La differenza tra immagini AI frustranti e mozzafiato non è il talento o la fortuna — è imparare a parlare il linguaggio visivo che la macchina comprende.
Ricordo ancora il momento esatto in cui tutto è cambiato. Erano le 2 di notte di un martedì. Stavo fissando il mio schermo da ore, provando prompt dopo prompt, guardando ChatGPT sputare immagini che non assomigliavano per niente a ciò che avevo immaginato. Dita con un'anatomia impossibile. Testo che si scioglieva in parole senza senso. Personaggi che sembravano resistere attivamente alle mie intenzioni. Ero pronto a rinunciare completamente alla generazione di immagini AI — a liquidarla come tecnologia sopravvalutata che funzionava solo per altre persone.
Poi ho provato qualcosa di diverso. Invece di descrivere ciò che volevo vedere, ho descritto ciò che una fotocamera avrebbe catturato. Invece di chiedere "un bel tramonto", ho scritto "luce dell'ora d'oro che filtra attraverso le cime delle montagne, scattata su Canon 5D Mark IV, obiettivo 24-70mm a f/2.8, color grading naturale". L'immagine apparsa non era solo accettabile — era sbalorditiva. Fotorrealistica. Esattamente ciò che esisteva solo nella mia immaginazione pochi istanti prima.
Quel singolo cambio di prospettiva ha sbloccato tutto. Nei mesi successivi, sono andato a fondo. Ho generato migliaia di immagini. Ho testato ogni tecnica che ho potuto trovare. Ho letto la documentazione di OpenAI da cima a fondo. Ho sperimentato con GPT Image 1.5 il giorno del lancio. E ora condividerò tutto ciò che ho imparato — non i consigli superficiali che troverai ovunque, ma la conoscenza profonda che separa i professionisti dagli hobbisti. Questa è la guida che avrei voluto esistesse quando ho iniziato. Ecco come passare da principiante frustrato a creatore sicuro.
Il Mio Viaggio nella Generazione di Immagini AI
Lascia che ti riporti a dove tutto è iniziato. Come molti di voi che leggono questo, ero inizialmente scettico sulla generazione di immagini AI. "È solo un giocattolo per appassionati di tecnologia", pensavo. "Il vero lavoro creativo richiede vere abilità". Non avrei potuto sbagliarmi di più.
La mia prima vera necessità di immagini AI è nata da un problema pratico. Stavo creando contenuti per un progetto e avevo bisogno di immagini di copertina — molte. Avevo pagato per foto d'archivio, sborsando soldi per scatti generici che anche ogni altro creatore stava usando. Le immagini andavano bene, ma mancavano di anima. Sembravano prese in prestito, non possedute.
Un amico ha menzionato che ChatGPT poteva generare immagini ora. "Descrivi solo quello che vuoi", ha detto. "È come magia". Così ci ho provato. Il mio primo prompt era imbarazzantemente ingenuo: "Un bel tramonto sulle montagne". Il risultato? Un pasticcio sfocato che sembrava un dipinto ad acquerello lasciato sotto la pioggia. Ero deluso, per non dire altro.
Ma qualcosa continuava a tirarmi indietro. Ho provato di nuovo. E ancora. Ogni fallimento mi insegnava qualcosa di nuovo su come l'IA interpretava il linguaggio. Ho iniziato a notare schemi — certe frasi che producevano costantemente risultati migliori, approcci strutturali che guidavano il modello verso la mia visione piuttosto che allontanarlo da essa.
La svolta è arrivata quando ho capito: la generazione di immagini AI non riguarda la descrizione di ciò che vedi nella tua mente — riguarda la descrizione di ciò che una fotocamera catturerebbe nella realtà. Quel singolo cambio di prospettiva ha cambiato tutto.
Ho smesso di pensare come un sognatore e ho iniziato a pensare come un fotografo. Invece di "bel tramonto", ho scritto di luce dell'ora d'oro, modelli di fotocamera specifici, lunghezze focali degli obiettivi, impostazioni di apertura, pellicole. L'IA capiva questo linguaggio perché era stata addestrata su milioni di immagini che venivano con esattamente questo tipo di metadati tecnici.
Nei mesi successivi, sono diventato ossessionato. Ho generato migliaia di immagini in ogni stile e caso d'uso che potessi immaginare. Ho letto ogni pezzo di documentazione pubblicato da OpenAI. Mi sono unito a comunità di creatori che spingevano i confini di ciò che era possibile. E quando GPT Image 1.5 è stato lanciato a gennaio 2026, ero pronto. Capivo non solo come usarlo, ma perché funzionava in quel modo.
Ora condividerò tutto ciò che ho imparato. Non i consigli superficiali che troverai in altre cento guide. La conoscenza profonda che deriva da un'ampia sperimentazione, test sistematici e innumerevoli conversazioni con altri creatori che stanno spingendo questi strumenti ai loro limiti. Questa è la guida completa — quella che ti porterà da principiante confuso a creatore sicuro.
Cos'è il Generatore di Immagini ChatGPT
Prima di immergerci nelle tecniche, lasciami chiarire esattamente con cosa stiamo lavorando. Il generatore di immagini ChatGPT è il sistema integrato di creazione e modifica di immagini di OpenAI, attualmente alimentato dal loro modello GPT Image 1.5. A differenza di strumenti autonomi come Midjourney o Stable Diffusion, è profondamente integrato nell'interfaccia conversazionale di ChatGPT.
Questa integrazione conta più di quanto potresti pensare. Poiché ChatGPT comprende il contesto, può mantenere la coerenza attraverso più generazioni, ricordare le tue preferenze all'interno di una sessione e persino ragionare su ciò che stai cercando di creare. Digli che stai lavorando a un libro per bambini e adatterà il suo stile di conseguenza. Menziona che hai bisogno di immagini per una presentazione aziendale e si sposterà verso un'estetica pulita e professionale. Questa consapevolezza contestuale è qualcosa che i generatori di immagini autonomi semplicemente non possono eguagliare.
🎨 Generazione Testo-a-Immagine
Descrivi qualsiasi cosa in linguaggio naturale e guardala materializzarsi. Dai ritratti fotorrealistici all'arte astratta, dai mockup di prodotti ai paesaggi fantastici — se puoi descriverlo, l'IA può crearlo.
✏️ Editing di Immagini di Precisione
Carica immagini esistenti e modificale con comandi di testo. Cambia colori, scambia oggetti, regola l'illuminazione, trasforma le stagioni o reinventa completamente la scena preservando gli elementi che vuoi mantenere.
🔄 Trasferimento di Stile
Prendi il linguaggio visivo da un'immagine — la sua tavolozza, texture, pennellata o estetica — e applicalo a contenuti completamente nuovi. Perfetto per mantenere la coerenza del marchio o creare serie coese.
📝 Resa del Testo Affidabile
Finalmente, un'IA che sa davvero scrivere. GPT Image 1.5 gestisce il testo nelle immagini con una precisione senza precedenti — perfetto per loghi, poster, infografiche e materiali di marketing dove le parole contano.
Come Funziona Davvero
Quando invii un prompt al generatore di immagini di ChatGPT, accadono diverse cose dietro le quinte. Primo, ChatGPT stesso elabora la tua richiesta, potenzialmente espandendo o chiarendo il tuo prompt in base al contesto. Potrebbe aggiungere dettagli che hai implicato ma non dichiarato, o strutturare la tua richiesta in un modo che il modello di immagine comprende meglio.
Poi la richiesta va al modello di generazione di immagini — attualmente GPT Image 1.5 — che trasforma la tua descrizione testuale in output visivo. Questo modello è stato addestrato su un enorme set di dati di immagini abbinate a descrizioni dettagliate, imparando le intricate relazioni tra linguaggio ed elementi visivi.
Il risultato è un sistema che comprende genuinamente ciò che stai chiedendo, non solo abbinando parole chiave. Chiedi "un momento spontaneo fotorrealistico" e ottieni qualcosa che sembra genuinamente non in posa. Richiedi "luce mattutina attraverso persiane veneziane" e ottieni lo specifico motivo a strisce che crea.
GPT Image 1.5 ha ottenuto il primo posto nell'Artificial Analysis Image Arena sia per la generazione testo-a-immagine che per l'editing di immagini, con un tasso di conformità alle istruzioni del 90% — 13 punti percentuali in più rispetto al suo concorrente più vicino. Questo non è parlare di marketing; riflette un genuino salto di capacità.
La Rivoluzione GPT Image 1.5
Quando OpenAI ha rilasciato GPT Image 1.5 a gennaio 2026, non hanno solo iterato sul loro modello precedente — hanno ricostruito le fondamenta. Avevo usato ampiamente le versioni precedenti, quindi ho notato immediatamente la differenza. Questo non era un miglioramento incrementale; era un cambio di paradigma.
Lasciami essere specifico su ciò che è cambiato, perché capire questi miglioramenti ti aiuterà a sfruttarli efficacemente.
I Tre Progressi Che Contano
I modelli precedenti avevano una frustrante tendenza a deviare. Chiedevi di cambiare una cosa, e altre tre cose cambiavano inaspettatamente. Correggevi l'illuminazione, e improvvisamente la faccia del personaggio sembrava diversa. GPT Image 1.5 comprende genuinamente "cambia solo questo elemento" — può modificare parti specifiche preservando illuminazione, composizione, tratti del viso, persino texture sottili. Questo rende il raffinamento iterativo effettivamente pratico.
La velocità di generazione è aumentata fino al 400% rispetto alle versioni precedenti. Quello che richiedeva 30 secondi ora ne richiede 7-8. Ma ancora più importante, puoi accodare nuove generazioni mentre quelle attuali sono ancora in elaborazione. Questo trasforma il processo creativo da "invia e aspetta" a "esplora e itera". La differenza psicologica è significativa — cicli di feedback più rapidi significano più sperimentazione.
La resa del testo nelle immagini AI è stata storicamente un disastro — errori di ortografia, duplicazioni, lettere che si sciolgono in forme astratte. GPT Image 1.5 gestisce testo denso e piccolo mantenendo tipografia, layout e leggibilità adeguati. Questo apre a infografiche, materiali di marketing, mockup UI e qualsiasi caso d'uso in cui le parole appaiono nelle immagini. Per la prima volta, posso generare slide di presentazione, grafiche per social media con didascalie ed etichette di prodotti che userei davvero.
Comprendere le Impostazioni di Qualità
GPT Image 1.5 offre diversi livelli di qualità, e capire quando usare ciascuno ti farà risparmiare tempo e migliorerà i tuoi risultati. Questo non riguarda solo la qualità dell'output — riguarda l'abbinamento dello strumento giusto al compito giusto.
⚡ Modalità Bassa Qualità
Non lasciarti ingannare dal nome — "bassa qualità" qui significa "veloce ed efficiente". I risultati sono comunque notevolmente buoni per la maggior parte dei casi d'uso. Usalo per:
- Esplorazione iniziale dei concetti e brainstorming
- Iterazioni rapide quando raffini le idee
- Composizioni semplici senza dettagli fini
- Generazione ad alto volume dove la velocità conta
- Bozze prima di impegnarsi nelle versioni finali
✨ Modalità Alta Qualità
Quando ogni pixel conta e hai bisogno di risultati pronti per la pubblicazione. Riservalo per:
- Immagini di produzione finale per la consegna
- Lavoro denso di testo e tipografia
- Infografiche complesse con piccoli dettagli
- Ritratti fotorrealistici dove la texture conta
- Qualsiasi immagine dove hai bisogno della massima fedeltà
L'Impostazione Nascosta di Fedeltà dell'Input
Ecco qualcosa che la maggior parte delle guide non ti dirà: quando modifichi le immagini, c'è un parametro chiamato input_fidelity che influenza drammaticamente i risultati. Impostalo su "high" (alto) quando hai bisogno di preservare i tratti del viso, mantenere l'identità attraverso le modifiche o apportare cambiamenti significativi alla scena. Il modello lavora più duramente per mantenere le caratteristiche chiave dell'immagine originale.
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # L'ingrediente segreto per la preservazione dell'identità
quality="high",
image=[open("portrait.png", "rb")],
prompt="Change the background to a sunset beach while preserving the person's exact appearance"
)Questa combinazione assicura la massima conservazione del soggetto originale mentre applica le modifiche richieste.
Il più grande cambiamento con GPT Image 1.5 non è tecnico — è filosofico. La generazione di immagini passa da "chiedi e prega" a "istruisci e itera". Questo richiede un modello mentale completamente diverso per come approcci la creazione visiva.
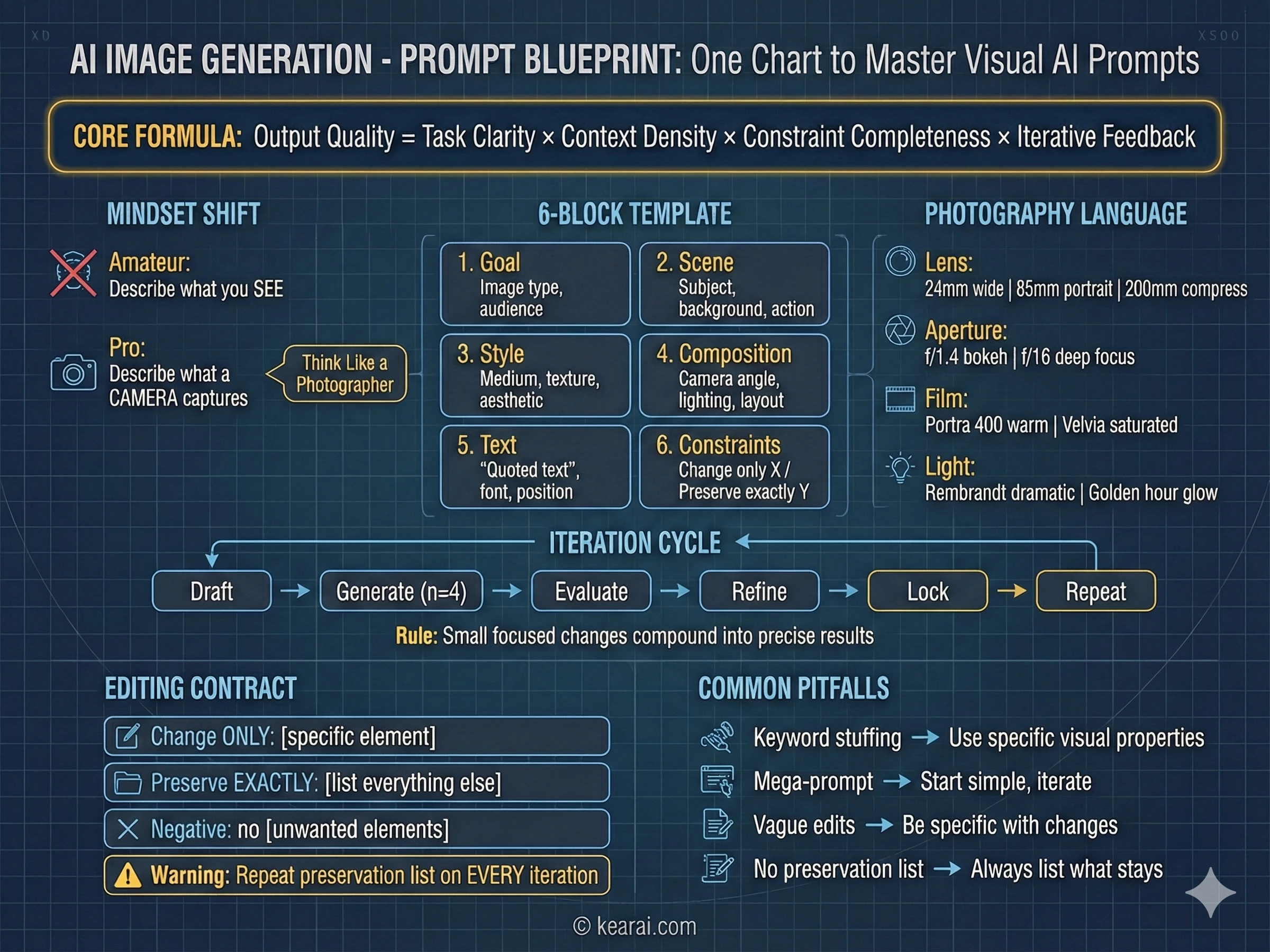
Il Framework di Prompt che ha Cambiato Tutto
Dopo aver generato migliaia di immagini, ho sviluppato un framework che produce costantemente risultati eccezionali. Dimentica tutto ciò che hai letto sull'aggiungere "masterpiece, trending on ArtStation, ultra-detailed, 8K resolution" ai tuoi prompt. Quelle parole chiave funzionavano per i modelli più vecchi che avevano bisogno di segnali di qualità, ma GPT Image 1.5 risponde alla struttura e alla specificità, non al riempimento di parole chiave.
La chiamo architettura strutturata dei prompt, e ogni prompt efficace che scrivo ora segue questo schema.
Goal/Output (Obiettivo/Output):
- [Type of image: ad, UI mockup, infographic, photo, illustration] (Tipo di immagine)
- [Intended use and audience] (Uso previsto e pubblico)
Scene (Scena):
- [Background/environment description] (Descrizione sfondo/ambiente)
- [Main subject with specific details] (Soggetto principale con dettagli specifici)
- [Action or relationship between elements] (Azione o relazione tra elementi)
Style (Stile):
- [Medium: photograph, watercolor, 3D render, vector illustration] (Mezzo)
- [Key textures: matte, glossy, grainy, smooth, organic] (Texture chiave)
- [Quality descriptors: realistic imperfections, stylized, minimalist] (Descrittori di qualità)
Composition/Layout (Composizione/Layout):
- [Camera position: close-up, wide shot, aerial view, eye-level] (Posizione fotocamera)
- [Lighting: golden hour, studio strobes, overcast, dramatic shadows] (Illuminazione)
- [Element placement: centered, rule of thirds, negative space, margins] (Posizionamento elementi)
Text (if any) (Testo se presente):
- "Exact text in quotes" ("Testo esatto tra virgolette")
- [Font style, size, color, position] (Stile font, dimensione, colore, posizione)
- [Specify: render only once, no duplicates] (Specificare: renderizzare solo una volta)
Constraints (Vincoli):
- Change ONLY: [specific element if editing] (Cambia SOLO)
- Preserve exactly: [elements that must stay unchanged] (Preserva esattamente)
- Negative: no watermark, no extra text, no logos, no [unwanted elements] (Negativo)Questo framework dà al modello un contesto chiaro per ogni decisione visiva che deve prendere.
I Sette Principi del Prompting Efficace
Oltre alla struttura, questi principi governano come scrivo ogni prompt. Sono la differenza tra immagini che funzionano quasi e immagini che centrano la tua visione.
Struttura Sopra Parole Chiave
Usa un ordine coerente: sfondo → soggetto → dettagli → vincoli. Per richieste complesse, usa sezioni etichettate o interruzioni di riga. I lunghi paragrafi confondono il modello; una struttura organizzata lo guida verso la tua intenzione.
Specificità Sopra Superlativi
Invece di "alta qualità" o "ultra-dettagliato", descrivi proprietà visive reali. Materiali, texture, forme, mezzi. "Pori della pelle visibili e lentiggini sottili" batte "faccia altamente dettagliata" ogni volta.
Controllo Esplicito della Composizione
Nomina la tua inquadratura (primo piano, campo lungo, vista a volo d'uccello), prospettiva (livello degli occhi, angolo basso, angolo olandese) e atmosfera di illuminazione (diffusa morbida, ora d'oro, luce di bordo ad alto contrasto). Non lasciare questi al caso.
Il Contratto Cambia vs. Preserva
Per l'editing, dichiara esplicitamente cosa dovrebbe cambiare E cosa dovrebbe rimanere intatto. Usa "change only X" e "preserve exactly Y". Ripeti questa lista di conservazione in ogni iterazione per prevenire la deriva.
Il Testo Richiede Precisione
Metti il testo richiesto tra "virgolette" o in MAIUSCOLO. Specifica stile del font, dimensione, colore e posizione. Per parole difficili o nomi di marchi, compitali lettera per lettera. Aggiungi sempre "render exactly once, no duplicates" (renderizza esattamente una volta, nessun duplicato).
Chiarezza di Riferimento Multi-Immagine
Quando lavori con più immagini di input, fai riferimento a ciascuna per indice e descrizione: "Immagine 1: lo scatto del prodotto, Immagine 2: il riferimento di stile". Dichiara esplicitamente come dovrebbero interagire.
Iterare Piuttosto che Sovraccaricare
Inizia con un prompt di base pulito, poi raffina con piccoli follow-up a singolo cambiamento. "Make the lighting warmer" (Rendi l'illuminazione più calda). "Remove the background tree" (Rimuovi l'albero sullo sfondo). Piccoli passi si sommano in risultati precisi.
L'Errore Più Comune
Il più grande errore che vedo fare alle persone: cercare di specificare tutto in un unico prompt massiccio, sperando che il modello in qualche modo lo capisca. Questo non funziona quasi mai bene. Inizia con un prompt più semplice per stabilire la base, poi itera con raffinamenti mirati. Otterrai risultati migliori in meno tempo con molti meno fallimenti frustranti.
La Mentalità Fotografica
Il singolo più grande miglioramento nei miei risultati è venuto da un cambiamento mentale: ho smesso di pensare come un artista che descrive una visione e ho iniziato a pensare come un fotografo che descrive uno scatto. Questa non è solo una metafora — è una tecnica pratica che sfrutta il modo in cui il modello è stato addestrato.
I modelli di immagini AI hanno imparato da milioni di fotografie che venivano con metadati: modelli di fotocamera, specifiche degli obiettivi, impostazioni di apertura, condizioni di illuminazione. Quando usi questo linguaggio, stai attivando la profonda comprensione del modello di come le vere fotocamere catturano scene reali.
Linguaggio Fotografico Che Funziona
- Scelta dell'obiettivo: "24mm wide angle" (grandangolo) crea scene ampie con distorsione ai bordi; "200mm telephoto" (teleobiettivo) comprime la profondità e isola i soggetti
- Sensazione di apertura: "f/1.4 bokeh" dà una sfocatura dello sfondo cremosa per i ritratti; "f/16 deep focus" (profondità di campo estesa) mantiene tutto nitido per i paesaggi
- Pellicole: "Kodak Portra 400" per tonalità della pelle calde e lusinghiere; "Fuji Velvia" per paesaggi saturi e vivaci; "Ilford HP5" per bianco e nero contrastato
- Setup di illuminazione: "Rembrandt lighting" per ritratti drammatici; "butterfly lighting" per scatti di bellezza; "golden hour backlight" per bordi luminosi eterei
- Movimento della fotocamera: "long exposure motion blur" per energia dinamica; "high-speed freeze frame" per catturare l'azione
Invece di dire "make it look professional" (fallo sembrare professionale), prova "shot on Hasselblad medium format, studio strobe lighting, seamless gray backdrop, color-calibrated for print reproduction". Invece di "realistic portrait" (ritratto realistico), prova "candid photograph, 85mm f/1.4 lens, window light from camera left, subtle fill from reflector, visible skin texture with pores, shot on Sony A7R IV".
❌ PRIMA (Vago):
"A beautiful portrait of an old fisherman, very detailed, high quality, realistic"
✅ DOPO (Mentalità Fotografica):
"Candid documentary photograph of an elderly fisherman on a weathered wooden boat.
Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind eyes.
Gray stubble. Faded traditional anchor tattoo on forearm. Salt-stained navy wool
sweater, worn cap.
Early morning coastal light, soft fog diffusing the sun. Medium close-up at eye
level, 50mm lens, f/2.8, shallow depth of field. Shot like 35mm film with subtle
grain, natural color balance.
Documentary style — honest, unretouched, capturing a real moment. No glamorization."La mentalità fotografica trasforma desideri vaghi in precise specifiche visive che il modello comprende profondamente.
Quando descrivi le immagini usando il linguaggio fotografico, non stai solo essendo più specifico — stai parlando una lingua che il modello è stato addestrato a capire. Le specifiche della fotocamera, i setup di illuminazione e le pellicole non sono parole chiave arbitrarie; codificano informazioni visive precise che il modello può decodificare accuratamente.
Maestria nel Testo-a-Immagine
Creare immagini da pure descrizioni testuali è dove la maggior parte delle persone inizia il proprio viaggio nelle immagini AI. È anche dove il divario tra risultati amatoriali e professionali è più visibile. Lascia che ti guidi attraverso le tecniche che producono costantemente risultati eccezionali in diversi casi d'uso.
Immagini Fotorrealistiche Che Sembrano Naturali
La chiave del fotorrealismo è controintuitiva: devi chiedere l'imperfezione. Pelle perfetta, illuminazione perfetta, composizione perfetta — queste urlano "generato da IA". La realtà è più disordinata, e quel disordine è ciò che rende le immagini autentiche.
Create a photorealistic candid photograph of an elderly sailor standing on a small fishing boat.
Subject: Weathered face with visible wrinkles, sun spots, and pores. Deep-set kind
eyes with crow's feet. Gray stubble, a few days unshaven. Faded traditional anchor
tattoo on forearm. Salt-stained navy wool sweater, worn and pilled. Creased cap
with faded insignia.
Setting: Early morning on the water, soft coastal fog diffusing the light. Aged
wooden boat deck with peeling paint, fishing nets in background, coiled rope.
Technical: Shot like 35mm film photography, medium close-up at eye level, 50mm
lens, shallow depth of field with boat blurred behind him. Subtle film grain,
natural color balance without heavy grading.
The image should feel like a real moment captured by a photojournalist — honest,
unposed, with real skin texture, worn materials, and everyday imperfection. No
glamorization, no heavy retouching, no artificial perfection.Nota come richiediamo esplicitamente imperfezioni — pelle segnata dalle intemperie, materiali usurati, vernice scrostata. La realtà ha consistenza.
Infografiche e Visualizzazione Dati
La resa del testo migliorata in GPT Image 1.5 rende le infografiche un caso d'uso genuinamente pratico. Ora creo grafiche informative di qualità professionale che uso effettivamente nel mio lavoro.
Create a detailed infographic explaining how a coffee machine works.
Structure:
- Title at top: "The Journey of Your Morning Coffee"
- Vertical flow diagram showing: bean hopper → grinder → portafilter →
grouphead → water heating → extraction → cup
- Each step has an icon and 1-2 sentence explanation
- Warm color palette (browns, creams, copper accents)
- Clean, modern design with plenty of white space
- Subtle coffee stain texture in background corners
Style: Professional print-quality infographic, vector-style icons, clear
hierarchy, readable at A4 size.
Typography: Clean sans-serif headings, readable body text, clear visual
hierarchy between title, section headers, and explanatory text.
No watermarks. No stock photo elements. Original illustration only.Per testo denso e layout complessi, usa sempre quality="high" per assicurare che il testo rimanga nitido e leggibile.
Design di Loghi e Brand
La generazione di loghi richiede di dare priorità a semplicità e scalabilità. Un grande logo funziona a qualsiasi dimensione, da una minuscola favicon a un enorme cartellone. Ecco come richiedere design che funzionano effettivamente come loghi.
Create an original logo for "Field & Flour" — a local artisan bakery.
Brand personality: Warm, authentic, handcrafted, timeless. Not trendy or corporate.
Design requirements:
- Clean vector-style shapes with strong silhouette
- Balanced negative space
- Must read clearly from 16px favicon to large signage
- Flat design, minimal strokes, no gradients unless essential
- Earth-tone palette: warm wheat gold, deep brown, cream
- Could incorporate subtle wheat or grain element
- Text must be perfectly legible and properly kerned
Output: Single centered logo on plain cream background. Generous padding around
the design for flexibility.
No watermarks, no mockups, no 3D effects, no complex imagery. Simple, functional,
timeless design.Usa n=4 per generare più variazioni. Il design del logo è soggettivo — datti opzioni tra cui scegliere.
Mockup UI e App
Per il design UI, descrivi l'interfaccia come se esistesse già e fosse spedita a utenti reali. Il linguaggio da concept art produce concept art. Il linguaggio da prodotto produce mockup utilizzabili.
Create a realistic mobile app UI mockup for a local farmers market app.
Screen content (from top):
- Simple header with market name "Riverside Market" and search icon
- Today's featured vendor carousel with square photos
- "Fresh Today" section with produce category chips (Vegetables, Fruits, Dairy, Baked)
- Vendor list with small photos, names, specialties, and distance
- Bottom navigation: Home, Map, Favorites, Cart, Profile
Design language:
- White background, subtle natural green accents
- Clear typography hierarchy (system fonts feel)
- Generous padding and touch-friendly targets
- Looks like a real shipped product, not a concept
- Uses realistic vendor names and produce photos
Frame: Place the UI inside an iPhone 15 Pro device frame, slight perspective
tilt, subtle shadow beneath.Concentrati su layout, gerarchia, spaziatura ed elementi di interfaccia realistici. Evita il linguaggio concettuale o artistico.
Strisce a Fumetti e Arte Sequenziale
Creare fumetti a più pannelli richiede di definire la narrazione come una sequenza di chiari battiti visivi, uno per pannello. Mantieni le descrizioni concrete e focalizzate sull'azione.
Create a 4-panel vertical comic strip. Equal panel sizes, clear panel borders.
Panel 1: Pet owner walks out the front door, keys in hand. Through the window
behind them, we see their cat watching — paws pressed against glass, eyes wide
with apparent sadness. The house suddenly feels empty.
Panel 2: The door clicks shut. The cat slowly turns away from the window toward
the empty house. Its posture shifts from forlorn to interested. Eyes narrow with
possibility.
Panel 3: Total chaos. Cat sprawled across the forbidden couch like royalty.
Knocked over plant on the floor. Papers scattered. Sunbeam spotlighting the
scene of domestic crime.
Panel 4: Door handle turns. Cat sits perfectly upright by the entrance,
composed and innocent, tail wrapped neatly around paws. Not a hair out of
place. As if nothing happened.
Style: Warm illustrated style with expressive characters, clear visual
storytelling that reads without text. Consistent character design across
all panels.
No speech bubbles or text. Let the visuals tell the story.Definisci ogni pannello come un battito visivo distinto con un'azione chiara. Il modello gestisce il layout del pannello e la continuità visiva.
Illustrazioni per Libri per Bambini
L'illustrazione di libri per bambini richiede un approccio specifico: design del personaggio memorabile, stile caldo e accessibile, e composizioni che funzionano con sovrapposizioni di testo.
Create a children's book illustration introducing the main character.
Character: Young forest hero, around 8 years old.
- Green hooded tunic (think woodland adventurer, not Robin Hood)
- Soft brown boots, well-worn
- Small belt pouch for collecting treasures
- Carries a tiny wooden bow (symbolic, for helping not hurting)
- Kind expression, bright curious eyes, brave but gentle demeanor
- Slightly oversized head for picture book proportions
Theme: This character protects and rescues small forest animals in trouble.
Style: Hand-painted watercolor look with soft outlines, warm earthy palette
with forest greens and autumn oranges. Whimsical, friendly, inviting for
young readers ages 4-8.
Composition: Character standing in simple forest glade, dappled sunlight,
leaving room for title text above. Character clearly showcased.
Original character design only. No text. No watermarks. No copyrighted
character references.Salva questa immagine di riferimento del personaggio — la userai per mantenere la coerenza nelle illustrazioni successive.
Sfruttare la Conoscenza del Mondo
Una delle capacità più sottovalutate di GPT Image 1.5 è la sua conoscenza del mondo incorporata. Il modello può dedurre il contesto da indizi sottili, generando immagini storicamente e culturalmente appropriate senza istruzioni esplicite.
Create a realistic outdoor crowd scene in Bethel, New York on August 16, 1969.
Photorealistic, period-accurate clothing, staging, and environment.
Documentary photography style, shot on film, natural lighting.Il modello sa che questo è Woodstock senza che gli venga detto. Genera hippies, moda dell'epoca, l'atmosfera del festival — tutto solo dalla data e dalla posizione.
Questa conoscenza del mondo si estende all'architettura attraverso le epoche, alla moda attraverso i decenni, eventi culturali, punti di riferimento geografici, movimenti artistici e persino estetiche fotografiche specifiche. Quando la precisione conta, fornire tempo e luogo spesso produce risultati migliori di lunghe descrizioni di ciò che ti aspetti di vedere.
L'Arte dell'Editing di Precisione
La generazione testo-a-immagine è impressionante, ma l'editing di immagini è dove GPT Image 1.5 brilla davvero. La capacità di modificare con precisione immagini esistenti preservando tutto il resto apre flussi di lavoro professionali che erano precedentemente impossibili senza competenze esperte di Photoshop.
La Regola d'Oro dell'Editing
Ogni editing di successo segue lo stesso schema: dichiara esplicitamente cosa cambia, dichiara esplicitamente cosa rimane uguale. Questo sembra ovvio, ma il livello di specificità richiesto è maggiore di quanto la maggior parte delle persone realizzi.
Struttura sempre i prompt di editing come: "Change ONLY [X]. Preserve EXACTLY: [comprehensive list of everything else]." Poi ripeti la tua lista di conservazione in ogni editing di follow-up per prevenire la deriva graduale dall'originale.
Prova Virtuale di Abbigliamento
L'e-commerce viene trasformato dalle capacità di prova virtuale dell'IA. Ecco la struttura del prompt che uso per scambi di abbigliamento che mantengono perfettamente l'identità.
Edit the image to dress this person in the provided clothing items.
MUST PRESERVE (do not change in any way):
- Face, facial features, expression, skin tone
- Body shape, proportions, and pose
- Hairstyle and hair color
- Background and environment
- Camera angle, framing, and composition
- Overall lighting direction and quality
CHANGE ONLY:
- Replace current clothing with provided garment images
- Fit garments naturally to body geometry
- Show realistic fabric draping, folds, and behavior
- Match lighting and shadows on fabric to original photo
REQUIREMENTS:
- Photorealistic integration — outfit should look worn, not pasted
- Maintain color temperature of original image
- No accessories, text, logos, or watermarks added
- Identity must remain clearly recognizablePer la prova virtuale, usa sempre input_fidelity="high" per assicurare che la somiglianza facciale sia mantenuta.
Trasferimento di Stile
Il trasferimento di stile prende il linguaggio visivo da un'immagine — la sua tavolozza, texture, pennellata, estetica — e lo applica a nuovi contenuti. Questo è inestimabile per mantenere la coerenza del marchio o creare serie coese.
Using the EXACT visual style of the reference image (Image 1), create:
A man riding a motorcycle on a winding mountain road.
STYLE ELEMENTS TO MATCH PRECISELY from reference:
- Color palette and saturation levels
- Line quality and weight
- Texture treatment and brushwork
- Lighting style and direction
- Level of detail vs. abstraction
- Overall artistic aesthetic
APPLY TO NEW CONTENT:
- Single subject (man on motorcycle)
- Clear composition with visual interest
- Mountain road environment with curves
- Sense of motion and freedom
The new image should look like it came from the same artist or series as
the reference. Maintain stylistic consistency exactly.Il trasferimento di stile funziona meglio quando sei specifico su quali elementi di stile preservare e quali elementi di contenuto cambiare.
Sostituzione Oggetti
Scambiare oggetti mantenendo il fotorrealismo è ora pratico. Il segreto è descrivere non solo cosa aggiungere, ma come dovrebbe integrarsi con la scena esistente.
In this room photo, replace ONLY the white plastic chairs with
mid-century modern wooden chairs (walnut finish, tapered legs,
woven seat).
PRESERVE COMPLETELY:
- Camera angle and perspective
- Room lighting direction and quality
- All other furniture and objects
- Wall colors and decorations
- Floor material and shadows
- Overall image quality and color grading
INTEGRATION REQUIREMENTS:
- Chairs must match room's perspective exactly
- Wood grain should catch existing light realistically
- Contact shadows must be natural and match light source
- Scale must be accurate relative to table height
- New chairs should look like they belong in this room
Photorealistic result — should look like the original photograph.La visualizzazione dell'interior design è una delle applicazioni di editing commercialmente più preziose.
Da Schizzo a Render Fotorrealistico
Trasformare schizzi approssimativi in render raffinati è incredibilmente utile per il design di prodotto, l'architettura e lo sviluppo di concetti. Il prompt deve trattare lo schizzo come una specifica da seguire.
Transform this hand-drawn sketch into a photorealistic image.
PRESERVE FROM SKETCH:
- Exact layout and proportions
- Perspective and viewing angle
- Element placement and relationships
- Implied depth and layering
ADD FOR REALISM:
- Appropriate real-world materials and textures
- Consistent natural lighting (interpret from sketch shading)
- Environmental context matching the implied setting
- Surface imperfections and wear appropriate to materials
CONSTRAINTS:
- Do not add new elements not present in sketch
- Do not add text or watermarks
- Treat the sketch as an architectural blueprint to follow exactly
- Fill in realistic details while honoring the original compositionIl modello interpreta l'intento dello schizzo e riempie con dettagli realistici mantenendo la composizione originale.
Trasformazione Illuminazione e Meteo
Cambiare le condizioni ambientali preservando la geometria della scena è una delle mie applicazioni di editing preferite. Perfetto per creare varianti stagionali, alternative di orario o aggiustamenti di atmosfera.
Transform this daytime summer scene into a winter evening with snowfall.
CHANGE:
- Time of day: from afternoon to dusk (warm interior lights visible)
- Season: summer to deep winter
- Weather: clear to active snowfall
- Ground: grass to fresh snow coverage
- Trees: summer foliage to bare branches with snow
- Atmosphere: add visible breath if people present
- Surfaces: add frost on windows and metal
PRESERVE:
- Camera position and angle exactly
- All objects and their exact positions
- Architecture and structural elements
- People and their poses (update clothing appropriately)
- Overall composition and framing
Style: Photorealistic, natural atmospheric perspective, visible
snowflakes in air, cozy contrast between warm interior lights and
cold exterior. Should feel photographed, not filtered.Usa input_fidelity="high" e quality="high" per i migliori risultati sulle trasformazioni ambientali.
Composizione Multi-Immagine
Combinare elementi da più immagini sorgente richiede chiare istruzioni su cosa proviene da dove e come gli elementi dovrebbero integrarsi senza problemi.
I'm providing 2 images:
- Image 1: Beach scene with woman standing on shore at sunset
- Image 2: Golden retriever sitting in a studio setting
Task: Place the dog from Image 2 into the beach scene from Image 1,
positioned next to the woman, looking up at her.
MATCHING REQUIREMENTS:
- Dog's lighting must match beach sunset (warm golden light from left)
- Scale dog appropriately relative to woman's height
- Dog should cast shadow consistent with scene's sun angle
- Sand texture should show around and under dog's paws
- Fur should catch the same golden hour highlights as scene
PRESERVE FROM IMAGE 1:
- Woman's exact appearance, position, and pose
- Beach background completely unchanged
- Original photo's color grading and mood
The composite should look like a single photograph taken on location.
No visible compositing artifacts.Fai riferimento alle immagini per numero e sii esplicito su quali elementi si trasferiscono e quali rimangono fissi.
Traduzione del Testo nelle Immagini
Localizzare contenuti visivi per i mercati internazionali è drammaticamente semplificato con le capacità di testo di GPT Image 1.5.
Translate all text in this infographic from English to Japanese.
MUST PRESERVE:
- Exact layout, spacing, and positioning of all elements
- All visual elements, icons, illustrations, and graphics
- Typography hierarchy (headlines vs body text relationships)
- Color scheme and overall design aesthetic
- Font weights and relative sizes
TRANSLATION REQUIREMENTS:
- Accurate Japanese translation with natural phrasing
- Match visual weight and style to original fonts
- Adjust character spacing for Japanese typographic norms
- No text truncation or overflow outside original bounds
Do not modify any non-text elements. Only change the language.Questo flusso di lavoro gestisce materiali di marketing, screenshot UI, packaging e infografiche senza ricostruire da zero.
Tecniche Avanzate per Professionisti
Una volta che hai padroneggiato le basi, queste tecniche avanzate eleveranno il tuo lavoro a livelli veramente professionali. Questi sono schemi che ho sviluppato attraverso un'ampia sperimentazione — tecniche che producono costantemente risultati superiori.
Coerenza del Personaggio Attraverso le Immagini
Una delle più grandi sfide nella generazione di immagini AI è mantenere la coerenza del personaggio attraverso più immagini. Per libri per bambini, mascotte di marca o qualsiasi progetto che richieda lo stesso personaggio in scene diverse, ecco il mio flusso di lavoro comprovato.
Genera un'immagine di riferimento dettagliata che stabilisce l'aspetto definitivo del personaggio. Includi tutti i dettagli chiave: outfit, proporzioni, espressione, tavolozza dei colori. Salva questa immagine — diventa la tua fonte di verità.
Scrivi una descrizione testuale dettagliata del personaggio che riferirai in tutti i prompt futuri. Sii specifico su ogni elemento visivo. Questa ancora testuale integra quella visiva.
Quando crei nuove scene, includi sempre l'immagine ancora come input e istruisci esplicitamente "maintain exact character appearance from reference image".
Il modello mantiene il contesto all'interno di una sessione di conversazione. Costruisci su immagini di successo piuttosto che iniziare da capo per ogni scena. Fai riferimento direttamente alle generazioni precedenti.
Continue the children's book story using the character from the reference image.
New Scene:
The same young forest hero is gently helping a frightened squirrel out
of a fallen hollow tree after a winter storm. Snow on the ground, bare
branches above, warm light filtering through clouds.
CHARACTER CONSISTENCY (from reference):
- Same green hooded tunic, exact shade and style
- Same soft brown boots
- Same belt pouch
- Same facial features, proportions, and color palette
- Same gentle, heroic personality in expression
- Same children's book proportions
STYLE CONSISTENCY (from reference):
- Same watercolor illustration style
- Same soft outlines
- Same warm earthy color treatment
- Same whimsical, friendly aesthetic
New elements: winter forest environment, frightened squirrel, fallen
tree with hollow.
Do not redesign the character. Do not change the artistic style.
No text. No watermarks.Fai riferimento all'immagine ancora e ripeti i dettagli chiave del personaggio per mantenere la coerenza attraverso l'intero libro.
La Tecnica del Ritratto Stilizzato 3D
Creare ritratti 3D iper-stilizzati da foto di riferimento è diventato uno dei miei output distintivi. La chiave è l'estrema specificità sull'estetica desiderata.
Create a hyper-stylized 3D floating head portrait based on this person.
STYLE CHARACTERISTICS:
- Smooth skin with glossy vinyl-finish surface
- Strong highlighter on cheekbones and nose tip catching soft light
- Holographic, iridescent eyeshadow (purple to teal color shift)
- Thick hair sculpted in slick, glossy waves like polished acrylic
- Small metallic chrome nose piercing with brushed reflections
EXPRESSION:
- Confident, slightly unimpressed look — half-lidded eyes, subtly
arched brow, the sophisticated "too cool" attitude.
TECHNICAL SPECIFICATIONS:
- Head floats isolated against plain white background
- Slight 15-degree tilt (premium product render feeling)
- Bright, diffuse studio lighting with no harsh shadows
- Emphasis on glossy, plastic, subsurface scattering effects
- Ultra-smooth textures throughout
- Close-up portrait angle, straight-on, 85mm lens feel
The result should look like a high-end 3D character render or
collectible figure — plastic perfection with personality.Questo livello di dettaglio estetico produce risultati notevolmente coerenti su soggetti diversi.
Trasformazione Personaggio Chibi
Convertire foto in adorabili personaggi in stile chibi funziona sorprendentemente bene per mascotte di marca, avatar di social media e merchandising.
Transform this person into an adorable chibi-style character.
CHIBI PROPORTIONS:
- Tiny body (about 1 head-height tall)
- Oversized head (3x body proportions)
- Large, sparkling eyes with cute highlights
- Soft, rounded facial features
- Cheerful, expressive pose with personality
PRESERVE FROM ORIGINAL:
- Recognizable facial features (simplified but identifiable)
- Hairstyle, length, and hair color
- Distinctive clothing style or accessories
- Any notable characteristics (glasses, jewelry, etc.)
- Overall personality and vibe
STYLE:
- Smooth pastel shading
- Clean lines and simplified details
- Bright, expressive colors
- Collectible figure aesthetic
Background: Simple gradient or plain color to showcase character.
The result should feel like an irresistible chibi mascot that
clearly represents the original person.Le trasformazioni chibi funzionano bene per il personal branding, gli avatar di squadra e i design di merchandising.
Creatività di Marketing con Testo Perfetto
Creare materiali di marketing con testo accurato richiede un rigoroso controllo della tipografia e specifiche di testo esplicite.
Create a realistic highway billboard mockup featuring this product.
BILLBOARD CONTENT:
- Product bottle prominently displayed on left third
- Main headline on right (EXACT TEXT, render verbatim):
"Fresh & Clean — Every Day"
- Tagline below headline: "Nature's Best Ingredients"
- Small logo placeholder area in bottom right corner
TYPOGRAPHY SPECIFICATIONS:
- Headline: Bold sans-serif, white text, high contrast
- Tagline: Light sans-serif, slightly smaller, same white
- Clean kerning, centered alignment within text area
- Text appears EXACTLY ONCE — no duplicates anywhere
SCENE:
- Billboard on highway overpass or roadside structure
- Sunset lighting creating warm, appealing atmosphere
- Photorealistic environment with motion-blurred vehicles below
- Professional advertising photography feel
No watermarks. No additional marketing copy. No logos unless
specified. Text must be perfectly legible and correctly spelled.Usa sempre quality="high" per materiali di marketing con testo. Verifica l'ortografia prima dell'uso finale.
Estrazione Fotografia Prodotto
Creare scatti di prodotto puliti con soggetti isolati è essenziale per l'e-commerce. Ecco il prompt che funziona.
Extract the product from this image for e-commerce use.
OUTPUT SPECIFICATIONS:
- Transparent background (RGBA PNG format)
- Crisp silhouette with clean edges
- No halos or color fringing around product
- All product labels and text perfectly preserved
- Exact product geometry and proportions maintained
OPTIONAL ENHANCEMENT:
- Add subtle, realistic contact shadow
- Shadow should be soft and natural, no hard edges
- Shadow works with the transparent background
CRITICAL CONSTRAINTS:
- Do NOT restyle or recolor the product
- Do NOT modify product appearance in any way
- Only remove background and add optional shadow
- Preserve every detail of the original product exactlyNota: Il modello attuale renderizza un motivo a scacchiera per la trasparenza — potrebbe essere necessario il post-processing per il vero canale alfa.
Limitazione Nota
La rimozione dello sfondo attualmente renderizza un motivo visivo a scacchiera per indicare la trasparenza piuttosto che produrre una vera trasparenza RGBA nel file di output. Per l'uso in produzione, potrebbe essere necessario post-elaborare l'output per convertire la scacchiera in effettiva trasparenza utilizzando un software di editing delle immagini.
Il Ciclo di Raffinamento Iterativo
Non cercare di raggiungere la perfezione in un singolo prompt. I risultati professionali derivano dall'iterazione sistematica.
Il Processo di Raffinamento
- Generare: Crea l'immagine iniziale con elementi fondamentali e composizione generale
- Valutare: Identifica i 1-2 problemi più importanti da affrontare per primi
- Raffinare: Correggi solo quei problemi specifici, preservando esplicitamente tutto il resto
- Bloccare: Salva lo stato corrente prima di tentare l'iterazione successiva
- Ripetere: Continua finché non sei soddisfatto, costruendo in modo incrementale
Ogni piccolo cambiamento mirato si somma in risultati finali precisi con molta meno frustrazione rispetto al tentativo di fare tutto in una volta.
Flussi di Lavoro Professionali del Mondo Reale
La teoria è preziosa, ma vedere come le tecniche si combinano in flussi di lavoro completi è dove la comprensione si cristallizza. Ecco i flussi di lavoro che uso più frequentemente nella pratica professionale.
Pipeline di Fotografia Prodotto E-Commerce
Sistema Visivo Completo del Prodotto
- Estrazione prodotto: Rimuovi sfondi da foto grezze del prodotto, crea scatti isolati puliti
- Contesti lifestyle: Genera scene ambientali (cucina, ufficio, esterno) e componi i prodotti in esse
- Varianti colore: Crea variazioni di colore del prodotto attraverso editing mirato senza scattare di nuovo
- Creatività marketing: Genera mockup di cartelloni, grafiche social, banner pubblicitari con integrazione del prodotto
- Localizzazione: Traduci il testo nei materiali di marketing per diversi mercati preservando il design
Una pipeline completa di fotografia di prodotto che prima richiedeva tempo in studio, esperienza Photoshop e molteplici specialisti ora passa attraverso una serie di prompt AI.
Libreria Visiva per Content Creator
Costruire Asset di Brand Coerenti
- Sviluppo personaggio: Crea mascotte del brand o avatar personale con immagine ancora dettagliata
- Generazione guida di stile: Produci riferimenti di palette colori, mood board ed esempi estetici
- Fabbrica di thumbnail: Genera thumbnail coerenti per YouTube/social usando personaggio e stile stabiliti
- Libreria sfondi: Crea sfondi di scena che corrispondono all'estetica del brand per vari tipi di contenuto
- Espansione variazioni: Usa il trasferimento di stile per mantenere la coerenza visiva su tutti i nuovi contenuti
Costruisci le tue fondamenta visive una volta, poi itera in modo efficiente. Crea il tipo di coerenza del brand che prima richiedeva un team di design dedicato.
Prototipazione Rapida di Design
Dal Concetto al Visual in Minuti
- Schizzo approssimativo: Disegna a mano il concetto base (la qualità da tovagliolo va bene — forme approssimative e layout)
- Render iniziale: Converti lo schizzo in immagine fotorrealistica o stilizzata preservando la tua composizione
- Ciclo di iterazione: Raffina attraverso modifiche mirate ("illuminazione più calda", "materiale diverso", "più contrasto")
- Esplorazione varianti: Genera molteplici variazioni (n=4) per presentazione al cliente o processo decisionale
- Pulizia finale: Export di alta qualità della direzione selezionata con dettagli raffinati
I designer riportano un'iterazione dei concetti drammaticamente più veloce rispetto ai tradizionali flussi di lavoro di creazione digitale.
Pipeline di Illustrazione Libri per Bambini
Creare Libri Illustrati Coerenti
- Design personaggio: Crea foglio di riferimento dettagliato del personaggio stabilendo l'aspetto definitivo
- Definizione stile: Genera 2-3 pagine di esempio per fissare lo stile di illustrazione, scegli il migliore
- Generazione scena per scena: Lavora attraverso la storia pagina per pagina, riferendo sempre sia l'ancora del personaggio che quella dello stile
- Revisione coerenza: Visualizza tutte le pagine insieme, usa l'editing per correggere qualsiasi deriva del personaggio o incoerenza di stile
- Raffinamento finale: Pulisci le singole pagine secondo necessità mantenendo il look stabilito
L'approccio dell'immagine ancora rende l'illustrazione coerente dei personaggi attraverso un intero libro genuinamente realizzabile.
Gli Errori che Stavano Uccidendo i Miei Risultati
Dopo aver osservato me stesso e innumerevoli altri lottare con la generazione di immagini AI, ho identificato gli schemi che separano il successo dalla frustrazione. Ecco gli errori che commettevo — e come li ho risolti.
❌ Keyword Stuffing
L'errore: Aggiungere "highly detailed, 8K, photorealistic, trending on ArtStation, masterpiece" a ogni singolo prompt.
La soluzione: Descrivi invece proprietà visive specifiche. "Pori della pelle visibili, luce della finestra mattutina, profondità di campo obiettivo 50mm" comunica molto più di generiche parole chiave di qualità.
❌ Il Mega-Prompt
L'errore: Cercare di specificare ogni possibile dettaglio in un unico prompt massiccio, sperando che il modello capisca in qualche modo la mia visione completa.
La soluzione: Inizia semplice. Ottieni prima una solida immagine di base, poi raffina con prompt di follow-up mirati. Costruire in modo incrementale produce risultati molto migliori.
❌ Istruzioni di Edit Vaghe
L'errore: Dire "fallo meglio" o "aggiusta l'illuminazione" senza specificare cosa significa "meglio" o come dovrebbe cambiare l'illuminazione.
La soluzione: Sii specifico sul cambiamento. "Sposta l'illuminazione da dura zenitale a luce morbida della finestra da sinistra, con temperatura di colore più calda."
❌ Dimenticare la Lista di Conservazione
L'errore: Richiedere modifiche senza dichiarare esplicitamente cosa dovrebbe rimanere invariato, poi sorprendersi quando altri elementi derivano.
La soluzione: Ogni prompt di modifica include requisiti di conservazione espliciti. Ripetili in ogni iterazione perché il modello non ricorda i vincoli precedenti.
❌ Amnesia del Contesto
L'errore: Iniziare nuove conversazioni per immagini correlate, perdendo tutto il contesto e la coerenza accumulati.
La soluzione: Costruisci all'interno delle sessioni per il lavoro correlato. Fai riferimento direttamente alle generazioni precedenti. Usa frasi come "stesso stile dell'immagine precedente" per sfruttare il contesto.
❌ Impostazioni Qualità Sbagliate
L'errore: Usare sempre alta qualità (lento e costoso per l'iterazione) o sempre bassa qualità (perdendo dettagli cruciali quando conta).
La soluzione: Abbina le impostazioni al compito. Bassa qualità per esplorazione e iterazione; alta qualità per output finali e qualsiasi cosa con testo.
❌ Combattere il Modello
L'errore: Eseguire ripetutamente lo stesso identico prompt, aspettandosi risultati diversi, o forzare una direzione che il modello resiste costantemente.
La soluzione: Se un prompt non funziona, riformula piuttosto che ripetere. Parole diverse attivano schemi diversi. A volte il tuo approccio deve cambiare, non solo l'output del modello.
❌ Ignorare la Stocasticità
L'errore: Aspettarsi risultati identici da prompt identici, frustrarsi quando gli output variano.
La soluzione: Genera più variazioni (n=4) e scegli la migliore. Abbraccia la variabilità come fonte di opzioni creative piuttosto che come difetto da superare.
Il singolo cambiamento di maggior impatto che la maggior parte delle persone può fare: smettere di trattare i prompt come desideri e iniziare a trattarli come specifiche. Sii preciso come lo saresti in un brief di design per un collaboratore umano. Il modello è notevolmente capace — ma ha bisogno di una direzione chiara per mostrare tale capacità.
Integrazione API per Sviluppatori
Se stai integrando GPT Image 1.5 nelle applicazioni programmaticamente, ecco i dettagli tecnici e le best practice di cui hai bisogno.
Configurazione API Base
import os
import base64
from openai import OpenAI
client = OpenAI()
# Create output directory
os.makedirs("output_images", exist_ok=True)
def save_image(result, filename: str) -> None:
"""Save base64 image response to file."""
image_base64 = result.data[0].b64_json
with open(f"output_images/{filename}", "wb") as f:
f.write(base64.b64decode(image_base64))
# Basic text-to-image generation
result = client.images.generate(
model="gpt-image-1.5",
prompt="Your detailed prompt here",
quality="high", # or "low" for faster iteration
n=1 # number of variations
)
save_image(result, "output.png")Editing di Immagini con Input Multipli
result = client.images.edit(
model="gpt-image-1.5",
input_fidelity="high", # Essential for identity preservation
quality="high",
image=[
open("input_images/source.png", "rb"),
open("input_images/style_reference.png", "rb"),
],
prompt="""
Apply the artistic style from Image 2 to the subject in Image 1.
PRESERVE: subject's identity, pose, and composition
CHANGE: artistic style, color palette, texture treatment
Do not add new elements. Maintain subject likeness exactly.
"""
)
save_image(result, "styled_output.png")Parametri Chiave API
Parametri di Generazione
model
"gpt-image-1.5" — l'ultimo modello di punta con le migliori capacità
prompt
La tua descrizione testuale — la struttura conta più della lunghezza
quality
"high" (alta) per dettagli e lavoro sul testo, "low" (bassa) per velocità e iterazione
n
Numero di variazioni da generare (1-4 tipicamente, più alto per esplorazione)
Parametri di Editing
image
Oggetto file o lista di oggetti file per input multi-immagine
input_fidelity
"high" (alta) per preservazione identità, critico per lavoro sui ritratti
Considerazioni sui Prezzi
Struttura Costi API
- Prezzi basati su token: I costi scalano con risoluzione e impostazioni di qualità
- 1MP alta qualità: Circa $133 per 1.000 immagini
- 1MP bassa qualità: Circa $9 per 1.000 immagini
- Risparmio costi: I costi di input/output immagini sono inferiori del 20% rispetto a GPT Image 1
Per applicazioni ad alto volume, inizia sempre con bassa qualità e aggiorna solo per output finali o immagini pesanti di testo.
Come si Confronta con Altri Strumenti
Ho trascorso molto tempo con ogni principale strumento di generazione immagini AI. Ecco la mia onesta valutazione di come il generatore di immagini ChatGPT (GPT Image 1.5) si posiziona rispetto alla concorrenza.
GPT Image 1.5 vs Gemini 3.0 Pro Image
GPT Image 1.5 vince: Conformità alle istruzioni (90% vs 77%), precisione resa testo, editing di precisione, qualità integrazione API
Gemini 3.0 Pro vince: Qualità immagine complessiva su alcuni benchmark, interpretazione creativa, scene complesse multi-figura
La mia opinione: GPT Image 1.5 per lavoro professionale che richiede precisione e coerenza; Gemini per esplorazione creativa dove vuoi più interpretazione
GPT Image 1.5 vs Midjourney
GPT Image 1.5 vince: Seguire le istruzioni, capacità di editing immagini, accesso API, resa del testo, risultati prevedibili
Midjourney vince: Estetica artistica e "fattore wow", funzionalità community e condivisione, stili pittorici
La mia opinione: GPT Image 1.5 per lavoro professionale/commerciale dove hai bisogno di risultati specifici; Midjourney per esplorazione artistica e concept art
GPT Image 1.5 vs DALL-E 3
GPT Image 1.5 vince: Capacità di editing, velocità (4x più veloce), coerenza tra iterazioni, conformità alle istruzioni
DALL-E 3 vince: Niente di significativo — GPT Image 1.5 è il successore e migliora su ogni dimensione
La mia opinione: Se stai ancora usando DALL-E 3, aggiorna immediatamente. GPT Image 1.5 è strettamente migliore.
GPT Image 1.5 vs Stable Diffusion
GPT Image 1.5 vince: Facilità d'uso, nessuna configurazione richiesta, seguire le istruzioni, resa del testo, qualità costante
Stable Diffusion vince: Personalizzazione completa, controllo locale, generazione gratuita illimitata, fine-tuning, modelli specializzati
La mia opinione: GPT Image 1.5 per velocità e facilità; Stable Diffusion per controllo, personalizzazione e lavoro ad alto volume attento ai costi
Nei test di benchmark, GPT Image 1.5 ha raggiunto la posizione #1 sia nelle categorie testo-a-immagine che editing di immagini su Artificial Analysis Image Arena. Per il lavoro di produzione che richiede risultati affidabili e prevedibili con controllo preciso, è attualmente la migliore opzione disponibile.
La vera risposta? Lo strumento migliore dipende dalle tue esigenze specifiche. Mantengo l'accesso a più strumenti perché ognuno eccelle in cose diverse. Ma se potessi averne solo uno per il lavoro professionale, sceglierei GPT Image 1.5 per la sua affidabilità, precisione e capacità di editing.
Segreti per Power User
Questi sono i consigli che mi hanno portato da risultati "piuttosto buoni" a "qualità professionale". Ognuno è stato appreso attraverso un'ampia sperimentazione e talvolta dolorosi fallimenti.
Inizia Fresco per Nuovi Progetti
Inizia ogni nuovo progetto in una nuova conversazione. Il contesto dei vecchi progetti può trapelare nelle nuove generazioni e causare risultati inaspettati. Tabula rasa, risultati puliti.
La Regola dell'80/20
Ottieni l'80% giusto nella prima generazione. Usa l'editing per il 20% finale. Cercare di raggiungere la perfezione in un singolo prompt porta a frustrazione e tempo perso.
Lo Specifico Batte il Superlativo
"Scattato su pellicola medio formato con grana naturale" batte "incredibile dettagliato altissima qualità" ogni volta. I dettagli guidano il modello; i superlativi aggiungono solo rumore.
Cita il Tuo Testo
Metti sempre il testo richiesto tra "virgolette" e specifica che deve apparire "exactly once, no duplicates". Questo previene la duplicazione e gli errori di ortografia che affliggono la resa del testo.
Finisci con i Negativi
Termina ogni prompt con ciò che non vuoi: "No watermarks, no text unless specified, no logos, no excessive saturation, no artificial bokeh". La prevenzione batte la correzione.
Salva i Tuoi Vincitori
Quando ottieni un ottimo risultato, salva sia l'immagine CHE il prompt completo. Costruisci una libreria personale di prompt comprovati che puoi adattare per progetti futuri.
Riformula, Non Ripetere
Se un prompt non funziona, non eseguirlo di nuovo sperando nella fortuna. Riformulalo. Parole diverse attivano schemi diversi nel modello. Cambia il tuo approccio.
Alta Qualità per il Testo Sempre
Ogni volta che la tua immagine include testo — qualsiasi testo — usa la modalità alta qualità. Il testo a bassa qualità è spesso illeggibile, rendendo inutile il risparmio di velocità.
Comprendere la Stocasticità
Ecco qualcosa di cruciale: la generazione di immagini AI è fondamentalmente stocastica. Lo stesso prompt può produrre risultati diversi ogni volta. Questo non è un bug — è la natura della tecnologia.
Abbraccia la Varianza
Invece di combattere la casualità, usala. Genera 4 variazioni e scegli la migliore. A volte l'interpretazione "inaspettata" porta a qualcosa di meglio di quanto avevi originariamente immaginato. I migliori artisti AI che conosco si appoggiano agli incidenti felici mantenendo abbastanza controllo per raggiungere i loro obiettivi. La variabilità è una caratteristica, non un difetto.
Risoluzione dei Problemi Comuni
Dopo migliaia di generazioni, ho incontrato ogni problema immaginabile. Ecco come risolvere i problemi più comuni che frustrano i creatori.
Problema: Il Testo è Scritto Male o Duplicato
Soluzione
Metti il testo esatto tra virgolette: "RISTORANTE" non ristorante. Aggiungi istruzione esplicita: "render exactly once, no duplicates". Per parole difficili, compita lettera per lettera: "R-I-S-T-O-R-A-N-T-E". Usa sempre quality="high" per qualsiasi immagine contenente testo. Verifica l'output prima dell'uso.
Problema: Il Personaggio Sembra Diverso tra le Immagini
Soluzione
Crea prima un'immagine ancora dettagliata del personaggio e salvala. Includi questa ancora come input per ogni generazione successiva. Scrivi una bibbia del personaggio elencando ogni dettaglio visivo. Istruisci esplicitamente "maintain exact character appearance from reference image". Usa input_fidelity="high" nelle chiamate API. Lavora all'interno di sessioni singole quando possibile.
Problema: Gli Edit Cambiano Più del Richiesto
Soluzione
Sii più esplicito sulla conservazione. Struttura i prompt come "Change ONLY: [X]. Preserve EXACTLY: [elenca tutto il resto in dettaglio]". Ripeti l'intera lista di conservazione in ogni iterazione di modifica — il modello non ricorda i vincoli precedenti. Usa input_fidelity="high" per elementi importanti.
Problema: Le Immagini Sembrano Ovviamente "Generate da IA"
Soluzione
Aggiungi imperfezioni realistiche: "subtle film grain", "slight lens vignette", "natural skin texture with pores and subtle blemishes", "dust particles visible in sunbeam", "minor wear on materials". La perfezione sembra finta. La realtà è disordinata. Descrivi ciò che le fotocamere catturano realmente, non versioni idealizzate.
Problema: I Colori Sembrano Troppo Saturi o Innaturali
Soluzione
Specifica il trattamento del colore esplicitamente: "natural color grading", "true-to-life colors", "muted earth tones", "not oversaturated", "color-accurate". Fai riferimento a specifiche pellicole per la guida al colore: "Kodak Portra color science" o "documentary color grading". Aggiungi "realistic color balance, no HDR look".
Problema: La Rimozione Sfondo Crea Aloni o Artefatti
Soluzione
Richiedi esplicitamente: "transparent background (RGBA PNG format), crisp silhouette, no halos, no color fringing, clean edges, no artifacts". Nota che il modello attuale renderizza un motivo a scacchiera per la trasparenza — potrebbe essere necessario il post-processing per il vero canale alfa in produzione.
Problema: Le Composizioni Sembrano Sbilanciate o Goffe
Soluzione
Specifica la composizione esplicitamente: "subject positioned using rule of thirds", "centered with symmetrical framing", "generous negative space on left for text overlay", "eye-level camera angle", "subject fills 60% of frame". Non lasciare la composizione al caso — descrivi esattamente ciò che vuoi.
Il Futuro della Generazione di Immagini AI
Stiamo vivendo una rivoluzione. Quello che era fantascienza due anni fa è ora una merce a cui chiunque può accedere. Ma siamo ancora ai primi capitoli di questa storia. Ecco cosa vedo arrivare.
Cosa C'è all'Orizzonte
🎬 Integrazione Video Senza Soluzione di Continuità
La linea tra immagini statiche e video si sta confondendo rapidamente. Aspettati transizioni fluide dalla generazione di immagini a sequenze animate all'interno della stessa interfaccia. Le prime versioni sono già qui (Sora, Runway), e stanno migliorando velocemente. I tuoi prompt per immagini diventeranno prompt per video con un adattamento minimo.
🎯 Coerenza Perfetta
Coerenza di personaggio e stile attraverso immagini illimitate senza sforzo manuale. Il flusso di lavoro ancora-e-riferimento diventerà automatico. Addestra il modello su alcuni esempi del tuo personaggio, e manterrà una coerenza perfetta per sempre. Il problema della "deriva" sarà risolto completamente.
✏️ Editing Collaborativo in Tempo Reale
Editing interattivo dove dipingi, trascini e manipoli elementi conversazionalmente in tempo reale. Immagina Photoshop dove ogni pennellata attiva una risposta AI, e gli edit complessi avvengono attraverso la conversazione piuttosto che strumenti tecnici.
🎨 Apprendimento Stile Personale
Addestra il modello sulla tua estetica con una manciata di esempi. Il tuo artista AI personale che comprende il tuo gusto, il tuo marchio, il tuo linguaggio visivo — e lo applica coerentemente a tutto ciò che crei.
La Democratizzazione della Creazione Visiva
Quello a cui stiamo assistendo è niente meno che la democratizzazione della creazione visiva. Abilità che una volta richiedevano anni di formazione — fotografia di prodotto, graphic design, illustrazione, concept art — stanno diventando accessibili a chiunque possa descrivere ciò che vuole vedere.
Questo non elimina il valore della creatività umana. Se non altro, lo eleva. Quando l'esecuzione diventa facile, la visione diventa tutto. Le persone che prospereranno in questo nuovo paesaggio non saranno quelle che possono renderizzare le mani più realistiche — l'IA gestisce quello ora. Saranno coloro che hanno qualcosa che vale la pena dire, qualcosa che vale la pena mostrare, qualcosa che muove le persone.
I fotografi che hanno prosperato nella transizione dalla pellicola al digitale non sono stati quelli che hanno resistito al cambiamento. Sono stati quelli che hanno abbracciato nuovi strumenti mantenendo la loro visione artistica. La generazione di immagini AI è lo stesso tipo di transizione, solo più drammatica e veloce.
Le migliori immagini generate dall'IA saranno sempre create da persone che comprendono sia la tecnologia CHE l'arte. Padroneggia gli strumenti, ma non dimenticare mai che gli strumenti servono la visione. La tecnologia amplifica la creatività umana — non la sostituisce.
Pensieri Finali
Thumbnail, grafiche e contenuti social in minuti invece che ore
Fotografia di prodotto, varianti e marketing su scala senza precedenti
Concept rapidi e presentazioni clienti che richiedevano giorni
Accesso programmatico robusto per costruire applicazioni abilitate alle immagini
Il linguaggio naturale rende l'ingresso più facile rispetto agli strumenti di design tradizionali
Qualità e coerenza sufficienti per il lavoro commerciale
Ho iniziato questo viaggio frustrato e scettico. Avevo sentito l'hype sulla generazione di immagini AI ma ho colpito ripetutamente il muro tra le promesse del marketing e la realtà pratica. Dita con un'anatomia impossibile. Testo che si scioglieva in forme astratte. Composizioni che combattevano attivamente le mie intenzioni. Ero pronto a liquidare tutto come tecnologia sopravvalutata.
Poi ho imparato a parlare la lingua della macchina. Ho smesso di descrivere ciò che volevo vedere e ho iniziato a descrivere ciò che una fotocamera avrebbe catturato. Ho smesso di sperare nella fortuna e ho iniziato a costruire sistematicamente. Ho smesso di combattere il modello e ho iniziato a collaborare con esso.
GPT Image 1.5 non ha solo migliorato i problemi precedenti — ha cambiato radicalmente la mia relazione con la creazione visiva. Ora penso in termini di prompt e iterazioni piuttosto che pennelli e livelli. Affronto le sfide visive con la fiducia che c'è una struttura di prompt che produrrà ciò di cui ho bisogno. Le immagini che creo oggi avrebbero richiesto giorni per essere prodotte solo due anni fa. Le idee che posso esplorare sono limitate solo dall'immaginazione, non dall'abilità tecnica.
La curva di apprendimento è reale. Non padroneggerai questo dall'oggi al domani. Ma i principi in questa guida — struttura sopra parole chiave, specificità sopra superlativi, iterazione sopra perfezione, la mentalità fotografica — comprimeranno settimane di sperimentazione frustrante in apprendimento mirato e produttivo.
Più di ogni altra cosa, spero che questa guida ti dia ciò che avrei voluto avere quando ho iniziato: non solo tecniche, ma un modello mentale. Una comprensione di come questa tecnologia interpreta il linguaggio, a cosa risponde e come parlare fluentemente il suo linguaggio visivo.
Il divario tra le immagini nella tua mente e le immagini sul tuo schermo non è mai stato così piccolo. E con l'approccio giusto, quel divario continua a ridursi con ogni prompt che scrivi.
Ora vai a fare qualcosa di bello.
Ricordo quel momento delle 2 di notte quando tutto ha fatto clic — quando l'immagine che è apparsa non era solo accettabile, ma esattamente ciò che avevo immaginato. Quella sensazione è disponibile per te ora. La tecnologia è arrivata. Le tecniche sono documentate. L'unica cosa rimasta è la tua immaginazione e la tua volontà di imparare una nuova lingua. Il generatore di immagini ChatGPT non è solo uno strumento — è un partner creativo che amplifica la visione umana in modi che stiamo appena iniziando a capire. Benvenuto nel futuro della creazione visiva. Le immagini che hai visto nella tua mente? Sono più vicine alla realtà di quanto non lo siano mai state.

Discussione
0 commentiLascia un commento
Sii il primo a condividere i tuoi pensieri!