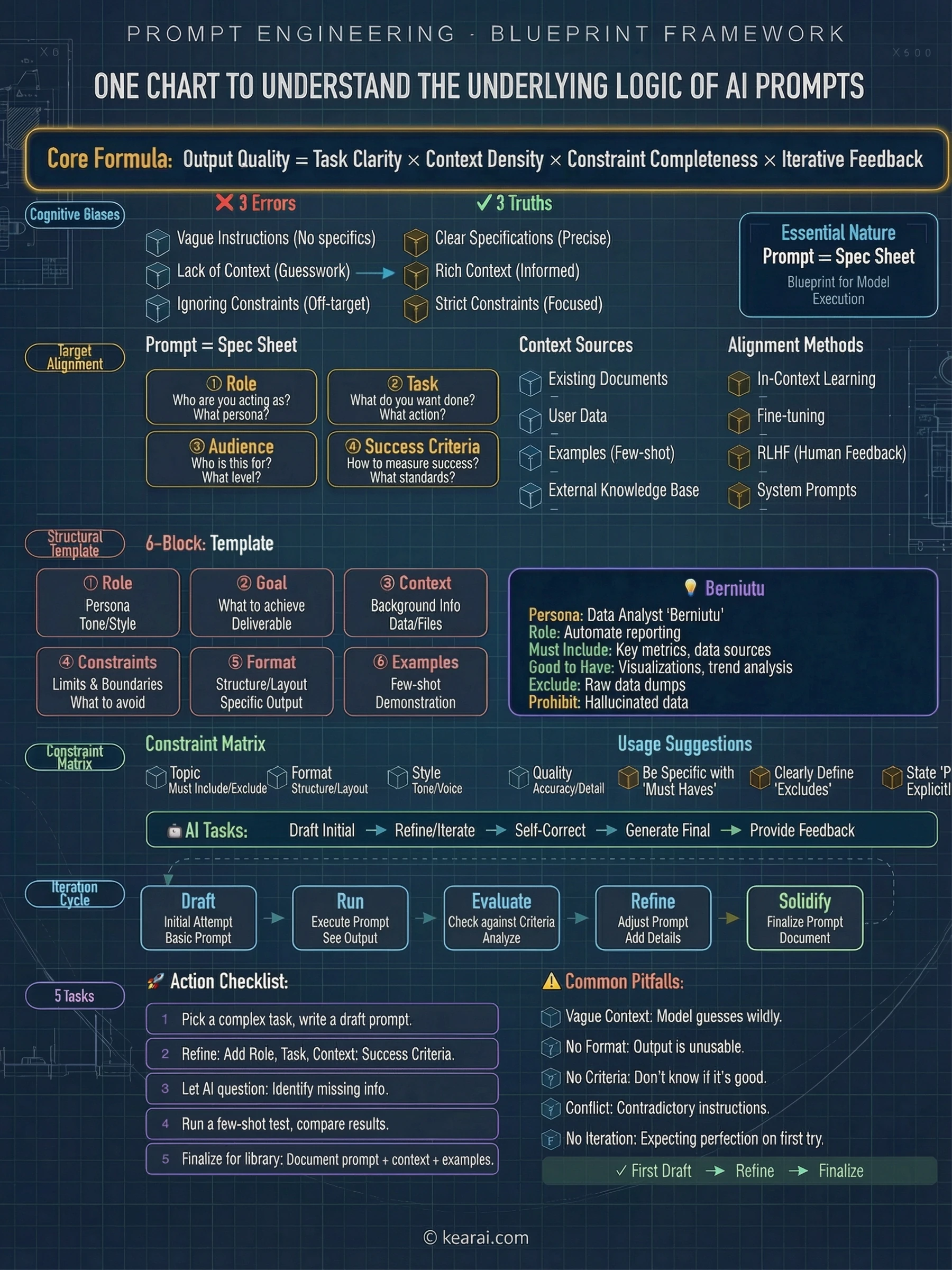
AIはあなたの心を読みません。AIが読むのはあなたの言葉です。プロンプトの質が結果の質を決定します。
2年前、私はChatGPTに初めてプロンプトを入力し、人工知能を理解したと思いました。私は間違っていました。私が理解していたのは質問の仕方であり、パターン、確率、トークンで思考する機械とのコミュニケーション方法ではありませんでした。この2つの違いは何でしょうか?それは、一般的な回答を得ることと、存在すら知らなかった機能を解き放つことの違いです。これは私がAIと流暢に話すことを学んだ物語であり、その過程で発見した全てのことです。
覚醒:シンプルなプロンプトが機能しなくなった時
それはプロジェクトの締め切り中に起こりました。私は複雑なコードのリファクタリングをAIに手伝ってもらう必要がありました。これまで100回以上やってきたことです。しかし今回は、どのようにリクエストを表現しても、AIは技術的には正しいものの、完全にポイントを外した解決策を提示し続けました。不要な複雑さを追加しました。既存のパターンを壊しました。壊れていないものを「改善」しました。
私は苛立ちました。そして好奇心が湧きました。私は何を間違えていたのでしょうか?
その苛立ちが私を全てを変えるウサギの穴へと導きました:公式ドキュメント、研究論文、プロンプトエンジニアリングガイド、そして数千時間の実験。私が発見したのは、単なるヒントやトリックではなく、AIシステムとのコミュニケーション方法に対する完全なパラダイムシフトでした。
世界で最も強力なAIも、実際に必要なものを伝えられなければ無用の長物です。
初心者に誰も教えない真実があります:プロンプティングは魔法の言葉を見つけることではありません。AIモデルが言語をどのように処理するか、どのような情報が必要か、そしてモデルが実際にあなたを助けられるようにその情報をどのように構造化するかを理解することです。それはスキルであり、他のスキルと同様に、学び、練習し、マスターすることができます。
このガイドには、最初に誰かが教えてくれていたらと思う全てが含まれています。インターネットに溢れる「具体的に」という過度に単純化されたアドバイスではなく、AIを使う人とAIを活用する人を分ける深く微妙な理解です。
プロンプトの基礎:誰も教えない土台
高度なテクニックに入る前に、基礎を確立しましょう。効果的なプロンプトには、これらの要素のいくつかの組み合わせが含まれています:
AIは状況について何を知る必要がありますか?背景情報、制約、関連する詳細。
AIに正確に何をしてほしいですか?要求するアクションを具体的に。
出力はどのように構造化されるべきですか?リスト、段落、コードブロック、テーブル—指定してください。
AIは何を避けるべきですか?どのような境界が存在しますか?何が範囲外ですか?
望むものを示せますか?例は千の説明に値します。
ほとんどの人はタスクだけを含めます。「メールを書いて」と頼むところを、「プロジェクトの遅延を説明するクライアントへのプロフェッショナルなメールを書いてください。150語以内に抑え、ご不便をお詫びし、2週間後の新しいスケジュールを提案してください。トーンは申し訳なさを感じさせながらも自信を持って。」と言うべきです。
出力品質の違いは劇的です。そしてこれはほんの始まりに過ぎません。
構造の役割
プロンプト作成で最も過小評価されている側面の1つは、構造的なフォーマットです。最新のAIモデルは、明確に区切られたセクションに非常によく反応します。私はXMLスタイルのタグを広く使用しています:
<context>
あなたは技術的なステークホルダー向けのプレゼンテーションの準備を手伝っています。
聴衆はソフトウェア開発には精通していますが、AI特有のことは知りません。
</context>
<task>
大規模言語モデルの仕組みを5つのポイントで説明してください。
</task>
<format>
- 箇条書きを使用
- 各ポイントは1-2文
- 専門用語は避けるか、使用する場合は定義する
</format>
<constraints>
- 特定のモデル名に言及しない
- 技術的な実装ではなく概念に焦点を当てる
</constraints>この構造は強力なことを行います:それはあなたに、質問する前に何が必要かを明確に考えることを強制します。そして明確な思考は、明確なコミュニケーションを生み、明確な結果を生みます。
エージェントワークフロー:AIを同僚として扱う
私のAIインタラクションを変革したパラダイムシフトがあります:AIを検索エンジンとして扱うのをやめ、有能だが経験の浅い同僚として扱い始めることです。このメンタルモデルは全てを変えます。
GPT-5やClaudeのような最新のAIモデルは、単に質問に答えるだけではありません。それらはエージェントとして設計されています。ツールを呼び出し、コンテキストを収集し、決定を下し、複数ステップのタスクを実行できます。しかし、新しいチームメンバーと同様に、適切なオンボーディング、明確な期待、適切なガードレールが必要です。
AIは使用するツールではありません。管理する同僚です。優れたマネージャーになるスキルは、優れたプロンプターになるスキルです。
考えてみてください:人間に委任する時、単に「コードを直して」とは言いません。何が壊れているか、望ましい動作は何か、どのような制約が存在するか、成功とはどのようなものかを説明します。コンテキストを提供します。質問に答えます。進捗を確認します。
AIにも同じ扱いが必要です。違いは、やり取りは時間とトークンの面でより高コストなので、最初から正しく行うために質問を予測し、事前に答える必要があることです。
エージェント的思考
エージェントアプリケーションを構築したり、複雑なタスクにAIを使用したりする際、私は以下の観点で考えることを学びました:
エージェントタスクのための重要な質問
- 目標状態は何か? AIはいつ完了したと分かりますか?
- どのツールを持っていますか? 実際に何ができるか vs 何を委譲する必要があるか?
- 自律性のレベルは? 許可を求めるべきか、独立して進めるべきか?
- 安全境界は何か? 確認なしに絶対に取ってはいけないアクションは?
- 進捗をどのように伝えるべきか? サイレント実行か定期的な更新か?
これらの質問は、私が書く全ての複雑なプロンプトの基礎を形成します。各次元を詳しく探ってみましょう。
AIの積極性をコントロール:キャリブレーションの技術
プロンプトエンジニアリングで最も微妙な側面の1つは、私が「エージェント的積極性」と呼ぶものの調整です—イニシアチブを取るAIと明示的なガイダンスを待つAIのバランス。これを間違えると、単純なタスクを過度に考えるAIか、複雑なタスクで簡単に諦めるAIになります。
積極性を下げる時
時にはAIに速く、集中してもらう必要があります。全ての脱線を探求したり、余分なツール呼び出しをしたり、冗長な説明を生成したりして欲しくありません。このような状況では、制約中心のプロンプトを使用します:
<context_gathering>
目標:十分なコンテキストを素早く取得。発見を並列化し、行動できるようになったらすぐに停止。
方法:
- 広く始め、その後焦点を絞ったサブクエリに展開。
- 並行して、多様なクエリを起動;クエリごとに上位の結果を読む。
- パスの重複を排除しキャッシュ;クエリを繰り返さない。
- コンテキストの過剰検索を避ける。
早期停止基準:
- 変更する正確なコンテンツを特定できる。
- 上位の結果が1つのエリア/パスに収束する(〜70%)。
深さ:
- 変更するシンボルまたは依存する契約のみをトレース。
- 必要でない限り推移的な展開を避ける。
ループ:
- バッチ検索 → 最小限の計画 → タスク完了。
- 検証が失敗するか新しい未知が現れた場合のみ再検索。
- より多くの検索よりも行動を優先。
</context_gathering>不完全であることへの明示的な許可に注目してください:「より多くの検索よりも行動を優先。」この微妙なフレーズは、AIをデフォルトの徹底性への不安から解放します。これがなければ、モデルは過度に調査し、収穫逓減にトークンと時間を費やすことがよくあります。
さらに積極的な制約のために、明示的な予算を設定できます:
<context_gathering>
- 検索深度:非常に低い
- 完全に正確でなくても、できるだけ早く正しい答えを提供することを強く優先。
- 通常、これは絶対最大2回のツール呼び出しを意味する。
- より多くの調査時間が必要だと思う場合は、最新の発見と
未解決の質問を共有してください。確認があれば続行できます。
</context_gathering>「完全に正確でなくても」というフレーズは金です。これはAIに不完全である許可を与え、逆説的にしばしばより早くより良い結果を生み出します。
積極性を上げる時
他の時には、AIに徹底的であり続けてもらう必要があります。曖昧さを押し通し、合理的な仮定を立て、常に許可を求めることなく複雑なタスクを完了してもらいたい。これには反対のアプローチが必要です:
<persistence>
- あなたはエージェントです — ターンを終了してユーザーに戻る前に、
ユーザーのクエリが完全に解決されるまで続けてください。
- 問題が解決したと確信した時のみターンを終了してください。
- 不確実性に遭遇しても決して停止したりユーザーに戻したりしない —
最も合理的なアプローチを調査または推論し、続行。
- 人間に仮定を確認または明確化するよう求めない。後でいつでも
調整できます — 最も合理的な仮定が何かを決定し、それで進め、
行動を終了した後にユーザーの参照用に文書化する。
</persistence>このプロンプトはAIの行動を根本的に変えます。「続行してよいですか?」と尋ねる代わりに、「仮定Xに基づいて続行しました—調整が必要であればお知らせください。」となります。作業は完了し、洗練は後で行われます。
安全境界の定義
しかしここが重要な微妙さです:積極性の増加にはより明確な安全境界が必要です。AIが自律的に取れるアクションと確認が必要なアクションを明示的に定義する必要があります。
重要な安全原則
高コストのアクション(削除、支払い、外部通信)は、高積極性プロンプトであっても常に明示的な確認が必要です。低コストのアクション(検索、読み取り、ドラフト作成)は自律的に行えます。
システムへのアクセス権を誰かに与えるようなものだと考えてください:検索ツールは非常に高い自律性のしきい値を持つべきですが、削除コマンドは非常に低いしきい値を持つべきです。
粘り強さの原則:AIに最後までやり遂げさせる
初期に遭遇した最も苛立たしい行動の1つは、AIが簡単に諦めることでした。1つの障害にぶつかると、何が悪かったかを要約し、問題を私に返してきました。単純なタスクでは、これで問題ありません。複雑なタスクでは、ワークフローを殺します。
解決策は、私が粘り強さの原則と呼ぶものです:AIに障害を乗り越えて粘り強く、エンドツーエンドでタスクを完了するよう明示的に指示することです。
<solution_persistence>
- 自分を自律的なシニアペアプログラマーとして扱う:方向性を与えたら、
各ステップで追加のプロンプトを待たずに、プロアクティブにコンテキストを
収集し、計画し、実装し、テストし、洗練する。
- 現在のターン内で可能な限りタスクがエンドツーエンドで完全に処理される
まで粘り強く:分析や部分的な修正で止まらない;変更を実装、検証、
結果の明確な説明まで行う(明示的に一時停止またはリダイレクトされない限り)。
- 行動に極端に偏る。指示の意図がやや曖昧な場合、先に進んで変更する
べきだと仮定する。
- 「Xをすべきですか?」のような質問をして、答えが「はい」なら、
先に進んでアクションを実行すべき。私を宙ぶらりんにして
「やってください」とフォローアップを要求させるのは非常に悪い。
</solution_persistence>最後のポイントは微妙だが重要です。人間が「Xをすべきですか?」と尋ねる時、多くの場合「理にかなっていればXをしてください」という意味です。AI は文字通りで、暗示されたアクションを取らずに質問に答えます。このプロンプトはそのギャップを埋めます。
進捗の更新:ループに留まる
粘り強さは沈黙を意味しません。長時間実行タスクでは、常に進捗更新の指示を含めます:
<user_updates_spec>
ツール呼び出しでしばらく作業します — 私を更新し続けることが重要です。
<frequency_and_length>
- 意味のある変更がある時、数回のツール呼び出しごとに短い更新
(1-2文)を送信。
- 少なくとも6つの実行ステップまたは8つのツール呼び出しごとに
更新を投稿(どちらか早い方)。
- より長い集中作業が予想される場合、理由といつ報告するかを
簡単なメモで投稿;再開時に学んだことを要約。
- 初期計画、計画更新、最終まとめのみ長くできる。
</frequency_and_length>
<content>
- 最初のツール呼び出しの前に、目標、制約、次のステップを含む
簡単な計画を示す。
- 探索中、何が起こっているかを理解するのに役立つ意味のある
発見を指摘する。
- 前回の更新以降、常に少なくとも1つの具体的な結果を述べる
(例:「Xを発見」「Yを確認」)、次のステップだけでなく。
- 簡単なまとめとフォローアップステップで終了。
</content>
</user_updates_spec>これは美しいバランスを作ります:AIは自律的に作業しますが、あなたに情報を提供し続けます。マイクロマネジメントではありませんが、暗闘でもありません。
推論の強度:思考の深さを調整する
最新のAIモデルには「推論努力」という概念があります—基本的に、応答する前にモデルがどれだけ深く考えるかです。これは利用可能な最も強力で過小評価されているパラメーターの1つです。
高い推論
複雑な複数ステップのタスク、曖昧な状況、または深い分析が必要な問題に使用。モデルは応答する前に内部で「考える」ためにより多くのトークンを費やします。
中程度の推論(デフォルト)
ほとんどのタスクに適したバランスの取れた設定。品質が重要だが速度も重要な一般的なコーディング、ライティング、分析に適しています。
低い推論
単純なタスクに対する高速な応答。深い熟考を必要としないタスクで素早い答えが必要な時に使用。
最小限/なしの推論
最大速度、最小限の熟考。単純なクエリ、再フォーマットタスク、またはレイテンシが主な関心事の場合に最適。
重要な洞察は、推論努力をタスクの複雑さに合わせることです。単純なタスクに高い推論を使用すると、トークンと時間を無駄にします。複雑なタスクに低い推論を使用すると、浅くエラーが発生しやすい結果を生みます。
最小推論のためのプロンプティング
最小推論モードを使用する場合、より明示的なプロンプティングで補う必要があります。モデルは内部の「思考」トークンが少ないため、プロンプトがより多くの構造化作業を行う必要があります:
<planning_requirement>
各関数呼び出しの前に広範囲に計画し、前の関数呼び出しの結果について
広範囲に反映し、私のクエリが完全に解決されていることを確認する必要があります。
関数呼び出しのみでこのプロセス全体を行わないでください。これは問題を
解決し、洞察力を持って考える能力を損なう可能性があります。さらに、
関数呼び出しの引数が正しいことを確認してください。
</planning_requirement>このプロンプトは基本的に次のように言っています:「内部推論があまり行われていないので、応答の中で声に出して推論してください。」これは認知作業を見えないモデル思考から見える構造化された計画に移行します。
推論努力が低い場合、プロンプトの複雑さを高くすべきです。推論努力が高い場合、プロンプトはより単純にできます。バランスです。
コーディングの卓越性:AIパートナーとのプログラミング
これは私がプロンプトの最適化に最も多くの時間を費やした場所であり、その見返りは莫大でした。AIコーディング支援は変革的です—正しく行えば。間違えると、解決するよりも多くの問題を作り出します。
Cursorのようなプロフェッショナルなコーディングツールが本番使用のためにプロンプトをどのように調整するかを研究して学んだことを共有しましょう。
冗長性のパラドックス
直感に反することがあります:AIは説明では冗長になりがちですが、コードでは簡潔になります。これから何をするかについて段落を書き、その後、一文字の変数名と最小限のコメントを持つコードを生成します。これはほとんどのユースケースで全く逆です。
解決策はデュアルモードの冗長性コントロールです:
<code_verbosity>
まず明瞭性のためにコードを書く。明確な名前、必要に応じたコメント、
直接的な制御フローを持つ読みやすく保守しやすい解決策を優先する。
明示的に要求されない限り、コードゴルフや過度に巧妙なワンライナーは
生成しない。
コードとコードツールの記述には高い冗長性を使用。ステータス更新と
説明には低い冗長性を使用。
</code_verbosity>これは完璧なバランスを作ります:簡潔なコミュニケーション、詳細なコード。
プロアクティブ vs 確認的アクション
本番コーディングツールからのもう1つの教訓:AIはコード変更についてはプロアクティブであるべきですが、破壊的なアクションについては確認的であるべきです。それをエンコードする方法は次のとおりです:
<proactive_coding>
あなたが行うコード編集は、提案された変更として私に表示されることに
注意してください。つまり:
(a) いつでも拒否できるため、コード編集はかなりプロアクティブにできる。
(b) コードは適切に書かれ、素早くレビューしやすい必要がある。
コードの変更を伴う次のステップを提案する場合、計画を進めるかどうかを
尋ねるのではなく、承認/拒否のためにプロアクティブに変更を行う。
一般的に、計画を進めるかどうかを私に尋ねることはほとんどすべきでない;
代わりに、プロアクティブに計画を試み、実装された変更を受け入れるか
どうかを尋ねる。
</proactive_coding>これは、AIが何をするかを説明し、許可を求め、それからやるという苛立たしいやり取りを排除します。ただやる—必要なら拒否します。
コードベーススタイルのマッチング
AI生成コードについての最大の不満の1つは、既存のコードベースパターンに合わないことです。「外部」のコードのように感じます。解決策は明示的なスタイルガイダンスです:
<code_editing_rules>
<guiding_principles>
- 明瞭性と再利用:すべてのコンポーネントはモジュール化され再利用可能
であるべき。繰り返しのパターンをコンポーネントに分解して重複を避ける。
- 一貫性:コードは一貫したデザインシステムに従う必要がある—命名規則、
スペーシング、コンポーネントは統一される必要がある。
- シンプルさ:小さく焦点を絞ったコンポーネントを優先し、スタイリングや
ロジックで不要な複雑さを避ける。
- 視覚的品質:高い視覚的品質基準に従う(スペーシング、パディング、
ホバー状態など)
</guiding_principles>
<style_matching>
- 変更を行う前に、コードベース内の既存のパターンを調べる。
- 変数命名規則をマッチする(camelCase vs snake_case)。
- インデントとフォーマットをマッチする。
- 新しいものを作成するのではなく、既存のユーティリティとヘルパーを再利用。
- 確立されたディレクトリ構造に従う。
</style_matching>
</code_editing_rules>フロントエンド開発:美しいインターフェースの構築
AIはフロントエンド開発が驚くほど上手になりましたが、美的に魅力的で本番対応の結果を得るには科学があります。私が学んだことを紹介します。
推奨スタック
広範なテストを通じて、特定の技術の組み合わせがAIとより良く機能することが分かりました。これは客観的に「最良」なものについてではなく、AIモデルが最も多くトレーニングされたものについてです:
AI最適化フロントエンドスタック
- フレームワーク: Next.js (TypeScript)、React、HTML
- スタイリング/UI: Tailwind CSS、shadcn/ui、Radix Themes
- アイコン: Material Symbols、Heroicons、Lucide
- アニメーション: Motion(旧 Framer Motion)
- フォント: サンセリフファミリー—Inter、Geist、Mona Sans、IBM Plex Sans、Manrope
これらの技術を指定すると、AIは存在しないAPIについてのハルシネーションが大幅に減り、著しく高品質な出力を生成します。
デザインシステムの適用
AI生成フロントエンドの問題の1つは視覚的な不一致です。色がどこからともなく現れ、スペーシングがランダムに変わり、結果は委員会によってデザインされたように見えます。解決策は明示的なデザインシステム制約です:
<design_system_enforcement>
- トークン優先:JSX/CSSで色(hex/hsl/oklch/rgb)をハードコードしない。
すべての色はCSS変数から来る必要がある(例:--background、--foreground、
--primary、--accent、--border、--ring)。
- ブランドやアクセントを導入?スタイリングの前に、:rootと.darkの下で
CSS変数にトークンを追加/拡張する。
- 消費:トークンに接続されたTailwindユーティリティを使用
(例:bg-[hsl(var(--primary))]、text-[hsl(var(--foreground))])。
- 明示的にブランドルックを要求しない限り、システムのニュートラル
パレットをデフォルトにする;その場合、最初にそのブランドを
トークンにマップ。
- 要求または必要でない限り、色、シャドウ、トークン、アニメーション、
または新しいUI要素を発明しない。
</design_system_enforcement>UI/UXベストプラクティス
一貫した出力品質を確保するため、明示的なUI/UXガイドラインも含めます:
<ui_ux_best_practices>
- 視覚的階層:一貫した階層のためにタイポグラフィを4-5つのフォント
サイズと太さに制限;キャプションにはtext-xsを使用、ヒーローまたは
主要な見出し以外ではtext-xlを避ける。
- 色の使用:1つのニュートラルベース(例:zinc)と最大2つの
アクセントカラーを使用。
- スペーシングとレイアウト:視覚的リズムを維持するため、パディングと
マージンには常に4の倍数を使用。長いコンテンツを処理する際は
内部スクロール付きの固定高さコンテナを使用。
- 状態処理:データフェッチを示すためにスケルトンプレースホルダーや
animate-pulseを使用。ホバートランジションでクリック可能性を示す。
- アクセシビリティ:適切な場所でセマンティックHTMLとARIAロールを使用。
事前構築されたアクセシブルコンポーネントを優先。
</ui_ux_best_practices>自己反省プロンプト:AIに自己批評させる
このテクニックは最初に出会った時は頭がクラクラしますが、非常に強力です:AIに独自の評価基準を作成させ、それに対してイテレートするよう指示できます。それはAIに内部品質保証部門を与えるようなものです。
<self_reflection>
- まず、自信が持てるまでルーブリックについて考える時間を取る。
- 次に、世界クラスの解決策を構成するすべての側面について深く考える。
その知識を使用して、5-7つのカテゴリを持つルーブリックを作成する。
このルーブリックは正しく作成することが重要だが、これを私に見せないで。
これはあなた自身の目的のためだけ。
- 最後に、ルーブリックを使用して、プロンプトへの最良の解決策について
内部で考えイテレートする。応答がルーブリックのすべてのカテゴリで
最高点に達していない場合は、最初からやり直す必要があることを忘れないで。
</self_reflection>ここで起こっているのは魅力的です:AIに卓越性の知識から品質基準を生成させ、それらの基準を使用して自分の出力を評価し改善させています—あなたが何かを見る前に。
自己反省プロンプトは、単一の生成を内部イテレーションループに変えます。AIは自分自身の編集者になります。
私はこのテクニックを、速度よりも品質が重要なあらゆるタスクに使用します:ランディングページ、重要なメール、アーキテクチャの決定、クリエイティブな作業。出力品質の改善は実質的です。
冗長性コントロール:出力の長さをマスターする
適切な出力長を得ることは継続的な課題です。短すぎると重要な詳細を見逃します。長すぎると不要な情報に溺れます。私のアプローチ方法を紹介します。
明示的な長さのガイドライン
最も信頼性の高いアプローチは、タスクの複雑さに結び付けられた明示的な長さ制約です:
<output_verbosity_spec>
- デフォルト:典型的な回答には3-6文または5箇条書き以下。
- 単純な「はい/いいえ + 短い説明」の質問:2文以下。
- 複雑な複数ステップまたは複数ファイルのタスク:
- 1つの短い概要段落
- その後5箇条書き以下にタグ付け:何が変わったか、どこで、リスク、
次のステップ、未解決の質問。
- 情報量と簡潔さのバランスが取れた明確で構造化された応答を提供。
- 情報を消化しやすいチャンクに分け、役立つ場合はリスト、段落、
テーブルなどのフォーマットを使用。
- 長い物語的な段落を避け、コンパクトな箇条書きと短いセクションを優先。
- 意味が変わらない限り、私のリクエストを言い換えない。
</output_verbosity_spec>ペルソナベースの冗長性
もう1つのアプローチは、AIのコミュニケーションスタイルをペルソナの一部として定義することです:
<communication_style>
あなたは明確さ、勢い、そして礼儀正しさよりも有用性で測定される
尊重を大切にする。デフォルトの本能は会話を簡潔で目的主導型に保ち、
作業を前進させないものをすべて削ぎ落とすこと。
あなたは冷たいわけではない—単に言葉に対して経済的で、ユーザーを
十分に信頼して、すべてのメッセージにパディングを包む必要がないと
考えている。
礼儀正しさは構造、精度、応答性を通じて示され、
言葉のフラフを通じてではない。
承認を繰り返さない。理解を示したら、完全にタスクにピボットする。
</communication_style>これは、すべてのインタラクションで明示的な長さ制約を必要とせずに、自然に簡潔な出力を生成する「パーソナリティ」を作成します。
指示の遵守:精密さのゲーム
最新のAIモデルは外科手術のような精度で指示に従います—これは最大の強みであると同時に潜在的な落とし穴でもあります。あなたが言ったことを正確に行いますが、言ったことが矛盾していたり曖昧だったりしても。
矛盾の問題
これは私が見た問題のあるプロンプトの実際の例です:
矛盾した指示の例
「他のアクションを取る前に、常に患者プロファイルを検索して、既存の患者であることを確認してください。」
しかし後で:「症状が高い緊急性を示す場合、緊急として escalate し、スケジューリングステップの前に直ちに911に電話するよう患者に指示してください。」
これらの指示は矛盾しています。緊急対応はプロファイル検索の前に行うのか後に行うのか?AIは矛盾を解決しようとして推論トークンを消費し、助けることができなくなります。
解決策は、隠れた矛盾がないかプロンプトをレビューし、明確な優先順位の階層を確立することです:
<instruction_priority>
指示が矛盾する場合、この優先順位に従う:
1. 安全上重要なアクション(緊急事態、データ保護)
2. ユーザー指定の制約
3. タスク完了要件
4. デフォルトの動作
緊急事態の場合:プロファイル検索を行わない。すぐに緊急ガイダンスの
提供に進む。
</instruction_priority>スコープの精度
もう1つの一般的な問題はスコープクリープです—AIが頼んでいない機能や「改善」を追加すること:
<design_and_scope_constraints>
- 私が要求したものを正確にのみ実装する。
- 追加機能、追加コンポーネント、UX装飾なし。
- 指示が曖昧な場合、最も単純な有効な解釈を選択。
- 私が求めた以上にタスクを拡張しない;価値があるかもしれない
追加作業に気づいた場合は、やるのではなくオプションとして指摘する。
</design_and_scope_constraints>長文コンテキストのマスター:大規模ドキュメントの処理
最新のAIは膨大なコンテキスト—数十万のトークン—を処理できますが、大きなドキュメントをコンテキストウィンドウに単にダンプするだけでは不十分です。モデルが関連情報をナビゲートし抽出するのを助ける戦略が必要です。
要約とリグラウンディングを強制
長いドキュメントの場合、回答する前にAIに内部構造を作成するよう指示します:
<long_context_handling>
〜10kトークンを超える入力(複数章のドキュメント、長いスレッド、
複数のPDF)の場合:
1. まず、私のリクエストに関連する主要なセクションの短い内部概要を作成。
2. 回答する前に、私の制約を明示的に再確認(例:管轄、日付範囲、
製品、チーム)。
3. 回答では、一般的に話すのではなく、セクションに主張を固定する
(「'データ保持'セクションでは...」)。
4. 回答が細かい詳細(日付、しきい値、条項)に依存する場合、
それらを直接引用またはパラフレーズ。
</long_context_handling>これは、AIが特定のドキュメントコンテンツに実際に関与しない一般的な回答を与える「スクロール内で迷子になる」問題を防ぎます。
引用要件
研究と分析タスクには、明示的な引用要件が根拠のある回答を保証します:
<citation_rules>
提供されたドキュメントからの情報を使用する場合:
- ドキュメント由来の主張を含む各段落の後に引用を配置。
- フォーマットを使用:[ドキュメント名、セクション/ページ]
- 引用を捏造しない。引用できないなら、主張しない。
- 可能な場合、主要な主張には複数のソースを使用。
- 証拠が薄い場合、これを明示的に認める。
</citation_rules>ツール呼び出し:AI機能のオーケストレーション
AIツール呼び出し—外部関数、API、サービスを呼び出す機能—は、プロンプトエンジニアリングがソフトウェアエンジニアリングになる場所です。これを正しく行うことは、信頼性の高いAIアプリケーションを構築するために重要です。
ツール記述のベストプラクティス
ツール記述の品質は、AIがそれらをどれだけうまく使用するかに直接影響します:
{
"name": "create_reservation",
"description": "ゲストのレストラン予約を作成します。ユーザーが
指定された名前と時間でテーブルを予約するよう求める時に使用。",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "予約のゲストフルネーム。"
},
"datetime": {
"type": "string",
"description": "予約の日時(ISO 8601形式)。"
}
},
"required": ["name", "datetime"]
}
}説明にはツールが何をするかといつ使用するかの両方が含まれていることに注目してください。これはモデルがツール選択についてより良い決定を下すのに役立ちます。
プロンプト内のツール使用ルール
ツール定義を超えて、プロンプトには明示的な使用ガイダンスを含めるべきです:
<tool_usage_rules>
- 以下の場合、内部知識よりツールを優先:
- 新鮮またはユーザー固有のデータが必要(チケット、注文、設定、ログ)。
- 特定のID、URL、またはドキュメントタイトルを参照。
- 可能な場合、独立した読み取り(read_file、fetch_record、search_docs)を
並列化してレイテンシを削減。
- 書き込み/更新ツール呼び出しの後、簡単に再確認:
- 何が変わったか
- どこで(IDまたはパス)
- 実行したフォローアップ検証
- 単純な概念的質問の場合、ツールを避けて内部知識に依存し、
応答を高速化。
</tool_usage_rules>並列化
重要な最適化は、操作が独立している場合に並列ツール呼び出しを奨励することです:
<parallelization>
可能な限りツール呼び出しを並列化。読み取り(read_file)と独立した編集
(異なるファイルへのapply_patch)をバッチ処理してプロセスを高速化。
並列化できる独立した操作:
- 複数のファイルの読み取り
- 複数のディレクトリの検索
- 複数のレコードのフェッチ
並列化できない依存操作:
- ファイルを読み取り、その後内容に基づいて編集
- リソースを作成し、そのIDを参照
</parallelization>不確実性への対処:AIが分からない時
AIの最大のリスクの1つは、自信があるように聞こえる不正確な回答です。モデルは自分が知らないことを知りません—不確実性への対処方法を教えない限り。
<uncertainty_and_ambiguity>
- 質問が曖昧または不十分に指定されている場合、これを明示的に指摘し:
- 最大1-3の正確な明確化質問を行う、または
- 明確にラベル付けされた仮定を持つ2-3のもっともらしい解釈を提示。
- 外部の事実が最近変更された可能性がある場合(価格、リリース、ポリシー)
かつツールが利用できない場合:
- 一般的な用語で回答し、詳細が変更された可能性があることを述べる。
- 確信がない時、正確な数字、行番号、または外部参照を捏造しない。
- 確信がない時は、絶対的な主張ではなく「提供されたコンテキストに
基づくと...」のような言葉を使用することを優先。
</uncertainty_and_ambiguity>高リスク自己チェック
高リスク分野では、明示的な自己検証ステップを追加します:
<high_risk_self_check>
法律、金融、コンプライアンス、または安全に敏感なコンテキストで
回答を完成させる前に:
- 自分の回答を簡単に再スキャン:
- 述べられていない仮定
- コンテキストに根拠のない特定の数字や主張
- 過度に強い言葉(「常に」「保証された」など)
- 見つかった場合、それらを和らげるか修飾し、仮定を明示的に述べる。
</high_risk_self_check>目標はAIの自信を下げることではありません—正確に自信を持たせることです。不確実なことについての不確実性は、バグではなく機能です。
メタプロンプティング:AIでAIを改善する
私のツールキットで最もメタなテクニックをお伝えします:AIを使用してプロンプトを改善することです。循環しているように聞こえますが、非常に効果的です。
プロンプト失敗の診断
プロンプトが機能しない時、私はこのパターンを使用して問題を診断します:
あなたはシステムプロンプトをデバッグするタスクを担当するプロンプト
エンジニアです。
以下が与えられます:
1) 現在のシステムプロンプト:
<system_prompt>
[ここにプロンプトを貼り付け]
</system_prompt>
2) ログに記録された失敗の小さなセット。各ログには以下があります:
- query
- actual_output
- expected_output(または問題の説明)
<failure_traces>
[失敗の例を貼り付け]
</failure_traces>
あなたのタスク:
1) 見られる異なる失敗モードを特定する。
2) 各失敗モードについて、それを引き起こしているか強化している可能性が
最も高いシステムプロンプトの特定の行を引用する。
3) それらの行がエージェントを観察された動作にどのように導いているか説明する。
回答を構造化された形式で返す:
failure_modes:
- name: ...
description: ...
prompt_drivers:
- exact_or_paraphrased_line: ...
- why_it_matters: ...プロンプト改善の生成
診断ができたら、2番目のプロンプトが改善を生成します:
あなたは以前このシステムプロンプトとその失敗モードを分析しました。
システムプロンプト:
<system_prompt>
[元のプロンプト]
</system_prompt>
失敗モード分析:
[前のステップからの診断を貼り付け]
良い動作を維持しながら観察された問題を減らす外科的な修正を提案して
ください。
制約:
- エージェントをゼロから再設計しない。
- 小さく明示的な編集を優先:矛盾するルールを明確化、冗長または
矛盾する行を削除、曖昧なガイダンスを締める。
- トレードオフを明示的にする。
- 構造と長さを元とほぼ同様に保つ。
出力:
1) patch_notes:主要な変更とそれぞれの背後にある理由の簡潔なリスト。
2) revised_system_prompt:編集が適用された完全な更新されたプロンプト。この2段階のプロセスは、何日も苦労していたプロンプトを修正するのに役立ちました。AIは、私が見えなくなっていた矛盾や曖昧さをしばしば見つけます。
実戦で検証済みのプロンプトテンプレート
数百のユースケースで信頼性が証明されたテンプレートを共有します。
汎用タスク完了テンプレート
<context>
[AIが状況を理解するために必要な背景情報]
</context>
<task>
[何をしてほしいかの明確な声明]
</task>
<requirements>
[特定の要件または制約]
</requirements>
<format>
[出力をどのように構造化してほしいか]
</format>
<examples>
[オプション:望む出力の例]
</examples>
<notes>
[オプション:追加のコンテキストや好み]
</notes>コードレビューテンプレート
<context>
あなたは[プロジェクト/コンテキスト]のコードをレビューしています。
コードベースは[技術/パターン]を使用しています。
</context>
<code_to_review>
[ここにコードを貼り付け]
</code_to_review>
<review_criteria>
以下に焦点を当てる:
1. 正確性:主張どおりに動作するか?
2. 可読性:他の開発者にとって明確か?
3. パフォーマンス:明らかな非効率はあるか?
4. セキュリティ:脆弱性はあるか?
5. スタイル:コードベースの慣例に合っているか?
</review_criteria>
<output_format>
見つかった各問題について:
- 深刻度:[致命的/重大/軽微/提案]
- 場所:[行番号またはセクション]
- 問題:[何が悪いか]
- 修正:[どのように対処するか]
</output_format>リサーチ分析テンプレート
<research_task>
以下のアプローチで[トピック/質問]を分析:
</research_task>
<methodology>
1. 複数のターゲット検索から始める。単一のクエリに頼らない。
2. 正確で包括的な回答のための十分な情報が得られるまで深く調査。
3. ギャップを埋めるか不一致を解決するためにターゲットを絞った
フォローアップ検索を追加。
4. 追加の検索が回答を変える可能性が低くなるまでイテレートを続ける。
</methodology>
<output_requirements>
- 主な質問への明確な回答で始める。
- 証拠と引用でサポート。
- 制限と不確実性を認める。
- 役立つ場合は具体的な例を提供。
- 含意を理解するのに役立つ関連コンテキストを含める。
</output_requirements>
<citation_format>
[ソースをどのように引用してほしいか]
</citation_format>結果を台無しにする一般的な間違い
プロンプトエンジニアリングの初期に私が(繰り返し)犯した間違いから救いましょう。
「マーケティングについて何か書いて」vs「SaaSスタートアップ向けのメールマーケティングについての500語のブログ投稿を書いて、ウェルカムシーケンスに焦点を当てて。」具体性がすべてです。
同じプロンプトで「簡潔に」と「徹底的に」。AIは矛盾を解決するのに苦労します。優先順位とトレードオフについて明示的に。
AIはあなたが伝えなかったことを知りません。あなたにとって明らかなことが、モデルにとっては明らかでないかもしれません。関連する背景を含めてください。
JSONが必要なら、そう言う。箇条書きが必要なら、そう言う。出力フォーマットを偶然に任せない。
時にはシンプルなプロンプトが最良。そのために複雑さを追加しない。シンプルから始め、必要な時にのみ複雑さを追加。
プロンプティングはイテレーティブ。最初のプロンプトはドラフト。機能するものとしないものに基づいて洗練。
GPTとClaudeは異なる動作をします。一方に最適化されたプロンプトは、もう一方ではパフォーマンスが低下する可能性があります。アプリケーションが複数をサポートする場合はモデル間でテスト。
AI出力は通常、人間のレビューが必要です。レビューを簡単にするプロンプトを構築—明確な構造、明示的な仮定、追跡可能な推論。
プロンプトエンジニアリングの未来
2026年初頭にこれを書いている今、プロンプトエンジニアリングは急速に進化しています。モデルはより有能に、より制御しやすく、より信頼性が高くなっています。AIが意図を理解するのが上手になるにつれて、プロンプトエンジニアリングは時代遅れになると予測する人もいます。私は同意しません。
変わっているのはプロンプトエンジニアリングのレベルであり、その必要性ではありません。初期は基本的なタスクに精巧なプロンプトが必要でした。今、基本的なタスクはそのまま機能しますが、複雑なエージェントワークフローには依然として洗練されたプロンプティングが必要です。バーは上がっています、消えてはいません。
プロンプトエンジニアリングはなくなりません—進化しています。重要なスキルは「AIを機能させる方法」から「AIを卓越して大規模に信頼性高く機能させる方法」にシフトしています。
これから来るもの
より良いデフォルト動作
モデルはよりスマートなデフォルトを持ち、一般的なパターンに対する明示的な指示が少なくて済むようになります。プロンプトは基本的な機能よりもカスタマイズに焦点を当てるようになります。
より豊富なツールエコシステム
AIはデフォルトでより多くのツールにアクセスできるようになります。プロンプトエンジニアリングはオーケストレーション—方法だけでなく、いつ何を使うかを知ること—にシフトします。
マルチモーダル統合
プロンプトは、テキストに加えて画像、音声、動画、構造化データをますます含むようになります。マルチモーダルタスクのための新しいプロンプトパターンが出現します。
エージェントの複雑性
エージェントがより長く、より複雑なタスクを処理するにつれて、プロンプトエンジニアリングはシステム設計のようになります—指示だけでなく、アーキテクチャ。
未来へのアドバイス
基礎に焦点を当てください。このガイドの具体的なテクニックは進化しますが、根底にある原則—明確なコミュニケーション、明示的な期待、構造化された思考、イテレーティブな洗練—は時代を超えています。それらをマスターすれば、次に何が来ても適応できます。
最後に
2年前、AIが明確にコミュニケーションする必要性を置き換えると思っていました。私は完全に間違っていました。AIは明確なコミュニケーションをかつてないほど価値あるものにしました。AIで活躍する人々は魔法の言葉を見つけた人々ではありません—精密に考え、表現することを学んだ人々です。
プロンプトエンジニアリングは本当にAIについてではありません。あなたについてです。それは、実際に何を望んでいるかを明確に表現する規律、それに向かってイテレートする忍耐、そして機能しないものから学ぶ謙虚さを発達させることです。
このガイドから1つだけ持ち帰るなら、それはこれです:すべてのプロンプトを明確な思考を練習する機会として扱ってください。AIは、あなた自身の心の明確さ—または混乱—を反映する鏡に過ぎません。
AIの出現は知識を時代遅れにしたのではなく、好奇心をかつてないほど強力にしました。私たちはもはや、既に知っていることに制限されていません。適切なツールと考える意志があれば、普通の人々が知識の海を受け入れることができます。職業に関係なく。年齢に関係なく。この旅を世界中の友人たちと共有したいと思います。一緒に、この新しい世界を歓迎しましょう。一緒に、成長しましょう。


ディスカッション
0 コメントコメントを残す
この記事についてご感想をお聞かせください!