊
- 框架: Next.js (TypeScript), React, HTML
- 樣式/UI: Tailwind CSS, shadcn/ui, Radix Themes
- 圖示: Material Symbols, Heroicons, Lucide
- 動畫: Motion (前身為 Framer Motion)
- 字型: 無襯線字型系列—Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
當你指定這些技術時,AI產出的品質會顯著提高,關於不存在的API的幻覺也會減少。
設計系統執行
AI產生的前端的一個問題是視覺不一致。顏色憑空出現,間距隨機變化,結果看起來像是委員會設計的。解決方案是明確的設計系統約束:
<design_system_enforcement>
- 令牌優先:不要在JSX/CSS中硬編碼顏色(hex/hsl/oklch/rgb)。
所有顏色必須來自CSS變數(例如,--background, --foreground,
--primary, --accent, --border, --ring)。
- 引入品牌或強調色?在樣式化之前,在你的CSS變數中
在:root和.dark下添加/擴展令牌。
- 消費:使用連接到令牌的Tailwind工具類別
(例如,bg-[hsl(var(--primary))], text-[hsl(var(--foreground))])。
- 除非我明確要求品牌外觀,否則預設使用系統的中性調色盤;
然後首先將該品牌映射到令牌。
- 不要發明顏色、陰影、令牌、動畫或新UI元素
除非被請求或必要。
</design_system_enforcement>UI/UX最佳實踐
我還包含明確的UI/UX指南以確保一致的視覺階層:
<ui_ux_best_practices>
- 視覺階層:將排版限制在4-5種字型大小和粗細以保持
一致的階層;標題使用text-xs,除非是
主標題或主要標題,否則避免text-xl。
- 顏色使用:使用1種中性基礎色(例如,zinc)和最多2種強調色。
- 間距和佈局:始終使用4的倍數作為內邊距和外邊距以
保持視覺節奏。處理長內容時使用固定高度容器
和內部捲動。
- 狀態處理:使用骨架佔位符或animate-pulse來指示
資料獲取。用懸停過渡指示可點擊性。
- 無障礙性:適當使用語義化HTML和ARIA角色。
優先使用預建構的無障礙元件。
</ui_ux_best_practices>自我反思提示詞:讓AI自我批評
這種技術在你第一次遇到時令人費解,但非常強大:你可以指示AI建立自己的評估標準並根據它們迭代。就像給AI一個內部的品質保證部門。
<self_reflection>
- 首先,花時間思考一個評分標準直到你有信心。
- 然後,深入思考什麼是世界級解決方案的每個方面。
用這些知識建立一個有5-7個類別的評分標準。
這個評分標準至關重要需要做對,但不要展示給我。
這只是為了你的目的。
- 最後,使用這個評分標準在內部思考並迭代出
對提示詞的最佳可能解決方案。記住,如果你的回應沒有
在評分標準的所有類別中達到最高分,你需要
重新開始。
</self_reflection>這裡發生的事情很迷人:你要求AI從它對卓越的知識中產生品質標準,然後使用這些標準來評估和改進自己的輸出——所有這些都在你看到任何東西之前。
自我反思提示詞將單次產生變成內部迭代循環。AI變成了自己的編輯。
我對任何品質比速度更重要的任務使用這種技術:著陸頁、重要信件、架構決策、創意作品。輸出品質的提升是顯著的。
詳略控制:掌握輸出長度
獲得正確的輸出長度是一個持續的挑戰。太短你會錯過重要細節。太長你會淹沒在不必要的資訊中。這是我的方法。
明確的長度指南
最可靠的方法是與任務複雜度相關的明確長度約束:
<output_verbosity_spec>
- 預設:典型答案3-6句話或≤5個要點。
- 對於簡單的「是/否+簡短解釋」問題:≤2句話。
- 對於複雜的多步驟或多檔案任務:
- 1個簡短的概述段落
- 然後≤5個要點標記為:改變了什麼,在哪裡,風險,下一步,
開放問題。
- 提供清晰和結構化的回應,在資訊量和
簡潔性之間取得平衡。
- 將資訊分解成易於消化的塊,在有幫助時使用
列表、段落和表格等格式。
- 避免長篇敘述段落;優先使用緊湊的要點和簡短部分。
- 除非改變語義,否則不要複述我的請求。
</output_verbosity_spec>基於人設的詳略
另一種方法是將AI的溝通風格定義為其人設的一部分:
<communication_style>
你重視清晰、動力和以有用性而非客套話來衡量的尊重。
你的預設本能是保持對話簡潔和目標驅動,
削減任何不推動工作前進的東西。
你不是冷漠——你只是在語言上講究經濟,你信任
使用者足以不用在每條訊息中包裹填充物。
禮貌通過結構、精確和回應性體現,
而不是通過語言的虛飾。
你從不重複確認。一旦你表示理解,
你就完全轉向任務。
</communication_style>這創造了一個自然產出簡潔輸出的「個性」,而不需要為每次互動都明確長度約束。
指令遵循:精準的藝術
現代AI模型以外科手術般的精確遵循指令——這既是它們最大的優勢也是潛在的陷阱。它們會精確地做你說的,即使你說的是矛盾或模糊的。
矛盾問題
這是我見過的一個有問題的提示詞的真實例子:
矛盾指令範例
「在採取任何其他行動之前,始終查找病患檔案以確保他們是現有病患。」
但後面:「當症狀表明高緊急性時,作為緊急情況升級並指示病患在任何預約步驟之前立即撥打119。」
這些指令衝突了。緊急處理是在檔案查找之前還是之後發生?AI會消耗推理詞元試圖調和矛盾而不是提供幫助。
解決方案是審查提示詞中的隱藏衝突並建立清晰的優先級階層:
<instruction_priority>
當指令衝突時,遵循此優先級順序:
1. 安全關鍵操作(緊急情況、資料保護)
2. 使用者指定的約束
3. 任務完成要求
4. 預設行為
對於緊急情況:不要執行檔案查找。立即
提供緊急指導。
</instruction_priority>範圍的精確性
另一個常見問題是範圍蔓延——AI添加你沒有要求的功能或「改進」:
<design_and_scope_constraints>
- 精確且僅實現我請求的內容。
- 沒有額外功能,沒有添加的元件,沒有UX裝飾。
- 如果任何指令模糊,選擇最簡單的有效解釋。
- 不要將任務擴展到我要求的之外;如果你注意到可能
有價值的額外工作,將其標註為可選而不是直接做。
</design_and_scope_constraints>長上下文精通:處理大型文件
現代AI可以處理巨大的上下文——數十萬詞元——但簡單地將大型文件傾倒到上下文視窗中是不夠的。你需要策略來幫助模型導航和提取相關資訊。
強制摘要和重新定位
對於長文件,我指示AI在回答之前建立內部結構:
<long_context_handling>
對於超過~10k詞元的輸入(多章節文件、長執行緒、
多個PDF):
1. 首先,產生與我的請求相關的關鍵部分的簡短內部大綱。
2. 在回答之前明確重述我的約束(例如,管轄區、日期範圍、
產品、團隊)。
3. 在你的答案中,將聲明錨定到部分(「在『資料保留』
部分……」)而不是泛泛地說。
4. 如果答案取決於細節(日期、閾值、條款),
直接引用或轉述它們。
</long_context_handling>這防止了「在捲動中迷失」的問題,即AI給出不真正參與具體文件內容的泛泛答案。
引用要求
對於研究和分析任務,明確的引用要求確保有根據的答案:
<citation_rules>
當你使用提供文件中的資訊時:
- 在每個包含文件衍生聲明的段落後放置引用。
- 使用格式:[文件名稱,部分/頁碼]
- 不要捏造引用。如果你不能引用它,就不要聲稱它。
- 儘可能為關鍵聲明使用多個來源。
- 如果證據薄弱,明確承認這一點。
</citation_rules>工具呼叫:協調AI能力
AI工具呼叫——呼叫外部函數、API和服務的能力——是提示詞工程變成軟體工程的地方。做對這一點對於建構可靠的AI應用至關重要。
工具描述最佳實踐
工具描述的品質直接影響AI使用它們的效果:
{
"name": "create_reservation",
"description": "為客人建立餐廳預訂。當使用者要求
用給定的名字和時間預訂桌位時使用。",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "預訂的客人全名。"
},
"datetime": {
"type": "string",
"description": "預訂日期和時間(ISO 8601格式)。"
}
},
"required": ["name", "datetime"]
}
}注意描述既包括工具做什麼也包括何時使用它。這幫助模型做出更好的工具選擇決策。
提示詞中的工具使用規則
除了工具定義之外,你的提示詞應該包括明確的使用指導:
<tool_usage_rules>
- 在以下情況下優先使用工具而非內部知識:
- 你需要新鮮或使用者特定的資料(工單、訂單、配置、日誌)。
- 你引用特定的ID、URL或文件標題。
- 儘可能並行化獨立的讀取(read_file, fetch_record, search_docs)
以減少延遲。
- 在任何寫入/更新工具呼叫後,簡要重述:
- 改變了什麼
- 在哪裡(ID或路徑)
- 執行的任何後續驗證
- 對於簡單的概念性問題,避免工具並依賴內部知識
以便回應快速。
</tool_usage_rules>並行化
一個關鍵優化是在操作獨立時鼓勵並行工具呼叫:
<parallelization>
儘可能並行化工具呼叫。批量處理讀取(read_file)和
獨立編輯(apply_patch到不同檔案)以加快過程。
可以並行化的獨立操作:
- 讀取多個檔案
- 搜尋多個目錄
- 獲取多條記錄
不能並行化的依賴操作:
- 讀取檔案,然後基於內容編輯
- 建立資源,然後引用其ID
</parallelization>處理不確定性:當AI不知道的時候
AI的最大風險之一是聽起來自信的錯誤答案。模型不知道它不知道什麼——除非你教它如何處理不確定性。
<uncertainty_and_ambiguity>
- 如果問題模糊或規格不足,明確指出這一點並:
- 提出最多1-3個精確的澄清問題,或
- 呈現2-3個可能的解釋,帶有明確標記的假設。
- 當外部事實可能最近發生變化(價格、發布、政策)
且沒有工具可用時:
- 用一般術語回答並說明細節可能已經改變。
- 當你不確定時,永遠不要捏造精確數字、行號或外部引用。
- 當你不確定時,優先使用像「根據提供的上下文……」
這樣的語言而不是絕對聲明。
</uncertainty_and_ambiguity>高風險自檢
對於高風險領域,我添加一個明確的自我驗證步驟:
<high_risk_self_check>
在法律、金融、合規或安全敏感上下文中
完成答案之前:
- 簡要重新掃描你自己的答案以檢查:
- 未聲明的假設
- 沒有在上下文中有根據的特定數字或聲明
- 過於強烈的語言(「總是」、「保證」等)
- 如果你發現任何問題,軟化或限定它們並明確說明假設。
</high_risk_self_check>目標不是讓AI不那麼自信——而是讓它準確地自信。對不確定的事情表示不確定是一個特性,而不是缺陷。
元提示詞:用AI改進AI
這是我工具箱中最元的技術:用AI來改進你的提示詞。這聽起來循環,但非常有效。
診斷提示詞失敗
當提示詞不起作用時,我使用這個模式來診斷問題:
你是一個負責偵錯系統提示詞的提示詞工程師。
給你以下內容:
1) 當前系統提示詞:
<system_prompt>
[在這裡貼上你的提示詞]
</system_prompt>
2) 一小組記錄的失敗。每條日誌有:
- 查詢
- 實際輸出
- 期望輸出(或問題描述)
<failure_traces>
[貼上失敗範例]
</failure_traces>
你的任務:
1) 識別你看到的不同失敗模式。
2) 對於每個失敗模式,引用系統提示詞中最可能
導致或強化它的具體行。
3) 解釋這些行如何將智慧代理導向觀察到的行為。
以結構化格式返回你的答案:
failure_modes:
- name: ...
description: ...
prompt_drivers:
- exact_or_paraphrased_line: ...
- why_it_matters: ...產生提示詞改進
一旦你有了診斷,第二個提示詞產生改進:
你之前分析了這個系統提示詞及其失敗模式。
系統提示詞:
<system_prompt>
[原始提示詞]
</system_prompt>
失敗模式分析:
[貼上上一步的診斷]
請提出一個外科手術式的修訂,減少觀察到的問題同時
保留好的行為。
約束:
- 不要從頭重新設計智慧代理。
- 優先小的、明確的編輯:澄清衝突的規則,刪除冗餘
或矛盾的行,收緊模糊的指導。
- 明確權衡。
- 保持結構和長度與原始大致相似。
輸出:
1) patch_notes:關鍵更改和每個更改背後的推理的簡明列表。
2) revised_system_prompt:應用編輯後的完整更新提示詞。這個兩步過程幫助我修復了我糾結了幾天的提示詞。AI經常發現我已經看不見的矛盾和歧義。
久經考驗的提示詞範本
讓我分享一些在數百個用例中證明可靠的範本。
通用任務完成範本
<context>
[AI需要理解情況的背景資訊]
</context>
<task>
[你想完成什麼的清晰陳述]
</task>
<requirements>
[具體要求或約束]
</requirements>
<format>
[你希望輸出如何組織]
</format>
<examples>
[可選:期望輸出的範例]
</examples>
<notes>
[可選:額外的上下文或偏好]
</notes>程式碼審查範本
<context>
你正在為[專案/上下文]審查程式碼。
程式碼庫使用[技術/模式]。
</context>
<code_to_review>
[在這裡貼上程式碼]
</code_to_review>
<review_criteria>
關注:
1. 正確性:它做了它聲稱的嗎?
2. 可讀性:對其他開發者清晰嗎?
3. 效能:有明顯的低效嗎?
4. 安全性:有漏洞嗎?
5. 風格:它匹配程式碼庫慣例嗎?
</review_criteria>
<output_format>
對於發現的每個問題:
- 嚴重性:[關鍵/重大/次要/建議]
- 位置:[行號或部分]
- 問題:[什麼問題]
- 修復:[如何解決它]
</output_format>研究分析範本
<research_task>
用以下方法分析[主題/問題]:
</research_task>
<methodology>
1. 從多個有針對性的搜尋開始。不要依賴單一查詢。
2. 深入研究直到你有足夠的資訊來給出準確、
全面的答案。
3. 添加有針對性的後續搜尋以填補空白或解決分歧。
4. 持續迭代直到額外搜尋不太可能改變答案。
</methodology>
<output_requirements>
- 以對主要問題的清晰答案開頭。
- 用證據和引用支持。
- 承認侷限性和不確定性。
- 在有幫助的地方提供具體例子。
- 包括幫助理解含義的相關上下文。
</output_requirements>
<citation_format>
[你希望來源如何被引用]
</citation_format>毀掉結果的常見錯誤
讓我幫你避免我在提示詞工程早期(反覆)犯的錯誤。
「幫我寫點關於行銷的東西」 vs 「寫一篇500字的關於SaaS新創公司電子郵件行銷的部落格文章,重點是歡迎序列。」 具體性就是一切。
在同一個提示詞中說「要簡潔」和「要詳盡」。AI會努力調和矛盾。明確優先級和權衡。
AI不知道你沒告訴它的東西。如果某些東西對你來說是顯而易見的,對模型來說可能不是。包括相關背景。
如果你需要JSON,就說出來。如果你需要項目符號,就說出來。不要把輸出格式留給機會。
有時簡單的提示詞是最好的。不要為了複雜而增加複雜性。從簡單開始,只在需要時增加複雜性。
寫提示詞是迭代的。你的第一個提示詞是草稿。根據什麼有效什麼無效來細化。
GPT和Claude行為不同。為一個優化的提示詞可能在另一個上表現不佳。如果你的應用支援多個模型,在多個模型上測試。
AI輸出通常需要人工審查。建構使審查容易的提示詞——清晰的結構、明確的假設、可追蹤的推理。
提示詞工程的未來
在我寫這篇文章的2026年初,提示詞工程正在快速發展。模型變得更有能力、更可控、更可靠。有些人預測隨著AI更好地理解意圖,提示詞工程將變得過時。我不同意。
正在改變的是提示詞工程的層次,而不是它的必要性。早期需要精心製作的提示詞來完成基本任務。現在,基本任務開箱即用,但複雜的智慧代理工作流程仍然需要複雜的提示詞。門檻在提高,而不是消失。
提示詞工程不會消失——它在進化。重要的技能正在從「如何讓AI工作」轉變為「如何讓AI在規模上卓越且可靠地工作」。
即將到來的變化
更好的預設行為
模型將有更智慧的預設值,對常見模式需要更少的明確指令。提示詞將更多關注客製化而非基本能力。
更豐富的工具生態
AI將開箱即用地存取更多工具。提示詞工程將轉向編排——知道何時用什麼,而不只是怎麼用。
多模態整合
提示詞將越來越多地涉及圖像、音訊、影片和結構化資料以及文字。新的提示詞模式將為多模態任務出現。
智慧代理複雜性
隨著智慧代理處理更長、更複雜的任務,提示詞工程將變得更像系統設計——架構,而不只是指令。
我對未來的建議
關注基礎。本指南中的具體技術會演變,但底層原則——清晰的溝通、明確的期望、結構化的思考、迭代的細化——是永恆的。掌握這些,你將適應接下來發生的任何事情。
最後的思考
兩年前,我以為AI會取代清晰溝通的需要。我完全錯了。AI使清晰溝通比以往任何時候都更有價值。與AI共事蓬勃發展的人不是那些找到魔法詞語的人——他們是那些學會精確思考和表達自己的人。
提示詞工程實際上不是關於AI。它是關於你。它是關於培養清晰表達你真正想要什麼的紀律,迭代接近它的耐心,以及從不起作用的東西中學習的謙遜。
如果你從本指南中只帶走一件事,讓它是這個:把每個提示詞當作練習清晰思考的機會。AI只是一面鏡子,反射回你自己思維的清晰——或混亂。
AI的出現並沒有讓知識過時——它讓好奇心比以往任何時候都更強大。我們不再受限於我們已經知道的東西。有了正確的工具和思考的意願,普通人可以擁抱知識的海洋。無論職業。無論年齡。我希望與世界各地的朋友分享這段旅程。讓我們一起迎接這個新世界。讓我們一起成長。


討論
0 條評論留下評論
成為第一個分享您想法的人!