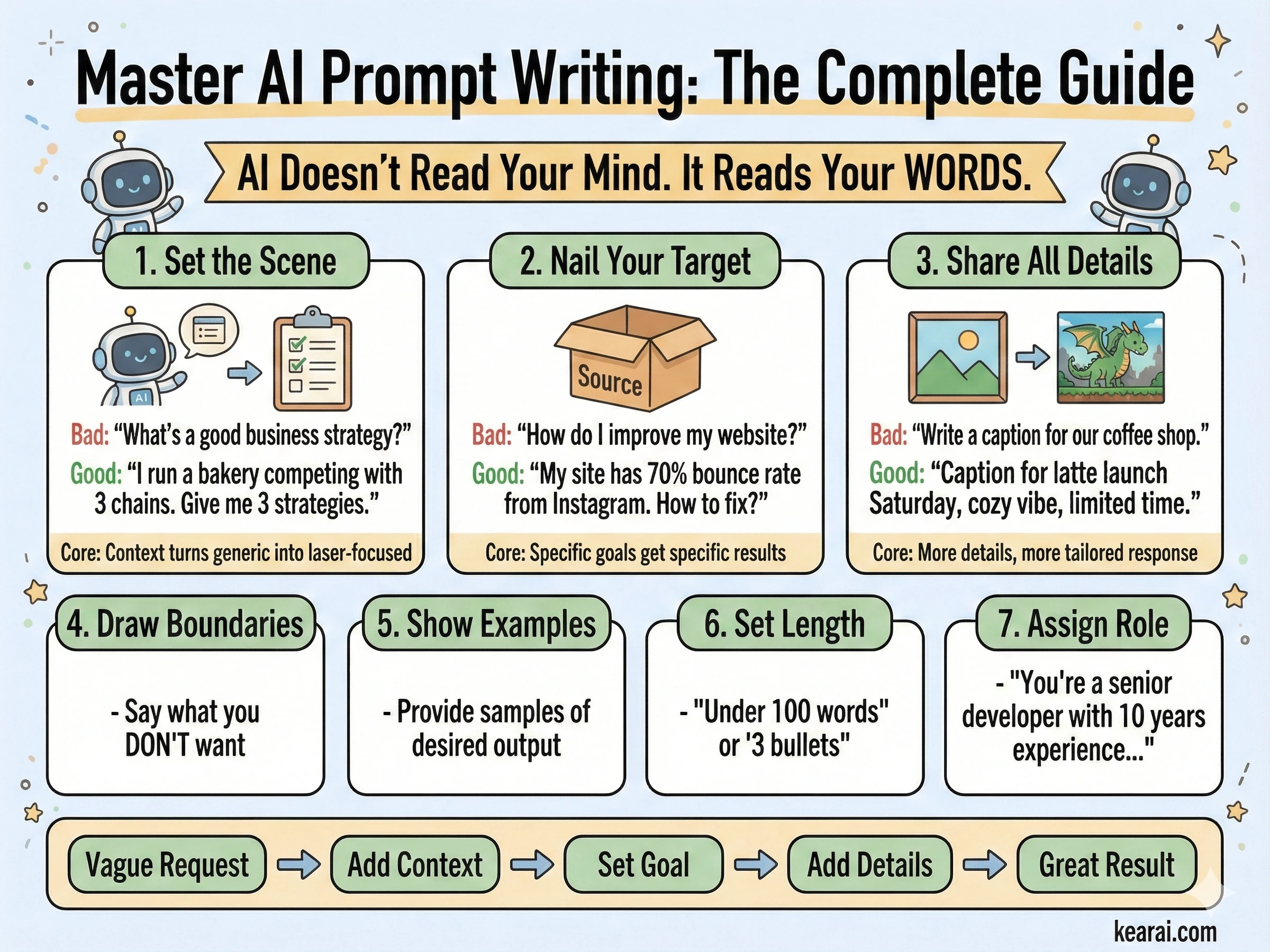
令人抓狂的AI圖像與令人驚嘆的傑作之間的區別,不在於天賦或運氣 —— 而在於學會說機器能聽懂的視覺語言。
我還記得一切改變的那一刻。那是週二凌晨2點。我盯著螢幕看了好幾個小時,不斷嘗試一個又一個提示詞,看著ChatGPT吐出的圖像與我設想的完全不符。手指的解剖結構不可能存在。文字融化成亂碼。角色似乎在主動抗拒我的意圖。我已經準備放棄AI圖像生成了 —— 把它歸結為過度的炒作,只對別人有效。
然後我嘗試了一些不同的東西。我不再描述我想看到什麼,而是描述攝影機能捕捉到什麼。我沒有要求「美麗的日落」,而是寫了「黃金時刻的光線穿過山峰,佳能5D Mark IV拍攝,24-70mm鏡頭,光圈f/2.8,自然色調」。出現的圖像不僅僅是可以接受 —— 它是驚豔的。照片級真實。正是幾分鐘前只存在於我想像中的東西。
視角的這一轉變開啟了一切。在接下來的幾個月裡,我深入研究。我生成了數千張圖像。我測試了能找到的每一種技巧。我通讀了OpenAI的文檔。我在GPT Image 1.5發布當天就進行了實驗。現在我要分享我學到的一切 —— 不是你在其他地方能找到的膚淺技巧,而是區分專業人士與業餘愛好者的深層知識。這是我希望在開始時就擁有的指南。這就是你如何從受挫的初學者變成自信的創作者。
我的AI圖像生成之旅
讓我帶你回到一切開始的地方。像你們許多人一樣,我最初對AI圖像生成持懷疑態度。「這只是技術愛好者的玩具,」我想。「真正的創造性工作仍然需要真正的技能。」我大錯特錯。
我對AI圖像的第一個真正需求來自一個實際問題。我正在為一個項目創建內容,需要封面圖片 —— 很多圖片。我一直在為圖庫照片付費,把錢花在其他創作者都在使用的通用照片上。這些圖片還可以,但缺乏靈魂。它們感覺是借來的,而不是擁有的。
一位朋友提到ChatGPT現在可以生成圖像了。「只要描述你想要的,」她說。「就像魔法一樣。」所以我試了一下。我的第一個提示詞幼稚得令人尷尬:「群山之上的美麗日落。」結果呢?一團模糊的亂碼,就像一幅被雨淋過的水彩畫。至少可以說,我很失望。
但有些東西一直吸引著我回去。我再次嘗試。再一次。每一次失敗都教會了我一些關於AI如何理解語言的新東西。我開始注意到模式 —— 某些短語始終能產生更好的結果,結構化的方法能引導模型接近我的願景,而不是遠離它。
突破來自於我意識到:AI圖像生成不是描述你腦海中看到的東西 —— 而是描述攝影機在現實中會捕捉到的東西。這單一視角的轉變改變了一切。
我不再像夢想家那樣思考,而是開始像攝影師一樣思考。我不再寫「美麗的日落」,而是寫關於黃金時刻的光線、具體的相機型號、鏡頭焦距、光圈設置、膠片類型。AI理解這種語言,因為它是在數百萬張帶有這種技術元數據的圖像上訓練出來的。
在接下來的幾個月裡,我著迷了。我生成了涵蓋我能想像到的每種風格和用例的數千張圖像。我閱讀了OpenAI發布的每一份文檔。我加入了推動這些工具極限的創作者社區。當GPT Image 1.5在2026年1月發布時,我已經準備好了。我不僅理解了如何使用它,還理解了它為什麼以這種方式工作。
現在我要分享我學到的一切。不是你在一百本其他指南中能找到的膚淺技巧。而是來自廣泛實驗、系統測試以及與將這些工具推向極限的其他創作者無數次對話的深層知識。這是完整的指南 —— 將帶你從困惑的初學者變成自信的創作者。
什麼是ChatGPT圖像生成器
在深入探討技巧之前,讓我澄清一下我們使用的是什麼。ChatGPT圖像生成器是OpenAI集成的圖像創建和編輯系統,目前由他們的GPT Image 1.5模型提供支持。與Midjourney或Stable Diffusion等獨立工具不同,它深度集成到了ChatGPT的對話界面中。
這種集成比你想像的更重要。因為ChatGPT理解上下文,它可以在多次生成中保持一致性,記住你在會話中的偏好,甚至推理你試圖創建的內容。告訴它你正在創作一本兒童讀物,它會相應地調整風格。提到你需要用於企業演示的圖片,它會轉向乾淨、專業的審美。這種上下文意識是獨立圖像生成器根本無法比擬的。
🎨 文生圖 (Text-to-Image)
用自然語言描述任何東西,看著它具象化。從照片級真實的人像到抽象藝術,從產品模型到奇幻風景 —— 只要你能描述,AI就能創造。
✏️ 精準圖像編輯
上傳現有圖片並用文字命令修改它們。改變顏色、交換物體、調整光照、轉換季節,或者在保留你想要的元素的同時完全重新構想場景。
🔄 風格遷移
提取一張圖片的視覺語言 —— 它的調色板、紋理、筆觸或審美 —— 並將其應用到全新的內容上。非常適合保持品牌一致性或創建連貫的系列。
📝 可靠的文本渲染
終於,AI真的能拼寫了。GPT Image 1.5在圖像中處理文本的準確性前所未有 —— 非常適合標誌、海報、信息圖表和文字至關重要的營銷材料。
它實際上是如何工作的
當你向ChatGPT的圖像生成器發送提示詞時,幕後會發生幾件事。首先,ChatGPT本身會處理你的請求,可能會根據上下文擴展或澄清你的提示詞。它可能會添加你暗示但未說明的細節,或者以圖像模型更能理解的方式構建你的請求。
然後請求進入圖像生成模型 —— 目前是GPT Image 1.5 —— 它將你的文本描述轉化為視覺輸出。這個模型是在海量圖像及其詳細描述的數據集上訓練的,學習了語言和視覺元素之間錯綜複雜的關係。
結果是一個真正理解你在要求什麼的系統,而不僅僅是匹配關鍵詞。要求「照片級真實的抓拍瞬間」,你會得到真正感覺未擺拍的東西。要求「透過百葉窗的晨光」,你會得到它產生的特定條紋圖案。
GPT Image 1.5在Artificial Analysis Image Arena的文生圖生成和圖像編輯方面均獲得了第一名,指令依從率達到90% —— 比最接近的競爭對手高出13個百分點。這不是營銷辭令;這反映了能力的真正飛躍。
GPT Image 1.5 的革命
當OpenAI在2026年1月發布GPT Image 1.5時,他們不僅僅是迭代了之前的模型 —— 他們重建了基礎。我曾廣泛使用早期版本,所以我立即注意到了差異。這不僅僅是增量改進;這是一次範式轉變。
讓我具體談談發生了什麼變化,因為理解這些改進將幫助你有效地利用它們。
三個重要的突破
以前的模型有一種令人沮喪的漂移傾向。你要求改變一件事,其他三件事會意外地發生變化。修復光線,角色的臉突然看起來不一樣了。GPT Image 1.5真正理解「只改變這個元素」 —— 它可以修改特定部分,同時保留光線、構圖、面部特徵,甚至微妙的紋理。這使得迭代優化真正實用。
生成速度比以前的版本提高了400%。過去需要30秒,現在只需7-8秒。但更重要的是,你可以在當前任務仍在處理時排隊新的生成。這將創作過程從「提交並等待」轉變為「探索和迭代」。心理差異是巨大的 —— 更快的反饋循環意味著更多的實驗。
AI圖像中的文本渲染歷來是一場災難 —— 拼寫錯誤、重複、字母融化成抽象形狀。GPT Image 1.5在保持適當的排版、布局和可讀性的同時處理密集的、小字體的文本。這開啟了信息圖表、營銷材料、UI模型以及任何文字出現在圖像中的用例。我有生以來第一次可以生成演示幻燈片、帶標題的社交媒體圖片和我真正會使用的產品標籤。
理解質量設置
GPT Image 1.5提供不同的質量層級,了解何時使用哪種層級將為你節省時間並改善結果。這不僅僅關於輸出質量 —— 更是關於為任務匹配合適的工具。
⚡ 低質量模式 (Low Quality)
不要被名字誤導 —— 這裡的「低質量」意味著「快速高效」。對於大多數用例,結果仍然非常好。將此用於:
- 初步概念探索和頭腦風暴
- 完善想法時的快速迭代
- 沒有精細細節的簡單構圖
- 速度至關重要的大批量生成
- 在致力於最終版本之前的草稿
✨ 高質量模式 (High Quality)
當每個像素都很重要,且你需要出版級的結果時。保留用於:
- 用於交付的最終生產圖像
- 密集的文本和排版工作
- 帶有微小細節的複雜信息圖表
- 紋理至關重要的照片級人像
- 任何你需要最大保真度的圖像
隱藏的輸入保真度設置
這是大多數指南不會告訴你的:在編輯圖像時,有一個名為 input_fidelity 的參數會極大地影響結果。當你需要保留面部特徵、在編輯中保持身份一致或進行重大場景更改時,將其設置為「high」(高)。模型會更加努力地保持原始圖像的關鍵特徵。
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # 身份保留的秘訣
quality="high",
image=[open("portrait.png", "rb")],
prompt="Change the background to a sunset beach while preserving the person's exact appearance"
)這種組合確保在應用你請求的更改時最大程度地保留原始主體。
GPT Image 1.5最大的轉變不是技術上的 —— 而是哲學上的。圖像生成從「提示並祈禱」轉變為「指令並迭代」。這需要一個完全不同的思維模型來處理視覺創作。
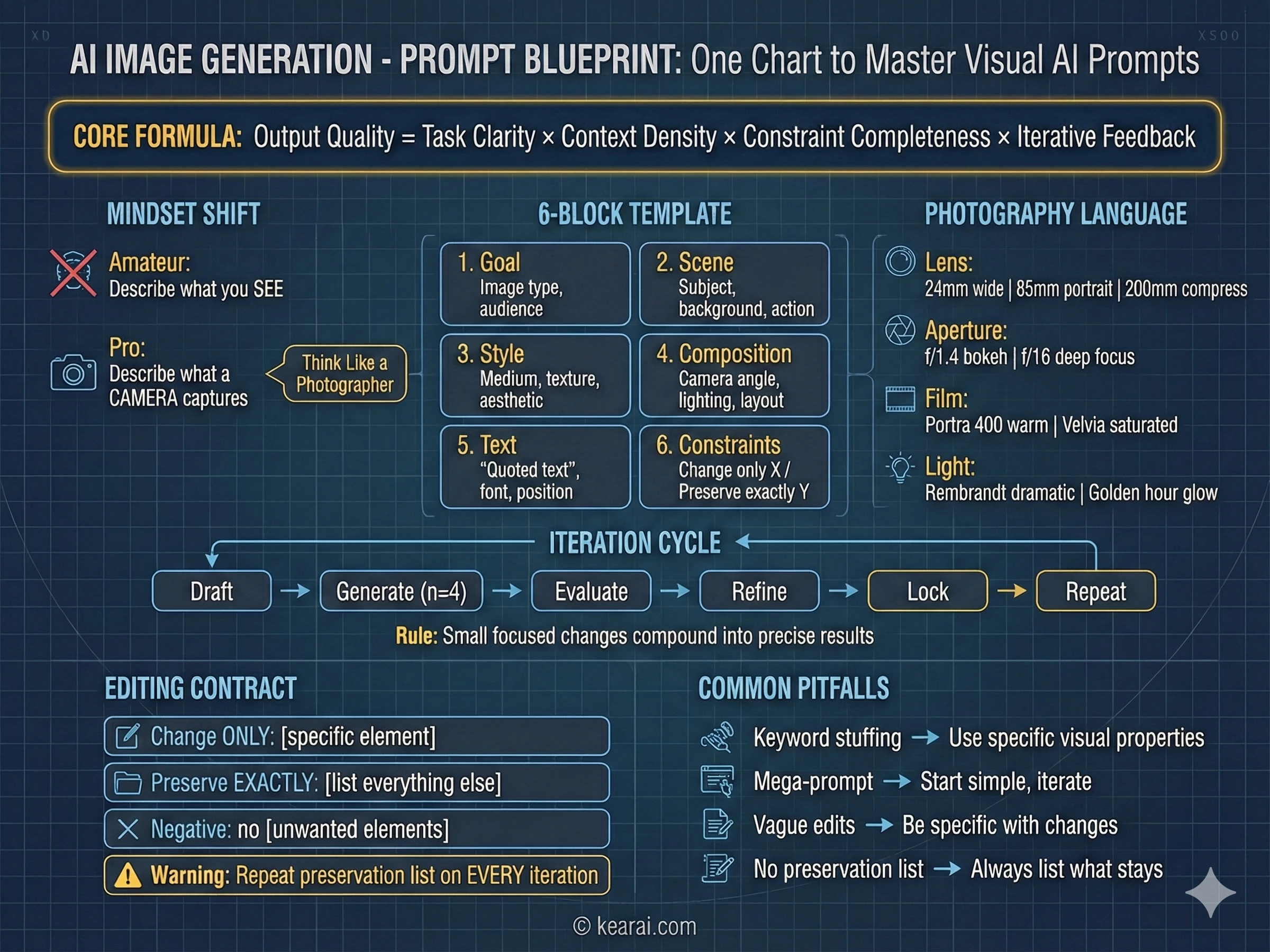
改變一切的提示詞框架
在生成了數千張圖像後,我開發了一個始終能產生出色結果的框架。忘掉你讀過的關於在提示詞中添加「傑作 (masterpiece)、ArtStation趨勢 (trending on ArtStation)、超細節 (ultra-detailed)、8K解析度」的一切。這些關鍵詞對需要質量提示的舊模型有用,但GPT Image 1.5響應的是結構和特異性,而不是關鍵詞堆砌。
我稱之為結構化提示詞架構,我現在寫的每一個有效提示詞都遵循這種模式。
Goal/Output (目標/輸出):
- [Type of image: ad, UI mockup, infographic, photo, illustration] (圖像類型:廣告、UI模型、信息圖、照片、插圖)
- [Intended use and audience] (預期用途和受眾)
Scene (場景):
- [Background/environment description] (背景/環境描述)
- [Main subject with specific details] (主體及具體細節)
- [Action or relationship between elements] (動作或元素間的關係)
Style (風格):
- [Medium: photograph, watercolor, 3D render, vector illustration] (媒介:照片、水彩、3D渲染、矢量插圖)
- [Key textures: matte, glossy, grainy, smooth, organic] (關鍵紋理:啞光、光澤、顆粒感、平滑、有機)
- [Quality descriptors: realistic imperfections, stylized, minimalist] (質量描述:逼真的瑕疵、風格化、極簡主義)
Composition/Layout (構圖/布局):
- [Camera position: close-up, wide shot, aerial view, eye-level] (相機位置:特寫、廣角、鳥瞰、平視)
- [Lighting: golden hour, studio strobes, overcast, dramatic shadows] (光照:黃金時刻、攝影棚閃光燈、陰天、戲劇性陰影)
- [Element placement: centered, rule of thirds, negative space, margins] (元素放置:居中、三分法、留白、邊距)
Text (if any) (文本,如果有):
- "Exact text in quotes" ("引號中的確切文本")
- [Font style, size, color, position] (字體風格、大小、顏色、位置)
- [Specify: render only once, no duplicates] (指定:僅渲染一次,無重複)
Constraints (約束):
- Change ONLY: [specific element if editing] (僅更改:[特定元素,如果是編輯])
- Preserve exactly: [elements that must stay unchanged] (完全保留:[必須保持不變的元素])
- Negative: no watermark, no extra text, no logos, no [unwanted elements] (負向:無水印、無額外文本、無Logo、無[不需要的元素])這個框架為模型提供了它需要做出的每一個視覺決策的清晰上下文。
有效提示的七個原則
除了結構之外,這些原則支配著我寫的每一個提示詞。它們是「基本能用」的圖像和「精準命中」你願景的圖像之間的區別。
結構勝於關鍵詞
使用一致的順序:背景 → 主體 → 細節 → 約束。對於複雜的請求,使用帶標籤的段落或換行。長段落會使模型困惑;有組織的結構引導它走向你的意圖。
特異性勝於最高級
不要用「高質量」或「超細節」,描述實際的視覺屬性。材料、紋理、形狀、媒介。「可見的皮膚毛孔和微妙的雀斑」每次都勝過「高度細節化的臉」。
明確的構圖控制
命名你的取景(特寫、廣角、鳥瞰)、視角(平視、低角度、荷蘭式傾斜)和光照氛圍(柔和漫射、黃金時刻、高對比度輪廓光)。不要把這些留給運氣。
更改 vs 保留契約
對於編輯,明確說明什麼應該改變以及什麼應該保持不動。使用「change only X」(僅改變X)和「preserve exactly Y」(完全保留Y)。在每次迭代中重複此保留列表以防止漂移。
文本需要精確
將所需的文本放在「引號」或全大寫中。指定字體風格、大小、顏色和位置。對於困難的單詞或品牌名稱,逐個字母拼寫出來。總是添加「render exactly once, no duplicates」(完全渲染一次,無重複)。
多圖參考清晰度
當使用多張輸入圖像時,通過索引和描述引用每一張:「Image 1: the product shot, Image 2: the style reference」(圖像1:產品圖,圖像2:風格參考)。明確說明它們應該如何交互。
迭代而非過載
從一個乾淨的基礎提示詞開始,然後通過小的、單一更改的後續操作進行完善。「讓光線更暖。」「移除背景樹木。」小步驟匯聚成精準的結果。
最常見的錯誤
我看到人們犯的最大的錯誤:試圖在一個巨大的提示詞中指定所有內容,希望模型能弄明白。這幾乎從不奏效。從一個更簡單的提示詞開始建立基礎,然後通過有針對性的細化進行迭代。你會在更短的時間內獲得更好的結果,而且失敗的挫敗感會少得多。
攝影師思維
我結果中最大的單一改進來自於思維的轉變:我不再像藝術家那樣描述願景,而是開始像攝影師一樣描述鏡頭。這不僅僅是一個比喻 —— 這是一個利用模型訓練方式的實用技巧。
AI圖像模型是從數百萬張帶有元數據的照片中學習的:相機型號、鏡頭規格、光圈設置、光照條件。當你使用這種語言時,你激活了模型對真實相機如何捕捉真實場景的深刻理解。
有效的攝影語言
- 鏡頭選擇: "24mm wide angle"(24mm廣角)創造邊緣有畸變的廣闊場景;"200mm telephoto"(200mm長焦)壓縮深度並隔離主體。
- 光圈感: "f/1.4 bokeh"(f/1.4散景)為人像提供奶油般的背景模糊;"f/16 deep focus"(f/16深景深)保持風景中的一切清晰。
- 膠片類型: "Kodak Portra 400"用於溫暖、討喜的膚色;"Fuji Velvia"用於有力、飽和的風景;"Ilford HP5"用於高對比度的黑白。
- 布光設置: "Rembrandt lighting"(倫勃朗光)用於戲劇性人像;"butterfly lighting"(蝴蝶光)用於美妝照;"golden hour backlight"(黃金時刻逆光)用於空靈的發光邊緣。
- 相機運動: "long exposure motion blur"(長曝光動態模糊)用於動態能量;"high-speed freeze frame"(高速定格)用於捕捉動作。
與其說「讓它看起來專業」,不如試著說「shot on Hasselblad medium format, studio strobe lighting, seamless gray backdrop, color-calibrated for print reproduction」(哈蘇中畫幅拍攝,影棚閃光燈照明,無縫灰色背景,為印刷複製進行色彩校準)。與其說「逼真的人像」,不如試著說「candid photograph, 85mm f/1.4 lens, window light from camera left, subtle fill from reflector, visible skin texture with pores, shot on Sony A7R IV」(抓拍照片,85mm f/1.4鏡頭,相機左側窗光,反光板微妙補光,可見帶毛孔的皮膚紋理,索尼A7R IV拍攝)。
❌ BEFORE (模糊):
"A beautiful portrait of an old fisherman, very detailed, high quality, realistic"
(一個老漁夫的美麗肖像,非常詳細,高質量,逼真)
✅ AFTER (攝影師思維):
"Candid documentary photograph of an elderly fisherman on a weathered wooden boat.
Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind eyes.
Gray stubble. Faded traditional anchor tattoo on forearm. Salt-stained navy wool
sweater, worn cap.
Early morning coastal light, soft fog diffusing the sun. Medium close-up at eye
level, 50mm lens, f/2.8, shallow depth of field. Shot like 35mm film with subtle
grain, natural color balance.
Documentary style — honest, unretouched, capturing a real moment. No glamorization."
(飽經風霜的木船上的老漁夫的紀實抓拍。飽經風霜的臉,可見皺紋、曬斑和毛孔。深陷的慈祥眼睛。灰色鬍渣。前臂上褪色的傳統錨紋身。鹽漬的海軍藍羊毛衫,磨損的帽子。
清晨的海岸光線,柔和的霧氣漫射著陽光。視線水平的中特寫,50mm鏡頭,f/2.8,淺景深。像35mm膠片一樣拍攝,有微妙的顆粒感,自然色彩平衡。
紀實風格 —— 誠實,未修飾,捕捉真實瞬間。沒有美化。)攝影師思維將模糊的願望轉化為模型能夠深度解碼的精確視覺規格。
當你使用攝影語言描述圖像時,你不僅更具體 —— 你還在說一種模型被訓練來理解的語言。相機規格、布光設置和膠片類型不是隨意的關鍵詞;它們編碼了模型可以準確解碼的精確視覺信息。
文生圖精通
從純文本描述創建圖像是大多數人開始AI圖像之旅的地方。這也是業餘愛好者和專業結果之間差距最明顯的地方。讓我帶你了解在不同用例中始終產生出色結果的技巧。
感覺自然的逼真圖像
照片級真實感的關鍵是反直覺的:你需要提示瑕疵。完美的皮膚、完美的光線、完美的構圖 —— 這些都在尖叫「AI生成的」。現實更混亂,而這種混亂正是讓圖像感覺真實的原因。
Create a photorealistic candid photograph of an elderly sailor standing on a small fishing boat.
(創建一張老水手站在小漁船上的照片級真實抓拍。)
Subject: Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind
eyes with crow's feet. Gray stubble, a few days unshaven. Faded traditional anchor
tattoo on forearm. Salt-stained navy wool sweater, worn and pilled. Creased cap
with faded insignia.
(主體:飽經風霜的臉,可見皺紋、曬斑和毛孔。深陷的慈祥眼睛,有魚尾紋。灰色鬍渣,幾天沒刮。前臂上褪色的傳統錨紋身。鹽漬的海軍藍羊毛衫,磨損起球。折痕帽子,褪色徽章。)
Setting: Early morning on the water, soft coastal fog diffusing the light. Aged
wooden boat deck with peeling paint, fishing nets in background, coiled rope.
(環境:清晨的水面,柔和的海岸霧氣漫射著光線。陳舊的木船甲板,油漆剝落,背景中有漁網,盤繞的繩索。)
Technical: Shot like 35mm film photography, medium close-up at eye level, 50mm
lens, shallow depth of field with boat blurred behind him. Subtle film grain,
natural color balance without heavy grading.
(技術:像35mm膠片攝影一樣拍攝,視線水平的中特寫,50mm鏡頭,淺景深,身後船隻模糊。微妙的膠片顆粒,自然色彩平衡,無重度調色。)
The image should feel like a real moment captured by a photojournalist — honest,
unposed, with real skin texture, worn materials, and everyday imperfection. No
glamorization, no heavy retouching, no artificial perfection.
(圖像應該感覺像是攝影記者捕捉到的真實瞬間 —— 誠實、未擺拍,有真實的皮膚紋理、磨損的材料和日常的瑕疵。沒有美化,沒有重度修飾,沒有人工完美。)注意我們要如何明確要求瑕疵 —— 飽經風霜的皮膚、磨損的材料、剝落的油漆。現實是有紋理的。
信息圖表和數據可視化
GPT Image 1.5改進的文本渲染使信息圖表成為真正實用的用例。我現在創建專業質量的信息圖表,並實際用於我的工作中。
Create a detailed infographic explaining how a coffee machine works.
(創建一個詳細的信息圖,解釋咖啡機是如何工作的。)
Structure (結構):
- Title at top: "The Journey of Your Morning Coffee" (頂部標題:"你晨間咖啡的旅程")
- Vertical flow diagram showing: bean hopper → grinder → portafilter →
grouphead → water heating → extraction → cup
(垂直流程圖顯示:豆倉 → 研磨機 → 手柄 → 沖煮頭 → 水加熱 → 萃取 → 杯子)
- Each step has an icon and 1-2 sentence explanation (每一步都有一個圖標和1-2句話的解釋)
- Warm color palette (browns, creams, copper accents) (暖色調:棕色、奶油色、銅色點綴)
- Clean, modern design with plenty of white space (乾淨、現代的設計,大量留白)
- Subtle coffee stain texture in background corners (背景角落有微妙的咖啡漬紋理)
Style (風格): Professional print-quality infographic, vector-style icons, clear
hierarchy, readable at A4 size. (專業印刷質量信息圖,矢量風格圖標,清晰層級,A4尺寸可讀。)
Typography (排版): Clean sans-serif headings, readable body text, clear visual
hierarchy between title, section headers, and explanatory text. (乾淨的無襯線標題,可讀的正文,標題、章節頭和解釋性文本之間有清晰的視覺層級。)
No watermarks. No stock photo elements. Original illustration only. (無水印。無圖庫照片元素。僅原創插圖。)對於密集的文本和複雜的布局,始終使用 quality="high" 以確保文本保持清晰可讀。
Logo和品牌設計
Logo生成需要優先考慮簡潔性和可擴展性。一個好的Logo在任何尺寸下都有效,從微小的網站圖標到巨大的廣告牌。這是如何提示實際上能作為Logo使用的設計。
Create an original logo for "Field & Flour" — a local artisan bakery.
(為"Field & Flour" —— 一家當地手工麵包店創建一個原創Logo。)
Brand personality: Warm, authentic, handcrafted, timeless. Not trendy or corporate.
(品牌個性:溫暖、真實、手工製作、永恆。不追逐潮流或企業化。)
Design requirements (設計要求):
- Clean vector-style shapes with strong silhouette (乾淨的矢量風格形狀,輪廓強)
- Balanced negative space (平衡的負空間)
- Must read clearly from 16px favicon to large signage (從16px網站圖標到大型標牌都必須清晰可讀)
- Flat design, minimal strokes, no gradients unless essential (扁平化設計,極簡線條,除非必要否則無漸變)
- Earth-tone palette: warm wheat gold, deep brown, cream (大地色調:暖麥金、深棕、奶油色)
- Could incorporate subtle wheat or grain element (可以融入微妙的小麥或穀物元素)
- Text must be perfectly legible and properly kerned (文本必須完全清晰且字距適當)
Output: Single centered logo on plain cream background. Generous padding around
the design for flexibility. (輸出:純奶油色背景上的單個居中Logo。設計周圍有寬敞的留白以增加靈活性。)
No watermarks, no mockups, no 3D effects, no complex imagery. Simple, functional,
timeless design. (無水印,無樣機,無3D效果,無複雜圖像。簡單、實用、永恆的設計。)使用 n=4 生成多個變體。Logo設計是主觀的 —— 給自己多種選擇。
UI和App模型
對於UI設計,描述介面就像它已經存在並正發貨給真實用戶一樣。概念藝術語言產生概念藝術。產品語言產生可用的模型。
Create a realistic mobile app UI mockup for a local farmers market app.
(為一個當地農貿市場App創建一個逼真的移動App UI模型。)
Screen content (from top) (屏幕內容(從上到下)):
- Simple header with market name "Riverside Market" and search icon (簡單的頭部,帶有市場名稱"Riverside Market"和搜索圖標)
- Today's featured vendor carousel with square photos (今日精選商家輪播,帶方形照片)
- "Fresh Today" section with produce category chips (Vegetables, Fruits, Dairy, Baked) ("今日新鮮"部分,帶農產品類別標籤(蔬菜、水果、乳製品、烘焙))
- Vendor list with small photos, names, specialties, and distance (商家列表,帶小照片、名稱、特色和距離)
- Bottom navigation: Home, Map, Favorites, Cart, Profile (底部導航:首頁、地圖、收藏、購物車、個人資料)
Design language (設計語言):
- White background, subtle natural green accents (白色背景,微妙的自然綠色點綴)
- Clear typography hierarchy (system fonts feel) (清晰的排版層級(系統字體感覺))
- Generous padding and touch-friendly targets (寬敞的填充和觸摸友好的目標)
- Looks like a real shipped product, not a concept (看起來像真正的已發布產品,而不是概念)
- Uses realistic vendor names and produce photos (使用真實的商家名稱和農產品照片)
Frame: Place the UI inside an iPhone 15 Pro device frame, slight perspective
tilt, subtle shadow beneath. (框架:將UI放置在iPhone 15 Pro設備框架內,輕微透視傾斜,下方有微妙陰影。)專注於布局、層級、間距和逼真的介面元素。避免概念性或藝術性的語言。
連環畫和順序藝術
創作多格漫畫需要將敘事定義為一系列清晰的視覺節拍,每一格一個。保持描述具體且以動作為中心。
Create a 4-panel vertical comic strip. Equal panel sizes, clear panel borders.
(創建一個4格垂直連環畫。格子大小相等,清晰的邊框。)
Panel 1: Pet owner walks out the front door, keys in hand. Through the window
behind them, we see their cat watching — paws pressed against glass, eyes wide
with apparent sadness. The house suddenly feels empty.
(第一格:寵物主人走出前門,手裡拿著鑰匙。透過身後的窗戶,我們看到他們的貓在看 —— 爪子按在玻璃上,眼睛睜得大大的,明顯很悲傷。房子突然感覺空蕩蕩的。)
Panel 2: The door clicks shut. The cat slowly turns away from the window toward
the empty house. Its posture shifts from forlorn to interested. Eyes narrow with
possibility.
(第二格:門關上了。貓慢慢從窗戶轉向空蕩蕩的房子。它的姿態從淒涼轉變為感興趣。眼睛眯起來,充滿了可能性。)
Panel 3: Total chaos. Cat sprawled across the forbidden couch like royalty.
Knocked over plant on the floor. Papers scattered. Sunbeam spotlighting the
scene of domestic crime.
(第三格:完全混亂。貓像皇室一樣躺在禁止入內的沙發上。地板上是被打翻的植物。紙張散落。陽光照亮了家庭犯罪現場。)
Panel 4: Door handle turns. Cat sits perfectly upright by the entrance,
composed and innocent, tail wrapped neatly around paws. Not a hair out of
place. As if nothing happened.
(第四格:門把手轉動。貓在入口處坐得筆直,鎮定而無辜,尾巴整齊地纏繞在爪子上。一絲不亂。彷彿什麼都沒發生過。)
Style: Warm illustrated style with expressive characters, clear visual
storytelling that reads without text. Consistent character design across
all panels.
(風格:溫暖的插圖風格,富有表現力的角色,清晰的視覺敘事,無需文字即可閱讀。所有格子中角色設計一致。)
No speech bubbles or text. Let the visuals tell the story. (無氣泡或文字。讓視覺講述故事。)將每一格定義為具有清晰動作的獨特視覺節拍。模型處理格子布局和視覺連續性。
兒童讀物插圖
兒童讀物插圖需要一種特定的方法:令人難忘的角色設計、溫暖易懂的風格,以及與文字覆蓋相協調的構圖。
Create a children's book illustration introducing the main character.
(創建一個介紹主角的兒童讀物插圖。)
Character: Young forest hero, around 8 years old. (角色:年輕的森林英雄,約8歲。)
- Green hooded tunic (think woodland adventurer, not Robin Hood) (綠色連帽長袍(想想林地冒險家,不是羅賓漢))
- Soft brown boots, well-worn (柔軟的棕色靴子,磨損良好)
- Small belt pouch for collecting treasures (用於收集寶藏的小腰包)
- Carries a tiny wooden bow (symbolic, for helping not hurting) (背著一把小木弓(象徵性的,用於幫助而非傷害))
- Kind expression, bright curious eyes, brave but gentle demeanor (善良的表情,明亮好奇的眼睛,勇敢但溫和的舉止)
- Slightly oversized head for picture book proportions (略大的頭,符合圖畫書比例)
Theme: This character protects and rescues small forest animals in trouble.
(主題:這個角色保護和拯救陷入困境的小森林動物。)
Style: Hand-painted watercolor look with soft outlines, warm earthy palette
with forest greens and autumn oranges. Whimsical, friendly, inviting for
young readers ages 4-8.
(風格:手繪水彩外觀,柔和輪廓,溫暖的大地色調,森林綠和秋季橙。異想天開,友好,吸引4-8歲的年輕讀者。)
Composition: Character standing in simple forest glade, dappled sunlight,
leaving room for title text above. Character clearly showcased.
(構圖:角色站在簡單的林間空地上,斑駁的陽光,上方留有標題文字空間。角色清晰展示。)
Original character design only. No text. No watermarks. No copyrighted
character references. (僅原創角色設計。無文字。無水印。無版權角色參考。)保存此角色參考圖像 —— 你將使用它在後續插圖中保持一致性。
利用世界知識
GPT Image 1.5最被低估的能力之一是其內置的世界知識。模型可以從微妙的線索中推斷出背景,在沒有明確指示的情況下生成符合歷史和文化的圖像。
Create a realistic outdoor crowd scene in Bethel, New York on August 16, 1969.
(創建一個1969年8月16日紐約伯特利的逼真戶外人群場景。)
Photorealistic, period-accurate clothing, staging, and environment.
(照片級真實,符合時代的服裝、布景和環境。)
Documentary photography style, shot on film, natural lighting.
(紀實攝影風格,膠片拍攝,自然光。)模型知道這是伍德斯托克音樂節,而無需被告知。它僅根據日期和地點就能生成嬉皮士、那個時代的時尚、節日氣氛。
這種世界知識延伸到各個時代的建築、幾十年的時尚、文化活動、地理地標、藝術運動,甚至特定的攝影美學。當準確性很重要時,提供時間和地點通常比長篇大論地描述你期望看到的東西能產生更好的結果。
精準編輯的藝術
文生圖生成令人印象深刻,但圖像編輯才是GPT Image 1.5真正閃耀的地方。能夠精確修改現有圖像,同時保留其他一切,開啟了以前沒有專家級Photoshop技能是不可能的專業工作流。
編輯的黃金法則
每一個成功的編輯都遵循相同的模式:明確說明什麼改變,明確說明什麼保持不變。這聽起來顯而易見,但所需的特異性水平比大多數人意識到的要高。
始終將編輯提示構建為:「Change ONLY [X]. Preserve EXACTLY: [comprehensive list of everything else].」 (僅更改[X]。完全保留:[其他所有內容的綜合列表]。)然後在每次後續編輯中重複此保留列表,以防止逐漸偏離原始圖像。
虛擬服裝試穿
電子商務正被AI試穿功能改變。這是我用於完美保持身份的服裝更換的提示詞結構。
Edit the image to dress this person in the provided clothing items.
(編輯圖像,讓此人穿上提供的服裝項目。)
MUST PRESERVE (do not change in any way) (必須保留(不要以任何方式更改)):
- Face, facial features, expression, skin tone (臉、面部特徵、表情、膚色)
- Body shape, proportions, and pose (體型、比例和姿勢)
- Hairstyle and hair color (髮型和髮色)
- Background and environment (背景和環境)
- Camera angle, framing, and composition (相機角度、取景和構圖)
- Overall lighting direction and quality (整體光照方向和質量)
CHANGE ONLY (僅更改):
- Replace current clothing with provided garment images (用提供的服裝圖像替換當前服裝)
- Fit garments naturally to body geometry (使服裝自然貼合身體幾何形狀)
- Show realistic fabric draping, folds, and behavior (顯示逼真的織物垂墜、褶皺和表現)
- Match lighting and shadows on fabric to original photo (使織物上的光照和陰影與原始照片匹配)
REQUIREMENTS (要求):
- Photorealistic integration — outfit should look worn, not pasted (照片級真實融合 —— 服裝應該看起來是穿在身上的,而不是粘貼上去的)
- Maintain color temperature of original image (保持原始圖像的色溫)
- No accessories, text, logos, or watermarks added (不添加配飾、文字、Logo或水印)
- Identity must remain clearly recognizable (身份必須保持清晰可辨)對於虛擬試穿,始終使用 input_fidelity="high" 以確保面部相似度得到保持。
風格遷移
風格遷移提取一張圖像的視覺語言 —— 它的調色板、紋理、筆觸、審美 —— 並將其應用於新內容。這對於保持品牌一致性或創建連貫的系列非常寶貴。
Using the EXACT visual style of the reference image (Image 1), create:
(使用參考圖像(圖像1)的完全相同的視覺風格,創建:)
A man riding a motorcycle on a winding mountain road.
(一個男人在蜿蜒的山路上騎摩托車。)
STYLE ELEMENTS TO MATCH PRECISELY from reference (從參考中精確匹配的風格元素):
- Color palette and saturation levels (調色板和飽和度水平)
- Line quality and weight (線條質量和粗細)
- Texture treatment and brushwork (紋理處理和筆觸)
- Lighting style and direction (光照風格和方向)
- Level of detail vs. abstraction (細節與抽象的程度)
- Overall artistic aesthetic (整體藝術審美)
APPLY TO NEW CONTENT (應用到新內容):
- Single subject (man on motorcycle) (單一主體(騎摩托車的人))
- Clear composition with visual interest (清晰的構圖,具有視覺趣味)
- Mountain road environment with curves (帶有彎道的山路環境)
- Sense of motion and freedom (運動感和自由感)
The new image should look like it came from the same artist or series as
the reference. Maintain stylistic consistency exactly.
(新圖像應該看起來像與參考圖像出自同一位藝術家或系列。精確保持風格一致性。)當你具體說明要保留哪些風格元素以及要更改哪些內容元素時,風格遷移效果最好。
物體替換
在保持照片級真實感的同時交換物體現在已經變得實用。秘訣不僅在於描述要添加什麼,還在於描述它應該如何與現有場景融合。
In this room photo, replace ONLY the white plastic chairs with
mid-century modern wooden chairs (walnut finish, tapered legs,
woven seat).
(在這個房間照片中,僅將白色塑料椅子替換為世紀中期現代風格的木椅(胡桃木飾面,錐形腿,編織座椅)。)
PRESERVE COMPLETELY (完全保留):
- Camera angle and perspective (相機角度和透視)
- Room lighting direction and quality (房間光照方向和質量)
- All other furniture and objects (所有其他家具和物體)
- Wall colors and decorations (牆壁顏色和裝飾)
- Floor material and shadows (地板材質和陰影)
- Overall image quality and color grading (整體圖像質量和調色)
INTEGRATION REQUIREMENTS (融合要求):
- Chairs must match room's perspective exactly (椅子必須精確匹配房間的透視)
- Wood grain should catch existing light realistically (木紋應逼真地捕捉現有光線)
- Contact shadows must be natural and match light source (接觸陰影必須自然並與光源匹配)
- Scale must be accurate relative to table height (比例必須相對於桌子高度準確)
- New chairs should look like they belong in this room (新椅子應該看起來屬於這個房間)
Photorealistic result — should look like the original photograph.
(照片級真實結果 —— 應該看起來像原始照片。)室內設計可視化是最具商業價值的編輯應用之一。
草圖轉照片級真實渲染
將粗略草圖轉化為精美的渲染圖對於產品設計、建築和概念開發非常有用。提示詞需要將草圖視為要遵循的規範。
Transform this hand-drawn sketch into a photorealistic image.
(將這張手繪草圖轉化為照片級真實的圖像。)
PRESERVE FROM SKETCH (從草圖中保留):
- Exact layout and proportions (精確的布局和比例)
- Perspective and viewing angle (透視和視角)
- Element placement and relationships (元素放置和關係)
- Implied depth and layering (暗示的深度和層次)
ADD FOR REALISM (為真實感添加):
- Appropriate real-world materials and textures (適當的現實世界材料和紋理)
- Consistent natural lighting (interpret from sketch shading) (一致的自然光照(從草圖陰影解讀))
- Environmental context matching the implied setting (匹配暗示環境的環境背景)
- Surface imperfections and wear appropriate to materials (適合材料的表面瑕疵和磨損)
CONSTRAINTS (約束):
- Do not add new elements not present in sketch (不要添加草圖中不存在的新元素)
- Do not add text or watermarks (不要添加文字或水印)
- Treat the sketch as an architectural blueprint to follow exactly (將草圖視為要精確遵循的建築藍圖)
- Fill in realistic details while honoring the original composition (在尊重原始構圖的同時填充逼真的細節)模型解讀草圖的意圖並填充逼真的細節,同時保持原始構圖。
光照和天氣轉換
在保留場景幾何結構的同時改變環境條件是我最喜歡的編輯應用之一。非常適合創建季節性變體、一天中的不同時間替代方案或情緒調整。
Transform this daytime summer scene into a winter evening with snowfall.
(將這個白天的夏季場景轉換為下雪的冬夜。)
CHANGE (更改):
- Time of day: from afternoon to dusk (warm interior lights visible) (時間:從下午到黃昏(可見溫暖的室內燈光))
- Season: summer to deep winter (季節:夏季到深冬)
- Weather: clear to active snowfall (天氣:晴朗到下雪)
- Ground: grass to fresh snow coverage (地面:草地到新雪覆蓋)
- Trees: summer foliage to bare branches with snow (樹木:夏季樹葉到帶雪的枯枝)
- Atmosphere: add visible breath if people present (氛圍:如果有人,添加可見的呼吸)
- Surfaces: add frost on windows and metal (表面:在窗戶和金屬上添加霜)
PRESERVE (保留):
- Camera position and angle exactly (相機位置和角度完全不變)
- All objects and their exact positions (所有物體及其確切位置)
- Architecture and structural elements (建築和結構元素)
- People and their poses (update clothing appropriately) (人和他們的姿勢(適當更新服裝))
- Overall composition and framing (整體構圖和取景)
Style: Photorealistic, natural atmospheric perspective, visible
snowflakes in air, cozy contrast between warm interior lights and
cold exterior. Should feel photographed, not filtered.
(風格:照片級真實,自然大氣透視,空氣中可見雪花,溫暖室內燈光與寒冷室外之間的舒適對比。應該感覺是拍攝的,而不是濾鏡處理的。)在環境轉換中使用 input_fidelity="high" 和 quality="high" 以獲得最佳結果。
多圖合成
結合來自多個源圖像的元素需要關於什麼來自哪裡以及元素應如何無縫融合的清晰指令。
I'm providing 2 images:
(我提供2張圖片:)
- Image 1: Beach scene with woman standing on shore at sunset (圖片1:日落時分女人站在岸邊的海灘場景)
- Image 2: Golden retriever sitting in a studio setting (圖片2:坐在攝影棚環境中的金毛尋回犬)
Task: Place the dog from Image 2 into the beach scene from Image 1,
positioned next to the woman, looking up at her.
(任務:將圖片2中的狗放入圖片1的海灘場景中,位於女人旁邊,抬頭看著她。)
MATCHING REQUIREMENTS (匹配要求):
- Dog's lighting must match beach sunset (warm golden light from left) (狗的光照必須匹配海灘日落(來自左側的溫暖金光))
- Scale dog appropriately relative to woman's height (相對於女人的身高適當縮放狗)
- Dog should cast shadow consistent with scene's sun angle (狗應該投射與場景太陽角度一致的陰影)
- Sand texture should show around and under dog's paws (狗爪周圍和下方應顯示沙子紋理)
- Fur should catch the same golden hour highlights as scene (毛髮應捕捉與場景相同的黃金時刻高光)
PRESERVE FROM IMAGE 1 (從圖片1保留):
- Woman's exact appearance, position, and pose (女人的確切外貌、位置和姿勢)
- Beach background completely unchanged (海灘背景完全不變)
- Original photo's color grading and mood (原始照片的調色和情緒)
The composite should look like a single photograph taken on location.
No visible compositing artifacts.
(合成圖應該看起來像是在現場拍攝的單張照片。沒有可見的合成偽影。)按編號引用圖片,並明確哪些元素轉移,哪些保持固定。
圖像中的文本翻譯
使用GPT Image 1.5的文本能力,為國際市場本地化視覺內容變得大大簡化。
Translate all text in this infographic from English to Japanese.
(將此信息圖中的所有文本從英語翻譯成日語。)
MUST PRESERVE (必須保留):
- Exact layout, spacing, and positioning of all elements (所有元素的精確布局、間距和位置)
- All visual elements, icons, illustrations, and graphics (所有視覺元素、圖標、插圖和圖形)
- Typography hierarchy (headlines vs body text relationships) (排版層級(標題與正文關係))
- Color scheme and overall design aesthetic (配色方案和整體設計審美)
- Font weights and relative sizes (字體粗細和相對大小)
TRANSLATION REQUIREMENTS (翻譯要求):
- Accurate Japanese translation with natural phrasing (準確的日語翻譯,措辭自然)
- Match visual weight and style to original fonts (匹配原始字體的視覺權重和風格)
- Adjust character spacing for Japanese typographic norms (針對日語排版規範調整字符間距)
- No text truncation or overflow outside original bounds (無文本截斷或溢出原始邊界)
Do not modify any non-text elements. Only change the language.
(不要修改任何非文本元素。只改變語言。)此工作流無需從頭重建即可處理營銷材料、UI截圖、包裝和信息圖表。
專業人士的高級技巧
一旦你掌握了基礎知識,這些高級技巧將把你的作品提升到真正的專業水平。這些是我通過廣泛實驗開發的模式 —— 始終能產生卓越結果的技巧。
跨圖像的角色一致性
AI圖像生成中最大的挑戰之一是保持多個圖像中角色的一致性。對於兒童讀物、品牌吉祥物或任何需要在不同場景中出現相同角色的項目,這是我經過驗證的工作流。
生成一個詳細的參考圖像,確立角色的最終外觀。包括所有關鍵細節:服裝、比例、表情、調色板。保存這張圖片 —— 它成為你的真理之源。
寫一段詳細的角色文本描述,你將在所有未來的提示詞中引用它。具體到每一個視覺元素。這個文本錨點補充了視覺錨點。
在創建新場景時,始終包含錨點圖像作為輸入,並明確指示「maintain exact character appearance from reference image」(保持與參考圖像完全相同的角色外觀)。
模型在對話會話中保持上下文。在成功的圖像基礎上構建,而不是為每個場景重新開始。直接引用之前的生成。
Continue the children's book story using the character from the reference image.
(使用參考圖像中的角色繼續兒童讀物故事。)
New Scene (新場景):
The same young forest hero is gently helping a frightened squirrel out
of a fallen hollow tree after a winter storm. Snow on the ground, bare
branches above, warm light filtering through clouds.
(同一個年輕的森林英雄在一場冬季風暴後,正溫柔地幫助一隻受驚的松鼠從倒下的空心樹中出來。地面上有雪,頭頂是光禿禿的樹枝,溫暖的光線透過雲層過濾下來。)
CHARACTER CONSISTENCY (from reference) (角色一致性(來自參考)):
- Same green hooded tunic, exact shade and style (同樣的綠色連帽長袍,確切的色調和款式)
- Same soft brown boots (同樣的柔軟棕色靴子)
- Same belt pouch (同樣的腰包)
- Same facial features, proportions, and color palette (同樣的面部特徵、比例和調色板)
- Same gentle, heroic personality in expression (表情中同樣的溫和、英雄個性)
- Same children's book proportions (同樣的兒童讀物比例)
STYLE CONSISTENCY (from reference) (風格一致性(來自參考)):
- Same watercolor illustration style (同樣的水彩插圖風格)
- Same soft outlines (同樣的柔和輪廓)
- Same warm earthy color treatment (同樣的溫暖大地色處理)
- Same whimsical, friendly aesthetic (同樣的異想天開、友好審美)
New elements: winter forest environment, frightened squirrel, fallen
tree with hollow. (新元素:冬季森林環境,受驚的松鼠,倒下的空心樹。)
Do not redesign the character. Do not change the artistic style.
No text. No watermarks.
(不要重新設計角色。不要改變藝術風格。無文字。無水印。)引用錨點圖像並重複關鍵角色細節,以在整本書中保持一致性。
3D風格化人像技術
根據參考照片創建超風格化的3D人像已成為我的標誌性輸出之一。關鍵是對所需審美的極端特異性。
Create a hyper-stylized 3D floating head portrait based on this person.
(根據此人創建一個超風格化的3D浮動頭像人像。)
STYLE CHARACTERISTICS (風格特徵):
- Smooth skin with glossy vinyl-finish surface (光滑皮膚,帶有光澤乙烯基表面)
- Strong highlighter on cheekbones and nose tip catching soft light (顴骨和鼻尖上的強高光捕捉柔和光線)
- Holographic, iridescent eyeshadow (purple to teal color shift) (全息、彩虹色眼影(紫色到青色變色))
- Thick hair sculpted in slick, glossy waves like polished acrylic (像拋光亞克力一樣雕刻成光滑、光澤波浪的濃密頭髮)
- Small metallic chrome nose piercing with brushed reflections (帶有拉絲反射的小金屬鉻鼻釘)
EXPRESSION (表情):
Confident, slightly unimpressed look — half-lidded eyes, subtly
arched brow, the sophisticated "too cool" attitude.
(自信,略帶不屑的表情 —— 半垂的眼瞼,微妙拱起的眉毛,複雜的「太酷了」的態度。)
TECHNICAL SPECIFICATIONS (技術規格):
- Head floats isolated against plain white background (頭像孤立漂浮在純白背景前)
- Slight 15-degree tilt (premium product render feeling) (輕微15度傾斜(高級產品渲染感))
- Bright, diffuse studio lighting with no harsh shadows (明亮、漫射的攝影棚燈光,無刺眼陰影)
- Emphasis on glossy, plastic, subsurface scattering effects (強調光澤、塑料、次表面散射效果)
- Ultra-smooth textures throughout (整體超平滑紋理)
- Close-up portrait angle, straight-on, 85mm lens feel (特寫人像角度,正視,85mm鏡頭感)
The result should look like a high-end 3D character render or
collectible figure — plastic perfection with personality.
(結果應該看起來像高端3D角色渲染或收藏人偶 —— 具有個性的塑料完美感。)這種程度的審美細節能在不同主體間產生驚人一致的結果。
Q版角色轉換
將照片轉換為可愛的Q版風格角色對於品牌吉祥物、社交媒體頭像和周邊商品效果出奇地好。
Transform this person into an adorable chibi-style character.
(將此人轉換為可愛的Q版風格角色。)
CHIBI PROPORTIONS (Q版比例):
- Tiny body (about 1 head-height tall) (微小的身體(約1個頭高))
- Oversized head (3x body proportions) (超大的頭(3倍身體比例))
- Large, sparkling eyes with cute highlights (大而閃亮的眼睛,帶有可愛的反光)
- Soft, rounded facial features (柔和、圓潤的面部特徵)
- Cheerful, expressive pose with personality (愉快、富有表現力的姿勢,具有個性)
PRESERVE FROM ORIGINAL (從原始圖像保留):
- Recognizable facial features (simplified but identifiable) (可辨認的面部特徵(簡化但可識別))
- Hairstyle, length, and hair color (髮型、長度和髮色)
- Distinctive clothing style or accessories (獨特的服裝風格或配飾)
- Any notable characteristics (glasses, jewelry, etc.) (任何顯著特徵(眼鏡、珠寶等))
- Overall personality and vibe (整體個性和氛圍)
STYLE (風格):
- Smooth pastel shading (平滑的柔和陰影)
- Clean lines and simplified details (乾淨的線條和簡化的細節)
- Bright, expressive colors (明亮、富有表現力的顏色)
- Collectible figure aesthetic (收藏人偶審美)
Background: Simple gradient or plain color to showcase character.
(背景:簡單的漸變或純色以展示角色。)
The result should feel like an irresistible chibi mascot that
clearly represents the original person.
(結果應該感覺像是一個無法抗拒的Q版吉祥物,清楚地代表原始人物。)Q版轉換非常適合個人品牌、團隊頭像和商品設計。
文字完美的營銷創意
創建文本準確的營銷材料需要嚴格的排版控制和明確的文本規範。
Create a realistic highway billboard mockup featuring this product.
(創建一個以該產品為特色的逼真高速公路廣告牌模型。)
BILLBOARD CONTENT (廣告牌內容):
- Product bottle prominently displayed on left third (產品瓶子醒目地展示在左三分之一處)
- Main headline on right (EXACT TEXT, render verbatim): (右側主標題(確切文本,逐字渲染):)
"Fresh & Clean — Every Day"
- Tagline below headline: "Nature's Best Ingredients" (標題下方的標語:"Nature's Best Ingredients")
- Small logo placeholder area in bottom right corner (右下角的小Logo占位區域)
TYPOGRAPHY SPECIFICATIONS (排版規格):
- Headline: Bold sans-serif, white text, high contrast (標題:粗體無襯線,白色文本,高對比度)
- Tagline: Light sans-serif, slightly smaller, same white (標語:細無襯線,稍小,同樣的白色)
- Clean kerning, centered alignment within text area (乾淨的字距,文本區域內居中對齊)
- Text appears EXACTLY ONCE — no duplicates anywhere (文本只出現一次 —— 任何地方都沒有重複)
SCENE (場景):
- Billboard on highway overpass or roadside structure (高速公路立交橋或路邊結構上的廣告牌)
- Sunset lighting creating warm, appealing atmosphere (日落光線營造溫暖、吸引人的氛圍)
- Photorealistic environment with motion-blurred vehicles below (照片級真實環境,下方有動態模糊的車輛)
- Professional advertising photography feel (專業廣告攝影感)
No watermarks. No additional marketing copy. No logos unless
specified. Text must be perfectly legible and correctly spelled.
(無水印。無額外營銷文案。除非指定,否則無Logo。文本必須完全清晰且拼寫正確。)對於包含文本的營銷材料,始終使用 quality="high"。在最終使用前驗證拼寫。
產品攝影提取
創建帶有孤立主體的乾淨產品照對於電子商務至關重要。這是有效的提示詞。
Extract the product from this image for e-commerce use.
(從這張圖像中提取產品用於電子商務。)
OUTPUT SPECIFICATIONS (輸出規格):
- Transparent background (RGBA PNG format) (透明背景(RGBA PNG格式))
- Crisp silhouette with clean edges (清晰的輪廓,邊緣乾淨)
- No halos or color fringing around product (產品周圍無光暈或彩色條紋)
- All product labels and text perfectly preserved (所有產品標籤和文本完美保留)
- Exact product geometry and proportions maintained (精確保持產品幾何形狀和比例)
OPTIONAL ENHANCEMENT (可選增強):
- Add subtle, realistic contact shadow (添加微妙、逼真的接觸陰影)
- Shadow should be soft and natural, no hard edges (陰影應柔和自然,無硬邊)
- Shadow works with the transparent background (陰影適用於透明背景)
CRITICAL CONSTRAINTS (關鍵約束):
- Do NOT restyle or recolor the product (不要重新設計或重新著色產品)
- Do NOT modify product appearance in any way (不要以任何方式修改產品外觀)
- Only remove background and add optional shadow (僅移除背景並添加可選陰影)
- Preserve every detail of the original product exactly (精確保留原始產品的每一個細節)注意:當前模型渲染棋盤格圖案來表示透明度 —— 可能需要後期處理才能獲得真正的Alpha通道。
已知限制
背景移除目前會渲染視覺棋盤格圖案來指示透明度,而不是在輸出文件中產生真正的RGBA透明度。對於生產使用,你可能需要使用圖像編輯軟體進行後期處理,將棋盤格轉換為實際的透明度。
迭代優化循環
不要試圖在一個提示詞中實現完美。專業結果來自系統迭代。
優化過程
- 生成: 創建包含核心元素和整體構圖的初始圖像
- 評估: 確定首先要解決的1-2個最重要的問題
- 完善: 僅修復那些特定問題,明確保留其他一切
- 鎖定: 在嘗試下一次迭代之前保存當前狀態
- 重複: 繼續直到滿意,增量構建
每一個小的、專注的改變都會匯聚成精確的最終結果,而且比試圖一次性完成所有事情的挫敗感要少得多。
現實世界的專業工作流
理論很有價值,但看到技巧如何組合成完整的工作流才是理解結晶的地方。以下是我在專業實踐中最常使用的工作流。
電子商務產品攝影流程
完整產品視覺系統
- 產品提取: 從原始產品照片中移除背景,創建乾淨的孤立鏡頭
- 生活方式背景: 生成環境場景(廚房、辦公室、戶外)並將產品合成其中
- 顏色變體: 通過有針對性的編輯創建產品顏色變體,無需重新拍攝
- 營銷創意: 生成帶有產品集成的廣告牌模型、社交媒體圖形、橫幅廣告
- 本地化: 翻譯營銷材料中的文本以適應不同市場,同時保留設計
以前需要攝影棚時間、Photoshop專業知識和多名專家的完整產品攝影流程,現在通過一系列AI提示詞即可運行。
內容創作者視覺庫
建立一致的品牌資產
- 角色開發: 創建帶有詳細錨點圖像的品牌吉祥物或個人頭像
- 風格指南生成: 製作調色板參考、情緒板和審美示例
- 縮略圖工廠: 使用已建立的角色和風格生成一致的YouTube/社交媒體縮略圖
- 背景庫: 為各種內容類型創建符合品牌審美的場景背景
- 變體擴展: 使用風格遷移在所有新內容中保持視覺一致性
一次性建立你的視覺基礎,然後高效迭代。創造出以前需要專門設計團隊才能做到的品牌一致性。
快速設計原型
從概念到視覺僅需幾分鐘
- 粗略草圖: 手繪基本概念(餐巾紙質量即可 —— 粗略形狀和布局)
- 初步渲染: 將草圖轉換為照片級真實或風格化的圖像,保留你的構圖
- 迭代周期: 通過有針對性的編輯進行完善(「更暖的光線」、「不同的材料」、「更多對比度」)
- 變體探索: 為客戶演示或決策生成多個變體 (n=4)
- 最終打磨: 導出選定方向的高質量版本,完善細節
設計師報告稱,與傳統數字創作流程相比,概念迭代速度顯著加快。
兒童讀物插圖流程
創作一致的插圖書
- 角色設計: 創建詳細的角色參考表,確立最終外觀
- 風格確立: 生成2-3個樣本頁面以鎖定插圖風格,挑選最好的
- 逐場景生成: 逐頁處理故事,始終引用角色和風格錨點
- 一致性審查: 一起查看所有頁面,使用編輯修復任何角色漂移或風格不一致
- 最終完善: 在保持已建立外觀的同時根據需要打磨個別頁面
錨點圖像方法使整本書中一致的角色插圖真正可以實現。
扼殺結果的常見錯誤
在看著我自己和無數其他人與AI圖像生成作鬥爭後,我發現了區分成功與挫折的模式。以下是我曾經犯過的錯誤 —— 以及我是如何修正它們的。
❌ 關鍵詞堆砌
錯誤: 在每個提示詞中都添加「highly detailed, 8K, photorealistic, trending on ArtStation, masterpiece」(高度細節,8K,照片級真實,ArtStation趨勢,傑作)。
修正: 描述具體的視覺屬性。「Visible skin pores, morning window light, 50mm lens depth of field」(可見皮膚毛孔,晨間窗光,50mm鏡頭景深)比通用質量關鍵詞傳達的信息多得多。
❌ 巨型提示詞
錯誤: 試圖在一個巨大的提示詞中指定每一個可能的細節,希望模型能以某種方式弄明白我的完整願景。
修正: 從簡單開始。先得到一個堅實的基礎圖像,然後用有針對性的後續提示進行完善。增量構建產生更好的結果。
❌ 模糊的編輯指令
錯誤: 說「make it better」(讓它更好)或「fix the lighting」(修復光線),而不具體說明「更好」意味著什麼或光線應該如何改變。
修正: 對更改要具體。「Shift lighting from harsh overhead to soft window light from the left, with warmer color temperature.」(將光線從刺眼的頂光轉變為來自左側的柔和窗光,色溫更暖。)
❌ 忘記保留列表
錯誤: 請求更改而不明確說明什麼應保持不變,然後驚訝於其他元素發生漂移。
修正: 每個編輯提示都包含明確的保留要求。在每次迭代中重複它們,因為模型不記得以前的約束。
❌ 上下文健忘症
錯誤: 為相關圖像開始新的對話,丟失了建立起來的所有上下文和一致性。
修正: 為相關工作在會話內構建。直接引用之前的生成。使用像「same style as the previous image」(與上一張圖片相同的風格)這樣的短語來利用上下文。
❌ 錯誤的質量設置
錯誤: 總是使用高質量(對於迭代來說既慢又貴)或總是使用低質量(在關鍵時刻丟失關鍵細節)。
修正: 將設置與任務匹配。低質量用於探索和迭代;高質量用於最終輸出和任何帶有文本的內容。
❌ 與模型對抗
錯誤: 重複運行完全相同的提示詞,期望得到不同的結果,或者強迫模型向它一貫抵制的方向發展。
修正: 如果提示詞不起作用,改寫而不是重複。不同的詞激活模型中的不同模式。有時你的方法需要改變,而不僅僅是模型的輸出。
❌ 忽視隨機性
錯誤: 期望從相同的提示詞中得到相同的結果,當輸出變化時感到沮喪。
修正: 生成多個變體 (n=4) 並挑選最好的。將變異性視為創意的來源,而不是要克服的缺陷。
大多數人可以做出的單一最具影響力的改變:停止把提示詞當作願望,開始把它們當作規範。像給人類合作者寫設計簡報一樣精確。模型非常能幹 —— 但它需要清晰的指導來展示這種能力。
開發者API集成
如果你正通過編程將GPT Image 1.5集成到應用程序中,這裡是你是需要的技術細節和最佳實踐。
基本API設置
import os
import base64
from openai import OpenAI
client = OpenAI()
# Create output directory (創建輸出目錄)
os.makedirs("output_images", exist_ok=True)
def save_image(result, filename: str) -> None:
"""Save base64 image response to file."""
image_base64 = result.data[0].b64_json
with open(f"output_images/{filename}", "wb") as f:
f.write(base64.b64decode(image_base64))
# Basic text-to-image generation (基本文生圖生成)
result = client.images.generate(
model="gpt-image-1.5",
prompt="Your detailed prompt here",
quality="high", # or "low" for faster iteration (或"low"用於更快迭代)
n=1 # number of variations (變體數量)
)
save_image(result, "output.png")多輸入圖像編輯
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # Essential for identity preservation (身份保留至關重要)
quality="high",
image=[
open("input_images/source.png", "rb"),
open("input_images/style_reference.png", "rb"),
],
prompt="""
Apply the artistic style from Image 2 to the subject in Image 1.
(將圖片2的藝術風格應用到圖片1的主體上。)
PRESERVE: subject's identity, pose, and composition
(保留:主體的身份、姿勢和構圖)
CHANGE: artistic style, color palette, texture treatment
(改變:藝術風格、調色板、紋理處理)
Do not add new elements. Maintain subject likeness exactly.
(不要添加新元素。精確保持主體相似度。)
"""
)
save_image(result, "styled_output.png")關鍵API參數
生成參數
model
"gpt-image-1.5" —— 具有最佳功能的最新旗艦模型
prompt
你的文本描述 —— 結構比長度更重要
quality
"high"用於細節和文本工作,"low"用於速度和迭代
n
生成的變體數量(通常1-4,探索時更高)
編輯參數
image
文件對象或多圖像輸入的文件對象列表
input_fidelity
"high"用於身份保留,對人像工作至關重要
定價考量
API 成本結構
- 基於Token的定價: 成本隨解析度和質量設置而變化
- 1MP 高質量: 每1,000張圖片約$133
- 1MP 低質量: 每1,000張圖片約$9
- 成本節約: 圖像輸入/輸出成本比GPT Image 1低20%
對於大批量應用,始終從低質量開始,僅針對最終輸出或文本密集型圖像升級。
與其他工具的對比
我花了大量時間使用每一個主流AI圖像生成工具。以下是我對ChatGPT圖像生成器(GPT Image 1.5)與競爭對手相比的誠實評估。
GPT Image 1.5 vs Gemini 3.0 Pro Image
GPT Image 1.5 勝出: 指令依從性 (90% vs 77%)、文本渲染準確性、精準編輯、API集成質量
Gemini 3.0 Pro 勝出: 部分基準測試的整體圖像質量、創意解讀、複雜的多人物場景
我的看法: GPT Image 1.5適合需要精度和一致性的專業工作;Gemini適合你想要更多解讀的創意探索
GPT Image 1.5 vs Midjourney
GPT Image 1.5 勝出: 指令遵循、圖像編輯能力、API訪問、文本渲染、可預測的結果
Midjourney 勝出: 藝術審美和「驚艷係數」、社區和分享功能、繪畫風格
我的看法: GPT Image 1.5適合你需要特定結果的專業/商業工作;Midjourney適合藝術探索和概念藝術
GPT Image 1.5 vs DALL-E 3
GPT Image 1.5 勝出: 編輯能力、速度(快4倍)、迭代間的一致性、指令依從性
DALL-E 3 勝出: 沒什麼顯著的 —— GPT Image 1.5是繼任者,在各個維度都有改進
我的看法: 如果你還在用DALL-E 3,立即升級。GPT Image 1.5全面超越。
GPT Image 1.5 vs Stable Diffusion
GPT Image 1.5 勝出: 易用性、無需設置、指令遵循、文本渲染、一致的質量
Stable Diffusion 勝出: 完全定製、本地控制、無限免費生成、微調、專用模型
我的看法: GPT Image 1.5適合速度和易用性;Stable Diffusion適合控制、定製和成本敏感的大批量工作
在基準測試中,GPT Image 1.5在Artificial Analysis Image Arena的文生圖和圖像編輯類別中均獲得了#1的位置。對於需要可靠、可預測結果和精確控制的生產工作,它是目前最好的選擇。
真正的答案?最好的工具取決於你的具體需求。我保留了多個工具的訪問權限,因為每個工具都在不同的方面表現出色。但如果為了專業工作我只能擁有一個,我會選擇GPT Image 1.5,因為它的可靠性、精確度和編輯能力。
高級用戶秘籍
這些技巧讓我從「還不錯」提升到了「專業質量」的結果。每一個都是通過廣泛的實驗和有時痛苦的失敗學到的。
新項目從頭開始
在新的對話中開始每個新項目。舊項目的上下文可能會滲入新的生成中並導致意外結果。乾淨的開始,乾淨的結果。
80/20法則
在第一次生成中爭取達到80%的正確率。使用編輯來完成最後的20%。試圖在一個提示詞中實現完美會導致挫折和浪費時間。
具體勝過最高級
「Shot on medium format film with natural grain」(中畫幅膠片拍攝,自然顆粒)每次都勝過「ultra-high-quality amazing detailed」(超高質量驚人細節)。具體細節引導模型;最高級只會增加噪音。
引用你的文本
總是將所需的文本放在「引號」中,並指定它應該出現「exactly once, no duplicates」(完全一次,無重複)。這可以防止困擾文本渲染的重複和拼寫錯誤。
以否定結束
以你不想要的東西結束每個提示詞:「No watermarks, no text unless specified, no logos, no excessive saturation, no artificial bokeh.」(無水印,除非指定否則無文字,無Logo,無過度飽和,無人工散景。)預防勝於糾正。
保存你的贏家
當你得到一個很好的結果時,保存圖像和完整的提示詞。建立一個你可以為未來項目調整的經證明有效的提示詞個人庫。
改寫,不要重複
如果一個提示詞不起作用,不要指望運氣好而再次運行它。改寫它。不同的詞激活模型中的不同模式。改變你的方法。
文本總是高質量
每當你的圖像包含文本 —— 任何文本 —— 使用高質量模式。低質量文本通常難以辨認,使得速度節省變得毫無價值。
理解隨機性 (Stochasticity)
這很關鍵:AI圖像生成本質上是隨機的。相同的提示詞每次都會產生不同的結果。這不是Bug —— 這是技術的本質。
擁抱變化
與其對抗隨機性,不如利用它。生成4個變體並挑選最好的。有時「意想不到」的解讀會比你最初想像的更好。我認識的最好的AI藝術家傾向於利用意外之喜,同時保持足夠的控制來實現他們的目標。變異性是一個特性,而不是缺陷。
常見問題排查
經過數千次生成,我遇到了能想像到的每一個問題。以下是如何修復讓創作者受挫的最常見問題。
問題:文本拼寫錯誤或重複
解決方案
將確切文本放在引號中:"RESTAURANT"而不是restaurant。添加明確指令:"render exactly once, no duplicates"(完全渲染一次,無重複)。對於困難的單詞,逐個字母拼寫:"R-E-S-T-A-U-R-A-N-T"。對於任何包含文本的圖像,始終使用 quality="high"。使用前驗證輸出。
問題:角色在不同圖像中看起來不同
解決方案
首先創建一個詳細的角色錨點圖像並保存它。將此錨點作為每個後續生成的輸入。寫一本列出每個視覺細節的角色聖經。明確指示「maintain exact character appearance from reference image」(保持與參考圖像完全相同的角色外觀)。在API調用中使用 input_fidelity="high"。儘可能在單個會話中工作。
問題:編輯改變了超出要求的內容
解決方案
對保留要更明確。將提示詞構建為「Change ONLY: [X]. Preserve EXACTLY: [list everything else in detail].」(僅更改:[X]。完全保留:[詳細列出其他所有內容]。)在每個編輯迭代中重複完整的保留列表 —— 模型不記得以前的約束。對重要元素使用 input_fidelity="high"。
問題:圖像看起來明顯是「AI生成的」
解決方案
添加逼真的瑕疵:「subtle film grain」(微妙膠片顆粒)、「slight lens vignette」(輕微鏡頭暗角)、「natural skin texture with pores and subtle blemishes」(帶有毛孔和微妙瑕疵的自然皮膚紋理)、「dust particles visible in sunbeam」(陽光中可見的塵埃顆粒)、「minor wear on materials」(材料上的輕微磨損)。完美看起來很假。現實是混亂的。描述相機實際捕捉到的東西,而不是理想化的版本。
問題:顏色看起來過飽和或不自然
解決方案
明確指定顏色處理:「natural color grading」(自然調色)、「true-to-life colors」(逼真色彩)、「muted earth tones」(柔和大地色調)、「not oversaturated」(不過飽和)、「color-accurate」(色彩準確)。引用特定膠片類型作為顏色指導:「Kodak Portra color science」(柯達Portra色彩科學)或「documentary color grading」(紀實調色)。添加「realistic color balance, no HDR look」(逼真色彩平衡,無HDR外觀)。
問題:背景移除產生光暈或偽影
解決方案
明確請求:「transparent background (RGBA PNG format), crisp silhouette, no halos, no color fringing, clean edges, no artifacts」(透明背景(RGBA PNG格式),清晰輪廓,無光暈,無彩色條紋,乾淨邊緣,無偽影)。注意當前模型渲染棋盤格圖案來表示透明度 —— 生產中可能需要後期處理以獲得真正的Alpha通道。
問題:構圖感覺不平衡或尷尬
解決方案
明確指定構圖:「subject positioned using rule of thirds」(主體使用三分法定位)、「centered with symmetrical framing」(居中對稱取景)、「generous negative space on left for text overlay」(左側大量留白用於文字覆蓋)、「eye-level camera angle」(平視相機角度)、「subject fills 60% of frame」(主體佔據畫面的60%)。不要把構圖留給運氣 —— 準確描述你想要的。
AI圖像生成的未來
我們正經歷一場革命。兩年前還是科幻小說的東西現在成了任何人都可以獲取的商品。但我們仍處於這個故事的早期章節。這是我看到的未來。
地平線上有什麼
🎬 無縫視頻集成
靜態圖像和視頻之間的界限正在迅速模糊。期待在同一介面內從圖像生成平滑過渡到動畫序列。早期版本已經出現(Sora, Runway),並且正在快速改進。你的圖像提示詞將只需極少的調整即可變為視頻提示詞。
🎯 完美的一致性
無需人工努力即可在無限圖像中保持角色和風格的一致性。錨點和參考工作流將變為自動。用幾個你的角色例子訓練模型,它就會永遠保持完美的一致性。「漂移」問題將被完全解決。
✏️ 實時協作編輯
交互式編輯,你可以在對話中實時繪畫、拖動和操縱元素。想像一下Photoshop,每一筆都會觸發AI響應,複雜的編輯通過對話而不是技術工具發生。
🎨 個人風格學習
用少量示例訓練模型學習你的審美。你自己的個人AI藝術家,理解你的品味、你的品牌、你的視覺語言 —— 並將其一致地應用到你創作的一切中。
視覺創作的民主化
我們正在目睹的不僅僅是視覺創作的民主化。曾經需要多年訓練的技能 —— 產品攝影、平面設計、插圖、概念藝術 —— 正在變得任何能描述自己想看什麼的人都可以獲得。
這並沒有消除人類創造力的價值。如果有的話,它提升了它。當執行變得容易時,願景就是一切。在這個新領域茁壯成長的人不會是那些能畫出最逼真手部的人 —— AI現在能處理這個。他們將是那些有值得說的話、值得展示的東西、能打動人心的人。
在從膠片過渡到數碼的過程中茁壯成長的攝影師不是那些抵制變革的人。他們是那些在保持藝術願景的同時擁抱新工具的人。AI圖像生成是同一種類型的過渡,只是更具戲劇性和速度更快。
最好的AI生成圖像將永遠由既了解技術又了解藝術的人創造。掌握工具,但永遠不要忘記工具服務於願景。技術放大了人類的創造力 —— 它不會取代它。
最後的想法
幾分鐘內完成縮略圖、圖形和社交內容,而不是幾小時
前所未有規模的產品攝影、變體和營銷
以前需要幾天的快速概念設計和客戶演示
用於構建啟用圖像的應用程序的強大編程訪問
自然語言使入門比傳統設計工具更容易
足以用於商業工作的質量和一致性
我開始這段旅程時感到沮喪和懷疑。我聽說過關於AI圖像生成的炒作,但反覆撞上營銷承諾與實際現實之間的牆。不可能的解剖結構的手指。融化成抽象形狀的文字。主動與我的意圖作對的構圖。我準備把這一切都當作過度炒作的技術而不予理會。
然後我學會了說機器的語言。我停止描述我想看到什麼,開始描述攝影機能捕捉到什麼。我停止指望運氣,開始系統地構建。我停止與模型對抗,開始與它合作。
GPT Image 1.5不僅僅是改進了以前的問題 —— 它從根本上改變了我與視覺創作的關係。我現在從提示詞和迭代的角度思考,而不是筆刷和圖層。我帶著信心處理視覺挑戰,相信有一個提示詞結構能產生我需要的東西。我今天創作的圖像在兩年前需要幾天才能製作出來。我可以探索的想法只受想像力的限制,而不受技術技能的限制。
學習曲線是真實的。你不會一夜之間掌握它。但本指南中的原則 —— 結構勝於關鍵詞,特異性勝於最高級,迭代勝於完美,攝影師思維 —— 將把數週令人沮喪的實驗壓縮成專注、高效的學習。
最重要的是,我希望這本指南能給你我在開始時希望擁有的東西:不僅僅是技巧,而是一個思維模型。一種理解這項技術如何解釋語言,它響應什麼,以及如何流利地講它的視覺語言。
你腦海中的圖像與螢幕上的圖像之間的差距從未如此之小。有了正確的方法,這個差距會隨著你寫的每一個提示詞繼續縮小。
現在去創造一些美麗的東西吧。
我還記得那個凌晨2點的時刻,當一切都變得清晰 —— 出現的圖像不僅僅是可以接受的,而且正是我所設想的。那種感覺現在你也可以擁有。技術已經到來。技巧已經記錄在案。剩下的就是你的想像力和你學習新語言的意願。ChatGPT圖像生成器不僅僅是一個工具 —— 它是一個創造性的合作夥伴,以我們才剛剛開始理解的方式放大人類的視覺。歡迎來到視覺創作的未來。你一直在腦海中看到的圖像?它們比以往任何時候都更接近現實。
討論
0 條評論留下評論
成為第一個分享您想法的人!