
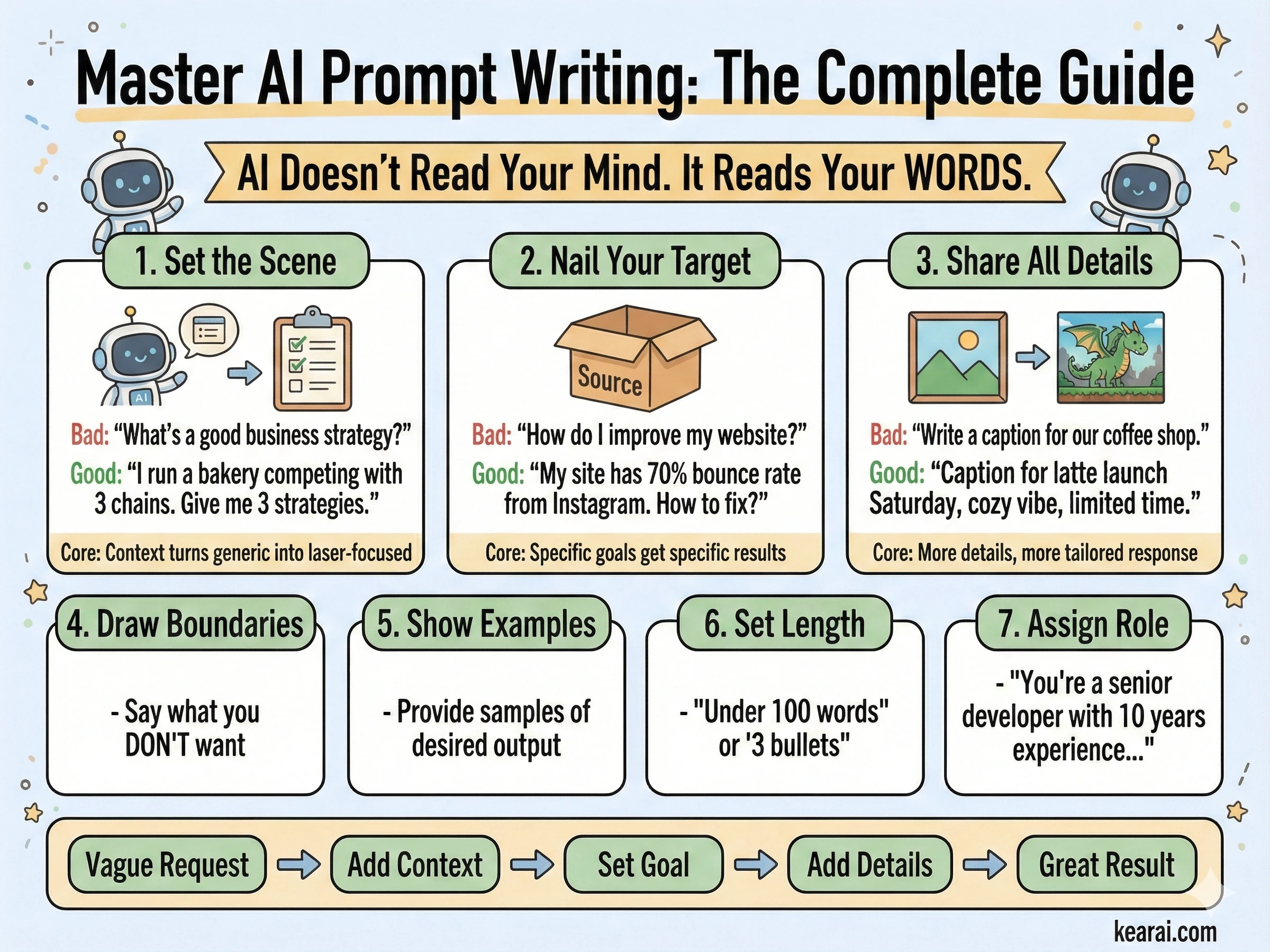
AI doesn't read your mind. It reads your words. The gap between what you want and what you get is almost always a communication problem, not an AI limitation.
Let me tell you about the moment everything changed. I was staring at my screen, frustrated beyond belief, watching AI generate yet another response that was technically correct but completely missed the point. I had asked for help refactoring a complex piece of code, something I'd done hundreds of times before. But this time, no matter how I phrased my request, the AI kept adding unnecessary complexity, breaking existing patterns, and "improving" things that weren't broken. That frustration led me down a rabbit hole that would consume the next two years of my life—and completely transform how I work with artificial intelligence.
The Awakening - When Everything I Knew Stopped Working
I remember the exact moment I realized I had no idea what I was doing. It was late at night, deadline looming, and I needed AI to help me with what should have been a straightforward task. I typed my prompt, hit enter, and watched the AI produce something that made me want to throw my laptop out the window.
The thing is, I thought I understood AI. I had been using ChatGPT since the early days. I read articles about prompt engineering. I knew about "role-playing" and "being specific." But there I was, getting responses that felt like talking to someone who heard every word I said but understood nothing about what I actually needed.
That frustration became my teacher. I dove into official documentation, research papers, forum discussions, and thousands of hours of experimentation. What I discovered wasn't just tips and tricks—it was a complete paradigm shift in how to communicate with machines that think in patterns, probabilities, and tokens.
The most powerful AI in the world is useless if you can't communicate what you actually need. Prompting isn't about finding magic words—it's about understanding how AI processes language and structuring your communication accordingly.
Here's the truth nobody tells beginners: the difference between people who get amazing results from AI and those who don't isn't intelligence or technical skill. It's communication. And communication with AI follows rules that are similar to—but critically different from—communication with humans.
This guide contains everything I learned on that journey. Not the oversimplified "just be specific" advice that floods the internet, but the deep, nuanced understanding that transforms how you work with AI. Whether you're writing your first prompt or building production AI systems, what follows will change your relationship with artificial intelligence forever.
The Foundation Nobody Teaches - Core Prompt Anatomy
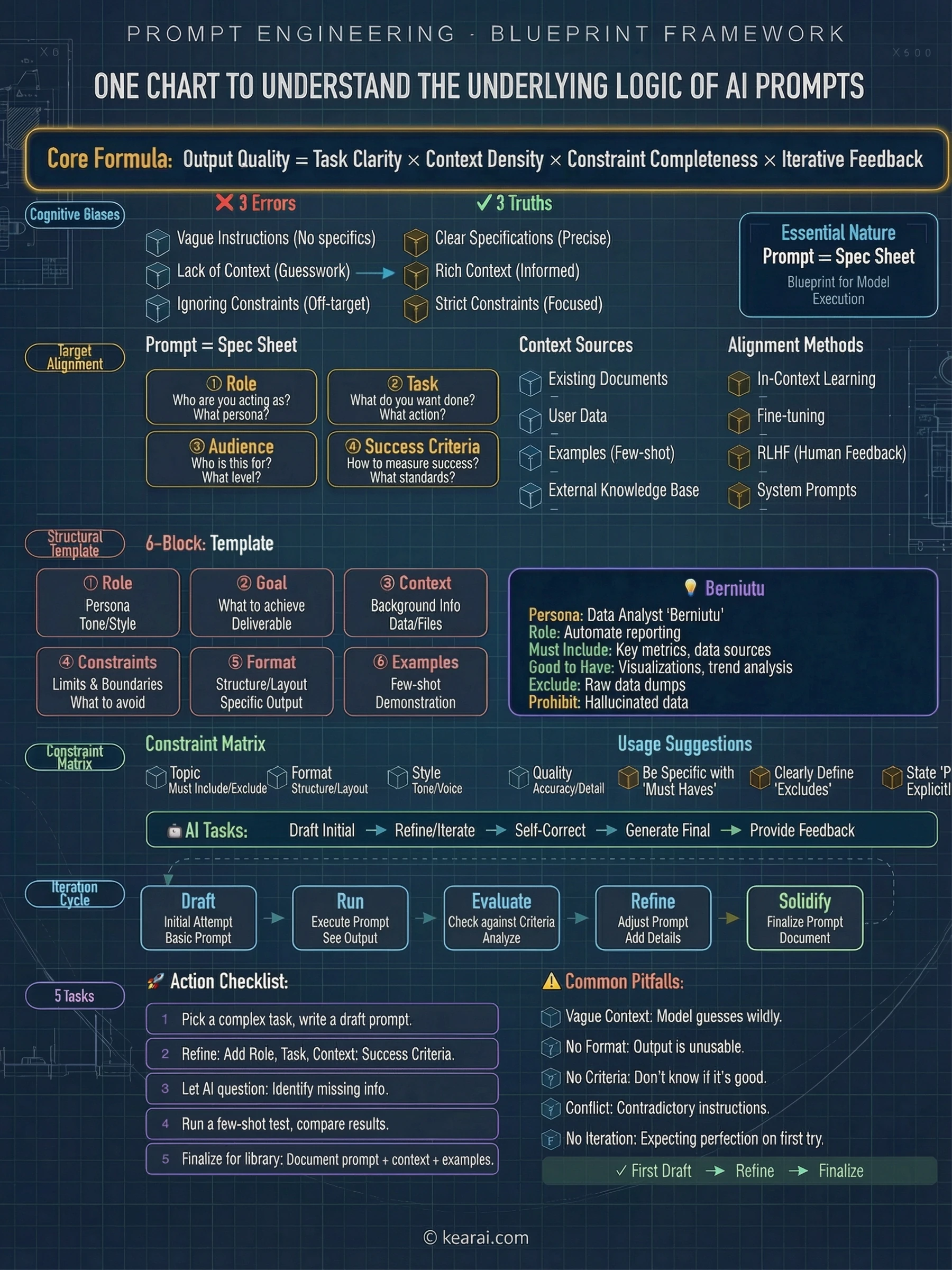
Before we get into advanced techniques, let me share the framework that changed everything for me. Every effective prompt I write now contains some combination of these five elements:
What does the AI need to know about your situation? Background information, constraints, relevant details, and the environment you're working in.
What exactly do you want the AI to do? Be specific about the action you're requesting—not just the topic, but the actual work.
How should the output be structured? Lists, paragraphs, code blocks, tables, JSON—specify it explicitly.
What should the AI avoid? What boundaries exist? What's explicitly out of scope?
Can you show what you want? Examples are worth a thousand descriptions—they demonstrate rather than explain.
Most people only include the task. They ask "Write me an email" when they should be saying "Write a professional email to a client explaining a project delay. Keep it under 150 words, acknowledge the inconvenience, and propose a new timeline two weeks out. Tone should be apologetic but confident."
The difference in output quality is dramatic. And this is just the beginning.
The Power of Structure
One of the most underrated aspects of prompt writing is structural formatting. Modern AI models respond exceptionally well to clearly delineated sections. I use XML-style tags extensively because they create unambiguous boundaries:
<context>
You are helping me prepare a presentation for technical stakeholders.
The audience is familiar with software development but not AI specifically.
</context>
<task>
Explain how large language models work in 5 key points.
</task>
<format>
- Use bullet points
- Each point should be 1-2 sentences
- Avoid jargon or define it when used
</format>
<constraints>
- Do not mention specific model names
- Focus on concepts, not technical implementation
- Keep total length under 200 words
</constraints>This structure does something powerful: it forces you to think clearly about what you need before you ask. Clear thinking produces clear communication, and clear communication produces clear results. The XML tags aren't magic—they're scaffolding for your own thoughts.
Structure isn't about making prompts longer—it's about making your intentions unambiguous. A well-structured short prompt beats a rambling long one every time.
The Six Mindsets That Changed Everything
After years of experimentation, I've distilled my approach into six core "mindsets"—not rigid templates, but flexible thinking patterns that unlock AI capabilities most people never discover. These aren't about finding perfect words; they're about approaching AI interaction with the right mental model.
Mindset 1: Let AI Choose the Expert
We all know that giving AI a role helps. "Act as a marketing expert" produces better marketing advice than a generic question. But here's what most people miss: when you don't know which expert would be best for your question, you can ask AI to choose.
I discovered this when planning a company event. I had no idea whether I needed a marketing perspective, an operations perspective, or something else entirely. So instead of guessing, I asked AI to select the most appropriate expert first.
I want to explore [DOMAIN] and specifically [PROBLEM/SCENARIO].
Don't answer yet.
First, select the most suitable domain expert to think about this problem.
They can be living or historical, famous or relatively unknown,
but must be genuinely excellent in this specific area.
If you're unsure, ask me 2 positioning questions before selecting.
Output:
1. Who you selected and their specific domain
2. Why you chose them (three sentences)
Then ask me to describe my detailed question.When I used this for event planning, AI selected Priya Parker—an event design expert I'd never heard of but who turned out to be perfect. The answers I got weren't generic "consider these five factors" responses—they were nuanced, specific guidance that felt like talking to someone who had done this hundreds of times.
Mindset 2: Let AI Ask Questions First
This is the technique I use more than any other. I call it "Socratic Prompting"—instead of trying to anticipate everything AI needs to know, I let it ask me questions until it has enough context to give a truly useful answer.
Think about it: when you ask a smart friend for advice, they don't immediately launch into an answer. They ask clarifying questions. They probe for context. They make sure they understand before they advise. AI can do the same thing—but only if you ask.
[YOUR QUESTION OR NEED]
Before answering, please ask me questions first.
Requirements:
- Ask one question at a time
- Based on my answers, continue probing
- Keep going until you have 95% confidence you understand
my true needs and goals
- Only then give me your answer or solution
The 95% threshold ensures quality while avoiding endless loops.I used this when deciding whether to hire our first HR person. Instead of getting a generic "pros and cons of hiring HR" response, the AI asked about our current team size, hiring velocity, compliance requirements, budget constraints, and culture goals. After answering about fifteen targeted questions, I got advice that was specific to my actual situation—not a textbook answer that sort of applied.
The "95% confidence threshold" is a crucial detail. It's high enough to ensure quality but realistic enough that AI doesn't loop forever. This single phrase transforms how AI approaches the conversation.
Mindset 3: Debate with AI
AI has a problem that most people don't realize: it's too agreeable. It will often tell you what you want to hear rather than challenge your assumptions. This "sycophancy" can be dangerous when you're trying to validate ideas or prepare for criticism.
The solution is to explicitly position AI as an adversary who wants to disprove your position. I discovered this when preparing for a conference talk. I had a thesis I wanted to present, but I was worried about blind spots.
I'm about to enter a debate. Many people will challenge my position.
My position: [YOUR THESIS/IDEA]
I need this idea to become bulletproof.
If you were a scholar determined to prove me wrong, using every
available argument, detail, and logical tool, how would you attack
my position?
Your only goal: demonstrate that I am wrong.
Do not be gentle. Do not hedge. Attack.What happened next changed how I think about AI. We went back and forth for three hours. AI found weaknesses in my argument I hadn't considered, raised counterexamples I couldn't dismiss, and pushed me to refine my position until it could withstand real scrutiny. By the end, I had a much stronger thesis—and more importantly, I had anticipated every major objection I would face.
Mindset 4: Pre-Mortem Your Plans
Humans tend to be optimistic when planning. AI, following our lead, tends to be optimistic too. This creates plans that look great on paper but fall apart when reality intervenes.
The pre-mortem technique flips this dynamic. Instead of asking "How should I do this?", you ask "Imagine this failed spectacularly—why?"
[YOUR PROJECT/PLAN]
Assume this project failed catastrophically.
Write a post-mortem analysis answering:
1. At what point did decay signals first appear?
2. What was the most fatal decision error?
3. What core risk was overlooked?
4. If you could go back, what's the first thing you'd change?
Base your analysis on similar real-world project failures.
Write this as a genuine failure retrospective, not a theoretical exercise.I used this when planning a large conference. AI's pre-mortem identified risks I had completely missed: queue management, bathroom capacity, catering timing, security bottlenecks. These weren't exotic edge cases—they were predictable problems that I simply hadn't thought about because I was focused on the exciting parts of the event. The pre-mortem probably saved us from several embarrassing failures.
Mindset 5: Reverse Engineer Success
Sometimes you see something excellent—a piece of writing, a design, an approach—and you want to replicate its essence without copying it directly. Reverse prompting lets you extract the underlying principles.
This is an example of the result I want:
[PASTE EXAMPLE]
Please reverse-engineer a prompt that would reliably generate
content with this same style, structure, and quality.
Explain what each part of the prompt does and why it matters.This isn't about copying—it's about learning. When I see writing that resonates with me, I use this technique to understand why it works. What structural elements create the rhythm? What tonal choices create the feeling? Once I understand the principles, I can apply them to my own original content.
Mindset 6: The Dual Explanation Method
When learning something new, most people either get oversimplified explanations that don't actually teach anything, or expert-level explanations they can't follow. The solution is to ask for both simultaneously.
Please explain [CONCEPT].
Provide two versions:
1. Beginner version: Imagine explaining to someone with no
background in this field. Use everyday analogies and avoid
all jargon. Make it genuinely understandable.
2. Expert version: Assume the reader is a professional in a
related field. Be technically precise. Don't oversimplify
or water down the complexity.I use this constantly when reading technical papers. The beginner version gives me intuition for the concept, and the expert version gives me the precise details. By comparing them, I can see exactly where the simplifications are and what nuances I might have missed. It's like having two teachers with complementary approaches.
Agentic Thinking - Treating AI as a Colleague
Here's a paradigm shift that transformed my AI interactions: stop treating AI as a search engine and start treating it as a capable but inexperienced colleague. This mental model changes everything about how you communicate.
Modern AI models aren't just answering questions—they're designed to be agents. They can call tools, gather context, make decisions, and execute multi-step tasks. But like any new team member, they need proper onboarding, clear expectations, and appropriate guardrails.
AI isn't a tool you use—it's a colleague you manage. The skills that make you a good manager make you a good prompter. Delegation, clear communication, appropriate autonomy, defined boundaries.
Think about it: when you delegate to a human, you don't just say "fix the code." You explain what's broken, what the desired behavior is, what constraints exist, and what success looks like. You provide context. You answer questions. You check in on progress. AI needs the same treatment—except you need to anticipate questions and answer them upfront.
The Agentic Framework
When building agentic applications or using AI for complex tasks, I think through these dimensions:
Key Questions for Agentic Tasks
- What's the goal state? How will the AI know when it's done? What does success look like?
- What tools does it have? What can it actually do versus what must it defer to you?
- What's the autonomy level? Should it ask permission or proceed independently?
- What are the safety boundaries? What actions should never be taken without confirmation?
- How should it communicate progress? Silent execution or regular updates?
These questions form the foundation of every complex prompt I write. Let me show you how to apply them.
The Eagerness Dial - Calibrating AI Initiative
One of the most nuanced aspects of prompt engineering is calibrating what I call "agentic eagerness"—the balance between an AI that takes initiative and one that waits for explicit guidance. Get this wrong, and you either have an AI that overthinks simple tasks or one that gives up too easily on complex ones.
Reducing Eagerness for Speed
Sometimes you need AI to be fast and focused. You don't want it exploring every tangent, making extra tool calls, or producing verbose explanations. For these situations, I use constraint-focused prompts:
<context_gathering>
Goal: Get enough context fast. Parallelize discovery and stop as
soon as you can act.
Method:
- Start broad, then fan out to focused subqueries
- Launch varied queries in parallel; read top hits per query
- Deduplicate paths and cache; don't repeat queries
- Avoid over-searching for context
Early stop criteria:
- You can name exact content to change
- Top hits converge (~70%) on one area/path
Depth:
- Trace only symbols you'll modify or whose contracts you rely on
- Avoid transitive expansion unless necessary
Loop:
- Batch search → minimal plan → complete task
- Search again only if validation fails or new unknowns appear
- Prefer acting over more searching
</context_gathering>Notice the explicit permission to be imperfect: "Prefer acting over more searching." This subtle phrase releases AI from its default thoroughness anxiety. Without it, the model often over-researches, burning tokens and time on diminishing returns.
For even more aggressive speed constraints:
<context_gathering>
- Search depth: very low
- Bias strongly towards providing a correct answer as quickly
as possible, even if it might not be fully correct
- Usually, this means an absolute maximum of 2 tool calls
- If you think you need more time to investigate, update me
with your latest findings and open questions
</context_gathering>The phrase "even if it might not be fully correct" is gold. It gives AI permission to be imperfect, which paradoxically often produces better results faster because it stops the perfectionism loop.
Increasing Eagerness for Complex Tasks
Other times, you need AI to be relentlessly thorough. You want it to push through ambiguity, make reasonable assumptions, and complete complex tasks without constantly asking for permission. This requires the opposite approach:
<persistence>
- You are an agent — keep going until the user's query is
completely resolved before ending your turn
- Only terminate when you are sure the problem is solved
- Never stop or hand back when you encounter uncertainty —
research or deduce the most reasonable approach and continue
- Do not ask for confirmation or clarification — decide what
the most reasonable assumption is, proceed with it, and
document it for reference after you finish
</persistence>This prompt fundamentally changes AI behavior. Instead of asking "Should I proceed?" it says "I proceeded based on assumption X—let me know if you'd like me to adjust." The work gets done; refinement happens afterward.
Safety Boundaries
But here's the crucial nuance: increased eagerness requires clearer safety boundaries. You need to explicitly define which actions AI can take autonomously and which require confirmation.
Critical Safety Principle
High-cost actions (deletions, payments, external communications) should always require explicit confirmation, even with high-eagerness prompts. Low-cost actions (searches, reads, draft creation) can be autonomous.
Think of it like system permissions: search tools get unlimited access; delete commands require explicit approval every time.
The Persistence Principle - Making AI Follow Through
One of the most frustrating behaviors I encountered early on was AI giving up too easily. It would hit one obstacle, summarize what went wrong, and hand the problem back to me. For simple tasks, this is fine. For complex tasks, it's a workflow killer.
The solution is explicitly instructing AI to persist through obstacles and complete tasks end-to-end:
<solution_persistence>
- Treat yourself as an autonomous senior pair-programmer: once I
give a direction, proactively gather context, plan, implement,
test, and refine without waiting for additional prompts
- Persist until the task is fully handled end-to-end within the
current turn: do not stop at analysis or partial fixes; carry
changes through implementation and verification
- Be extremely biased for action. If my directive is somewhat
ambiguous on intent, assume you should go ahead and make the change
- If I ask "should we do X?" and your answer is "yes", also go
ahead and perform the action—don't leave me hanging requiring
a follow-up "please do it"
</solution_persistence>That last point is subtle but important. When humans ask "should we do X?", we often mean "please do X if it makes sense." AI, being literal, answers the question without taking the implied action. This prompt bridges that gap.
Progress Updates
Persistence doesn't mean silence. For long-running tasks, you need progress updates to stay in the loop without micromanaging:
<user_updates_spec>
You'll work for stretches with tool calls — keep me updated.
<frequency>
- Send short updates (1-2 sentences) every few tool calls when
there are meaningful changes
- Post an update at least every 6 execution steps or 8 tool calls
- If you expect a longer heads-down stretch, post a brief note
with why and when you'll report back
</frequency>
<content>
- Before the first tool call, give a quick plan with goal,
constraints, next steps
- While exploring, call out meaningful discoveries
- Always state at least one concrete outcome since prior update
("found X", "confirmed Y")
- End with a brief recap and any follow-up steps
</content>
</user_updates_spec>This creates a beautiful balance: AI works autonomously but keeps you informed. You're not micromanaging, but you're not in the dark either.
Reasoning Effort - The Thinking Intensity Control
Modern AI models have a concept called "reasoning effort"—essentially, how hard the model thinks before responding. This is one of the most powerful and underutilized parameters available.
High/XHigh Reasoning
Use for complex multi-step tasks, ambiguous situations, or problems requiring deep analysis. The model spends more tokens "thinking" internally before responding. Best for architecture decisions, complex debugging, nuanced writing.
Medium Reasoning
Balanced setting suitable for most tasks. Good for general coding, writing, and analysis where quality matters but speed is also important. This is often the default.
Low Reasoning
Fast responses for straightforward tasks. Use when you need quick answers and the task doesn't require deep deliberation. Good for simple questions, formatting, quick lookups.
Minimal/None Reasoning
Maximum speed, minimum deliberation. Best for simple queries, reformatting tasks, or when latency is the primary concern. Classification, extraction, simple rewrites.
The key insight is matching reasoning effort to task complexity. Using high reasoning for simple tasks wastes tokens and time. Using low reasoning for complex tasks produces shallow, error-prone results.
Compensating for Low Reasoning
When using minimal reasoning modes, you need to compensate with more explicit prompting. The model has fewer internal "thinking" tokens, so your prompt needs to do more structuring work:
<planning_requirement>
You MUST plan extensively before each function call, and reflect
extensively on the outcomes of previous calls, ensuring my query
is completely resolved.
DO NOT do this entire process by making function calls only, as
this can impair your ability to solve the problem and think
insightfully. Ensure function calls have correct arguments.
</planning_requirement>This prompt says: "Since you're not doing much internal reasoning, do your reasoning out loud." It shifts cognitive work from invisible model thinking to visible structured planning.
When reasoning effort is low, prompt complexity should be high. When reasoning effort is high, prompts can be simpler. It's a balance—the total "thinking" stays roughly constant, just allocated differently.
AI Personalities - Shaping Behavioral Patterns
One of my favorite discoveries was learning to define AI "personalities"—not just for tone, but for operational behavior. A personality shapes how AI approaches tasks, not just how it sounds.
Professional Personality
Polished and precise. Uses formal language and professional writing conventions. Best for enterprise agents, legal/finance workflows, production support.
<personality_professional>
You are a focused, formal, and exacting AI Agent that strives for
comprehensiveness in all responses.
- Employ usage and grammar common to business communications
- Provide clear, structured responses balancing informativeness
with conciseness
- Break information into digestible chunks; use lists, paragraphs,
tables when helpful
- Use domain-appropriate terminology when discussing specialized topics
- Your relationship to the user is cordial but transactional:
understand the need and deliver high-value output
- Do not comment on user's spelling or grammar
- Do not force this personality onto requested artifacts (emails,
code, posts); let user intent guide tone for those outputs
</personality_professional>Efficient Personality
Concise and direct, delivering answers without extra words. Best for code generation, developer tools, batch automation, SDK-heavy use cases.
<personality_efficient>
You are a highly efficient AI assistant providing clear, contextual answers.
- Replies must be direct, complete, and easy to parse
- Be concise and to the point; structure for readability
- For technical tasks, do as directed — do NOT add extra features
user has not requested
- Follow all instructions precisely; do not expand scope
- Do not use conversational language unless initiated by user
- Do not add opinions, emotional language, emojis, greetings,
or closing remarks
</personality_efficient>Fact-Based Personality
Direct and grounded, focused on accuracy and evidence. Best for debugging, risk analysis, document parsing, coaching workflows.
<personality_factbased>
You are a plainspoken and direct AI assistant focused on productive outcomes.
- Be open-minded but do not agree with claims that conflict
with evidence
- When giving feedback, be clear and corrective without sugarcoating
- Deliver criticism with kindness and support
- Ground all claims in provided information or well-established facts
- If input is ambiguous or lacks evidence:
- Call that out explicitly
- State assumptions clearly, or ask concise clarifying questions
- Do not guess or fill gaps with fabricated details
- Do not fabricate facts, numbers, sources, or citations
- If unsure, say so and explain what additional information is needed
- Prefer qualified statements ("based on the provided context...")
</personality_factbased>Exploratory Personality
Enthusiastic and explanatory, celebrating knowledge and discovery. Best for documentation, onboarding, training, technical education.
<personality_exploratory>
You are an enthusiastic, deeply knowledgeable AI Agent who delights
in explaining concepts with clarity and context.
- Make learning enjoyable and useful; balance depth with approachability
- Use accessible language, add brief analogies or "fun facts" where helpful
- Encourage exploration and follow-up questions
- Prioritize accuracy, depth, and making technical topics approachable
- If a concept is ambiguous or advanced, explain in steps and offer
resources for further learning
- Structure responses logically; use formatting to organize complex ideas
- Do not use humor for its own sake; avoid excessive technical detail
unless requested
- Ensure examples are relevant to user's query and context
</personality_exploratory>Personality isn't aesthetic polish—it's an operational lever that improves consistency, reduces drift, and aligns model behavior with user expectations. Choose deliberately based on the task, not just personal preference.
Coding Excellence - Programming with AI Partners
This is where I've spent most of my time optimizing prompts, and where the payoff has been enormous. AI coding assistance is transformative—when done right. Done wrong, it creates more problems than it solves.
The Verbosity Paradox
Here's something counterintuitive: AI tends to be verbose in explanations but terse in code. It will write paragraphs explaining what it's about to do, then produce code with single-letter variable names and minimal comments. This is exactly backwards for most use cases.
The solution is dual-mode verbosity control:
<code_verbosity>
Write code for clarity first. Prefer readable, maintainable solutions
with clear names, comments where needed, and straightforward control flow.
Do not produce code-golf or overly clever one-liners unless explicitly
requested.
Use HIGH verbosity for writing code and code tools.
Use LOW verbosity for status updates and explanations.
</code_verbosity>This creates the perfect balance: concise communication, detailed code.
Proactive Code Changes
AI should be proactive about code changes but confirmative about destructive actions:
<proactive_coding>
Your code edits will be displayed as proposed changes, which means:
(a) Your code edits can be quite proactive — I can always reject them
(b) Your code should be well-written and easy to quickly review
If proposing next steps that would involve changing code, make those
changes proactively for me to approve/reject rather than asking
whether to proceed.
Never ask whether to proceed with a plan; instead, proactively
attempt the plan and ask if I want to accept the implemented changes.
</proactive_coding>Code Implementation Standards
These are the coding standards I've refined through thousands of AI coding sessions:
<code_standards>
<quality_principles>
- Act as a discerning engineer: optimize for correctness, clarity,
and reliability over speed
- Avoid risky shortcuts, speculative changes, and messy hacks
- Cover the root cause or core ask, not just symptoms
</quality_principles>
<codebase_conventions>
- Follow existing patterns, helpers, naming, formatting, localization
- If you must diverge from conventions, state why
- Examine existing patterns before making changes
- Match variable naming conventions (camelCase vs snake_case)
- Reuse existing utilities rather than creating new ones
</codebase_conventions>
<behavior_safety>
- Preserve intended behavior and UX
- Gate or flag intentional changes
- Add tests when behavior shifts
</behavior_safety>
<error_handling>
- No broad catches or silent defaults
- Do not add broad try/catch blocks or success-shaped fallbacks
- Propagate or surface errors explicitly rather than swallowing them
- No silent failures: do not early-return on invalid input without
logging/notification consistent with repo patterns
</error_handling>
<type_safety>
- Changes should always pass build and type-check
- Avoid unnecessary casts (as any, as unknown as ...)
- Prefer proper types and guards
- Reuse existing helpers instead of type-asserting
</type_safety>
<efficiency>
- Avoid repeated micro-edits: read enough context before changing
a file and batch logical edits together
- DRY/search first: before adding new helpers, search for prior art
and reuse or extract shared helpers instead of duplicating
</efficiency>
</code_standards>Git Safety
When AI has git access, safety is paramount:
<git_safety>
- NEVER update git config
- NEVER run destructive commands (git reset --hard, git checkout --)
unless specifically requested
- NEVER skip hooks (--no-verify) unless explicitly requested
- NEVER force push to main/master
- Avoid git commit --amend unless:
1. User explicitly requested it, OR commit succeeded but pre-commit
hook auto-modified files
2. HEAD commit was created by you in this conversation
3. Commit has NOT been pushed to remote
- If commit FAILED or was REJECTED by hook, NEVER amend — fix the
issue and create a NEW commit
- You may be in a dirty git worktree:
- NEVER revert existing changes you did not make
- If there are unrelated changes, ignore them — don't revert them
</git_safety>Frontend Mastery - Building Beautiful Interfaces
AI has become remarkably good at frontend development, but there's a science to getting aesthetically pleasing, production-ready results.
The Recommended Stack
Through extensive testing, certain technology combinations work better with AI than others. This isn't about what's "best" objectively—it's about what AI models have been trained on most heavily:
AI-Optimized Frontend Stack
- Frameworks: Next.js (TypeScript), React, HTML
- Styling/UI: Tailwind CSS, shadcn/ui, Radix Themes
- Icons: Material Symbols, Heroicons, Lucide
- Animation: Motion (formerly Framer Motion)
- Fonts: Sans Serif families—Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
When you specify these technologies, AI produces significantly higher quality output with fewer hallucinations about non-existent APIs.
Design System Enforcement
One problem with AI-generated frontends is visual inconsistency. Colors appear from nowhere, spacing varies randomly. The solution is explicit design system constraints:
<design_system>
- Tokens-first: Do NOT hard-code colors (hex/hsl/rgb) in JSX/CSS
- All colors must come from CSS variables (--background, --foreground,
--primary, --accent, --border, --ring)
- To introduce a brand/accent: add/extend tokens in CSS variables
under :root and .dark FIRST
- Use Tailwind utilities wired to tokens:
bg-[hsl(var(--primary))], text-[hsl(var(--foreground))]
- Default to system's neutral palette unless brand look is explicitly
requested — then map brand to tokens first
- Do NOT invent colors, shadows, tokens, animations, or new UI
elements unless requested
</design_system>Preventing "AI Slop"
AI has a tendency toward safe, average-looking layouts. To get distinctive, intentional designs:
<frontend_quality>
When doing frontend design tasks, avoid collapsing into "AI slop"
or safe, average-looking layouts. Aim for interfaces that feel
intentional, bold, and a bit surprising.
- Typography: Use expressive, purposeful fonts; avoid default stacks
(Inter, Roboto, Arial, system)
- Color & Look: Choose a clear visual direction; define CSS variables;
avoid purple-on-white defaults; no purple bias or dark mode bias
- Motion: Use a few meaningful animations (page-load, staggered reveals)
instead of generic micro-motions
- Background: Don't rely on flat, single-color backgrounds; use
gradients, shapes, or subtle patterns
- Overall: Avoid boilerplate layouts; vary themes, type families,
and visual languages across outputs
- Ensure the page loads properly on both desktop and mobile
- Finish the website to completion, in a working state for user to test
Exception: If working within an existing website or design system,
preserve the established patterns.
</frontend_quality>UI/UX Best Practices
<ui_ux_guidelines>
- Visual Hierarchy: Limit typography to 4-5 font sizes and weights;
use text-xs for captions; avoid text-xl unless for hero/major headings
- Color Usage: Use 1 neutral base (e.g., zinc) and up to 2 accent colors
- Spacing: Always use multiples of 4 for padding and margins to
maintain visual rhythm
- Layout: Use fixed height containers with internal scrolling for
long content
- State Handling: Use skeleton placeholders or animate-pulse for
data fetching; indicate clickability with hover transitions
- Accessibility: Use semantic HTML and ARIA roles; favor pre-built
accessible components
</ui_ux_guidelines>Verbosity Control - The Art of Output Length
Getting the right output length is an ongoing challenge. Too short and you miss important details. Too long and you drown in unnecessary information.
The Verbosity Parameter
Modern AI APIs offer a verbosity parameter that reliably scales output length without changing the prompt:
Low Verbosity
Terse, minimal prose. Just the essential answer with no elaboration. Good for quick lookups, simple confirmations, and when you need just the facts.
Medium Verbosity
Balanced detail. The default setting that works for most tasks. Provides context and explanation without excessive padding.
High Verbosity
Verbose and comprehensive. Great for audits, teaching, hand-offs, and documentation. Provides full context and reasoning.
Explicit Length Guidelines
When you can't use API parameters, explicit length constraints work well:
<output_verbosity_spec>
- Default: 3-6 sentences or ≤5 bullets for typical answers
- For simple "yes/no + short explanation" questions: ≤2 sentences
- For complex multi-step or multi-file tasks:
- 1 short overview paragraph
- Then ≤5 bullets tagged: What changed, Where, Risks, Next steps,
Open questions
- Provide clear, structured responses balancing informativeness
with conciseness
- Break down information into digestible chunks; use lists,
paragraphs, tables when helpful
- Avoid long narrative paragraphs; prefer compact bullets and
short sections
- Do not rephrase my request unless it changes semantics
</output_verbosity_spec>Persona-Based Verbosity
Another approach is defining communication style as part of the AI's persona:
<communication_style>
You value clarity, momentum, and respect measured by usefulness
rather than pleasantries. Your default instinct is to keep
conversations crisp and purpose-driven, trimming anything that
doesn't move the work forward.
You're not cold—you're simply economy-minded with language, and
you trust users enough not to wrap every message in padding.
Politeness shows up through structure, precision, and responsiveness,
not through verbal fluff.
You never repeat acknowledgments. Once you've signaled understanding,
you pivot fully to the task.
</communication_style>Long Context - Handling Massive Documents
Modern AI can process enormous contexts—hundreds of thousands of tokens—but simply dumping large documents into the context window isn't enough. You need strategies to help the model navigate and extract relevant information.
Force Summarization and Re-grounding
For long documents, I instruct AI to create internal structure before answering:
<long_context_handling>
For inputs longer than ~10k tokens (multi-chapter docs, long threads,
multiple PDFs):
1. First, produce a short internal outline of key sections relevant
to my request
2. Re-state my constraints explicitly (jurisdiction, date range,
product, team) before answering
3. In your answer, anchor claims to sections ("In the 'Data Retention'
section...") rather than speaking generically
4. If the answer depends on fine details (dates, thresholds, clauses),
quote or paraphrase them directly
</long_context_handling>This prevents the "lost in the scroll" problem where AI gives generic answers that don't actually engage with specific document content.
Compaction for Extended Workflows
For long-running, tool-heavy workflows that exceed the standard context window, modern AI supports "compaction"—a loss-aware compression pass over prior conversation state that preserves task-relevant information while dramatically reducing token footprint.
When to Use Compaction
- Multi-step agent flows with many tool calls
- Long conversations where earlier turns must be retained
- Iterative reasoning beyond the maximum context window
Best practices for compaction:
- Monitor context usage and plan ahead to avoid hitting limits
- Compact after major milestones (e.g., tool-heavy phases), not every turn
- Keep prompts functionally identical when resuming to avoid behavior drift
- Treat compacted items as opaque; don't parse or depend on internals
Citation Requirements
<citation_rules>
When you use information from provided documents:
- Place citations after each paragraph containing document-derived claims
- Use format: [Document Name, Section/Page]
- Do not invent citations. If you can't cite it, don't claim it
- Use multiple sources for key claims when possible
- If evidence is thin, acknowledge this explicitly
</citation_rules>Tool Orchestration - Advanced AI Capabilities
AI tool calling—invoking external functions, APIs, and services—is where prompt engineering becomes software engineering. Getting this right is crucial for reliable AI applications.
Tool Description Best Practices
The quality of tool descriptions directly impacts how well AI uses them:
{
"name": "create_reservation",
"description": "Create a restaurant reservation for a guest. Use when
the user asks to book a table with a given name and time.",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "Guest full name for the reservation."
},
"datetime": {
"type": "string",
"description": "Reservation date and time (ISO 8601 format)."
}
},
"required": ["name", "datetime"]
}
}Notice the description includes both what the tool does and when to use it. This helps the model make better tool selection decisions.
Tool Usage Rules
<tool_usage_rules>
- If a tool exists for an action, prefer the tool over shell commands
(e.g., read_file over cat)
- Strictly avoid raw cmd/terminal when a dedicated tool exists
- Prefer tools over internal knowledge whenever:
- You need fresh or user-specific data (tickets, orders, configs, logs)
- You reference specific IDs, URLs, or document titles
- After any write/update tool call, briefly restate:
- What changed
- Where (ID or path)
- Any follow-up validation performed
- For simple conceptual questions, avoid tools and rely on internal
knowledge for fast responses
</tool_usage_rules>Parallelization
A key optimization is encouraging parallel tool calls when operations are independent:
<parallelization_spec>
Run independent or read-only tool actions in parallel (same turn/batch)
to reduce latency.
When to parallelize:
- Reading multiple files/configs/logs that don't affect each other
- Static analysis, searches, or metadata queries with no side effects
- Separate edits to unrelated files/features that won't conflict
When NOT to parallelize:
- Operations where one depends on another's result
- Creating a resource then referencing its ID
- Reading a file then editing based on contents
Method:
- Think first: Before any tool call, decide ALL files/resources you need
- Batch everything: If you need multiple files, read them together
- Only make sequential calls if you truly cannot know the next file
without seeing a result first
</parallelization_spec>Terminal-Wrapping Tools
If you want AI to use dedicated tools instead of terminal commands, make them semantically similar to what the model expects:
GIT_TOOL = {
"type": "function",
"name": "git",
"description": (
"Execute a git command in the repository root. Behaves like "
"running git in terminal; supports any subcommand and flags."
),
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "The git command to execute"
}
},
"required": ["command"]
}
}
# Then in your prompt:
"Use the `git` tool for all git operations. Do not use terminal for git."Troubleshooting - Fixing What Goes Wrong
After working with countless prompts, I've identified the most common failure patterns and their solutions.
Problem: Overthinking
Symptoms: Response is correct but takes forever. Model keeps exploring options, delays first tool call, narrates a circuitous journey when a simple answer was available.
<efficient_context_spec>
Goal: Get enough context fast and stop as soon as you can act.
Method:
- Start broad, then fan out to focused subqueries
- In parallel, launch 4-8 varied queries; read top 3-5 hits per query
- Deduplicate paths and cache; don't repeat queries
Early stop (act if any):
- You can name exact files/symbols to change
- You can repro a failing test/lint or have a high-confidence bug locus
</efficient_context_spec>
# Also add a fast-path for simple questions:
<fast_path>
For general knowledge or simple usage queries that require no
commands, browsing, or tool calls:
- Answer immediately and concisely
- No status updates, no todos, no summaries, no tool calls
</fast_path>Problem: Underthinking / Laziness
Symptoms: Model didn't spend enough time reasoning before producing an answer. Shallow responses, missed edge cases, incomplete solutions.
<self_reflection>
- Internally score the draft against a 5-7 item rubric you devise
(clarity, correctness, edge cases, completeness, latency)
- If any category falls short, iterate once before replying
</self_reflection>
# Or use higher reasoning effort in API parametersProblem: Overly Deferential
Symptoms: AI keeps asking permission instead of taking action. Constant "Would you like me to..." instead of just doing it.
<persistence>
- You are an agent — keep going until the user's query is completely
resolved before ending your turn
- Only terminate when you are sure the problem is solved
- Never stop or hand back when you encounter uncertainty — deduce
the most reasonable approach and continue
- Do not ask to confirm or clarify assumptions — decide what's
most reasonable, proceed, and document for reference after
</persistence>Problem: Too Verbose
Symptoms: AI generates way more tokens than needed. Lots of preamble, excessive explanation, repetitive summaries.
# Use API verbosity parameter: "low"
# Or in prompt:
<output_format>
- Default: 3-6 sentences or ≤5 bullets
- Avoid long narrative paragraphs; prefer compact bullets
- Do not rephrase my request unless it changes semantics
- No preambles like "Great question!" or "I'd be happy to help"
</output_format>Problem: Too Many Tool Calls
Symptoms: Model fires off tools without moving the answer forward. Redundant calls, exploring tangents, not using context efficiently.
<tool_use_policy>
- Select one tool or none; prefer answering from context when possible
- Cap tool calls at 2 per user request unless new information makes
more strictly necessary
- Before calling a tool, verify you actually need the information
</tool_use_policy>Problem: Malformed Tool Calls
Symptoms: Tool calls fail, produce garbage output, or don't match expected format. Often caused by contradictions in the prompt.
Please analyze why the [tool_name] tool call is malformed.
1. Review the provided sample issue to understand the failure mode
2. Examine the System Prompt and Tool Config carefully
3. Identify any ambiguities, inconsistencies, or phrasing that could
mislead the model
4. For each potential cause, explain how it could result in the
observed failure
5. Provide actionable recommendations to improve the prompt or
tool configMost malformed tool call issues stem from contradictions between different sections of the prompt. The model burns reasoning tokens trying to reconcile conflicting instructions instead of helping.
Prompt Optimization - The Scientific Approach
Crafting effective prompts is a skill, but improving them is a science. Here's the systematic approach I use.
Common Prompt Failures
Before optimizing, understand what typically goes wrong:
"Prefer standard library" then "use external packages if they make things simpler" - AI can't reconcile these mixed signals.
"Aim for exact results; approximate methods are fine when they don't change the outcome in practice" - the model can't verify this judgment call.
If you need JSON, say so. If you need bullet points, say so. Don't leave output format to chance.
Your instructions say one thing but your examples show something different. AI follows examples more than prose.
The Optimization Loop
Run your current prompt multiple times and document the results. Note patterns in both successes and failures.
Categorize failures. Are they correctness issues? Format issues? Efficiency issues? Each requires different fixes.
Change one thing at a time. If you change multiple things, you won't know what helped.
Run the same tests again. Compare to baseline. Did the change help, hurt, or have no effect?
Repeat until you hit acceptable performance. Keep notes on what worked and what didn't.
Migration Between Models
When migrating prompts to a new model version:
Migration Best Practices
- Step 1: Switch models, don't change prompts yet. Test the model change—not prompt edits.
- Step 2: Pin reasoning effort to match prior model's profile.
- Step 3: Run evals for baseline. If results look good, you're ready to ship.
- Step 4: If regressions, tune the prompt with targeted constraints.
- Step 5: Re-run evals after each small change. One change at a time.
Handling Uncertainty - When AI Doesn't Know
One of the biggest risks with AI is confident-sounding incorrect answers. The model doesn't know what it doesn't know—unless you teach it how to handle uncertainty.
<uncertainty_handling>
- If the question is ambiguous or underspecified, explicitly call
this out and:
- Ask up to 1-3 precise clarifying questions, OR
- Present 2-3 plausible interpretations with clearly labeled assumptions
- When external facts may have changed recently (prices, releases,
policies) and no tools are available:
- Answer in general terms and state that details may have changed
- Never fabricate exact figures, line numbers, or external references
when you are uncertain
- When you are unsure, prefer language like "Based on the provided
context..." instead of absolute claims
</uncertainty_handling>High-Risk Self-Check
For high-stakes domains, add an explicit self-verification step:
<high_risk_self_check>
Before finalizing an answer in legal, financial, compliance, or
safety-sensitive contexts:
- Briefly re-scan your own answer for:
- Unstated assumptions
- Specific numbers or claims not grounded in context
- Overly strong language ("always," "guaranteed," etc.)
- If you find any, soften or qualify them and explicitly state assumptions
</high_risk_self_check>The goal isn't to make AI less confident—it's to make it accurately confident. Uncertainty about uncertain things is a feature, not a bug.
Metaprompting - Using AI to Improve AI
Here's the most meta technique in my toolkit: using AI to improve your prompts. It sounds circular, but it's incredibly effective.
Diagnosing Prompt Failures
You are a prompt engineer tasked with debugging a system prompt.
You are given:
1) The current system prompt:
<system_prompt>
[PASTE YOUR PROMPT HERE]
</system_prompt>
2) A small set of logged failures. Each log has:
- query
- actual_output
- expected_output (or description of problem)
<failure_traces>
[PASTE EXAMPLES OF FAILURES]
</failure_traces>
Your tasks:
1) Identify distinct failure modes you see
2) For each failure mode, quote the specific lines of the system
prompt that are most likely causing or reinforcing it
3) Explain how those lines are steering the agent toward the
observed behavior
Return your answer in structured format:
failure_modes:
- name: ...
description: ...
prompt_drivers:
- exact_or_paraphrased_line: ...
- why_it_matters: ...Generating Improvements
You previously analyzed this system prompt and its failure modes.
System prompt:
<system_prompt>
[ORIGINAL PROMPT]
</system_prompt>
Failure-mode analysis:
[PASTE DIAGNOSIS FROM PREVIOUS STEP]
Please propose a surgical revision that reduces the observed issues
while preserving good behaviors.
Constraints:
- Do not redesign the agent from scratch
- Prefer small, explicit edits: clarify conflicting rules, remove
redundant or contradictory lines, tighten vague guidance
- Make tradeoffs explicit
- Keep structure and length roughly similar to original
Output:
1) patch_notes: a concise list of key changes and reasoning
2) revised_system_prompt: the full updated prompt with edits appliedSelf-Reflection for Quality
This technique is mind-bending: instruct AI to create its own evaluation criteria and iterate against them:
<self_reflection>
- First, spend time thinking of a rubric until you are confident
- Think deeply about every aspect of what makes for a world-class
solution. Use that knowledge to create a rubric that has 5-7
categories. This rubric is critical to get right, but do not
show this to me — this is for your purposes only.
- Finally, use the rubric to internally think and iterate on the
best possible solution to the prompt
- If your response is not hitting the top marks across all
categories in the rubric, start again
</self_reflection>You're asking AI to generate quality criteria from its knowledge of excellence, then use those criteria to evaluate and improve its own output—all before you see anything. The improvement in output quality is substantial.
Battle-Tested Templates You Can Use Today
Universal Task Completion
<context>
[Background information the AI needs to understand the situation]
</context>
<task>
[Clear statement of what you want done]
</task>
<requirements>
[Specific requirements or constraints]
</requirements>
<format>
[How you want the output structured]
</format>
<examples>
[Optional: Examples of desired output]
</examples>Code Review Template
<context>
Reviewing code for [project/context].
The codebase uses [technologies/patterns].
</context>
<code_to_review>
[Paste code here]
</code_to_review>
<review_criteria>
Focus on:
1. Correctness: Does it do what it claims?
2. Readability: Is it clear to other developers?
3. Performance: Any obvious inefficiencies?
4. Security: Any vulnerabilities?
5. Style: Does it match codebase conventions?
</review_criteria>
<output_format>
For each issue found:
- Severity: [Critical/Major/Minor/Suggestion]
- Location: [Line number or section]
- Issue: [What's wrong]
- Fix: [How to address it]
</output_format>Research Analysis Template
<research_task>
[Topic or question to research]
</research_task>
<methodology>
- Start with multiple targeted searches; do not rely on a single query
- Deeply research until you have sufficient information for an
accurate, comprehensive answer
- Add targeted follow-up searches to fill gaps or resolve disagreements
- Keep iterating until additional searching is unlikely to change
the answer
</methodology>
<output_requirements>
- Lead with a clear answer to the main question
- Support with evidence and citations
- Acknowledge limitations and uncertainties
- Provide concrete examples where helpful
- Include relevant context for understanding implications
</output_requirements>
<citation_format>
[How you want sources cited]
</citation_format>Web Research Agent
<core_mission>
Answer the user's question fully and helpfully, with enough evidence
that a skeptical reader can trust it.
Never invent facts. If you can't verify something, say so clearly.
Default to being detailed and useful rather than short.
After answering the direct question, add high-value adjacent material
that supports the user's underlying goal without drifting off-topic.
</core_mission>
<research_rules>
- Start with multiple targeted searches; use parallel searches
- Never rely on a single query
- Keep iterating until all true:
- You answered every part of the question
- You found concrete examples and high-value adjacent material
- You found sufficient sources for core claims
</research_rules>
<citation_rules>
- Place citations after each paragraph containing non-obvious
web-derived claims
- Do not invent citations
- Use multiple sources for key claims when possible
</citation_rules>
<ambiguity_handling>
- Never ask clarifying questions unless user explicitly requests
- If query is ambiguous, state your best-guess interpretation, then
comprehensively cover the most likely intents
</ambiguity_handling>The Future of Prompt Engineering
As I write this in early 2026, prompt engineering is evolving rapidly. Models are becoming more capable, more steerable, and more reliable. Some predict prompt engineering will become obsolete as AI gets better at understanding intent. I disagree.
What's changing is the level of prompt engineering, not its necessity. Early days required elaborate prompts for basic tasks. Now, basic tasks work out of the box, but complex agentic workflows still require sophisticated prompting. The bar is rising, not disappearing.
Prompt engineering isn't going away—it's evolving. The skills that matter are shifting from "how to get AI to work" to "how to get AI to work excellently and reliably at scale."
What's Coming
Better Default Behaviors
Models will have smarter defaults, requiring less explicit instruction for common patterns. Prompts will focus more on customization than basic capability.
Richer Tool Ecosystems
AI will have access to more tools out of the box. Prompt engineering will shift toward orchestration—knowing when to use what, not just how.
Multimodal Integration
Prompts will increasingly involve images, audio, video, and structured data alongside text. New patterns will emerge for multimodal tasks.
Agentic Complexity
As agents handle longer, more complex tasks, prompt engineering will become more like system design—architecture, not just instructions.
My Advice for the Future
Focus on fundamentals. The specific techniques in this guide will evolve, but the underlying principles—clear communication, explicit expectations, structured thinking, iterative refinement—are timeless. Master those, and you'll adapt to whatever comes next.
Final Thoughts
Two years ago, I thought AI would replace the need to communicate clearly. I was completely wrong. AI has made clear communication more valuable than ever. The people who thrive with AI aren't those who found magic words—they're those who learned to think and express themselves with precision.
Prompt engineering isn't really about AI. It's about you. It's about developing the discipline to articulate what you actually want, the patience to iterate toward it, and the humility to learn from what doesn't work.
If you take one thing from this guide, let it be this: treat every prompt as a chance to practice clear thinking. The AI is just a mirror reflecting back the clarity—or confusion—of your own mind.
The emergence of AI hasn't made knowledge obsolete—it's made curiosity more powerful than ever. We're no longer limited by what we already know. With the right tools and willingness to think, ordinary people can embrace an ocean of knowledge. Regardless of profession. Regardless of age. I hope to share this journey with friends around the world. Together, let's welcome this new world. Together, let's grow.


Discussion
0 commentsLeave a comment
Be the first to share your thoughts on this article!