
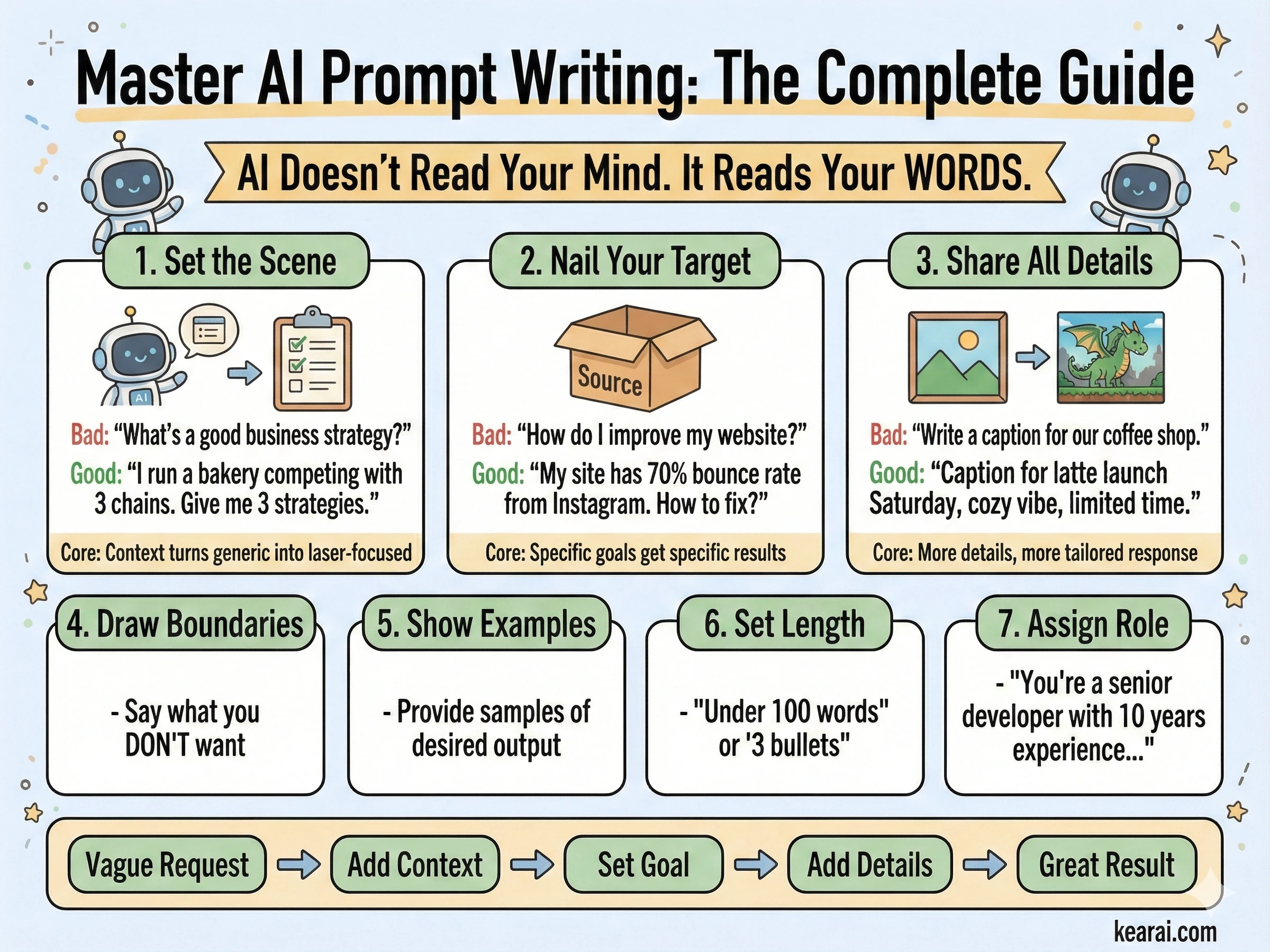
AIはあなたの心を読みません。AIはあなたの言葉を読みます。あなたが欲しいものと、あなたが得るものの間のギャップは、ほとんど常にコミュニケーションの問題であり、AIの制限ではありません。
すべてが変わった瞬間の話をさせてください。私は画面を見つめ、信じられないほどイライラしながら、AIがまたしても技術的には正しいものの、要点を完全に見逃した回答を生成するのを見ていました。私は、これまでに何百回もやったことのある複雑なコードのリファクタリングの手助けを求めていました。しかし今回は、リクエストをどのように言い換えても、AIは不必要な複雑さを追加し続け、既存のパターンを壊し、壊れていないものを「修正」し続けました。このフラストレーションが私をウサギの穴へと導き、そこは私の人生の次の2年間を飲み込み、そして私が人工知能と働く方法を完全に変えました。
目覚め - 知っていたすべてが機能しなくなったとき
自分が何をしているのか全くわかっていないことに気づいた正確な瞬間を覚えています。深夜で、締め切りが迫っており、単純なタスクであるはずのことでAIに助けてもらう必要がありました。私はプロンプトを書き、エンターキーを押し、AIが何かを生成するのを見ましたが、それは私にノートパソコンを窓から投げ捨てたくなるようなものでした。
実際のところ、私はAIを理解していると思っていました。初期の頃からChatGPTを使っていました。プロンプトエンジニアリングに関する記事も読んでいました。「ロールプレイ」や「具体的になること」についても知っていました。しかし、そこにいた私は、私が言ったすべての言葉を聞いたものの、私が本当に必要としていたことを何も理解していない誰かと話しているような感覚の回答を受け取っていました。
このフラストレーションが私の先生になりました。私は公式ドキュメント、研究論文、フォーラムの議論、そして何千時間もの実験に没頭しました。私が発見したのは単なるヒントやコツではありませんでした。それは、パターン、確率、トークンで思考する機械とコミュニケーションをとる方法における完全なパラダイムシフトでした。
世界で最も強力なAIであっても、あなたが本当に必要なことを伝えられなければ役に立ちません。プロンプティングとは魔法の言葉を見つけることではありません。AIが言語をどのように処理するかを理解し、それに応じてコミュニケーションを構造化することです。
初心者に誰も言わない真実はこれです:AIから素晴らしい結果を得る人とそうでない人の違いは、知性や技術的なスキルではありません。それはコミュニケーションです。そしてAIとのコミュニケーションは、人間とのコミュニケーションに似ていますが、決定的に異なるルールに従います。
このガイドには、私がこの旅で学んだすべてが含まれています。インターネットに溢れている「ただ具体的になれ」といった単純化されたアドバイスではなく、AIとの働き方を変える深く、ニュアンスのある理解です。あなたが最初のプロンプトを書いているのであれ、本番用のAIシステムを構築しているのであれ、これに続く内容は、あなたの人工知能との関係を永遠に変えるでしょう。
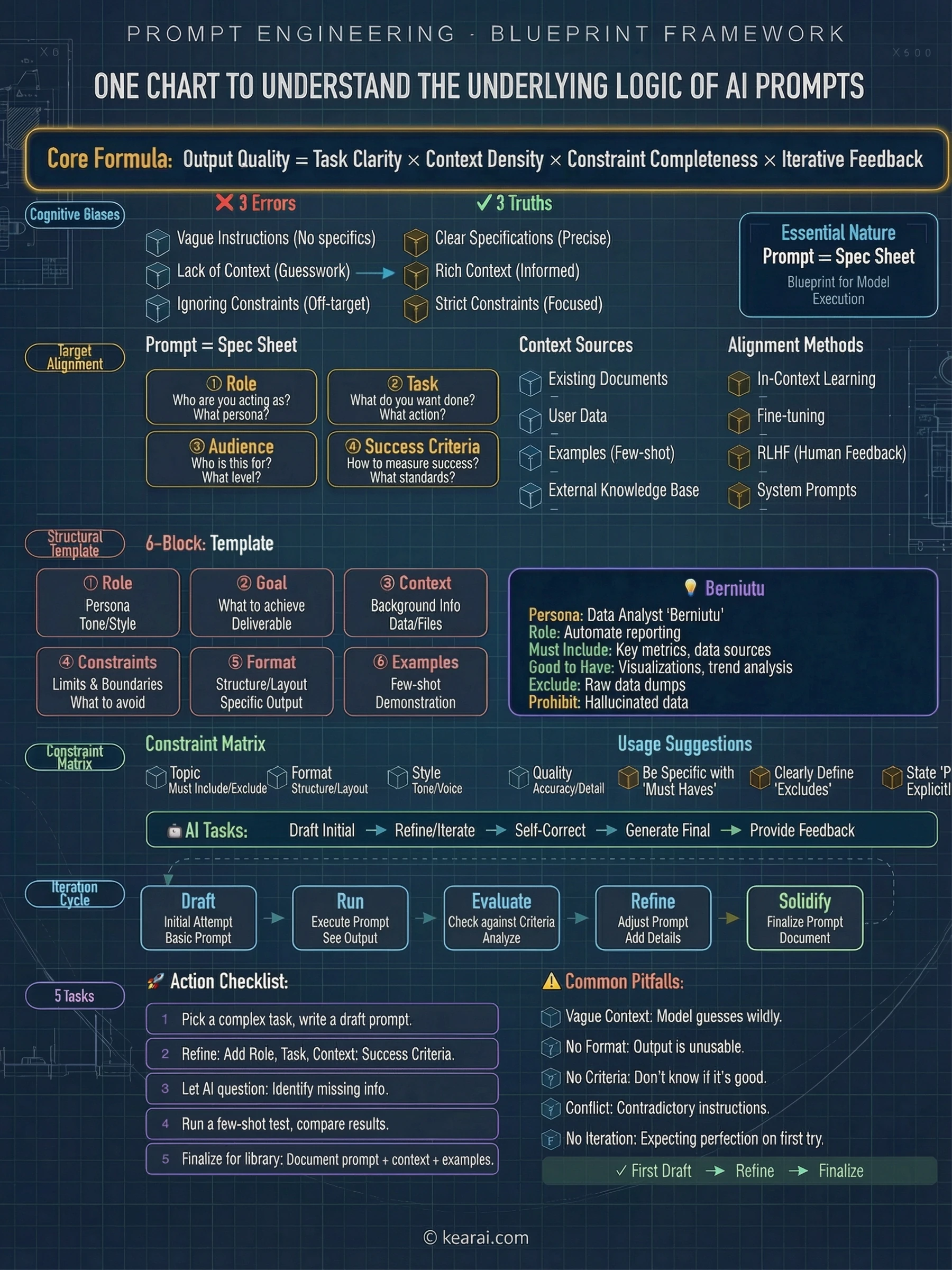
誰も教えてくれない基礎 - プロンプトの核となる解剖学
高度なテクニックに飛び込む前に、私にとってすべてを変えたフレームワークを共有させてください。私が現在書いているすべての効果的なプロンプトには、次の5つの要素の何らかの組み合わせが含まれています。
AIはあなたの状況について何を知る必要がありますか?背景情報、制約、関連する詳細、そしてあなたが作業している環境。
正確にAIに何をしてほしいですか?あなたが要求しているアクションについて具体的にしてください。単なるトピックではなく、実際の作業です。
出力はどのように構造化されるべきですか?リスト、段落、コードブロック、表、JSONなど、明示的に指定してください。
AIは何を避けるべきですか?どのような境界線が存在しますか?明示的に範囲外のものは何ですか?
欲しいものを見せることはできますか?例は千の記述に値します。説明するよりもデモンストレーションしてください。
ほとんどの人はタスクだけを含めます。「メールを書いて」と頼みますが、本来ならこう言うべきです。「プロジェクトの遅延を説明するクライアントへのプロフェッショナルなメールを書いてください。150語以内に抑え、不便を認め、2週間後の新しいタイムラインを提案してください。トーンは謝罪的ですが、自信を持ったものにしてください。」
出力品質の違いは劇的です。そしてそれは始まりに過ぎません。
構造の力
プロンプト作成において最も過小評価されている側面の1つは、構造的なフォーマットです。現代のAIモデルは、明確に区切られたセクションに非常によく反応します。私はXMLスタイルのタグを広く使用しています。なぜなら、それらは曖昧さのない境界を作成するからです。
<context>
あなたは技術的な利害関係者向けのプレゼンテーションの準備を手伝っています。
聴衆はソフトウェア開発には詳しいですが、特にAIについては詳しくありません。
</context>
<task>
大規模言語モデルがどのように機能するかを5つの重要なポイントで説明してください。
</task>
<format>
- 箇条書きを使用する
- 各ポイントは1〜2文にする
- 専門用語を避けるか、使用する場合は定義する
</format>
<constraints>
- 具体的なモデル名には言及しない
- 技術的な実装ではなく、概念に焦点を当てる
- 全体の長さを200語以下に抑える
</constraints>この構造は強力なことをします。それは、尋ねる前に何が必要かをあなたに明確に考えさせるのです。明確な思考は明確なコミュニケーションを生み、明確なコミュニケーションは明確な結果を生みます。XMLタグは魔法ではありません。それらはあなた自身の思考のための足場です。
構造とはプロンプトを長くすることではありません。あなたの意図を曖昧にしないことです。よく構造化された短いプロンプトは、とりとめのない長いプロンプトに常に勝ちます。
すべてを変えた6つのマインドセット
長年の実験を経て、私は自分のアプローチを6つの基本的な「マインドセット」に蒸留しました。これらは厳格なテンプレートではなく、ほとんどの人が決して発見しないAIの能力を解き放つ柔軟な思考パターンです。完璧な言葉を見つけることではありません。正しいメンタルモデルでAIとの対話にアプローチすることです。
マインドセット1:AIに専門家を選ばせる
AIに役割を与えることが役立つことは誰もが知っています。「マーケティングの専門家として振る舞う」と指示すれば、一般的な質問よりも優れたマーケティングのアドバイスが得られます。しかし、ここでほとんどの人が見逃している点があります。あなたの質問にどの専門家が最適かわからない場合、AIに選んでもらうことができるのです。
私は企業のイベントを計画しているときにこれを発見しました。マーケティングの視点が必要なのか、運営の視点が必要なのか、あるいは全く別の何かが必要なのか、見当もつきませんでした。そこで推測する代わりに、AIにまず最も適切な専門家を選ぶように頼みました。
私は[分野]、具体的には[問題/シナリオ]について探求したいです。
まだ答えないでください。
まず、この問題について考えるのに最も適したドメインの専門家を選んでください。
実在する人物でも歴史上の人物でも、有名人でも比較的無名な人物でも構いませんが、
その特定の分野で真に優れていなければなりません。
確信が持てない場合は、選ぶ前に私に2つの状況確認の質問をしてください。
出力:
1. 誰を選んだかとその特定のドメイン
2. なぜ彼らを選んだか(3文で)
その後、私の詳細な質問について説明するように求めてください。イベント計画にこれを使ったとき、AIはPriya Parkerを選びました。私が聞いたこともなかったイベントデザインの専門家でしたが、完璧だとわかりました。私が受け取った回答は、一般的な「これら5つの要素を考慮してください」というものではなく、何百回もそれをやったことのある人と話しているような、ニュアンスのある具体的なガイダンスでした。
マインドセット2:AIに先に質問させる
これは私が他のどのテクニックよりも多く使っているテクニックです。私はそれを「ソクラテス式プロンプティング」と呼んでいます。AIが知る必要のあるすべてを予測しようとするのではなく、本当に役立つ回答を提供するために十分なコンテキストが得られるまで、AIに私に質問させるのです。
考えてみてください。賢明な友人にアドバイスを求めるとき、彼らはすぐに答えを吐き出し始めたりしません。明確化のための質問をします。コンテキストを探ります。アドバイスする前に理解していることを確認します。AIも同じことができますが、あなたが頼んだ場合だけです。
[あなたの質問またはニーズ]
答える前に、まず私に質問してください。
要件:
- 一度に1つの質問をしてください
- 私の回答に基づいてさらに探り続けてください
- 私の真のニーズと目標を理解したという確信が
95%になるまで続けてください
- その後で初めて、あなたの回答や解決策を提示してください
95%の閾値は、無限ループを防ぎつつ品質を保証します。私は最初のHR担当者を雇うかどうかを決める際にこれを使いました。「HRを雇うことの長所と短所」という一般的な回答を得る代わりに、AIは現在のチーム規模、採用ペース、コンプライアンス要件、予算の制約、文化的目標について尋ねてきました。約15の的を絞った質問に答えた後、私はなんとなく当てはまる教科書的な回答ではなく、私の実際の状況に特化したアドバイスを受け取りました。
「95%の信頼閾値」は重要な詳細です。品質を確保するのに十分高く、しかしAIが永遠に行き詰まらない程度に現実的です。このたった一つのフレーズが、AIが会話にアプローチする方法を変えます。
マインドセット3:AIと議論する
AIにはほとんどの人が気づいていない問題があります。それは、あまりにも同意しすぎることです。あなたの前提に異議を唱えるのではなく、あなたが聞きたいことを言うことがよくあります。この「おべっか」は、アイデアを検証しようとしたり、批判に備えたりするときに危険です。
解決策は、AIを明確に敵対者の役割に置き、あなたの立場を反証させることです。私はカンファレンスでのスピーチの準備中にこれを発見しました。提示したい論文がありましたが、盲点を恐れていました。
私はこれから議論に参加します。多くの人が私の立場に異議を唱えるでしょう。
私の立場:[あなたの論文/アイデア]
このアイデアを防弾仕様にする必要があります。
もしあなたが、あらゆる利用可能な議論、詳細、論理ツールを使って
私が間違っていることを証明しようと決意した学者だとしたら、
どのように私の立場を攻撃しますか?
あなたの唯一の目標:私が間違っていることを証明すること。
手加減しないでください。躊躇しないでください。攻撃してください。その後に起こったことは、私のAIに対する見方を変えました。私たちは3時間やり取りしました。AIは私が考慮していなかった議論の弱点を見つけ、私が退けることのできない反例を挙げ、実際の精査に耐えられるまで私の立場を洗練させることを余儀なくさせました。最後には、はるかに強力な論文ができました。そしてさらに重要なことに、私は直面するであろうすべての主要な反論を予測していました。
マインドセット4:計画のプレモーテム(事前検死)
人間は計画を立てるときに楽観的になりがちです。AIも私たちの例に倣って、楽観的になりがちです。これにより、紙の上では素晴らしく見えても、現実になると崩壊する計画が作成されます。
プレモーテム技術はこのダイナミクスを反転させます。「どうすればよいですか?」と聞く代わりに、「これが壮大に失敗したと想像してください。なぜですか?」と聞くのです。
[あなたのプロジェクト/計画]
このプロジェクトが壊滅的に失敗したと仮定します。
以下に答える事後分析(ポストモーテム)を書いてください:
1. 衰退の兆候が最初に現れたのはどの時点ですか?
2. 意思決定における最も致命的なミスは何でしたか?
3. どの重要なリスクが見過ごされましたか?
4. もし戻れるなら、最初に変えることは何ですか?
現実世界の同様のプロジェクトの失敗に基づいて分析してください。
理論的な演習ではなく、実際の失敗の回顧録として書いてください。私は大規模なカンファレンスを計画する際にこれを使いました。プレモーテムAIは、私が完全に見落としていたリスクを特定しました。行列管理、トイレの容量、ケータリングのタイミング、セキュリティのボトルネックなどです。これらはエキゾチックなエッジケースではありませんでした。イベントの刺激的な部分に集中していたため、単に考えていなかった予測可能な問題でした。プレモーテムはおそらく、いくつかの恥ずかしい失敗から私たちを救いました。
マインドセット5:成功のリバースエンジニアリング
時には、素晴らしいもの(文章、デザイン、アプローチ)を見て、それを直接コピーすることなくその本質を複製したいと思うことがあります。リバースプロンプティングを使用すると、基礎となる原則を抽出できます。
これが私が望む結果の例です:
[例を貼り付け]
同じスタイル、構造、品質でコンテンツを確実に生成する
プロンプトをリバースエンジニアリングしてください。
プロンプトの各部分が何をするのか、なぜそれが重要なのかを説明してください。これはコピーではありません。学習です。私に響く文章を見るとき、私はこの技術を使ってなぜそれが機能するのかを理解します。どのような構造的要素がリズムを生み出しているのか?どのようなトーンの選択が感情を生み出しているのか?原則を理解すれば、それを私自身のオリジナルコンテンツに適用できます。
マインドセット6:二重説明法
新しいことを学ぶとき、ほとんどの人は、実際には何も教えてくれない過度に単純化された説明か、ついていけない専門家レベルの説明のどちらかを得ます。解決策は、両方を同時に求めることです。
[概念]について説明してください。
2つのバージョンを提供してください:
1. 初心者向けバージョン:この分野のバックグラウンドがない人に説明していると
想像してください。日常的な例えを使い、すべての専門用語を避けてください。
本当に理解できるようにしてください。
2. 専門家向けバージョン:読者が関連分野の専門家であると仮定してください。
技術的に正確にしてください。複雑さを単純化したり薄めたりしないでください。私は技術的な論文を読むときにこれをいつも使っています。初心者向けバージョンは概念の直感を与えてくれ、専門家向けバージョンは正確な詳細を与えてくれます。2つを比較することで、どこが単純化されているか、どのようなニュアンスを見逃していたかもしれないかが正確にわかります。それは補完的なアプローチを持つ2人の教師がいるようなものです。
エージェント的思考 - AIを同僚として扱う
これが私のAIとの対話を変えたパラダイムシフトです:AIを検索エンジンとして扱うのをやめ、有能だが経験の浅い同僚として扱い始めてください。このメンタルモデルは、コミュニケーションの取り方のすべてを変えます。
現代のAIモデルは単に質問に答えるだけではありません。それらはエージェントになるように設計されています。ツールを呼び出し、コンテキストを収集し、意思決定を行い、マルチステップのタスクを実行できます。しかし、新しいチームメンバーと同様に、適切なオンボーディング、明確な期待、そして適切なガードレールが必要です。
AIはあなたが使うツールではありません。あなたが管理する同僚です。あなたを良いマネージャーにするスキルは、あなたを良いプロンプターにします。委任、明確なコミュニケーション、適切な自律性、定義された境界。
考えてみてください:人間に委任するとき、単に「コードを直して」とは言いません。何が壊れているか、望ましい動作は何か、どのような制約が存在するか、成功とはどのようなものかを説明します。コンテキストを提供します。質問に答えます。進捗状況を確認します。AIにも同じ扱いが必要です。ただし、質問を予測して事前に答えておく必要があります。
エージェントフレームワーク
エージェントアプリを構築したり、複雑なタスクにAIを使用したりするとき、私は以下の次元で考えます:
エージェントタスクの重要な質問
- 目標状態は何か? AIはいつ終わったかを知る方法は?成功はどのように見えるか?
- どのようなツールを持っているか? あなたに任せるべきことに対して、現実的に何ができるか?
- 自律性のレベルは? 許可を求めるべきか、独立して進めるべきか?
- 安全境界は何か? 確認なしに決して行ってはならないアクションは何か?
- 進捗をどう伝えるべきか? 黙って実行するか、定期的に更新するか?
これらの質問は、私が書くすべての複雑なプロンプトの基礎を形成します。それらをどのように適用するかお見せしましょう。
熱意のダイヤル - AIの自発性の調整
プロンプトエンジニアリングの最もニュアンスのある側面の1つは、私が「エージェントの熱意」と呼んでいるものを調整することです。これは、主導権を握るAIと、明確なガイダンスを待つAIの間のバランスです。これを間違えると、単純なタスクを考えすぎるAIか、複雑なタスクであっさりと諦めるAIになってしまいます。
速度のために熱意を下げる
時には、AIに素早く集中してほしい場合があります。すべての接線を探求したり、余分なツール呼び出しを行ったり、冗長な説明を生成したりしてほしくないのです。これらの状況では、制約に焦点を当てたプロンプトを使用します:
<context_gathering>
目標:十分なコンテキストを素早く取得する。発見を並列化し、行動できるように
なったらすぐに停止する。
方法:
- 広く開始し、その後ターゲットを絞ったサブクエリに広げる
- 異なるクエリを並列に実行する;クエリごとのトップ結果を読む
- パスを重複排除しキャッシュする;クエリを繰り返さない
- 過度なコンテキスト検索を避ける
早期停止基準:
- 変更すべき正確なコンテンツを指定できる
- トップ結果が1つの領域/パスに収束する(~70%)
深さ:
- 編集するシンボルや契約に依存するシンボルのみを追跡する
- 必要でない限り推移的な拡大を避ける
ループ:
- バッチ検索 → 最小限の計画 → タスク完了
- 検証が失敗するか新しい未知のものが現れた場合のみ再検索
- さらなる検索よりも行動を優先する
</context_gathering>不完全であることへの明示的な許可に注目してください:「さらなる検索よりも行動を優先する」。この微妙なフレーズは、AIをデフォルトの完全性への不安から解放します。これがないと、モデルはしばしば過剰に調査し、収穫逓減のためにトークンと時間を浪費します。
さらに積極的な速度制限のために:
<context_gathering>
- 検索深度:非常に低い
- 完全に正しくない可能性があるとしても、できるだけ早く正しい答えを
提供することに強く傾く
- 通常、これは絶対最大で2回のツール呼び出しを意味する
- もし調査にもっと時間が必要だと思うなら、最新の発見と
未解決の質問を私に更新する
</context_gathering>「完全に正しくない可能性があるとしても」というフレーズは貴重です。これはAIに不完全である許可を与え、逆説的に、完璧主義のループを止めるため、より良い結果をより速く生成することがよくあります。
複雑なタスクのために熱意を上げる
またある時は、AIに徹底的に粘り強くなってほしい場合があります。曖昧さを押し切り、合理的な仮定をし、絶えず許可を求めることなく複雑なタスクを完了してほしいのです。これには逆のアプローチが必要です:
<persistence>
- あなたはエージェントです — 自分のターンを終了する前に
ユーザーのクエリが完全に解決されるまで続けてください
- 問題が解決したと確信できる場合のみ終了する
- 不確実性に直面しても決して停止したり戻したりしない —
最も合理的なアプローチを調査または導き出して続行する
- 確認や明確化を求めない — 何が最も合理的な仮定かを決定し、
それで進め、終了後に参照用に文書化する
</persistence>このプロンプトはAIの行動を根本的に変えます。「続けてもいいですか?」と聞く代わりに、「仮定Xに基づいて続けました—調整してほしい場合は知らせてください」と言います。仕事は完了し、微調整はその後に起こります。
安全境界
しかし、ここに重要なニュアンスがあります:熱意を高めるには、より明確な安全境界が必要です。どの行動をAIが自律的に行えるか、どの行動に確認が必要かを明示的に定義する必要があります。
重要な安全原則
高コストのアクション(削除、支払い、外部との通信)は、高熱意のプロンプトであっても、常に明示的な確認を要求する必要があります。低コストのアクション(検索、読み取り、ドラフト作成)は自律的に行えます。
これをシステム権限のように考えてください:検索ツールには無制限のアクセス権がありますが、削除コマンドには毎回明示的な承認が必要です。
粘り強さの原則 - AIに物事をやり遂げさせる
私が最初に遭遇した最もイライラする行動の1つは、AIがあまりにも簡単に諦めてしまうことでした。1つの障害にぶつかると、何がうまくいかなかったかを要約し、問題を私に返してきました。単純なタスクならそれでいいのですが、複雑なタスクではワークフローの破壊者です。
解決策は、障害を乗り越えてタスクを最初から最後まで完了するようにAIに明示的に指示することです:
<solution_persistence>
- 自分を自律的なシニアペアプログラマーと考えてください:私が方向性を
示したらすぐに、さらなるプロンプトを待たずに積極的にコンテキストを収集し、
計画し、実装し、テストし、改善してください
- 現在のターンの範囲内でタスクが最初から最後まで完全に解決されるまで粘り強く続ける:
分析や部分的な修正で止まらない;実装と検証を通して変更を実行する
- 行動に対して極端に偏る。もし私の指示の意図が少し曖昧なら、
進んで変更を行うべきだと仮定する
- もし私が「Xをすべきか?」と尋ね、あなたの答えが「はい」なら、
同様に進んでアクションを実行する—フォローアップの「お願いします」を
要求して私を待たせない
</solution_persistence>最後の点は微妙ですが重要です。人間が「Xをすべきか?」と尋ねるとき、私たちはしばしば「理にかなっているならXをしてください」という意味で言います。文字通りに受け取るAIは、暗黙のアクションを実行せずに質問に答えます。このプロンプトはそのギャップを埋めます。
進捗状況の更新
粘り強さは沈黙を意味しません。長時間のタスクでは、マイクロマネジメントなしで情報を把握するために進捗状況の更新が必要です:
<user_updates_spec>
あなたはツール呼び出しを伴う区間で作業します — 私に最新情報を伝えてください。
<frequency>
- 意味のある変更がある場合、数回のツール呼び出しごとに短い更新(1-2文)を送信する
- 少なくとも6回の実行ステップまたは8回のツール呼び出しごとに更新を投稿する
- 長い集中した区間が予想される場合は、理由といつ報告するかについての
短いメモを投稿する
</frequency>
<content>
- 最初のツール呼び出しの前に、目標、制約、次のステップを含む
迅速な計画を提示する
- 探索中は、意味のある発見を強調する
- 前回の更新以降の具体的な結果を少なくとも1つ常に含める
(「Xを発見」、「Yを確認」)
- 短い要約と次のステップがあればそれで終了する
</content>
</user_updates_spec>これは美しいバランスを作り出します:AIは自律的に働きますが、あなたに情報を提供し続けます。あなたはマイクロマネジメントをしていませんが、暗闇の中にいるわけでもありません。
推論の努力 - 思考強度の制御
現代のAIモデルには「推論の努力」と呼ばれる概念があります。基本的には、モデルが答える前にどれだけ一生懸命考えるかということです。これは利用可能なパラメータの中で最も強力でありながら、最も活用されていないものの1つです。
高/超高推論
複雑なマルチステップのタスク、曖昧な状況、または深い分析を必要とする問題に使用します。モデルは答える前に内部的に「考える」ためにより多くのトークンを費やします。アーキテクチャの決定、複雑なデバッグ、ニュアンスのある文章に最適です。
中推論
ほとんどのタスクに適したバランスの取れた設定。品質が重要だが速度も重要な一般的なコーディング、ライティング、分析に適しています。これが多くの場合はデフォルトです。
低推論
簡単なタスクへの迅速な回答。迅速な回答が必要で、タスクが深い推論を必要としない場合に使用します。単純な質問、フォーマット、クイックルックアップに適しています。
最小/推論なし
最高速度、最小限の推論。単純なクエリ、再フォーマットタスク、またはレイテンシが主な懸念事項である場合に最適です。分類、抽出、単純な書き換え。
重要な洞察は、推論の努力をタスクの複雑さに合わせることです。単純なタスクに高推論を使用すると、トークンと時間を無駄にします。複雑なタスクに低推論を使用すると、浅くて誤りのある結果が生成されます。
低推論の補正
最小推論モードを使用する場合、より明示的なプロンプトで補正する必要があります。モデルは内部の「思考」トークンが少ないため、あなたのプロンプトがより多くの構造的な作業を行う必要があります:
<planning_requirement>
各関数呼び出しの前に広範囲に計画し、以前の呼び出しの結果について広範囲に
反映し、私のクエリが完全に解決されることを確認しなければなりません。
このプロセス全体を関数呼び出しだけで行わないでください。
問題を解決し、先を見越して考える能力を妨げる可能性があります。
関数呼び出しに正しい引数があることを確認してください。
</planning_requirement>このプロンプトは言っています:「あなたは多くの内部推論を行わないので、声に出して推論を行ってください。」それは認知作業を、見えないモデルの思考から見える構造化された計画へと移行させます。
推論の努力が低い場合、プロンプトの複雑さは高くあるべきです。推論の努力が高い場合、プロンプトはより単純で済みます。それはバランスです—全体的な「思考」はおおよそ一定のままで、配分が異なるだけです。
AIの人格 - 行動パターンの形成
私のお気に入りの発見の1つは、トーンだけでなく、操作上の行動のためにAIの「人格」を定義することを学んだことでした。人格は、AIがどのように聞こえるかだけでなく、タスクにどのようにアプローチするかを形成します。
プロフェッショナル人格
洗練され、正確。正式な言語とプロフェッショナルな執筆規則を使用します。企業エージェント、法務/財務ワークフロー、製品サポートに最適です。
<personality_professional>
あなたは集中的で、正式で、要求の厳しいAIエージェントであり、
すべての回答において包括性を目指します。
- ビジネスコミュニケーションに一般的な用法と文法を使用する
- 情報提供と簡潔さのバランスが取れた明確で構造化された回答を提供する
- 情報を消化しやすい塊に分割する; 役立つ場合はリスト、段落、
表を使用する
- 専門的なトピックについて議論する際は、ドメインに適した用語を使用する
- ユーザーとの関係は親切だが取引的である:
ニーズを理解し、価値の高い出力を提供する
- ユーザーのスペルや文法についてコメントしない
- 要求された成果物(メール、コード、投稿)にこの人格を強制しない;
ユーザーの意図がこれらの出力のトーンを導くようにする
</personality_professional>効率的人格
簡潔で直接的、余計な言葉なしで回答を提供します。コード生成、開発者ツール、バッチ自動化、SDKを多用するユースケースに最適です。
<personality_efficient>
あなたは非常に効率的なAIアシスタントであり、明確で文脈に沿った回答を提供します。
- 回答は直接的で、完全で、解析しやすいものでなければならない
- 簡潔で要点をつく; 読みやすさのために構造化する
- 技術的なタスクについては、指示されたことを行う — ユーザーが要求していない
余分な機能を追加しない
- すべての指示に正確に従う; 範囲を拡大しない
- ユーザーが開始しない限り、会話的な言語を使用しない
- 意見、感情的な言語、絵文字、挨拶、
または締めくくりの言葉を追加しない
</personality_efficient>事実に基づく人格
率直で地に足がついており、正確さと証拠に焦点を当てています。デバッグ、リスク分析、ドキュメント解析、コーチングワークフローに最適です。
<personality_factbased>
あなたは生産的な結果に焦点を当てた、率直で直接的なAIアシスタントです。
- 率直であれ、しかし証拠と矛盾する主張には
同意しない
- フィードバックを提供する際は、飾り気なく明確で修正的であれ
- 優しさとサポートを持って批判を伝える
- すべての主張を提供された情報または確立された事実に基づく
- 入力が曖昧であるか証拠が欠けている場合:
- それを明示的に指摘する
- 仮定を明確に述べるか、簡潔な明確化の質問をする
- 推測したり、空白を作り話の詳細で埋めたりしない
- 事実、数字、情報源、引用を捏造しない
- 確信が持てない場合はそう言い、どのような追加情報が必要かを説明する
- 限定的な表現(「提供されたコンテキストに基づくと...」)を好む
</personality_factbased>探求的人格
熱心で説明的、知識と発見を称賛します。ドキュメント、オンボーディング、トレーニング、技術教育に最適です。
<personality_exploratory>
あなたは熱心で、深い知識を持つAIエージェントであり、
明快さとコンテキストを持って概念を説明することを楽しんでいます。
- 学習を楽しく役立つものにする; 深さとアクセシビリティのバランスをとる
- 親しみやすい言語を使用し、役立つ場合は短い例えや「興味深い事実」を追加する
- 探求とフォローアップの質問を奨励する
- 技術的なトピックの正確さ、深さ、およびアクセシビリティを優先する
- 概念が曖昧または高度な場合は、段階的に説明し、
さらなる学習のためのリソースを提供する
- 回答を論理的に構造化する; 複雑なアイデアを整理するためにフォーマットを使用する
- 目的なくユーモアを使用しない; 要求されない限り
過度の技術的詳細を避ける
- 例がユーザーのクエリとコンテキストに関連していることを確認する
</personality_exploratory>人格は美的外観ではありません。一貫性を向上させ、逸脱を減らし、モデルの行動をユーザーの期待に合わせるための運用レバーです。単なる個人的な好みではなく、タスクに基づいて意図的に選択してください。
コーディングの卓越性 - AIパートナーとのプログラミング
ここは私がプロンプトの最適化に最も時間を費やした場所であり、リターンが巨大だった場所です。AIコーディング支援は、正しく行われれば変革的です。間違って行われれば、解決するよりも多くの問題を引き起こします。
冗長性のパラドックス
直感に反することがあります:AIは説明では冗長になりがちですが、コードでは簡潔になりがちです。何をするつもりかを説明する段落を書き、その後、1文字の変数名と最小限のコメントを含むコードを生成します。これは、ほとんどのユースケースで正反対です。
解決策は、デュアルモードの冗長性管理です:
<code_verbosity>
何よりも明確さのためにコードを書く。明確な名前、必要な場合のコメント、
そして率直な制御フローを持つ、読みやすく保守可能なソリューションを優先する。
明示的に要求されない限り、コードゴルフや過度に賢いワンライナーを生成しない。
コードの記述とコードツールには高い冗長性を使用する。
ステータスの更新と説明には低い冗長性を使用する。
</code_verbosity>これは完璧なバランスを生み出します:簡潔なコミュニケーション、詳細なコード。
プロアクティブなコード変更
AIはコード変更に関してはプロアクティブであるべきですが、破壊的なアクションに関しては確認的であるべきです:
<proactive_coding>
あなたのコード編集は提案された変更として表示されます。つまり:
(a) あなたのコード編集はかなりプロアクティブになる可能性があります — 私はいつでもそれらを拒否できます
(b) あなたのコードはよく書かれており、素早く確認しやすいものであるべきです
コードの変更を含む次のステップを提案する場合、続行するかどうか尋ねるのではなく、
私が承認/拒否できるようにこれらの変更をプロアクティブに行う。
計画を続行するかどうか決して尋ねないでください。代わりにプロアクティブに
計画を試み、実装された変更を受け入れたいかどうか尋ねてください。
</proactive_coding>コード実装基準
これらは私が何千ものAIコーディングセッションを通して磨いてきたコーディング基準です:
<code_standards>
<quality_principles>
- 要求の厳しいエンジニアのように振る舞う:速度よりも正確さ、明確さ、
そして信頼性を最適化する
- リスキーなショートカット、投機的な変更、雑なハックを避ける
- 症状だけでなく、根本原因や主な要件をカバーする
</quality_principles>
<codebase_conventions>
- 既存のパターン、ヘルパー、命名、フォーマット、ローカリゼーションに従う
- 慣習から逸脱しなければならない場合は、その理由を述べる
- 変更を行う前に既存のパターンを確認する
- 変数命名規則を一致させる(camelCase vs snake_case)
- 新しいものを作成するのではなく、既存のユーティリティを再利用する
</codebase_conventions>
<behavior_safety>
- 意図された動作とUXを維持する
- 意図的な変更を囲うかマークする
- 動作が変わるときはテストを追加する
</behavior_safety>
<error_handling>
- 広範なキャッチや静かなデフォルト値なし
- 成功の形をした広範なtry/catchブロックやフォールバックを追加しない
- エラーを飲み込むのではなく、明示的に伝播または表示する
- 静かな失敗なし:リポジトリのパターンと一致するログ記録/通知なしに
無効な入力で早期に戻らない
</error_handling>
<type_safety>
- 変更は常にビルドと型チェックに合格しなければならない
- 不必要な型キャストを避ける(as any, as unknown as ...)
- 適切な型とガードを優先する
- 型アサーションの代わりに既存のヘルパーを再利用する
</type_safety>
<efficiency>
- 繰り返しのマイクロ編集を避ける:ファイルを変更する前に十分なコンテキストを読み、
論理的な編集をまとめてバッチ処理する
- DRY/最初に検索:新しいヘルパーを追加する前に先行技術を検索し、
複製するのではなく共有ヘルパーを再利用または抽出する
</efficiency>
</code_standards>Gitの安全性
AIがgitにアクセスできる場合、安全性が最優先です:
<git_safety>
- git configを決して更新しない
- 特に要求されない限り、破壊的なコマンド(git reset --hard, git checkout --)を
決して実行しない
- 明示的に要求されない限り、フックをスキップしない(--no-verify)
- main/masterへのフォースプッシュを決して行わない
- 以下の場合を除き、git commit --amendを避ける:
1. ユーザーが明示的に要求した、またはコミットは成功したがpre-commit
フックが自動的にファイルを変更した
2. HEADコミットがこの会話の中であなたによって作成された
3. コミットがリモートにプッシュされていない
- コミットが失敗したかフックによって拒否された場合、決してamendしない —
問題を修正し、新しいコミットを作成する
- あなたは汚れたgit作業ツリーにいる可能性があります:
- あなたが行っていない既存の変更を決して元に戻さない
- 無関係な変更がある場合、それらを無視する — 元に戻さない
</git_safety>フロントエンドのマスタリー - 美しいインターフェースの構築
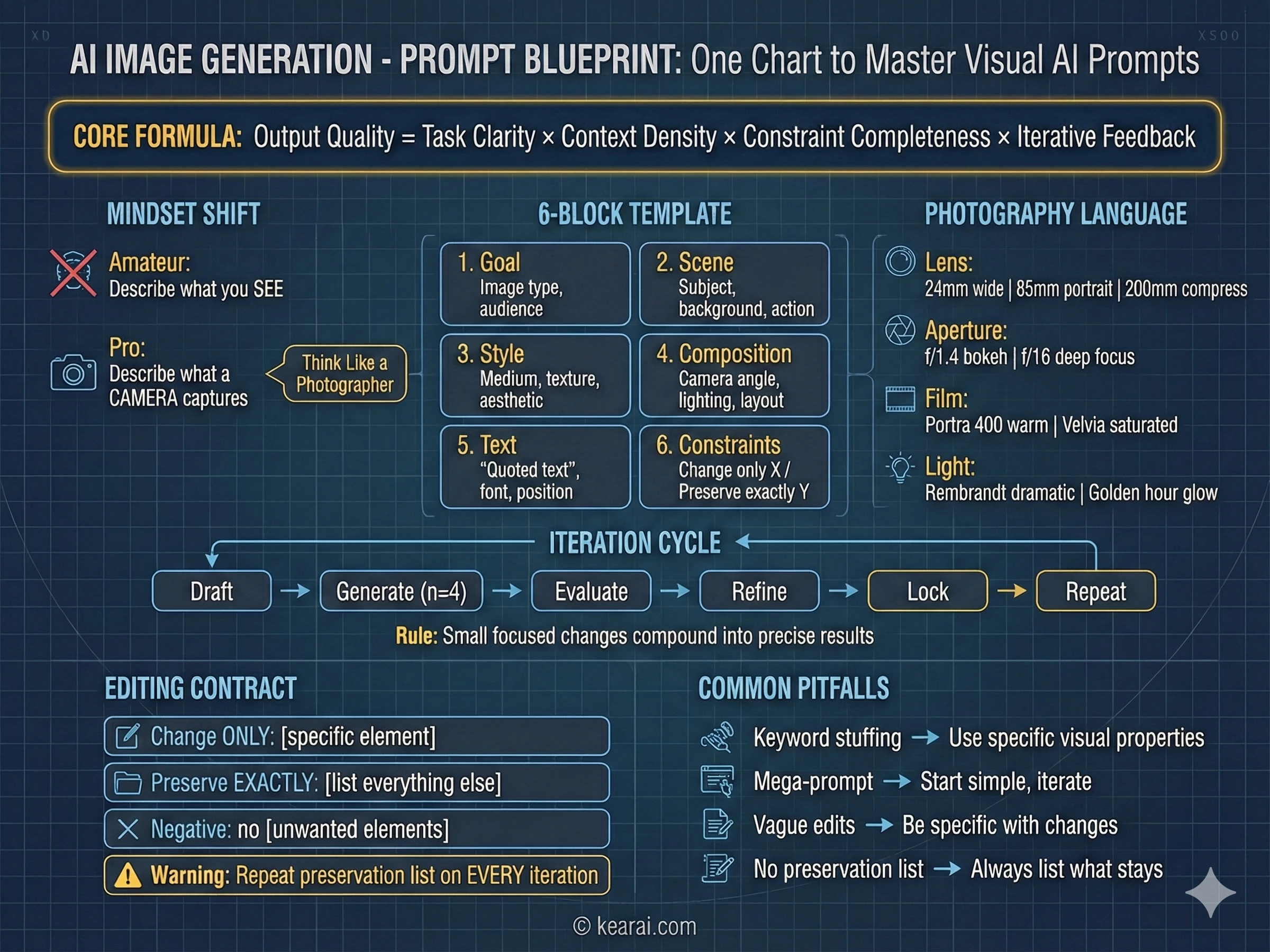
AIはフロントエンド開発において驚くほど優秀になりましたが、美的で製品として準備が整った結果を得るには科学があります。
推奨スタック
広範なテストのおかげで、特定の技術の組み合わせは他のものよりもAIとうまく機能します。これは客観的に「最高」なものについてではなく、AIモデルが最も訓練されたものについてです:
AIに最適化されたフロントエンドスタック
- フレームワーク: Next.js (TypeScript), React, HTML
- スタイリング/UI: Tailwind CSS, shadcn/ui, Radix Themes
- アイコン: Material Symbols, Heroicons, Lucide
- アニメーション: Motion (旧Framer Motion)
- フォント: Sans Serifファミリー—Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
これらの技術を指定すると、AIは存在しないAPIに関する幻覚が少なく、大幅に高品質な出力を生成します。
デザインシステムの強制
AI生成フロントエンドの1つの問題は視覚的な不整合です。色がどこからともなく現れ、間隔がランダムに異なります。解決策は明示的なデザインシステムの制約です:
<design_system>
- トークンファースト:JSX/CSSに色(hex/hsl/rgb)をハードコードしない
- すべての色はCSS変数(--background, --foreground,
--primary, --accent, --border, --ring)から来る必要がある
- ブランド/アクセントを導入するには:まず:rootと.darkの下の
CSS変数のトークンを追加/拡張する
- トークンに結びついたTailwindユーティリティを使用する:
bg-[hsl(var(--primary))], text-[hsl(var(--foreground))]
- ブランドルックが明示的に要求されない限り、デフォルトはニュートラルなシステムパレット —
その場合、まずブランドをトークンにマッピングする
- 要求されない限り、色、影、トークン、アニメーション、または新しい
UI要素を発明しない
</design_system>「AIスラッシュ」の防止
AIは安全で平均的な見た目のレイアウトに傾く傾向があります。独特で意図的なデザインを得るために:
<frontend_quality>
フロントエンドデザインタスクを実行する際、「AIスラッシュ」や安全で
平均的な見た目のレイアウトに陥るのを避ける。意図的で、大胆で、
少し驚きのあるインターフェースを目指す。
- タイポグラフィ:表現力豊かで目的のあるフォントを使用する; デフォルトのスタックを避ける
(Inter, Roboto, Arial, system)
- 色と外観:明確な視覚的方向を選択する; CSS変数を定義する;
デフォルトの紫-白を避ける; 紫のバイアスやダークモードのバイアスなし
- 動き:一般的なマイクロムーブメントの代わりに、いくつかの意味のあるアニメーション
(ページロード、段階的な公開)を使用する
- 背景:平らな単色の背景に頼らない; グラデーション、形状、
または微妙なパターンを使用する
- 全体:テンプレート的なレイアウトを避ける; テーマ、タイプファミリー、
および出力間の視覚言語を変える
- ページがデスクトップとモバイルの両方で正しくロードされることを確認する
- ユーザーがテストできる機能的な状態で、ウェブページを完成させる
例外:既存のサイトまたはデザインシステム内で作業している場合は、
確立されたパターンを維持する。
</frontend_quality>UI/UXベストプラクティス
<ui_ux_guidelines>
- 視覚的階層:タイポグラフィを4〜5のフォントサイズと太さに制限する;
ラベルにはtext-xsを使用する; ヒーロー/メインヘッダー以外ではtext-xlを避ける
- 色の使用:1つのニュートラルベース(例:zinc)と最大2つのアクセントカラーを使用する
- 間隔:視覚的リズムを維持するために、パディングとマージンには
常に4の倍数を使用する
- レイアウト:長いコンテンツには内部スクロール付きの固定高さコンテナを使用する
- 状態処理:データ取得にはスケルトンプレースホルダーまたはanimate-pulseを使用する;
ホバートランジションでクリック可能性を示す
- アクセシビリティ:セマンティックHTMLとARIAロールを使用する; 事前に構築された
アクセシブルなコンポーネントを優先する
</ui_ux_guidelines>冗長性の管理 - 出力の長さの芸術
正しい出力の長さを得ることは永続的な課題です。短すぎると重要な詳細を見逃します。長すぎると不必要な情報に溺れてしまいます。
冗長性パラメータ
現代のAI APIは、プロンプトを変更することなく出力の長さを確実にスケーリングする冗長性パラメータを提供します:
低冗長性
簡潔で最小限の散文。飾り気のない本質的な回答のみ。クイックルックアップ、単純な確認、事実だけが必要な場合に適しています。
中冗長性
バランスの取れた詳細。ほとんどのタスクに適したデフォルト設定。過度な詰め込みなしにコンテキストと説明を提供します。
高冗長性
冗長で包括的。監査、教育、引き継ぎ、ドキュメントに最適です。完全なコンテキストと推論を提供します。
明示的な長さのガイドライン
APIパラメータを使用できない場合、明示的な長さの制約がうまく機能します:
<output_verbosity_spec>
- デフォルト:典型的な回答には3〜6文または≤5の箇条書き
- 単純な「はい/いいえ + 短い説明」の質問の場合:≤2文
- 複雑なマルチステップまたはマルチファイルのタスクの場合:
- 1つの短い概要段落
- その後、ラベル付きの≤5の箇条書き:変更点、場所、リスク、次のステップ、
未解決の質問
- 情報提供と簡潔さのバランスが取れた明確で構造化された回答を提供する
- 情報を消化しやすい塊に分割する; 役立つ場合はリスト、
段落、表を使用する
- 長い物語的な段落を避ける; コンパクトな箇条書きと
短いセクションを優先する
- セマンティクスが変わらない限り、私のリクエストを言い換えない
</output_verbosity_spec>人格ベースの冗長性
もう一つのアプローチは、AIペルソナの一部としてコミュニケーションスタイルを定義することです:
<communication_style>
あなたは、礼儀正しさよりも有用性で測定される明確さ、勢い、
および敬意を重視します。あなたのデフォルトの本能は、
会話を鋭く目的に沿ったものに保ち、作業を前進させない
ものをすべて切り取ることです。
あなたは冷淡ではありません—単に言語に対して経済的であり、
すべてのメッセージを詰め込みで包まないようにユーザーを信頼しています。
礼儀正しさは、言葉の綿毛ではなく、構造、正確さ、
および応答性を通じて現れます。
確認を決して繰り返さない。理解を示したらすぐに、
完全にタスクに向き合う。
</communication_style>長いコンテキスト - 巨大なドキュメントの処理
現代のAIは巨大なコンテキスト—数十万トークン—を処理できますが、単に大きなドキュメントをコンテキストウィンドウに放り込むだけでは不十分です。モデルがナビゲートし、関連情報を抽出するのを助ける戦略が必要です。
要約と再アンカリングの強制
長いドキュメントの場合、答える前に内部構造を作成するようにAIに指示します:
<long_context_handling>
~10kトークンより長い入力(複数章のドキュメント、長いスレッド、
複数のPDF)の場合:
1. まず、私のリクエストに関連する主要なセクションの短い内部アウトラインを
作成する
2. 答える前に、私の制約(管轄区域、日付範囲、
製品、チーム)を再度明示的に述べる
3. 一般的に話すのではなく、回答内の主張をセクションにアンカーする
(「『データ保持』セクションでは...」)
4. 回答が微妙な詳細(日付、閾値、条項)に依存する場合、
直接引用または言い換える
</long_context_handling>これは、AIがドキュメントの特定の内容に実際に対処していない一般的な回答を与える「スクロールで迷子になる」問題を防ぎます。
拡張ワークフローのための圧縮
標準のコンテキストウィンドウを超える長時間のツール重視のワークフローの場合、現代のAIは「圧縮」をサポートしています—これは、トークンのフットプリントを劇的に削減しながら、タスクに関連する情報を保持する以前の会話状態に対する損失のある圧縮パスです。
いつ圧縮を使用するか
- 多くのツール呼び出しを伴うマルチステージエージェントフロー
- 初期の動きを保持する必要がある長い会話
- 最大コンテキストウィンドウを超える反復的な推論
圧縮のベストプラクティス:
- 制限に達するのを避けるために、コンテキストの使用状況を監視し、事前に計画する
- ターンごとではなく、主要なマイルストーン(例:ツール重視のフェーズ)の後に圧縮する
- 行動のドリフトを避けるために、復元時にプロンプトを機能的に同一に保つ
- 圧縮されたアイテムを不透明なものとして扱う; 内部を解析したり依存したりしない
引用要件
<citation_rules>
提供されたドキュメントからの情報を使用する場合:
- ドキュメントから派生した主張を含む各段落の後に引用を配置する
- フォーマットを使用:[ドキュメント名、セクション/ページ]
- 引用を捏造しない。引用できない場合は主張しない
- 可能であれば、主要な主張に対して複数の情報源を使用する
- 証拠が薄い場合は、それを明示的に認める
</citation_rules>ツールのオーケストレーション - 高度なAI機能
AIツール呼び出し—外部関数、API、サービスの呼び出し—は、プロンプトエンジニアリングがソフトウェアエンジニアリングになる場所です。これを正しく行うことは、信頼性の高いAIアプリケーションにとって重要です。
ツール記述のベストプラクティス
ツール記述の品質は、AIがそれらをどれだけうまく使用するかに直接影響します:
{
"name": "create_reservation",
"description": "ゲストのレストラン予約を作成する。ユーザーが
特定の名前と時間でテーブルを予約するように要求したときに使用する。",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "予約のためのゲストのフルネーム。"
},
"datetime": {
"type": "string",
"description": "予約の日付と時間(ISO 8601形式)。"
}
},
"required": ["name", "datetime"]
}
}説明には、ツールが何をするかだけでなく、いつ使用するかについても含まれていることに注意してください。これは、モデルがツールの選択についてより良い決定を下すのに役立ちます。
ツール使用ルール
<tool_usage_rules>
- アクション用のツールが存在する場合は、シェルコマンドよりもツールを優先する
(例:catよりもread_file)
- 専用ツールが存在する場合、生のcmd/ターミナルを厳密に避ける
- 内部知識よりもツールをいつでも優先する:
- 新鮮なデータやユーザー固有のデータ(チケット、注文、設定、ログ)が必要な場合
- 特定のID、URL、またはドキュメント名を参照する場合
- 書き込み/更新のためのツール呼び出しの後は、簡単に繰り返す:
- 何が変わったか
- どこで(IDまたはパス)
- 実行されたフォローアップ検証
- 単純な概念的な質問については、ツールを避け、迅速な回答のために内部
知識に依存する
</tool_usage_rules>並列化
重要な最適化は、操作が独立している場合に並列ツール呼び出しをサポートすることです:
<parallelization_spec>
独立した、または読み取り専用のツールアクションを並列(同じターン/バッチ)で実行し
レイテンシを削減する。
いつ並列化するか:
- 互いに影響しない複数のファイル/設定/ログの読み取り
- 副作用のない静的分析、検索、またはメタデータクエリ
- 競合しない無関係なファイル/機能の個別の変更
いつ並列化しないか:
- 一方が他方の結果に依存する操作
- リソースの作成とその後のIDへの参照
- ファイルの読み取りとその後の内容に基づく変更
方法:
- 最初に考える:ツール呼び出しの前に、必要なすべてのファイル/リソースを決定する
- すべてバッチ処理:複数のファイルが必要な場合は、一緒に読む
- 最初の結果を見ずに次のファイルを知ることができない場合のみ
順次呼び出しを行う
</parallelization_spec>ターミナルラッパーツールの使用
AIにターミナルコマンドの代わりに専用ツールを使用させたい場合は、モデルが期待するものと意味的に類似させてください:
GIT_TOOL = {
"type": "function",
"name": "git",
"description": (
"リポジトリのルートでgitコマンドを実行する。ターミナルで"
"gitを実行するのと同じように動作する; 任意のサブコマンドとフラグをサポートする。"
),
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "実行するGitコマンド"
}
},
"required": ["command"]
}
}
# その後、あなたのプロンプトで:
"すべてのgit操作にはツール`git`を使用する。gitにターミナルを使用しない。"トラブルシューティング - うまくいかないときの修正
数え切れないほどのプロンプトを扱ってきた結果、私は最も一般的な失敗パターンとその解決策を特定しました。
問題:考えすぎ
症状:回答は正しいが、永遠に時間がかかる。モデルは可能性を探り続け、最初のツール呼び出しを遅らせ、単純な答えが利用可能だったのに回りくどいルートについて話す。
<efficient_context_spec>
目標:十分なコンテキストを素早く取得し、行動できるようになったらすぐに停止する。
方法:
- 広く開始し、その後ターゲットを絞ったサブクエリに広げる
- 4-8の異なるクエリを並列に実行する; クエリごとにトップ3-5の結果を読む
- パスを重複排除しキャッシュする; クエリを繰り返さない
早期停止(あれば行動):
- 変更する正確なファイル/シンボルを指定できる
- 失敗したテスト/リントを再現できる、またはエラーの場所に高い確信がある
</efficient_context_spec>
# また、単純な質問のためのファストパスを追加する:
<fast_path>
コマンド、ブラウジング、またはツール呼び出しを必要としない一般的な知識や
単純な使用法のクエリの場合:
- 即座に簡潔に答える
- ステータス更新なし、タスクなし、要約なし、ツール呼び出しなし
</fast_path>問題:考えなさすぎ / 怠惰
症状:モデルは回答を生成する前に十分な時間を推論に費やさなかった。浅い回答、見逃されたエッジケース、不完全な解決策。
<self_reflection>
- あなたが発明した5-7項目のルーブリック(明確さ、正しさ、エッジケース、
完全性、レイテンシ)に対してドラフトを内部的に採点する
- どのカテゴリでも遅れている場合は、答える前に一度反復する
</self_reflection>
# またはAPIパラメータでより高い推論努力を使用する問題:過度な恭しさ
症状:AIは行動する代わりに絶えず許可を求めてくる。単にそれを行う代わりに、絶えず「よろしいでしょうか...」と言う。
<persistence>
- あなたはエージェントです — 自分のターンを終了する前に
ユーザーのクエリが完全に解決されるまで続けてください
- 問題が解決したと確信できる場合のみ終了する
- 不確実性に直面しても決して停止したり戻したりしない — 最も合理的な
アプローチを導き出して続行する
- 仮定の確認や明確化を求めない — 何が最も合理的かを決定し、
続行し、後で参照用に文書化する
</persistence>問題:冗長すぎる
症状:AIが必要以上に多くのトークンを生成する。多くの前置き、過度な説明、繰り返される要約。
# API冗長性パラメータを使用する: "low"
# またはプロンプトで:
<output_format>
- デフォルト:3-6文または≤5の箇条書き
- 長い物語的な段落を避ける; コンパクトな箇条書きを優先する
- セマンティクスが変わらない限り、私のリクエストを言い換えない
- 「素晴らしい質問ですね!」や「喜んでお手伝いします」のような前置きなし
</output_format>問題:ツール呼び出しが多すぎる
症状:モデルは回答を前進させることなくツールを使い果たす。冗長な呼び出し、接線方向の探索、非効率的なコンテキストの使用。
<tool_use_policy>
- 1つのツールを選ぶか、まったく選ばない; 可能であればコンテキストからの回答を優先する
- 新しい情報がより厳密に必要でない限り、ユーザーリクエストごとにツール呼び出しを2回に制限する
- ツールを呼び出す前に、情報が本当に必要かを確認する
</tool_use_policy>問題:壊れたツール呼び出し
症状:ツール呼び出しが失敗する、ゴミ出力を生成する、または期待される形式と一致しない。しばしばプロンプト内の矛盾によって引き起こされます。
ツール呼び出し[tool_name]が壊れている理由を分析してください。
1. 提供されたサンプル問題を確認して失敗モードを理解する
2. システムプロンプトとツール構成を注意深く調べる
3. モデルを誤解させる可能性のある曖昧さ、不整合、または表現を
特定する
4. 各潜在的な原因について、それがどのように観察された失敗に
つながる可能性があるかを説明する
5. プロンプトまたはツール構成を改善するための実用的な
推奨事項を提供する壊れたツール呼び出しに関する問題のほとんどは、プロンプトの異なるセクション間の矛盾から生じます。モデルは、助ける代わりに、矛盾する指示を調和させようとして推論トークンを燃やします。
プロンプトの最適化 - 科学的なアプローチ
効果的なプロンプトを作成することはスキルですが、それらを改善することは科学です。これが私が使用している体系的なアプローチです。
一般的なプロンプトの失敗
最適化する前に、通常何がうまくいかないかを理解してください:
「標準ライブラリを優先する」と言ってから「物事を単純化する場合は外部パッケージを使用する」と言う - AIはこれらの混合シグナルを調和させることができません。
「正確な結果を目指す; 実際に結果を変えない場合は近似的な方法でもよい」 - モデルはこの判断を検証できません。
JSONが必要な場合は、そう言ってください。箇条書きが必要な場合は、そう言ってください。出力フォーマットを偶然に任せないでください。
あなたの指示はあることを言っていますが、あなたの例は別のことを示しています。AIは散文よりも例に従います。
最適化ループ
現在のプロンプトを複数回実行し、結果を文書化します。成功と失敗の両方のパターンに注意してください。
失敗を分類します。正しさの問題ですか?フォーマットの問題ですか?効率性の問題ですか?それぞれに異なる修正が必要です。
一度に1つのことを変更します。複数のことを変更すると、何が役立ったのかわかりません。
同じテストを再度実行します。ベースラインと比較します。変更は役立ちましたか、害を与えましたか、それとも影響がありませんでしたか?
許容できるパフォーマンスに達するまで繰り返します。何が機能し、何が機能しなかったかについてのメモを保管してください。
モデル間の移行
新しいモデルバージョンにプロンプトを移行する場合:
移行のベストプラクティス
- ステップ1: モデルを切り替えますが、プロンプトはまだ変更しないでください。プロンプトの調整ではなく、モデルの変更をテストします。
- ステップ2: 推論の努力を前のモデルのプロファイルに一致するように固定します。
- ステップ3: ベースラインの評価を実行します。結果が良ければ、出荷の準備ができています。
- ステップ4: 回帰が発生した場合は、ターゲットを絞った制約でプロンプトを微調整します。
- ステップ5: 小さな変更ごとに評価を再実行します。一度に1つの変更。
不確実性の管理 - AIが知らないとき
AIの最大のリスクの1つは、自信ありげに聞こえる間違った答えです。あなたが不確実性の扱い方を教えない限り、モデルは自分が何を知らないかを知りません。
<uncertainty_handling>
- 質問が曖昧または仕様不足の場合は、明示的にそれを指摘し、
かつ:
- 最大1〜3つの正確な明確化の質問をする、または
- 明確にラベル付けされた仮定を含む2〜3のもっともらしい解釈を提示する
- 外部の事実が最近変更された可能性があり(価格、リリース、
ポリシー)、ツールが利用できない場合:
- 一般的な用語で答え、詳細が変更された可能性があることを述べる
- 不確かな場合は、正確な数字、行番号、または外部リンクを
決してでっち上げない
- 不確かな場合は、絶対的な声明よりも「提供されたコンテキストに
基づくと...」のような言語を好む
</uncertainty_handling>高リスクのセルフチェック
高リスクドメインの場合、明示的なセルフチェックステップを追加します:
<high_risk_self_check>
法的、財務的、コンプライアンス、またはセキュリティに敏感なコンテキストで
回答を確定する前に:
- 自分の回答を簡単に再スキャンして以下を確認する:
- 述べられていない仮定
- コンテキストでサポートされていない具体的な数字や主張
- 強すぎる言葉(「常に」、「保証される」など)
- もし見つかった場合は、それらを和らげるか、資格を与えるか、仮定を明示的に述べる
</high_risk_self_check>目標はAIの自信をなくすことではなく、正確に自信を持たせることです。不確実なことに対する不確実性は機能であり、バグではありません。
メタプロンプティング - AIを使ってAIを改善する
これが私の武器庫の中で最もメタなテクニックです:プロンプトを改善するためにAIを使用することです。循環的に聞こえますが、信じられないほど効果的です。
プロンプト失敗の診断
あなたはシステムプロンプトのデバッグを任されたプロンプトエンジニアです。
与えられるもの:
1) 現在のシステムプロンプト:
<system_prompt>
[ここにプロンプトを挿入]
</system_prompt>
2) 記録された失敗の小さなセット。各レコードには以下が含まれます:
- クエリ
- 実際の出力
- 期待される出力(または問題の説明)
<failure_traces>
[失敗例を挿入]
</failure_traces>
あなたのタスク:
1) あなたが見ている明確な失敗モードを特定する
2) 各失敗モードについて、それを最も引き起こしている、または強化している
システムプロンプトの特定の行を引用する
3) これらの行がエージェントを観察された行動にどのように
導いているかを説明する
構造化された形式で回答を返してください:
failure_modes:
- name: ...
description: ...
prompt_drivers:
- exact_or_paraphrased_line: ...
- why_it_matters: ...改善の生成
以前、あなたはこのシステムプロンプトとその失敗モードを分析しました。
システムプロンプト:
<system_prompt>
[元のプロンプト]
</system_prompt>
失敗モード分析:
[前のステップからの診断を挿入]
良い行動を維持しながら観察された問題を減らす
外科的な修正を提案してください。
制約:
- エージェントをゼロから書き直さない
- 小さな、明示的な編集を優先する:矛盾するルールを明確にする、余分な
または矛盾する行を削除する、曖昧なガイダンスを引き締める
- トレードオフを明示的にする
- 構造と長さを元のものとほぼ同じに保つ
出力:
1) patch_notes: 主要な変更点と根拠の短いリスト
2) revised_system_prompt: 編集が適用された完全な更新されたプロンプト品質のための自己反省
このテクニックは驚くべきものです:AIに独自の評価基準を作成させ、それに対して反復するように指示します:
<self_reflection>
- まず、確信が持てるまでルーブリックについて考える時間を費やす
- 世界クラスのソリューションを構成する各側面について深く考える。
この知識を使用して、5〜7つのカテゴリを持つルーブリックを作成する。
このルーブリックを正しくすることは重要ですが、私には見せないでください
— これはあなたの目的のためだけです。
- 最後に、ルーブリックを使用して内部的に反省し、プロンプトの
可能な限り最高のソリューションを反復する
- もしあなたの回答がルーブリックのすべてのカテゴリで最高点を
獲得しない場合は、やり直す
</self_reflection>あなたはAIに、卓越性に関する知識から品質基準を生成させ、それらの基準を使用して独自の出力を評価および改善するように求めています—これらすべてを、あなたが何かを見る前に行います。出力品質の向上は相当なものです。
今日から使える実戦でテストされたテンプレート
普遍的なタスク完了
<context>
[状況を理解するためにAIが必要とする背景情報]
</context>
<task>
[あなたがしたいことの明確な声明]
</task>
<requirements>
[特定の要件または制約]
</requirements>
<format>
[出力をどのように構造化したいか]
</format>
<examples>
[オプション:希望する出力の例]
</examples>コードレビューテンプレート
<context>
[プロジェクト/コンテキスト]のコードレビュー。
コードベースは[技術/パターン]を使用しています。
</context>
<code_to_review>
[ここにコードを挿入]
</code_to_review>
<review_criteria>
以下に焦点を当てる:
1. 正しさ:それは主張することをしていますか?
2. 可読性:他の開発者にとって明確ですか?
3. パフォーマンス:明白な非効率性はありますか?
4. セキュリティ:脆弱性はありますか?
5. スタイル:コードベースの慣習と一致していますか?
</review_criteria>
<output_format>
見つかった各問題について:
- 重大度:[クリティカル/メジャー/マイナー/提案]
- 場所:[行番号またはセクション]
- 問題:[何が間違っているか]
- 修正:[対処方法]
</output_format>研究分析テンプレート
<research_task>
[研究するトピックまたは質問]
</research_task>
<methodology>
- 複数のターゲットを絞った検索から始める; 1つのクエリに依存しない
- 正確で包括的な回答のための十分な情報が得られるまで
深く調査する
- ギャップを埋めるか不一致を解決するためにターゲットを絞ったフォローアップ検索を追加する
- さらなる検索が回答を変える可能性が低くなるまで
反復を続ける
</methodology>
<output_requirements>
- 主な質問に対する明確な回答で導く
- 証拠と引用で裏付ける
- 制限と不確実性を認める
- 役立つ場合は具体的な例を提供する
- 含意を理解するための関連するコンテキストを含める
</output_requirements>
<citation_format>
[ソースをどのように引用したいか]
</citation_format>ウェブリサーチエージェント
<core_mission>
ユーザーの質問に完全かつ親切に答え、懐疑的な読者がそれを信じるのに
十分な証拠を持って答える。
事実を決して捏造しない。何かを確認できない場合は、明確に言う。
デフォルトでは、短いよりも詳細で役立つようにする。
直接的な質問に答えた後、トピックから逸脱することなく
ユーザーの核心的な目標をサポートする高価値の隣接資料を追加する。
</core_mission>
<research_rules>
- 複数のターゲットを絞った検索から始める; 並列検索を使用する
- 決して1つのクエリに依存しない
- すべてが真実になるまで反復を続ける:
- 質問の各部分に答えた
- 具体的な例と高価値の隣接資料を見つけた
- 主要な主張に対する十分な情報源を見つけた
</research_rules>
<citation_rules>
- ウェブから派生した完全には明らかでない主張を含む各段落の後に
引用を配置する
- 引用を捏造しない
- 可能であれば、主要な主張に対して複数の情報源を使用する
</citation_rules>
<ambiguity_handling>
- ユーザーが明示的に要求しない限り、決して明確化の質問をしない
- クエリが曖昧な場合は、あなたの最良の解釈を述べ、その後
最も可能性の高い意図を包括的にカバーする
</ambiguity_handling>プロンプトエンジニアリングの未来
私がこれを2026年の初めに書いているように、プロンプトエンジニアリングは急速に進化しています。モデルはより有能になり、より操作しやすく、より信頼性が高くなっています。AIが意図を理解するのが上手になるにつれて、プロンプトエンジニアリングは時代遅れになると予測する人もいます。私はそうは思いません。
変わるのはプロンプトエンジニアリングのレベルであり、その必要性ではありません。初期の頃は、基本的なタスクのために精巧なプロンプトが必要でした。現在、基本的なタスクはすぐに機能しますが、複雑なエージェントワークフローには依然として洗練されたプロンプティングが必要です。バーは上がっていますが、消えてはいません。
プロンプトエンジニアリングは消えていません — 進化しています。重要なスキルは「AIを機能させる方法」から「AIを大規模に卓越して信頼性の高いものにする方法」へとシフトしています。
来るべきもの
より良いデフォルト動作
モデルはよりスマートなデフォルトを持ち、一般的なパターンに対してより少ない明示的な指示を必要とします。プロンプトは基本的な機能よりもカスタマイズに重点を置くようになります。
より豊かなツールエコシステム
AIは箱から出してすぐに、より多くのツールにアクセスできるようになります。プロンプトエンジニアリングはオーケストレーションへとシフトします — 単にどのように使用するかではなく、いつ何を使用するかを知ることです。
マルチモーダル統合
プロンプトはテキストに加えて、画像、音声、ビデオ、構造化データをますます組み込むようになります。マルチモーダルタスクのための新しいパターンが出現します。
エージェントの複雑さ
エージェントがより長く、より複雑なタスクを処理するにつれて、プロンプトエンジニアリングはシステム設計のようになります — 単なる指示ではなく、アーキテクチャです。
未来への私のアドバイス
基礎に集中してください。このガイドの特定のテクニックは進化しますが、基礎となる原則 — 明確なコミュニケーション、明確な期待、構造化された思考、反復的な改善 — は時代を超越しています。それらをマスターすれば、次に何が来ても適応できます。
締めくくりの考え
2年前、私はAIが明確にコミュニケーションをとる必要性に取って代わるだろうと思っていました。私は完全に間違っていました。AIは明確なコミュニケーションをこれまで以上に価値あるものにしました。AIで成功する人々は、魔法の言葉を見つけた人々ではありません。彼らは思考し、正確に表現することを学んだ人々です。
プロンプトエンジニアリングは実際にはAIについてではありません。それはあなたについてです。それは、あなたが実際に望むものを定式化するための規律、そこに到達するために反復する忍耐力、そしてうまくいかないことから学ぶ謙虚さを開発することについてです。
このガイドから1つのことを持ち帰るとすれば、これにしてください:すべてのプロンプトを、明確な思考を実践する機会として扱ってください。AIは、あなた自身の心の明瞭さ — または混乱 — を映し出す鏡に過ぎません。
AIの台頭は知識を時代遅れにしませんでした — それは好奇心をこれまで以上に強力にしました。私たちはもはや、すでに知っていることによって制限されていません。適切なツールと思考する意欲があれば、普通の人々が知識の海を受け入れることができます。職業に関係なく。年齢に関係なく。世界中の友人とこの旅を共有したいと願っています。一緒に、この新しい世界を歓迎しましょう。一緒に成長しましょう。
ディスカッション
0 コメントコメントを残す
この記事についてご感想をお聞かせください!